はじめに
Pythonで機械学習モデルを構築する場合、scikit-learnに含まれている処理パターン(分類・回帰・クラスタリング等)であればネット上にサンプルも数多くあり、それらを参照すれば簡単に実装可能なのですが、そうでない場合、ライブラリの選定から、実装サンプルの入手まで結構大変だったりします。
その典型例が、マーケティング分析で多用される「アソシエーション分析」です。Rであればよく使われるライブラリで簡単にモデル構築が可能ですが、Pythonでは意外にそうしたサンプルコードが少ないです。
当記事は、その部分の紹介をします。
ちなみに、より上流の業務観点でのユースケース、UCIのサンプルデータセットからの元データからの加工手段を含めた一連の手順とその解説は、私の著作「儲かるAI」の5.4節で詳しく記載しています。
関心ある方は、是非こちらの本も参照されて下さい。

Amazon 単行本
https://www.amazon.co.jp/dp/4296106961/
Amazon Kindle
https://www.amazon.co.jp/dp/B08F9P726T/
書籍サポートページ
https://github.com/makaishi2/profitable_ai_book_info/blob/master/README.md
利用データ
次のリンク先のデータを利用します。
このデータはUCIデータセットから一定の加工を行ったあとのものです。
ここに至るまでの加工手順については、上述の書籍を参考にして下さい。
実装コード概要
以下に、このデータを使ったアソシエーション分析実装コードの概要を示します。
Notebook全体については、
にアップしておきました。
共通処理
書籍共通の事前処理のうち、今回のサンプルで関係ある部分を抽出しました。
# 共通事前処理
# 余分なワーニングを非表示にする
import warnings
warnings.filterwarnings('ignore')
# 必要ライブラリのimport
import pandas as pd
import numpy as np
# データフレーム表示用関数
from IPython.display import display
# 表示オプション調整
# pandasでの浮動小数点の表示精度
pd.options.display.float_format = '{:.4f}'.format
# データフレームですべての項目を表示
pd.set_option("display.max_columns",None)
データ読込み
上で示した事前加工済みCSVデータをデータフレームに取り込みます。
url = 'https://raw.githubusercontent.com/makaishi2/sample-data/master/data/retail-france.csv'
df = pd.read_csv(url)
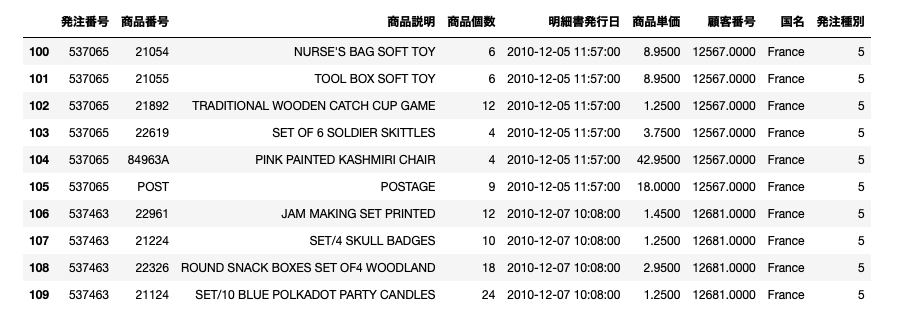
display(df[100:110])
display関数の結果はこんな形になるはずです。
データ加工
上記のデータに対してアソシエーション分析をするためには、データをヨコ持ち形式に変換する必要があります。
(ヨコ持ちとはそもそも何か知りたい方は書籍を参照して下さい)
そのための実装コードが下記になります。
# 発注番号と商品番号をキーに商品個数を集計する
w1 = df.groupby(['発注番号', '商品番号'])['商品個数'].sum()
# 結果確認
print(w1.head())
この段階でのw1の状態は以下のとおりです。

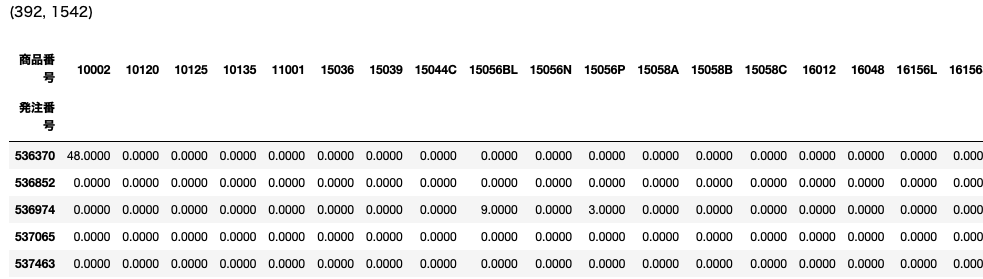
unstack関数を使って行にあった商品番号を列に移動します。
# 商品番号を列に移動 (unstack関数の利用)
w2 = w1.unstack().reset_index().fillna(0).set_index('発注番号')
# サイズ確認
print(w2.shape)
# 結果確認
display(w2.head())
結果は次のようになります。
最後にデータフレームのapply関数で、各要素を数値から True / False のバイナリ値に変換します。
# 集計結果が正か0かでTrue/Falseを設定
basket_df = w2.apply(lambda x: x>0)
# 結果確認
display(basket_df.head())
結果は次のとおりです。これでアソシエーション分析のための前処理は完了しました。

モデル構築
アソシエーション分析のライブラリとしてはmlextendを利用します。
mlextendは、sckit-learnほど有名ではないですが、scikit-learn同様の、Python機械学習用のライブラリです。
最初にmlxtendのライブラリを導入します。
# mlxtend の導入
!pip install mlxtend
次に分析で利用する関数aprioriとassociation_rulesをimportします。
# ライブラリの読み込み
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
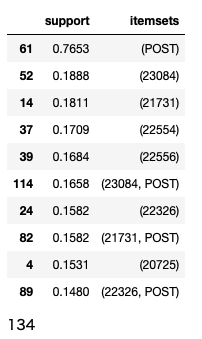
最初にアプリオリ分析という手法で「サポート」と呼ばれる数値の値が高い商品間の関係を抽出します。
# アプリオリによる分析
freq_items1 = apriori(basket_df, min_support = 0.06,
use_colnames = True)
# 結果確認
display(freq_items1.sort_values('support',
ascending = False).head(10))
# itemset数確認
print(freq_items1.shape[0])
次のような結果になります。
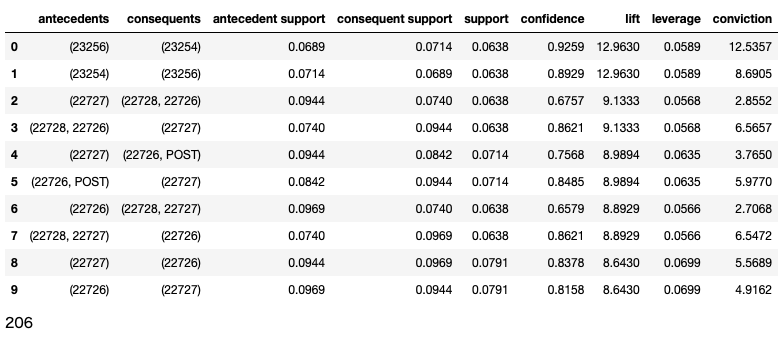
最後に抽出したリストに対して「リフト値」の高い関係を抽出します。
# アソシエーションルールの抽出
a_rules1 = association_rules(freq_items1, metric = "lift",
min_threshold = 1)
# リフト値でソート
a_rules1 = a_rules1.sort_values('lift',
ascending = False).reset_index(drop=True)
# 結果確認
display(a_rules1.head(10))
# ルール数確認
print(a_rules1.shape[0])
以下のリストが最終結果です。
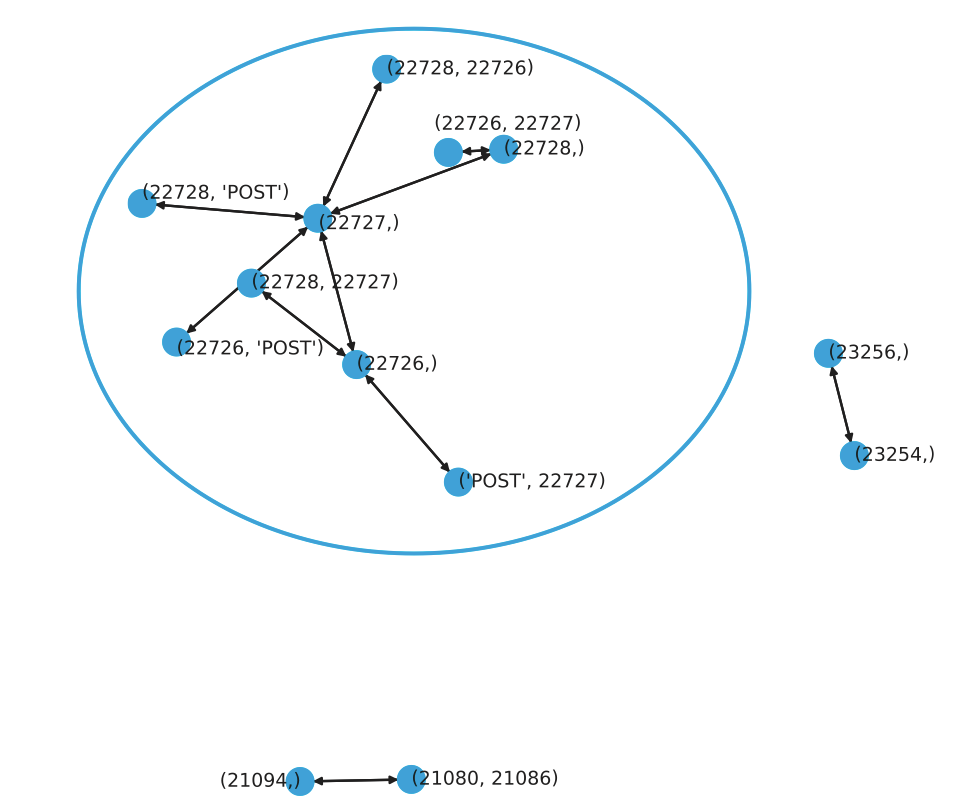
書籍の中では、上記の結果を元にNetworkXを使って下のような関係グラフを作ることもやっています。
なお、ここで出てきた技術用語である「サポート」「リフト値」については、書籍の中で解説しているので、そちらを参照して下さい。