はじめに
Watson StudioのModel Builderに関する記事は、今までにもいくつかあるのですが、自分が気付いたTipsを含めて、今までわかっていることをまとめるつもりで、この記事を投稿します。
(2020-04-25 追記)現在 Watson StudioではModel Builderは利用できません。代わりにAutoAIが利用できますので、そちらの機能を利用してください。
参考リンク AutoAIでお手軽機械学習(その1) 準備編
[2020-04-25] AutoAIの話を追記
そもそも機械学習とは
機械学習モデルは、学習方法によって「教師あり」「教師なし」「強化」の3つに大別されます。
最も挙動が単純で理解しやすいのが「教師あり」型です。
Model Builderで扱える対象も「教師あり」型に限定されているので、このタイプに限定して機械学習モデルの定義を行うと次のようになるかと思います。
- 原則1 入力データから出力データを予測するモデルである
- 原則2 「学習」によってモデルの構築を行う
この記事では公開データセットとして有名なアイリスデータセットを使って、予測モデルを作ります。
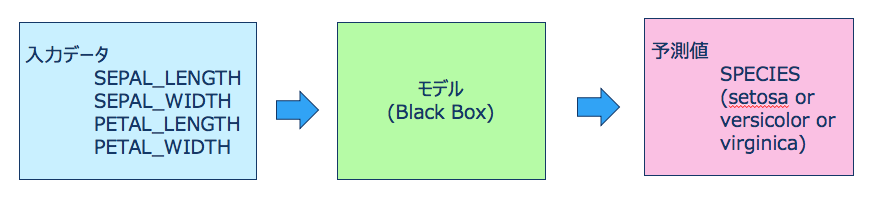
この場合、入力値は、4種類の花弁の長さ情報(SEPAL_LENGTH,SEPAL_WIDTH,PETAL_LENGTH,PETAL_WIDTH)です。
このデータを元に予測するのは、3種類のアヤメの花のうち、どの花に該当するか(SPECIES)となります。
図で示すと、次のような感じです。
原則2について少し補足すると、アイリスデータセットを人間が分析して、if then elseの組み合わせでこのような挙動をする機能(ブラックボックス)を作ることができるかもしれません。しかし、これを機械学習モデルとはいいません。それは分類の基準となる閾値の判断を人間が行ってしまっているからです。「分類を自動的に行う仕組みを持っている」ことが機械学習モデルの絶対条件で、これが原則2に該当することになります。
参考までにいろいろな機械学習モデルの中には、if then elseの組み合わせで分類する仕組みのものもあり、「Decision Tree」と呼ばれています。
教師あり型機械学習モデルも予測値の形態で2種類に分けることができます。
一つが上の例で示したように、どのグループに属するかという離散値情報を予測するもので、これは分類と呼ばれています。
もう一つが、数値を予測するタイプのものです。このタイプは回帰と呼ばれています。
分類は更にYes / Noの二値を分類するタイプのもの(スパムメール判定など)と、多値分類を行うものに分かれます。今回例で取り上げるモデルは、出力が3種類のアヤメの種別なので、多値分類に該当することになります。
入力データの準備
Model Builderではモデルの入力データとしてCSVファイルを利用します。
通常のデモシナリオでは、CSVデータはできあがっていて、このアップロードから操作が始まることが多いですが、実際に自分で試す場合は、CSVデータから作る必要があります。
そこで、CSVデータの作り方について少し解説を行います。
SEPAL_LENGTH,SEPAL_WIDTH,PETAL_LENGTH,PETAL_WIDTH,SPECIES
5.1,3.5,1.4,0.2,setosa
4.9,3.0,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
上記のものが、今回の記事で利用するCSVデータの頭の部分です。
見ていただければわかるとおり、次の特徴を持っています。
- 先頭の1行は、データではなく項目名
- 2行目以降のデータ部分は、シングルクオート、ダブルクオートはなく、単純なカンマ区切り
Model Builderでは、読み込んだCSVデータから、項目名称やデータの型などを自動判定します。この仕組みを利用するため、上のルールを守る必要があります。
例えば、データ型は自動判定なので、CSVデータの項目に一つでも異常値があると、誤った型判断をされてしまいます。これを防ぐためにはあらかじめCSVデータのクレンジングを行う必要があります。(Watson Studioの機能でいうとData Refineryがこれに該当します)
もう一点注意する必要があるのが、先頭の項目名の部分です。
将来改善される可能性はありますが、2018-07-22時点で項目名については日本語対応がされていません。そのため、項目名には英字を使う必要があります。更に、Webサービス化を行う場合には、項目名が英小文字だとうまくいかないようなので、英大文字を使うようにして下さい。
以降のガイドで使うCSVに関しては、事前に作成済みですので、ダウンロード先からダウンロードして使って下さい。
このiris.csvは、元々あった50件ずつ計150件のデータを5件ずつ取り除いて135件のデータになっています。取り除いた15件のデータは後で検証用に利用する想定です。検証用データ
環境の準備
IBM Cloudのアカウントがあり、Watson Studioのプロジェクトまでができている必要があります。この手順については、別記事10分でできるPython機械学習環境! Watson Studioセットアップガイドをアップしていますので、こちらを参照して下さい。
この記事の中で、以下の手順を実施する必要があります。Jupyter Notebook系の手順は不要です。
- ステップ0 IBM Cloudアカウント取得
- ステップ1 Watson Studioインスタンスを作る
- ステップ2 プロジェクトの作成
- Watson Machine Learningサービスの追加
CSVファイルのアップロード
プロジェクト管理の画面で「Assets」タブを表示します。
画面上部にある「Add to project」のリンクをクリックして「Data asset」を選択すると、下のように画面右にファイルアップロード用のウインドが表示されるので、ここに、事前にダウンロードしたiris.csvをドラッグアンドドロップします。
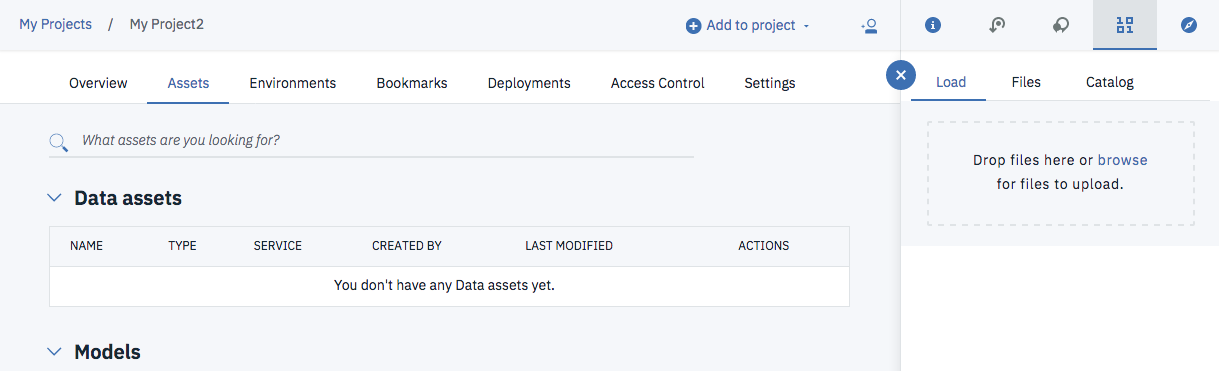
アップロードが正常に終わると、下の画面のようにData Assetsの欄にcsvファイルが追加されます。
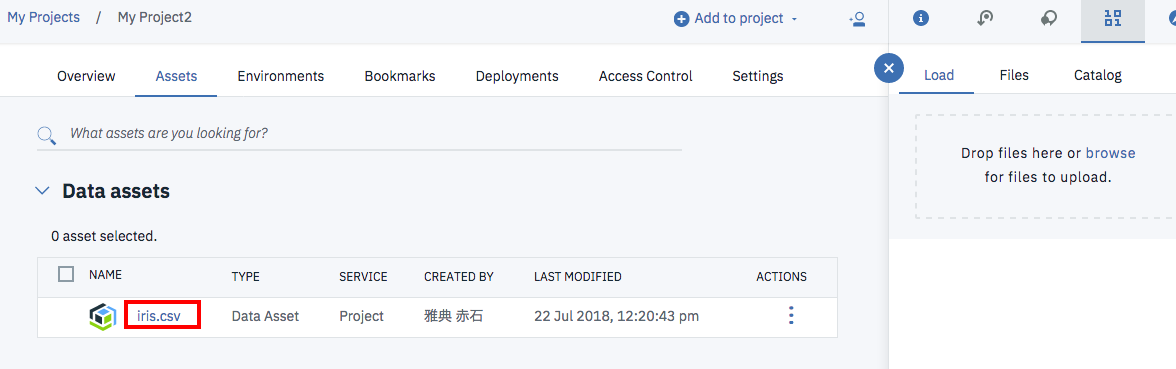
赤枠で囲まれたリンクをクリックすると、csvファイルの内容を確認できます。
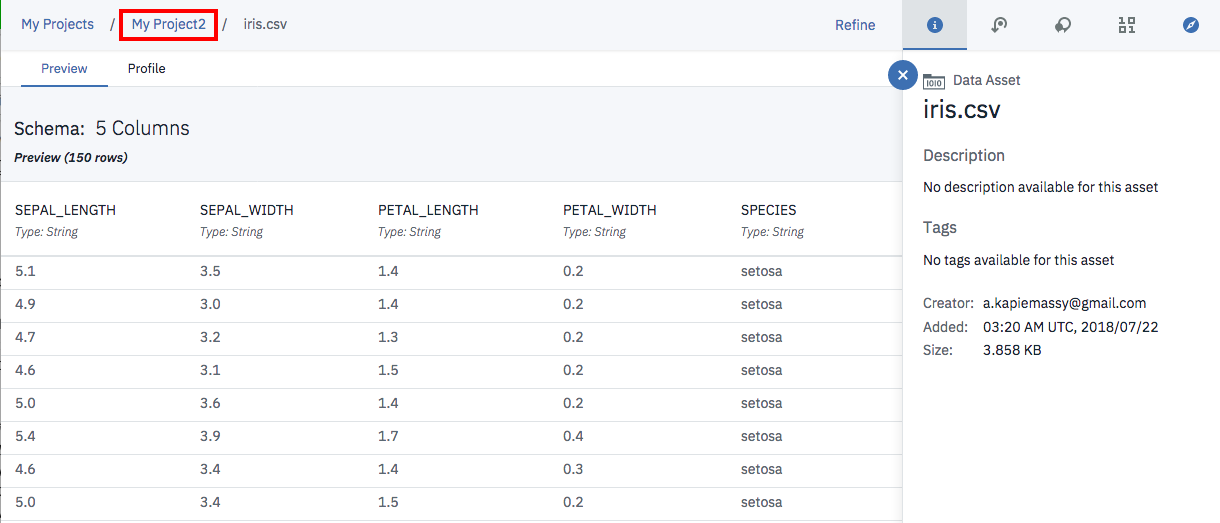
確認が終わったら、画面上部のプロジェクト名のリンクをクリックして、元の画面に戻ります。
以上で、CSVファイルのアップロードは完了です。
Model builderの起動からモデル作成、評価まで
データのアップロードが終わったら、Model Builderを起動します。そのためには、プロジェクト管理画面から「Add to project」->「Model」を選択して下さい。
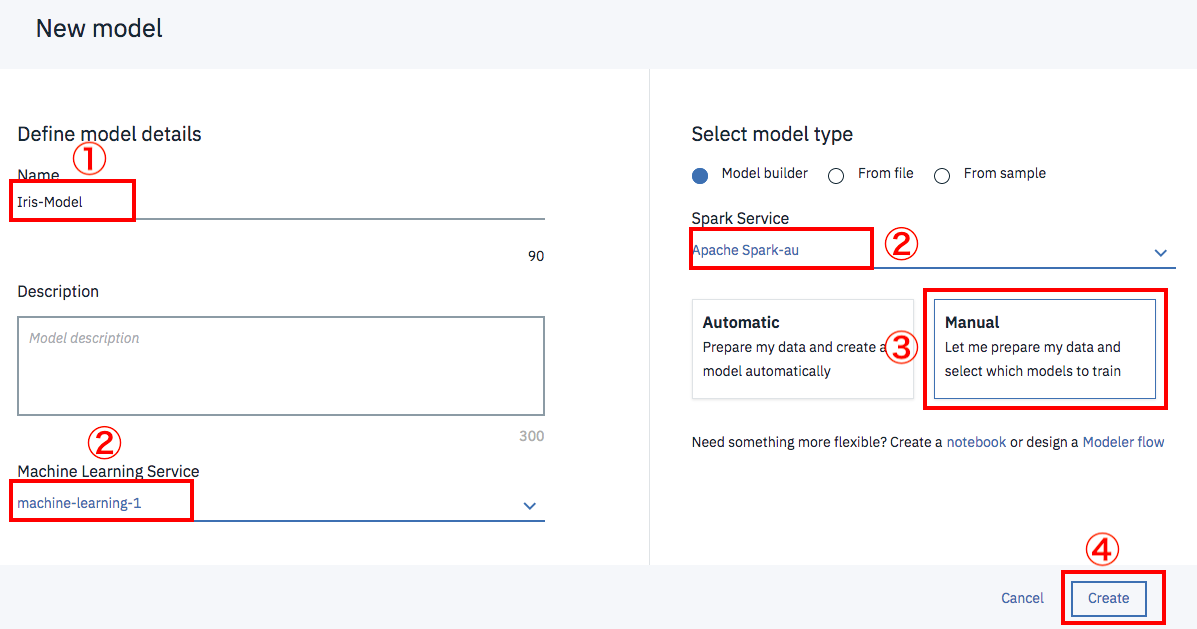
下が、新規モデル作成の画面です。次の操作を行って下さい。
① モデル名称 「Iris-Model」と入力します。
② 関連サービス 図のようにMachine LearningとSparkのサービスが選択された状態になっていることを確認して下さい。もし、こうなっていない場合は、必要に応じて新規サービスを作成し、関連づけの設定を行います。
③ 作成モード デフォルトの「Automatic」を「Manual」に変更します。
④ 以上の設定が全部終わったら、「Craete」ボタンをクリックします。
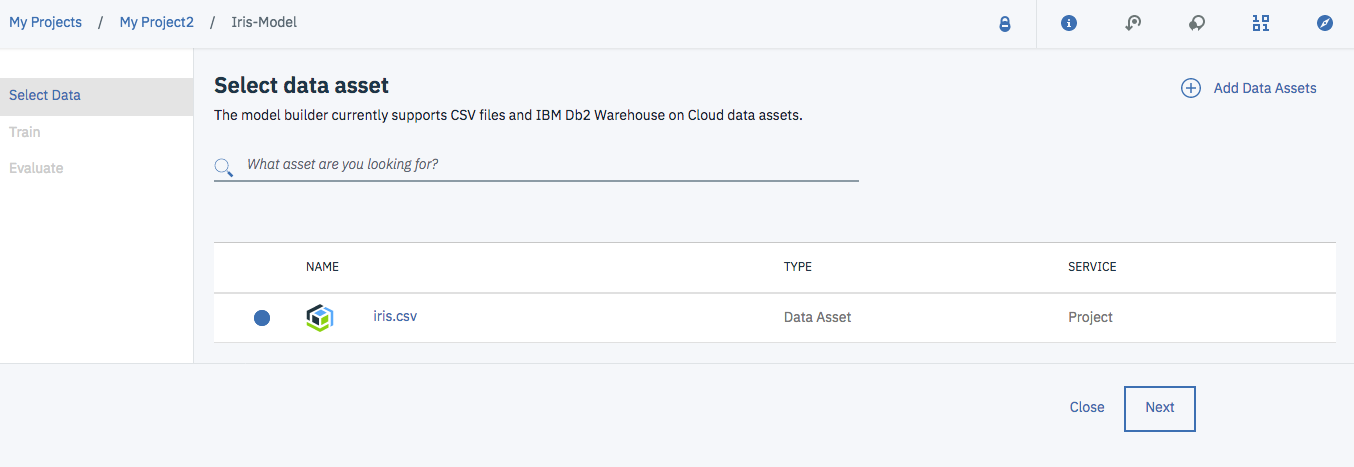
次のような「Select data asset」の画面になるので、「iris.csv」を選択して「Next」をクリックします。
データ解析が完了すると、次のような「Select a technique」の画面となります。
まず、画面左上の「Column value to predict (Label Col)」つまり目的変数を一番下のSPECIESにします。
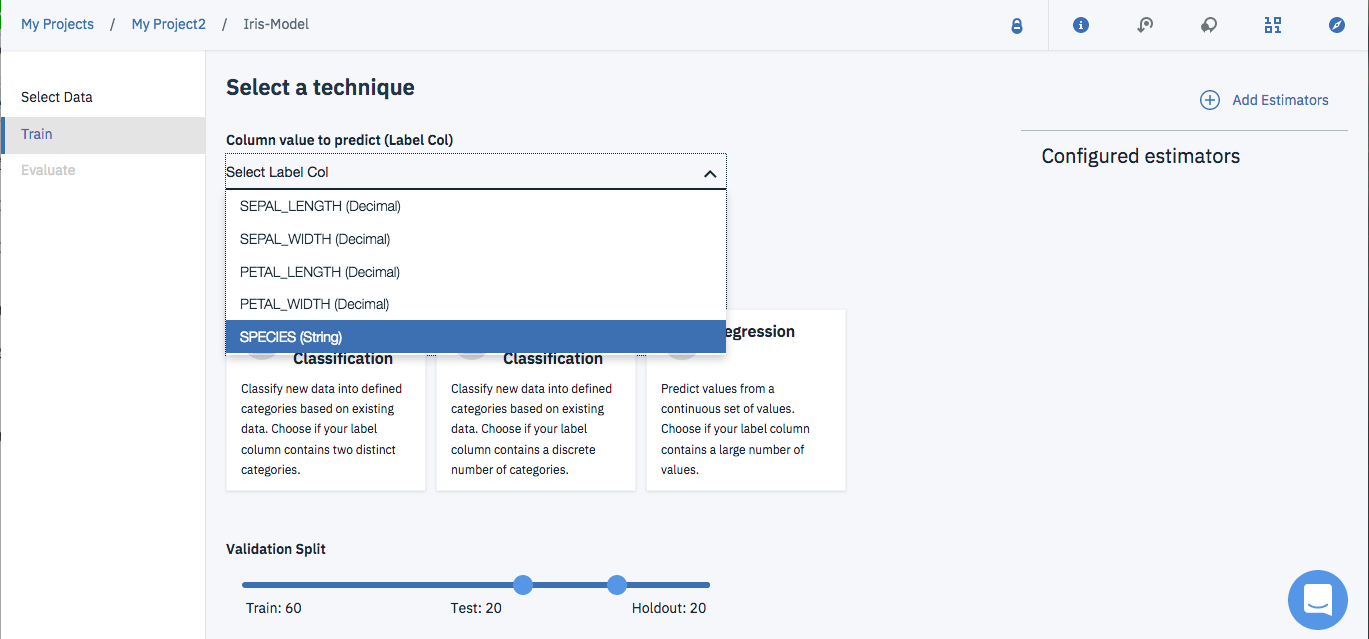
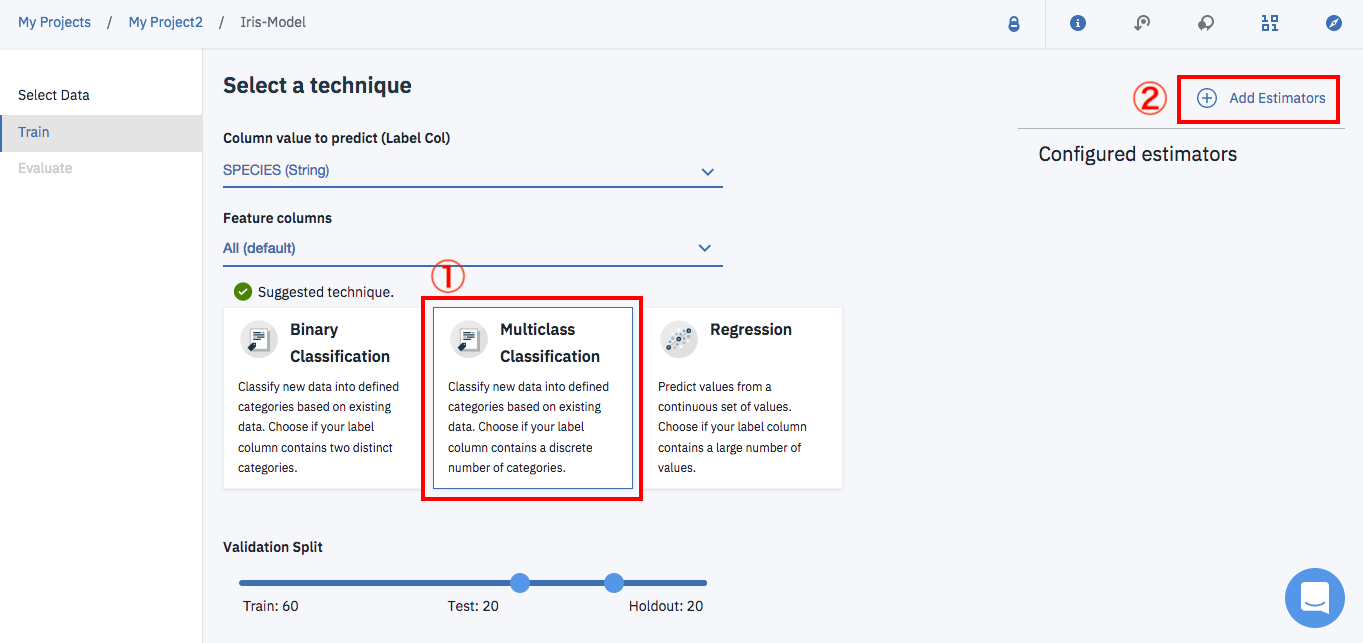
目的変数の設定が終わったら
①モデルの種類として「Multiclass Classification」を選択し、
②画面右の「Add Estimators」をクリックします
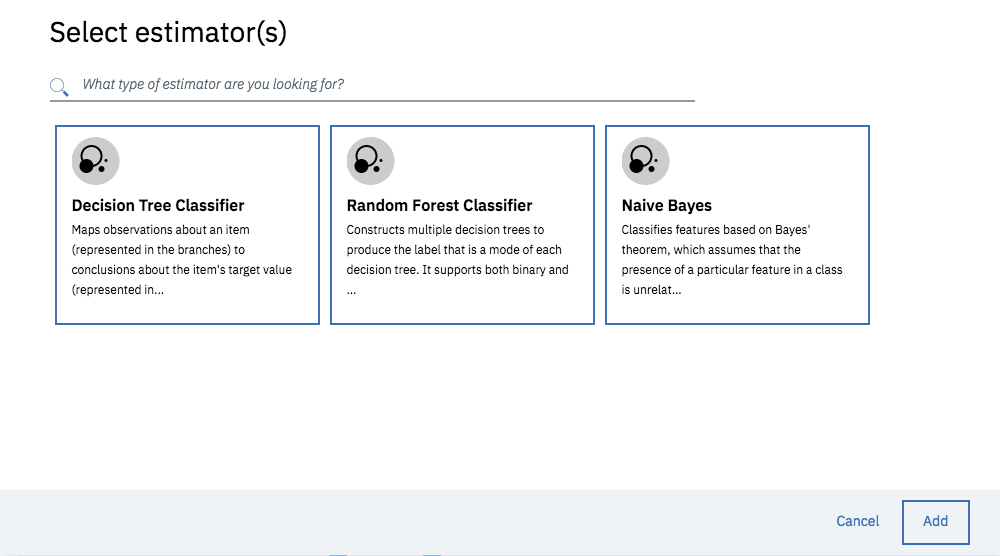
下のようなモデル選択の画面がでたら、すべて選択して、「Add」をクリックします。
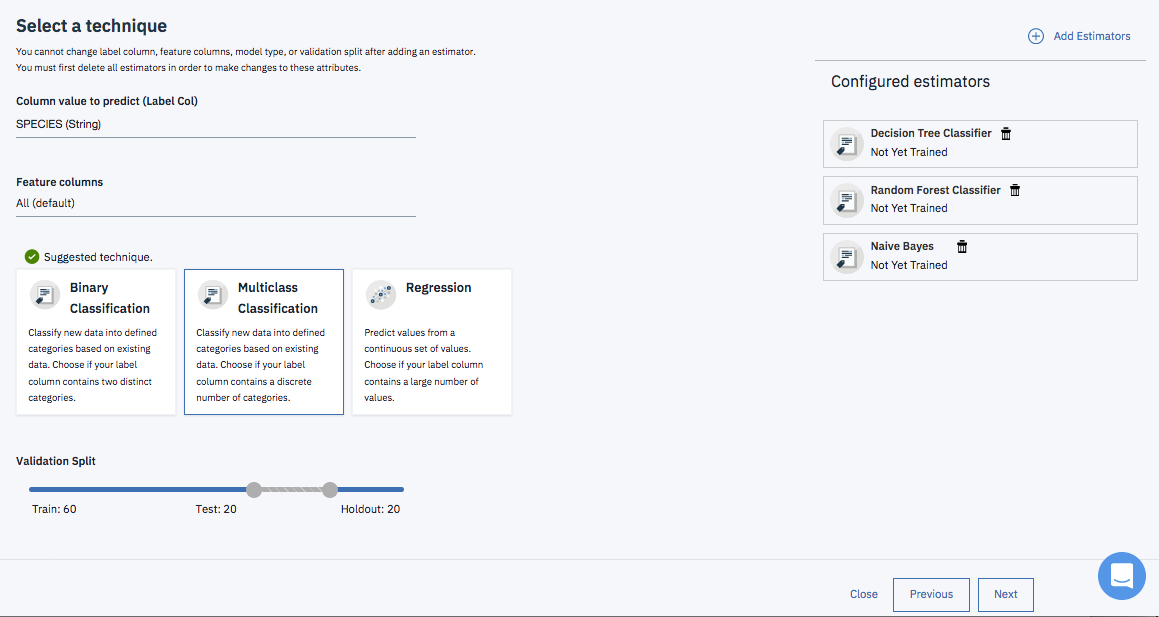
下の画面が、必要な設定が全部終わった状態です。
Feature columns(入力項目)とValidation Splits(学習用、評価用のデータ分割)はデフォルト設定のままとしています。
この状態で、画面右下の「Next」をクリックすると学習が開始されます。
下記が学習開始直後の画面です。

すべて学習が終わると下のようになります。(学習データ分割に乱数を使っているので、いつも同じ数値にはなりません)
今回は、DecisionTreeClssifierが一番精度がよかったようです。
この分類器を選択し(動作に不安定なところがあるので、いったん別の項目を選択後、再度選択するようにして下さい)、画面右下の「Save」をクリックします。
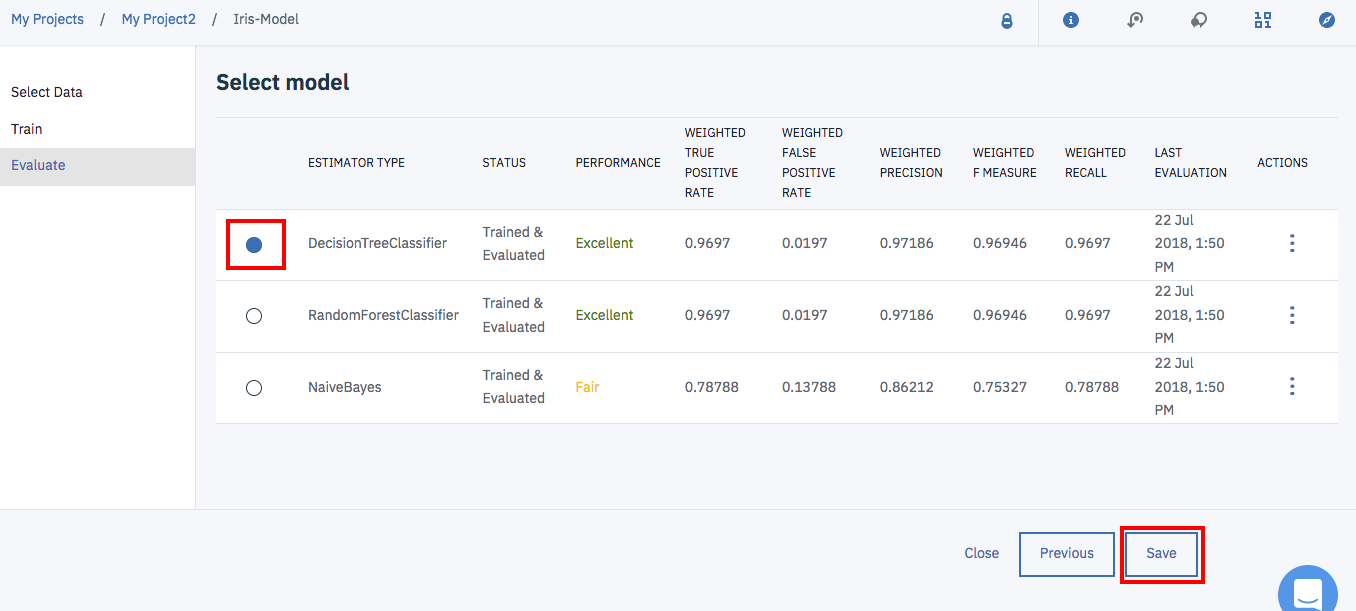
下のようなパネルが出たら、「Save」をクリックします。
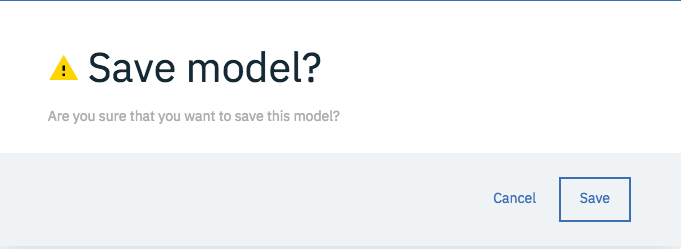
しばらくすると、下のような画面が表示されます。
これで、モデル作成、学習、評価、モデルのリポジトリへの保存がすべて完了しました。
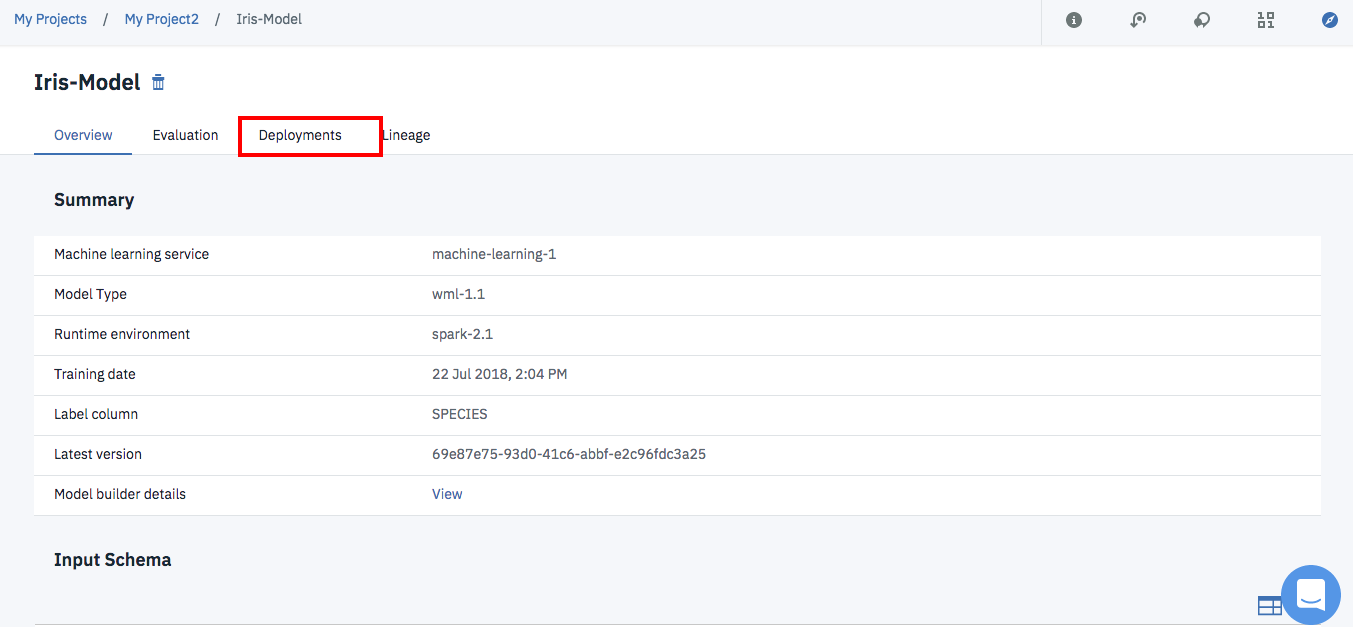
モデルのWebサービス化
上記の画面で「Deployments」タブをクリックします。
次の画面で「Add Deployment」のリンクをクリックします。
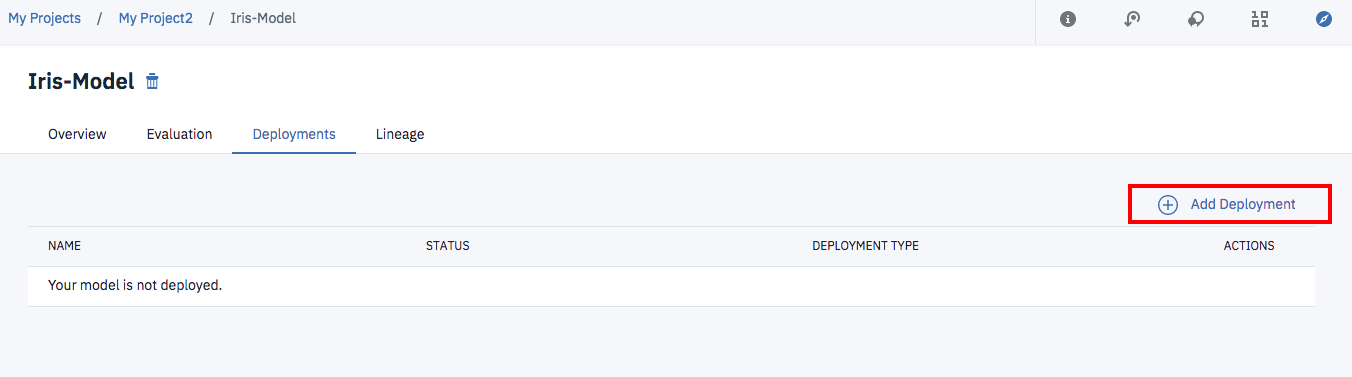
名称を「Iris-Web」として「Save」をクリックします。
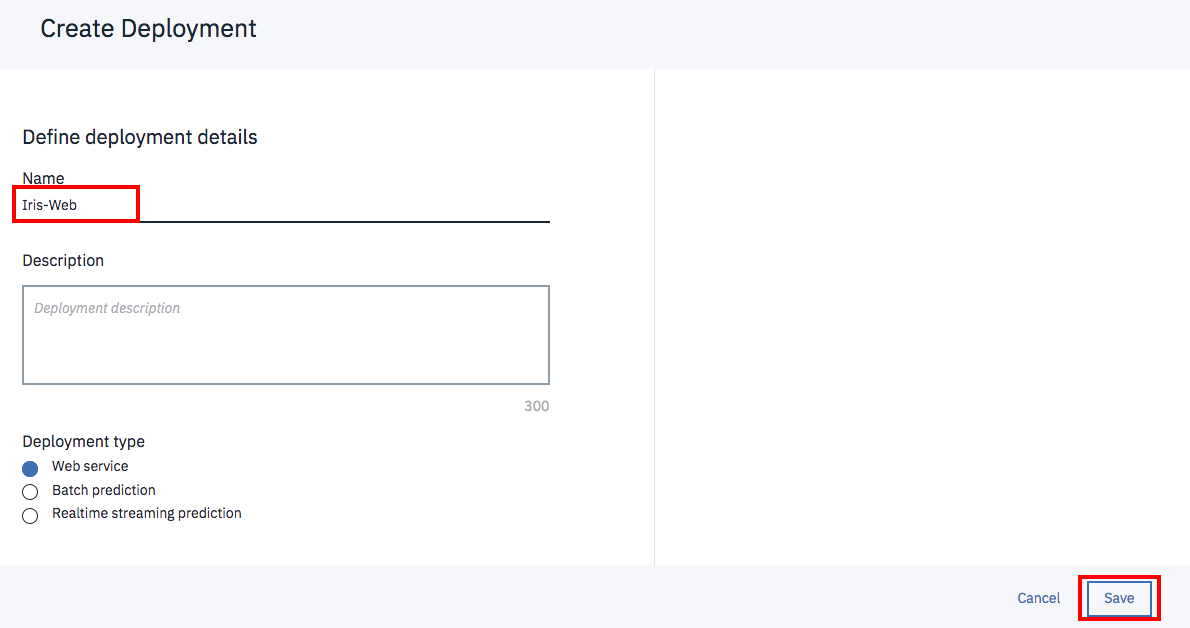
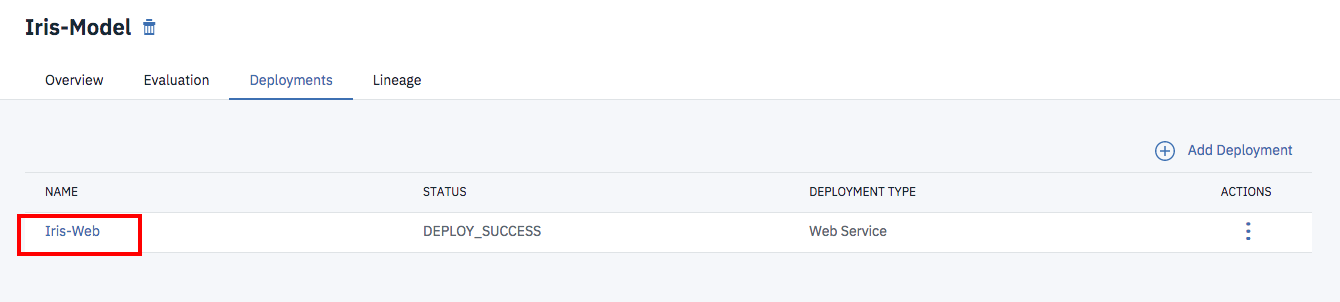
Statusが「DEPLOY_SUCCESS」になったらWebサービス化は完了しています。
作成したWebサービスの確認のため、赤枠のリンクをクリックします。
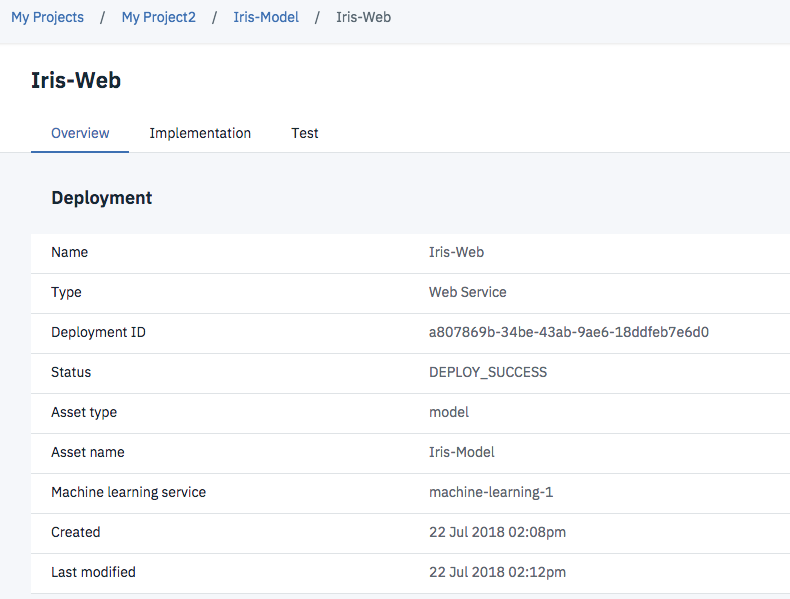
下のようなWebサービスの管理画面になるので、「Test」のタブをクリックします。
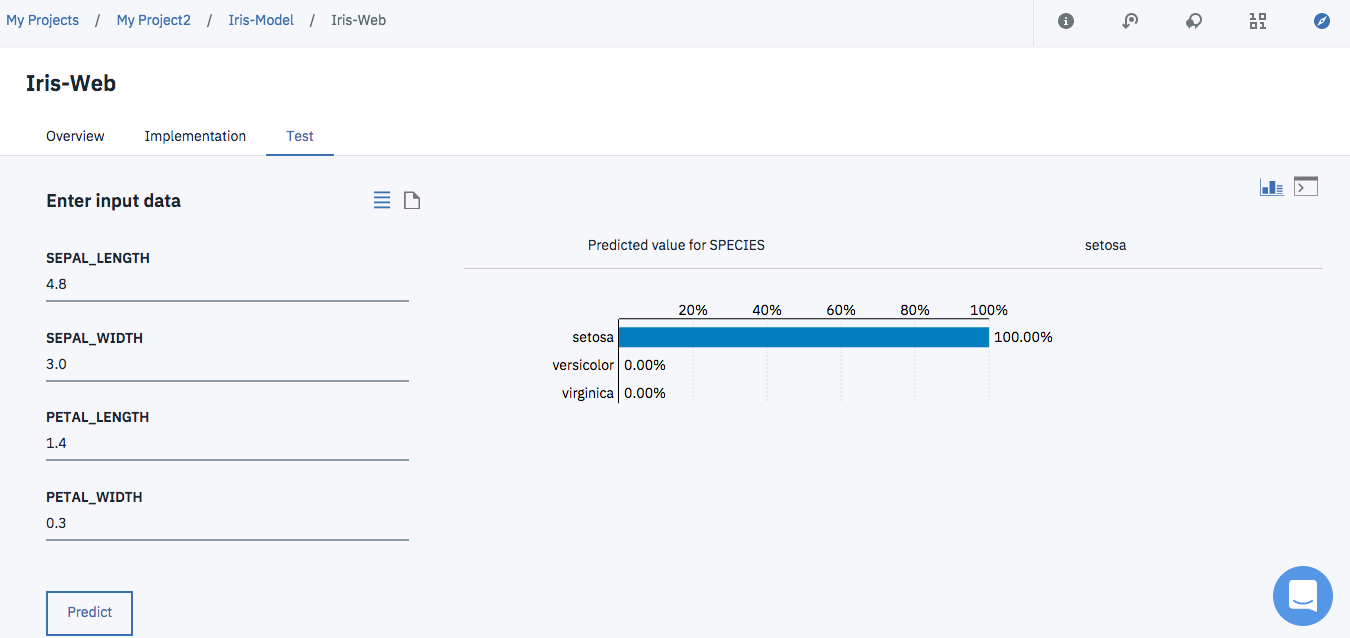
iris-test.csvからダウンロード可能な検証データを使って予測を行ってみます。
入力パラメータをすべて入れて、「Predict」ボタンをクリックすると、下の図のように予測結果が表示されます。
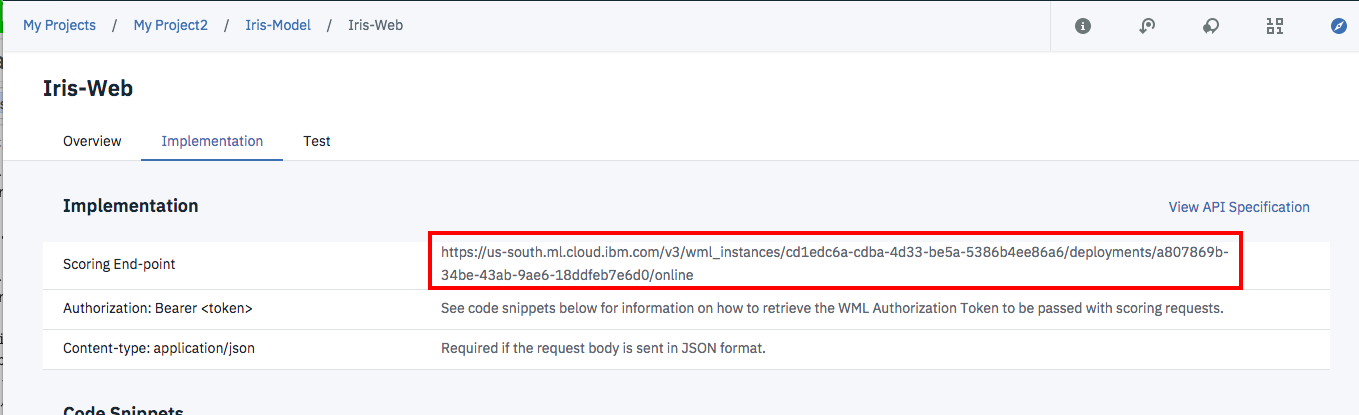
最後にImplementationタブを表示して、下の図の赤枠で囲んだ「Scoring End Point」のURLをコピーし、エディタなどに保存します。このURLは次の「アプリケーションのデプロイ」で必要になります。
アプリケーションのデプロイ
最後にこのモデルをWebアプリケーションから呼び出すためのサンプルアプリケーションを作ってみます。
ソースコードはGithubにあります。
git clone https://github.com/makaishi2/wml-iris-sample.gitとするか、あるいはWeb画面からzipファイルをダウンロード後、解凍して下さい。
解凍後にそのディレクトリにcdします。
その後で、以下のコマンドでデプロイを行って下さい。
cfコマンドが使えることが前提なので、まだの人はCloud Foundryからダウンロード、導入して下さい。
ダウンロード後には、次のコマンドでログインまで行います。
$ cf api https://api.ng.bluemix.net
$ cf login
以下のデプロイ用コマンド例では、
アプリケーション名: wml-iris-xxx
Watson ML サービス名: machine-learing-1
Scoring URL: xxxx
を前提としています。
実際の環境に応じてそれぞれのコマンド引数を変更して下さい。
Watson MLサービス名に関しては、
$cf s
でサービス名一覧を表示して確認します。
(サービス名 = pm-20となっているサービスの「名称」)
名称にブランクを含んでいる場合は、"Machine Learing-ae"のようにダブルクオートで囲む必要があります。
$ cf push wml-iris-xxx
$ cf bs wml-iris-xxx machine-learing-1
$ cf se wml-iris-xxx SCORING_URL xxxx
$ cf rg wml-iris-xxx
デプロイが正常に完了したら、
$ cf a
コマンドでデプロイしたアプリケーションのURLがわかるので、そのURLをブラウザから入力して下さい。
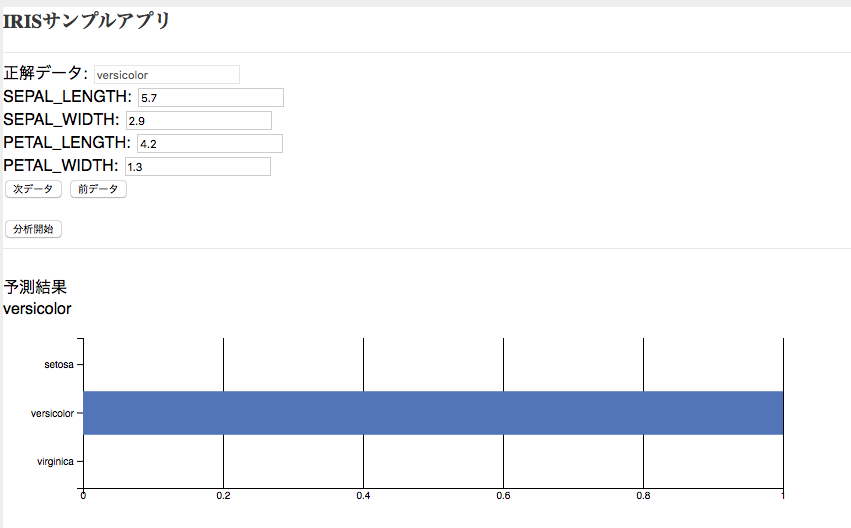
うまくいくと下のような画面が立ち上がります。
冒頭で紹介した、オリジナルデータのうち検証用にリザーブした15件のデータが、「次データ」「前データ」のボタンをクリックすると順に表示されるようになっています。
「分析開始」ボタンをクリックすると、そのデータに対する機械学習モデルの予測結果が返されます。15ケースそれぞれに対して正解がかえってくるかどうか、試してみて下さい。