始めに
別記事
CPLEXサンプル(warehouse)をWatson StudioのDecision Optimization上で動かす と
CPLEXサンプル(warehouse)をWatson MLのWebサービス化する
でOPLで実装したCPLEXのコードをWatson Studio / Watson Machine Learning上で動かす方法を説明しました。
当記事は、Python APIによる実装で同じことをした場合の手順の説明です。
対象コード
対象とするコードは、以下のものをポーティングしたものです。
すべての栄養素に関する制約を満たしつつ、コスト最小の献立にするには、どうしたらいいかという問題です。
このコードをModel Builder用に修正したものが、下記になります。
# dd-cell
food = inputs['diet_food']
nutrients = inputs['diet_nutrients']
food_nutrients = inputs['diet_food_nutrients']
food_nutrients.set_index('Food', inplace=True)
# dd-cell
from docplex.mp.model import Model
# Model
mdl = Model(name='diet')
# Create decision variables, limited to be >= Food.qmin and <= Food.qmax
qty = food[['name', 'qmin', 'qmax']].copy()
qty['var'] = qty.apply(lambda x: mdl.continuous_var(lb=x['qmin'],
ub=x['qmax'],
name=x['name']),
axis=1)
# make the name the index
qty.set_index('name', inplace=True)
# Limit range of nutrients, and mark them as KPIs
for n in nutrients.itertuples():
amount = mdl.sum(qty.loc[f.name]['var'] * food_nutrients.loc[f.name][n.name]
for f in food.itertuples())
mdl.add_range(n.qmin, amount, n.qmax)
mdl.add_kpi(amount, publish_name='Total %s' % n.name)
# Minimize cost
obj = mdl.sum(qty.loc[f.name]['var'] * f.unit_cost for f in food.itertuples())
mdl.add_kpi(obj, publish_name="Minimal cost");
mdl.minimize(obj)
mdl.print_information()
# dd-markdown <h1>Solve</h1>
# dd-cell
ok = mdl.solve()
# dd-cell
mdl.print_solution()
# dd-markdown Make dataframe from solution
# dd-cell
import pandas
import numpy
solution_df = pandas.DataFrame(columns=['name', 'value'])
for index, dvar in enumerate(mdl.solution.iter_variables()):
solution_df.loc[index,'name'] = dvar.to_string()
solution_df.loc[index,'value'] = dvar.solution_value
# dd-cell
solution_df
# dd-cell
outputs['solution'] = solution_df
実装上のポイントは以下の点になります。
- 入力データは辞書型の変数
inputsから取得可能 - 例えば
inputs['diet_food']という参照により、diet_food.csvをデータフレームに取り込んだ結果が取得できる - 出力も同じルールで
outputs['solution']という形で辞書にデータフレームを保存すると、出力用csvsolution.csvとして取得可能
入力データ
OPLの場合と同様に、入力データはすべてCSVにする必要があります。
今回の場合、CSVデータとしてはdiet_food.csv、diet_nutrients.csv、diet_food_nutrients.csvの3つを利用します。
それぞれのCSVファイルは、以下のgithubからダウンロードして下さい。
IBM クラウドへのユーザー登録・Watson Studioの準備
これからの操作をするためには、IBM Cloudにアカウント登録を行い、Watson Studioのインスタンスを作成してWatson Studioのプロジェクトを作る必要があります。また、Watson Machine Learningとの関連づけも必要です。
一連の手順は、別記事に記載してありますので、こちらを参照して下さい。
無料でなんでも試せる! Watson Studioセットアップガイド
モデルビルダーの起動
次の手順でモデルビルダーを起動します。
資産管理の画面から、画面右上の「プロジェクトに追加」をクリック
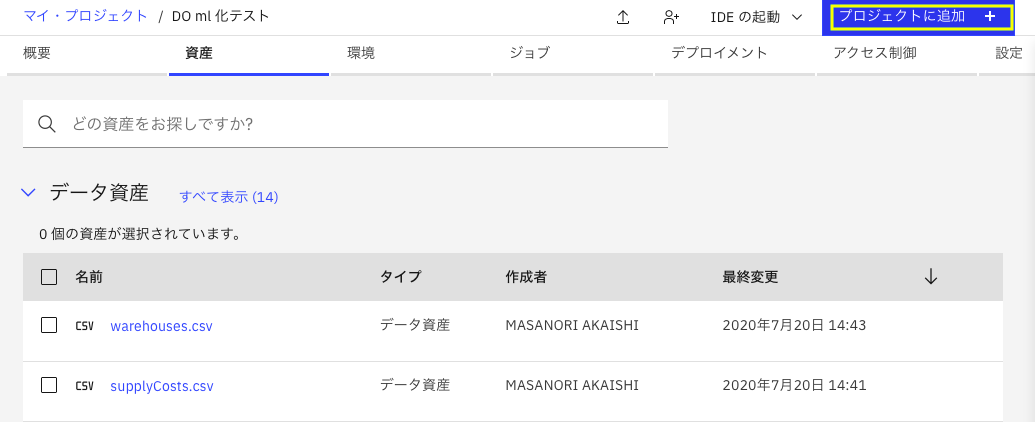
メニューから「意思決定最適化の実験」を選択
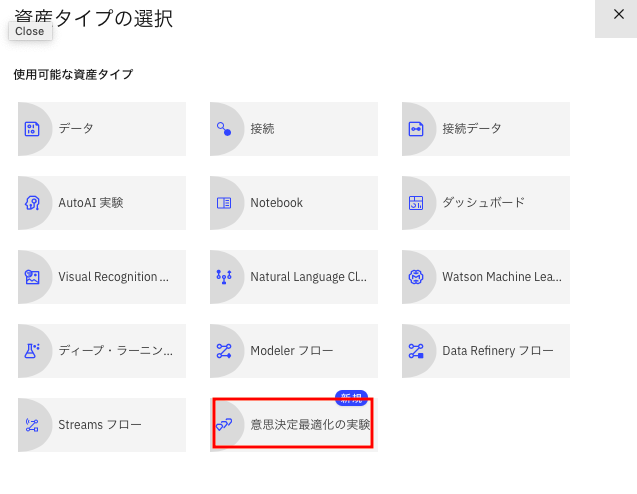
①下の画面で「diet python」などと、名称を入力
②画面右下の「Create」ボタンをクリック
これで、モデルビルダーの初期画面が表示されます。
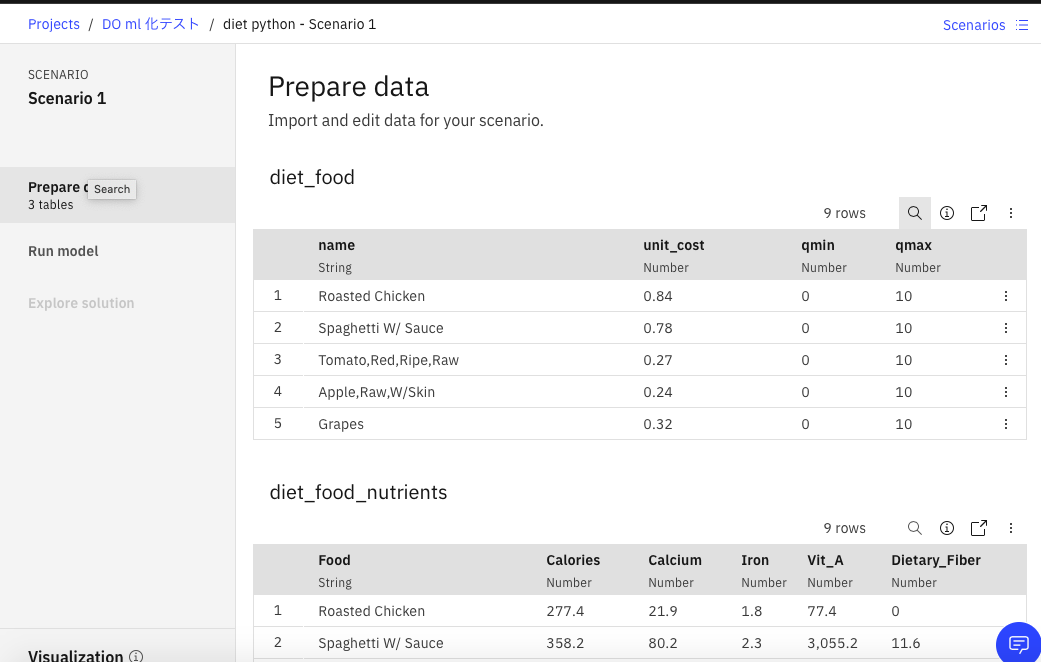
CSVデータのロード
モデル構築の最初のステップは事前準備したCSVデータのロードです。
①上の画面からdrag and dropで3つのCSVデータをアップロードして下さい。
②アップロードが終わると、下の画面のように3つのCSVファイルが選択された状態になるはずです。
③この状態で、黄色の枠で示した、Importのリンクをクリックして下さい。
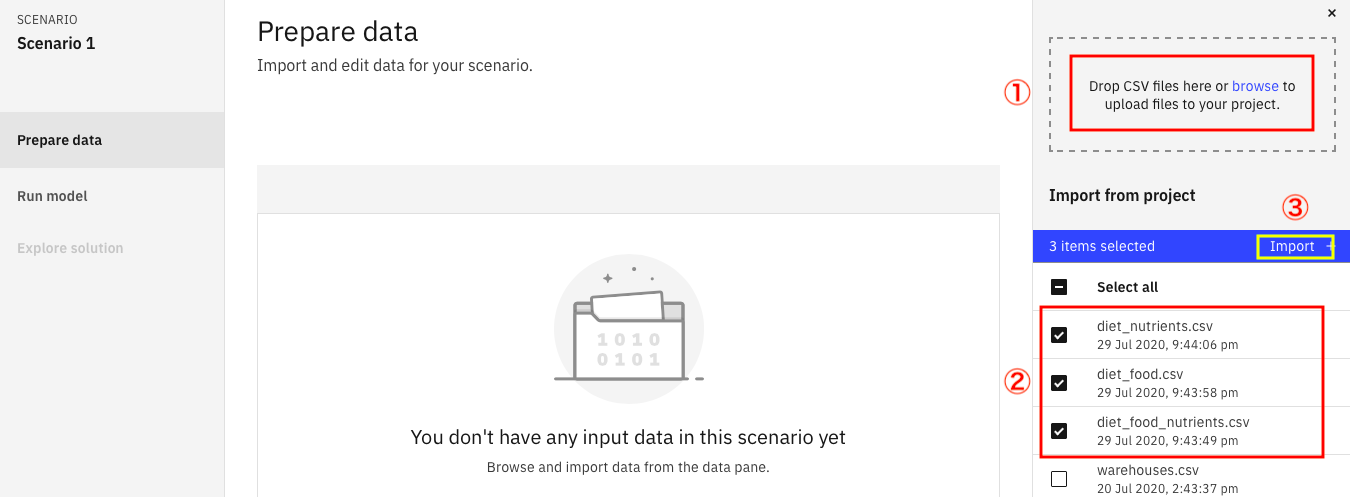
すると、下の画面のように3つのCSVデータがモデルビルダーに取り込まれた形になるはずです。これで、データの準備は完了となります。
Modelの定義
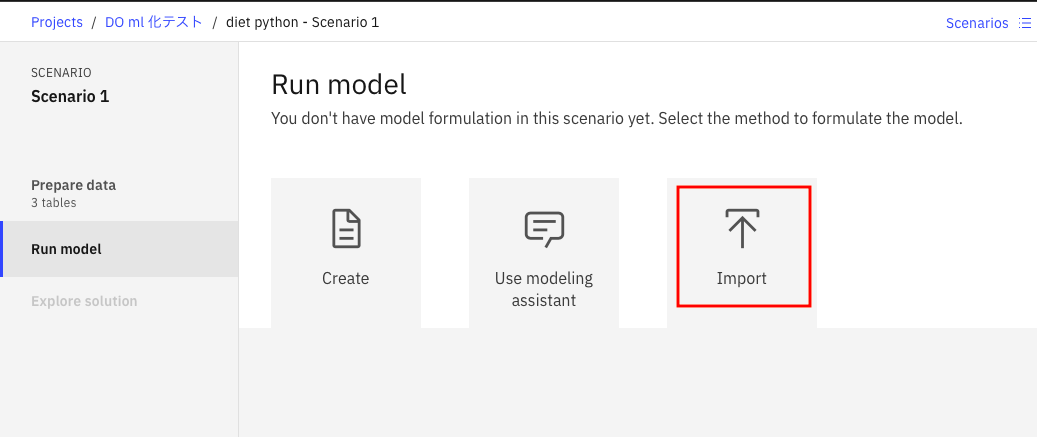
データの準備が完了したら、次はモデルの定義です。上の画面で赤枠で囲んだ、「Run model」をクリックして下さい。すると、下の画面になります。
今回は、実装済みのpythonコードを取り込めばいいので、一番右の「Import」を選びます。
下のような画面になります。今回の実装はPythonなので、「Python」タブを選択します。
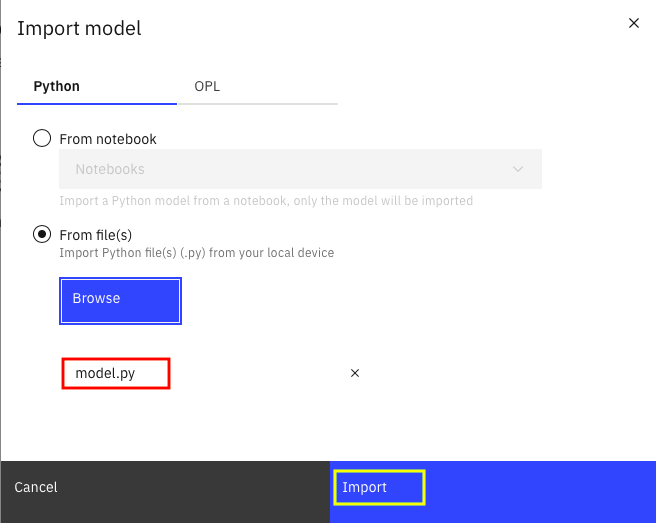
「Browse」ボタンをクリックして事前準備済みのOPLコードmodel.pyを指定します。
その後で、画面右下の「Import」ボタンをクリックして下さい。
下のような画面に遷移したら、コードの準備も完了です。
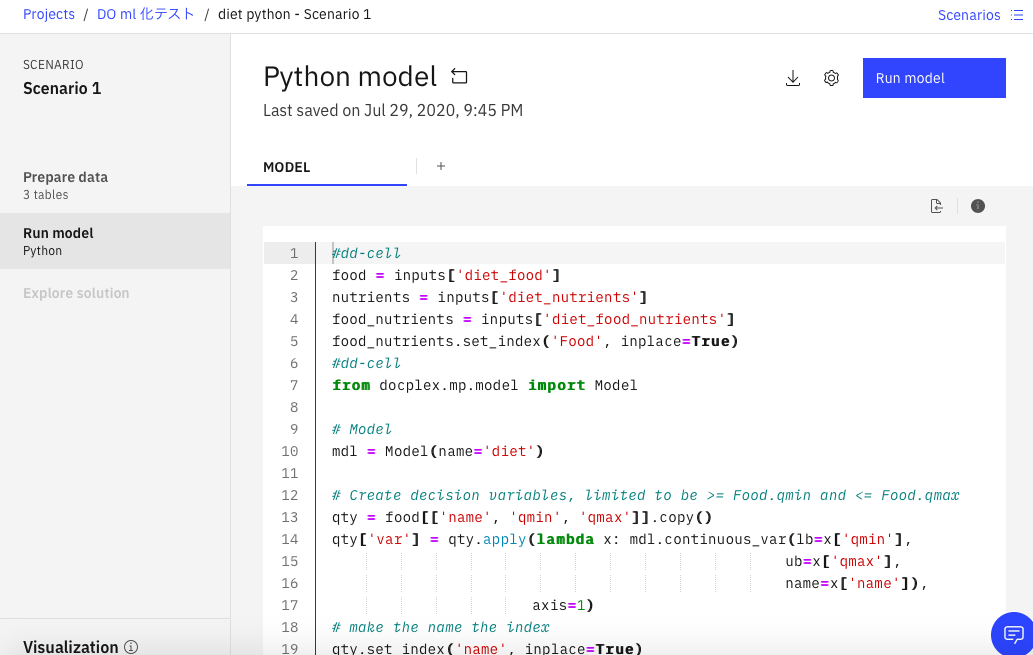
モデルの実行
これで、Watson StudioでDOモデルを実行するためのすべての準備は整いました。あとは画面右上の「Run model」ボタンをクリックすると、モデルが実行されます。
しばらく待って、下のような画面になれば、モデルの実行に成功しています。
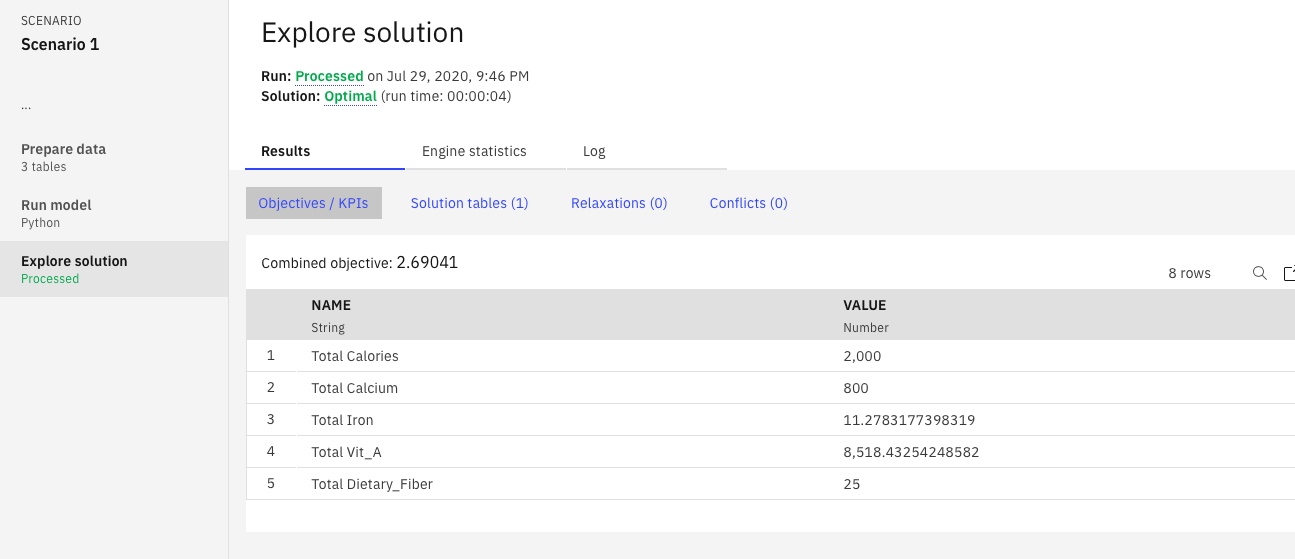
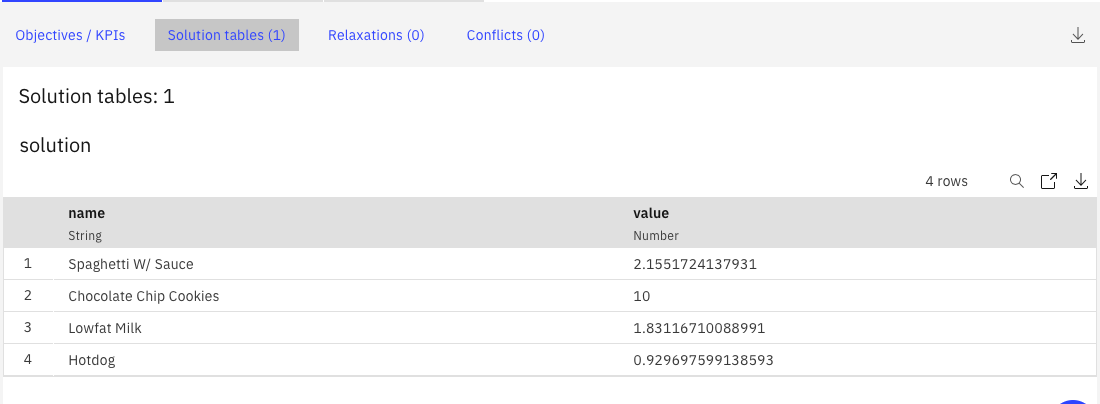
「Solution Tables」のタブをクリックすると、下のような最適解が表示されます。
コード・データ一式は、下記githubにアップしておきました。
別のデータで最適化する場合
いったんModel Builderで登録したデータを削除します。それから、新しいCSVデータを同じファイル名でクラウド上にアップロードしなおして下さい。
あとは、先ほどと同じ手順で、Model Builder上にデータ登録し、モデルを実行すれば結果が得られます。
Watson MLでのWebサービス化
ここまでの動作が確認された場合、次のステップとして、動作を確認したPythonコードをWatson MLにデプロイし、Webサービスとして呼び出すことも可能です。
その手順については、別記事CPLEXサンプル(diet.py)をWatson MLのWebサービス化するで紹介します。