はじめに
赤石です。この記事は書籍「ChatGPTで儲かるデータ分析」の補足としてアップしています。
序章の実習では、最後に決定木分析をしているのですが、紙面の関係で、その解説が一切できていません。
その解説用の記事という位置づけになります。
notebook自体は、下記のURLにアップしているので、どなたでも動かすことが可能です。
Google Colabで動作確認済みです。
決定木分析とは
決定木分析とは何かを簡単に説明すると、データ分析において目的変数(今回の例の場合「生存」)にどの説明変数が大きな影響を与えたかを分析する手法です。この記事では有名な「タイタニック・データセット」に対して、決定木分析を行っています。
分析結果
最初に分析で得られたツリー図を示し、そこから何が読み取れるか解説します。
最終結果
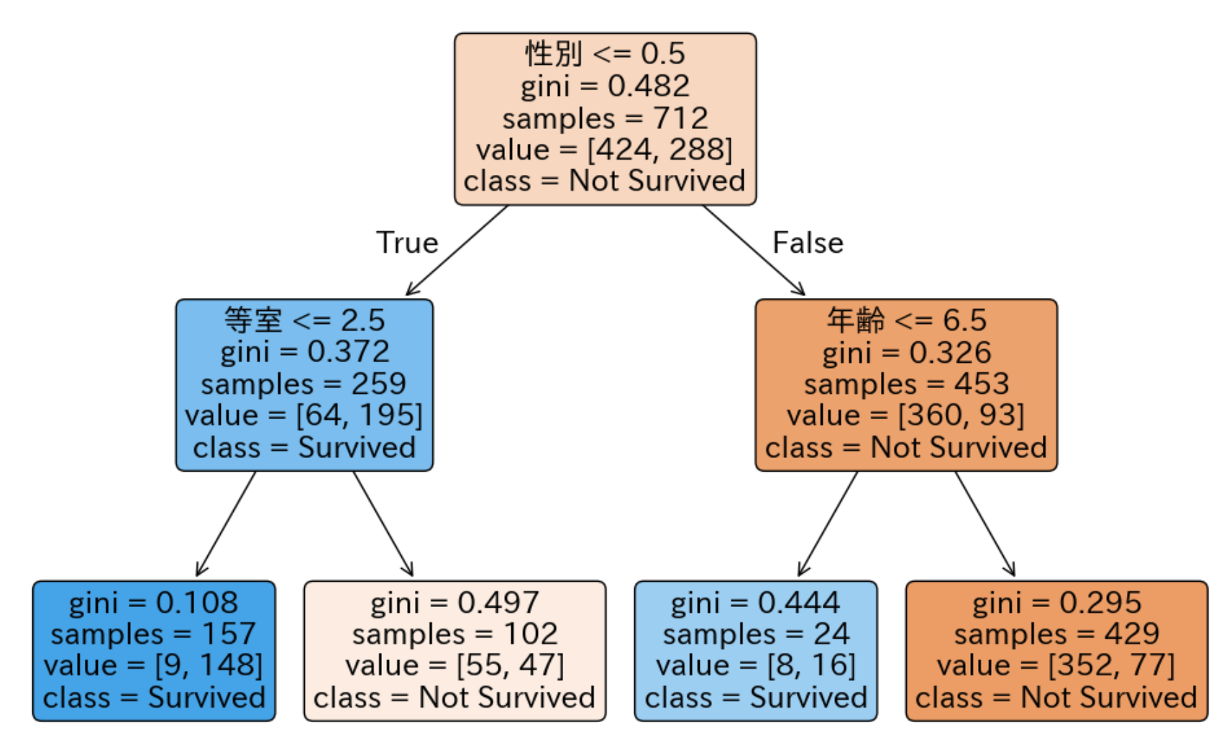
一連の分析で、最終的には次のツリー図が得られます。
読みとき方
このツリー図は、各ノードに多くの情報が含まれ、読み取り方が難しいのでその解説をします。

① 次のノードにどのような基準で分離されるかを示しています。
この例の場合「等室」(客室のクラスを示し、1, 2 , 3の値を取る)の値が2.5以下(True)の場合は左の子ノードに、2.5より大きい場合は右の子ノードになります。「等室」の値は1, 2, 3の値しか取らないため、結果的に
- 一等客室、二等客室の乗客は左
- 三等客室の乗客は右
ということになります。
② 自分自身のノードの純度を示します。
決定木は「純度」をいう数値を元に、最適な分類対象の項目と閾値を見つけます。2値分類の目的変数に対して理想的な状態はすべて同一の値になっている状態で、これが純度=0です。反対に完全にバラバラな状態は1対1の状態で、この場合の純度は0.5になります。
③ 自分自身のノードにおけるデータ件数を示しています。
④ 目的変数の項目値の集計結果を示します。
左側が0(生存できなかった)件数、右側が1(生存できた)件数です。
③と④をあわせて解釈すると、このノードにおけるデータ件数は全部で259件(乗客数259名)で、うち64名が救助されず、195名が救助されたことを意味します。
⑤ このノードがどちらのグループに分類されるかを示しています。
今回の例の場合、このノードの目的変数で1の値が多い場合は"Survived"を、0の値が多い場合は"Not Survived"を示します。
今回の図の読み解き
上の可視化結果は、読み取りにくい部分があるので、その解説を加えました。

各ノードの詳細解説
上の図に対して解説を加えます。
今回の例では 「性別」が一番大きな影響を与えていたことがわかります。
元のデータを「女性」「男性」で分類すると、「女性」の生存率が75.3% であったのに対して「男性」の生存率は20.5%でした。
女性の中でもどの客室の乗客だったかで生存率は大きく変わります。一等と二等客室の場合、生存率は94.3%まであがります。逆に三等客室の場合は、46.1%まで下がってしまいました。
男性の場合、年齢によって生存率が大きく変わります。
年齢6歳以下の場合、生存率は66.7%まで高くなりました。
一方で、年齢が7歳以上の場合の生存率は17.9%と、更に低い数字になっています。
コード解説
最後にnotebookのコード解説を簡単にします。
共通コード
著者が、書籍のサンプルコードで標準的に共通化しているコードです。必
要なライブラリのインポートや変数初期設定をしています。
# 日本語化ライブラリ導入
!pip install japanize-matplotlib | tail -n 1
# 必要ライブラリのimport
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# matplotlib日本語化対応
import japanize_matplotlib
# データフレーム表示用関数
from IPython.display import display
# pandasでの浮動小数点の表示精度
pd.options.display.float_format = '{:.2f}'.format
# 余分なワーニングを非表示にする
import warnings
warnings.filterwarnings('ignore')
データ読み込み
項目名を日本語化した「タイタニック・データセット」のデータを読み込んでいます。
url = 'https://raw.githubusercontent.com/makaishi2/sample-data/refs/heads/master/data/titanic_j.csv'
df = pd.read_csv(url)
display(df.head())

データ前処理
ここからは、生成AI(GPT-4o)が自動生成したコードの後追い解説です。ちょっと、どうよという箇所もありますが、かかなり粒度の荒いプロンプトに対するものなので、大目に見てあげてください。(書籍の本編の中では、こういうことが起きないよう、もっと細かい粒度のプロンプトを出す形にしています。)
参考までに、GPT-4oに出した具体的なプロンプトは下記になります。たったこれだけの指示で、ある程度実用に足る結果を出せることは、十分凄いとも言えます。
「生存」を目的変数とし、深さ2の決定木分析し、結果を可視化してください
「等室」「年齢」「性別」「乗船港」を説明変数に含めた上で、欠損値を除去してモデル構築をします
欠損値を除去
決定木分析で分析対象にする項目のみに対して、欠損値を除去します。
# 欠損値を除去
df_clean = df[['生存', '等室', '年齢', '性別', '乗船港']].dropna()
display(df_clean.head())
| 生存 | 等室 | 年齢 | 性別 | 乗船港 | |
|---|---|---|---|---|---|
| 0 | 0 | 3 | 22 | male | Southampton |
| 1 | 1 | 1 | 38 | female | Cherbourg |
| 2 | 1 | 3 | 26 | female | Southampton |
| 3 | 1 | 1 | 35 | female | Southampton |
| 4 | 0 | 3 | 35 | male | Southampton |
エンコード
決定木分析のためには、カテゴリデータをエンコードする必要があるので、その対応をします。
(この話は、データ分析を行うに際しては必須知識です。書籍の中では講座2.1と講座2.2で詳しく解説しています)
乗船港に関してこの方式(ラベルエンコード)でエンコードをかけるのはどうかと思いますが、大目にみてあげてください。
from sklearn.preprocessing import LabelEncoder
# カテゴリカル変数を数値に変換
label_encoders = {}
for column in ['性別', '乗船港']:
le = LabelEncoder()
df_clean[column] = le.fit_transform(df_clean[column])
label_encoders[column] = le
display(df_clean.head())
| 生存 | 等室 | 年齢 | 性別 | 乗船港 | |
|---|---|---|---|---|---|
| 0 | 0 | 3 | 22 | 1 | 2 |
| 1 | 1 | 1 | 38 | 0 | 0 |
| 2 | 1 | 3 | 26 | 0 | 2 |
| 3 | 1 | 1 | 35 | 0 | 2 |
| 4 | 0 | 3 | 35 | 1 | 2 |
説明変数と目的変数を定義
説明変数Xと目的変数yにデータを分離します。
(GPT-4oは、ここで「訓練データ」と「テストデータ」への分割もやっていたのですが、意味がないし読む人の見通しが悪くなるので、そこは記事ではカットしました。)
X = df_clean[['等室', '年齢', '性別', '乗船港']]
y = df_clean['生存']
モデル構築・分析
これで決定木分析に必要な前処理がすべておわりました。あとは、全量データを使って深さ2の決定木を作り、更に可視化します。
決定木モデルを構築(深さ2)
from sklearn.tree import DecisionTreeClassifier, plot_tree
# 決定木モデルを構築(深さ2)
clf = DecisionTreeClassifier(max_depth=2, random_state=42)
clf.fit(X, y)
結果の可視化
plt.figure(figsize=(12, 8))
plot_tree(clf, feature_names=X.columns, class_names=['Not Survived', 'Survived'], filled=True, rounded=True)
plt.title('深さ2の決定木による生存予測')
plt.show()
これで冒頭で紹介した決定木ができました。