はじめに
IBMは、CPLEXという最適化ソフトを製品として持っていますが、現在、そのクラウド対応版としてDecision Optimizationというツールを提供しています。具体的にはクラウド上のWatson Studioでも動きますし、OpenShiftベースの製品であるCP4Dでも動きます。
当記事では、下記リンク先のチュートリアルを参考に、Python APIを使ったスケジューリング問題の実装を解説していきます。
元のチュートリアルは、かなり長いものなので、その中の問題毎に記事を分けて解説することにします。
なお、一つ一つの関数の細かい解説は、下記APIリファレンスに詳しいので、こちらも適宜参照して下さい。
Decision Optimizationの利用方法
Decision Optimizationは次の3つの利用方法があります。
- Python APIをNotebookから起動
- UI(Model Builder)から起動
- Rest APIを利用してWeb Serviceとして起動
2.の利用法については、スケジューリング問題ではありませんが、別記事CPLEXサンプル(diet.py)をWatson StudioのDecision Optimization上で動かすで解説しています。
3.の利用方法についても、別記事CPLEXサンプル(diet.py)をWatson MLのWebサービス化するで解説しています。
当記事は、1.のJupyter Notebookに絞って解説を行います。
事前準備
事前準備として
- IBM Cloudでアカウント登録を行う (クレジットカードなし、無料で可)
- Watson Studio、Cloud Object Storage、Watson Machine Learningのインスタンス作成
- プロジェクトの作成
- プロジェクトとWatson Machine Learingの関連付け
の作業が必要です。こちらの手順については、別記事無料でなんでも試せる! Watson Studioセットアップガイドを参照して下さい。
CPLEX(Decision Optimization)のコミュニティエディションと製品版の違い
これから解説するDecision Optimizationは、OSSとして公開されている版(コミュニティエディション)と、製品版があります。違いは変数やルール数が1000を超えることができるかどうかです。
試しに使ってみる分には、コミュニティエディションでいいのですが、実業務で使おうとするとすぐにこの制約を超える必要が出てきます。その場合は、製品版を使っていただく形になります。以下の手順は製品版を利用するためのものとなります。
(クラウドの無料のWatson Studioでは50CUHという無料で使えるCPU利用量の上限があります。この範囲内であれば製品版も使える形になります)
Notebookの作成
Watson StudioでNotebookを作成します。
まず、下のプロジェクト管理の画面で「プロジェクトに追加」をクリックします。
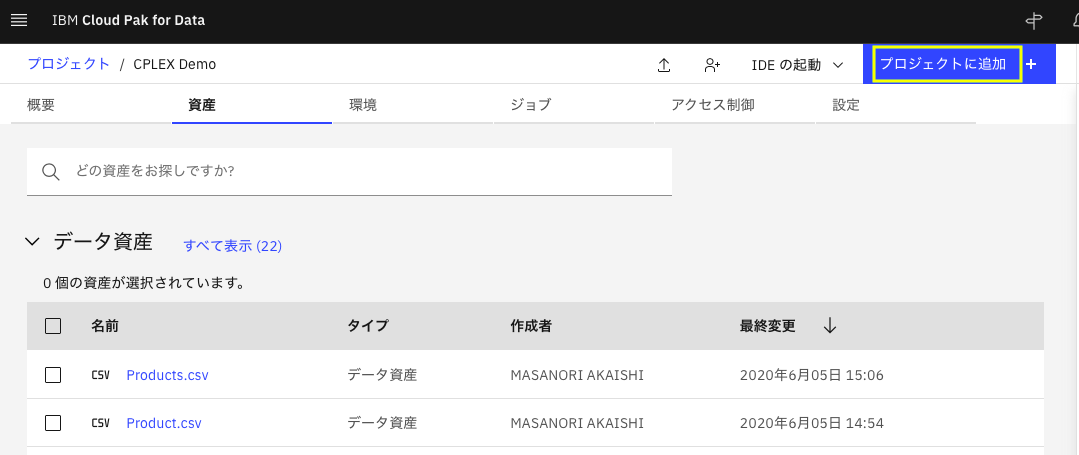
出てきたパネルで「Notebook」を選択します。
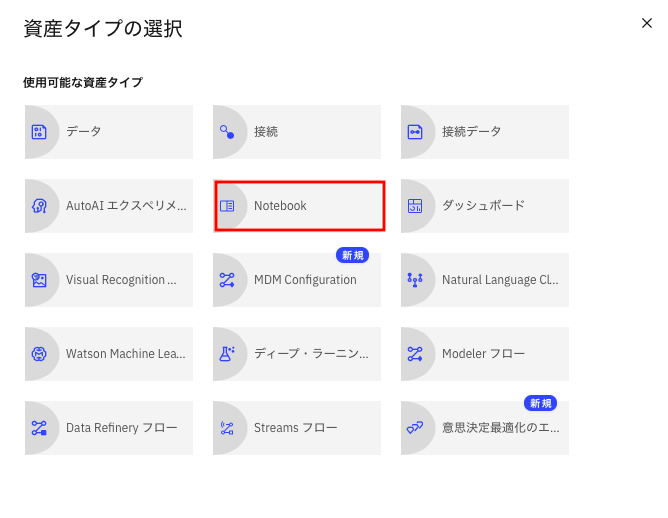
次の画面が出てくるので、順に以下の操作をします。
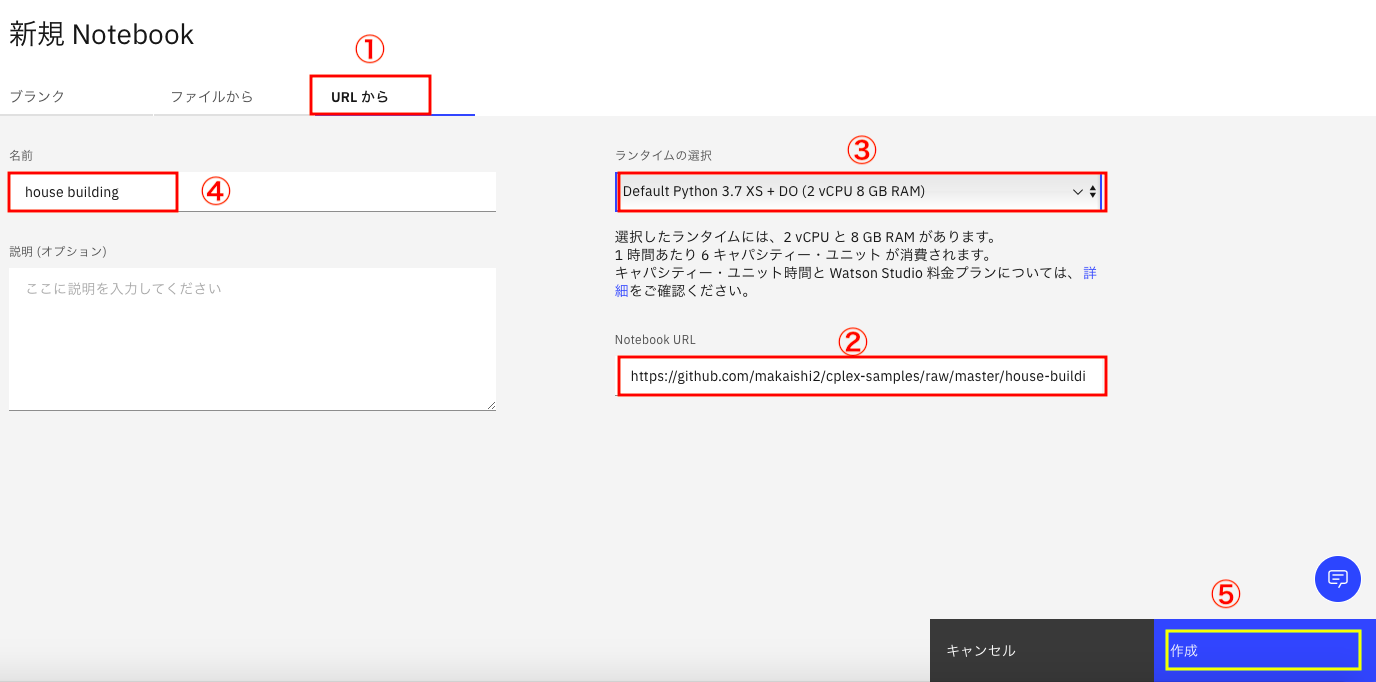
① 画面上部の「URLから」タブをクリックします。
② 右下の「Notebook URL」の欄に下記URLをコピペします。
https://github.com/makaishi2/cplex-samples/raw/master/house-building/house-building1.ipynb
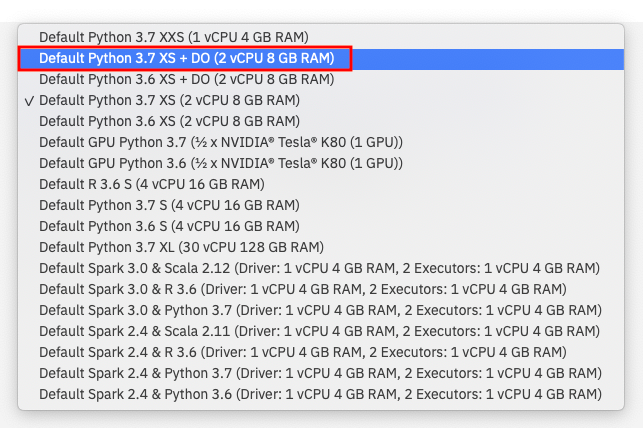
③ 右側の「ランタイムの選択」のドロップダウンをクリックします。
下のリストが出てくるので、「Default Python 3.7 XS + DO (2vCPU 8 GB RAM)」を選択して下さい。これを選ぶことで、上で説明した1000件の制約が取れることになります。
④画面右上の「名前」を入力(図では house buildingとしています)
⑤ 入力がすべて終わったら、「作成」ボタンをクリックします。
しばらくして下のような結果になったら,Notebook作成に成功しています。
サンプルコード紹介
コードの内容
これから紹介するコードは以下のURLから参照可能です。
コードの実行
まずは、shift+enterを何度も押して、今読み込んだコードを実行してみて下さい。
最後に下のようなガントチャートが出てくればプログラム実行に成功しています。
問題の説明
DOのコードの説明をする前に、これから解く問題の説明を簡単にします。
これからやるのは、家の建築計画の策定です。
- 家の建築は「celling」「roofing」など、全部で10個の工程からなります。
- それぞれの工程は所要日数が決まっています。
- 各工程には依存関係があります。 (土台ができていないと壁を作れないなど)
- この2つの条件を満たしつつ、最短日数で建築するにはどうしたらいいかを考えます。
これを解くのが最適化問題ということになります。
コードの解説
それでは、上のセルから順にコードの解説を行います。
条件の定義
最初に条件をPythonの変数で定義します。
TaskNamesは各工程の名称のリストです。
Durationは工程毎に必要な日数を表しています。
Precedencesは工程間の依存関係を示します。
例えば、("masonry", "celling")は、「基礎が完成しないと壁を作れない」ということを意味します。
# 工程名
TaskNames = ["masonry", "carpentry", "plumbing",
"ceiling", "roofing", "painting",
"windows", "facade", "garden", "moving"]
# 工程毎の期間
Duration = [35, 15, 40, 15, 5, 10, 5, 10, 5, 5]
# 工程間依存関係
Precedences = [("masonry", "carpentry"),("masonry", "plumbing"),
("masonry", "ceiling"), ("carpentry", "roofing"),
("ceiling", "painting"), ("roofing", "windows"),
("roofing", "facade"), ("plumbing", "facade"),
("roofing", "garden"), ("plumbing", "garden"),
("windows", "moving"), ("facade", "moving"),
("garden", "moving"), ("painting", "moving")]
モデルインスタンスの生成
ライブラリのimportを行い、モデルインスタンスを生成します。
# ライブラリのimportとモデルのインスタンス作成
import sys
from docplex.cp.model import *
mdl0 = CpoModel()
from docplex.cp.model import *がDO用のライブラリのimport文です。
DOでは、「線形計画法」と「制約プログラミング」の2つのライブラリが利用可能です。今回の建築計画では、このうち「制約プログラミング(cp)」を利用します。
参考までに線形計画法のライブラリ名称はmpとなります。
その次のCpoModel()が、制約プログラミング用モデルインスタンスの生成コードになります。
工程ごとの期間の定義
次に各工程毎の所要日数をモデル上に表現していきます。
# 工程ごとの期間の定義
# タスク名からInterval変数を引く辞書
itvs = {}
# Interval変数の定義
# タスク名
for i,taskName in enumerate(TaskNames):
itvs[taskName] = mdl0.interval_var(size=Duration[i], name=taskName)
このコードの説明に入る前に、Decision Optimization固有の概念である、interval variableの説明をしましょう。
下の図が、interval_variableの概念を図示したものです。
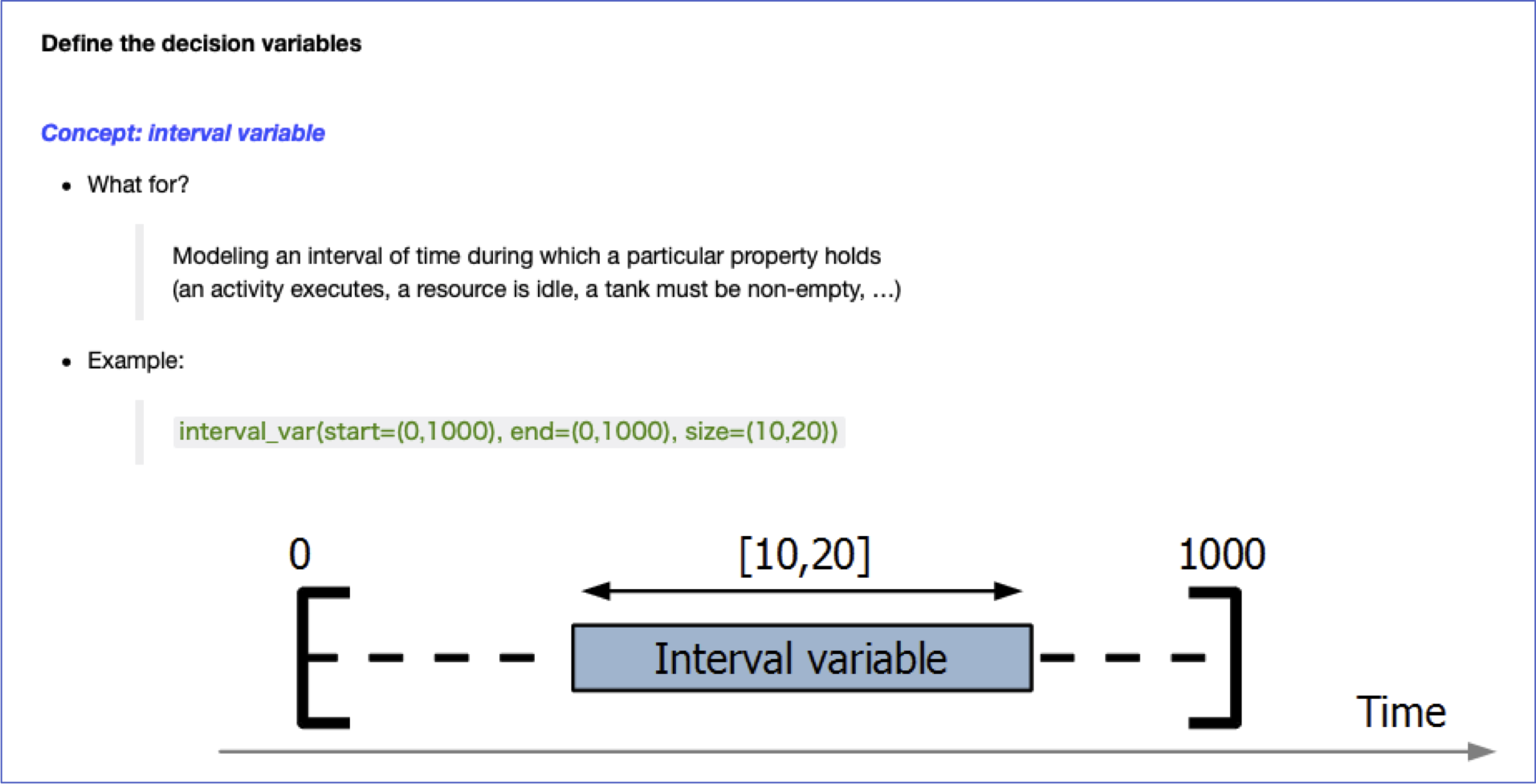
inteval variableとは、例えば壁を作るなどの工程の期間を、開始日(start)、終了日(end)、期間(size)の3つの整数の組みで表現したものです。例えば、壁を作る工程に15日かかるのだとすると、celling用のinterval variableは、
開始日: 未定
終了日: 未定
期間: 15日
と表現できます。作業工程に特化したデータ構造を作り、未定の部分の組み合わせを最適化問題で解いていくことになります。
この方式のいいところは、ルール定義が簡潔にできる点です。
このことを頭において上のコードを見直します。
mdl0.interval_var(size=Duration[i], name=taskName)が、今説明したinterval variableを宣言している箇所です。sizeのパラメータにタスクごとの期間が、nameのパラメータにceiingなどの工程名をセットした形で、interval_var関数が呼ばれていることがわかると思います。
関数の呼び出し結果はitvs[taskName]に代入され、タスク名からいつでもこの変数を取り出せるようにしています。
タスク間の依存関係定義
次にタスク間の依存関係をモデル上の制約として表現していきます。
# タスク間の依存関係定義
for p in Precedences:
mdl0.add(mdl0.end_before_start(itvs[p[0]], itvs[p[1]]) )
タスク間の依存関係はend_before_startという関数で表現します。
この関数は2つの引数を取ります。前の引数が前提タスク、後の引数が、従属タスクです。
それぞれ、interval variableである必要があるため、さっそく上で定義した辞書を使って、タスク名からinterval variableオブジェクトを引いています。
こうして定義した依存関係は、モデルインスタンスのadd関数を使って制約として追加していきます。
モデルを解く
これでモデルを解くための準備は整いました。モデルインスタンスに対して必要な条件をすべてセットし終わったら、solve関数で、最適により問題を解きます。実装コードは以下のとおりです。
# モデルを解く
print("\nSolving model....")
msol0 = mdl0.solve(TimeLimit=10)
print("done")
solve関数の引数としていろいろな条件を付けることもできますが、今回は時間制限値だけをオプションにしています。
今回はとても簡単な問題なので、一瞬で解けるはずです。
結果確認
それでは、解いた結果をprint関数で確認してみましょう。コードは以下のとおりです。
# 結果表示
for taskName in TaskNames:
var_sol = msol0.get_var_solution(taskName)
print(f"{taskName} : {var_sol.get_start()}..{var_sol.get_end()}")
解を示すインスタンスであるmsol0に対して、工程の名称ごとに、get_var_solution関数を呼び出しています。
ここで得られたvar_sol変数は、get_start関数で開始日、get_end関数で終了日を取得できるので、全タスクでその結果を確認しています。
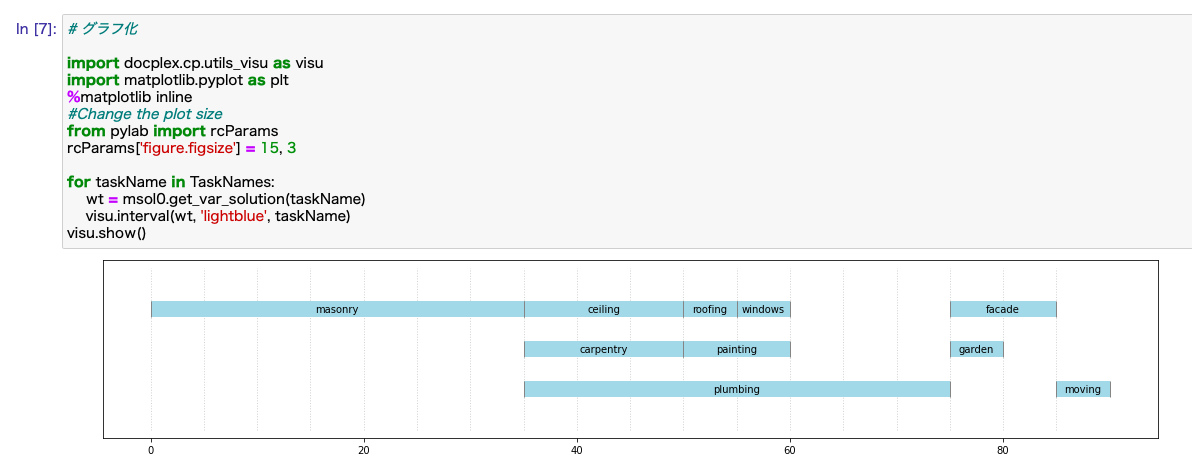
うまくいくと、次のような結果が返ってきているはずです。
masonry : 0..35
carpentry : 35..50
plumbing : 35..75
ceiling : 35..50
roofing : 50..55
painting : 50..60
windows : 55..60
facade : 75..85
garden : 75..80
moving : 85..90
グラフ化
Decision Optimizationでは、専用の関数を使って、得られた結果をグラフ(ガントチャート)の形でも表示可能です。
そのことを実際に試してみましょう。
# グラフ化
import docplex.cp.utils_visu as visu
import matplotlib.pyplot as plt
%matplotlib inline
#Change the plot size
from pylab import rcParams
rcParams['figure.figsize'] = 15, 3
for taskName in TaskNames:
wt = msol0.get_var_solution(taskName)
visu.interval(wt, 'lightblue', taskName)
visu.show()
get_var_solution関数を使って、タスクごとに結果の入った変数のインスタンスを取得するところは、先ほどのprint関数の例と同じです。今回は、print関数の代わりに、visu.interval(wt, 'lightblue', taskName)という関数呼び出しをしています。これが、ガントチャートで該当interval variableの期間を表示する関数となります。
うまくいくと、下のようになるはずです。

終わりに
Decision Optimizationを使った初めてのスケジューリングはいかがだったでしょうか?
新しい概念がいくつかあり、それになれるのが多少大変ですが、定義自体は意外と簡単なものであることがわかったかと思います。
最適化ツールでは、モデルの内部では複雑な数学の理論が使われているのですが、使う立場では、条件をプログラムで表現さえすれば、後はツールがよろしくやってくれるので、そういう数学的なことは考えなくていいのです。
今回は、初めての回であったため、制約条件はたった2種類のとてもシンプルなものでした。結果のガントチャートを見て、
* 3つのタスクを同時にやっているけれど、作業員はそんなに大勢いるのか
* そもそも、だれでもどのタスクができるのか
など、いろいろとツッコミを入れたいところがあるかと思います。
次回は、こうした現実的な制約も配慮して、今回より複雑な条件の最適化を実装してみます。ご期待下さい。