gensimのライブラリを使うと、Word2Vecを使うことは恐ろしく簡単です。
(パラメータのチューニングは別にしてとにかく使ってみるという目的であれば)
しかし、日本語を対象にする場合、形態素解析をしないといけないというハードルがあり、それがWord2Vecを使いにくいものにしている気がしています。
以下で説明する手順は、このことを考慮して、「最短コースで日本語Word2Vecを使う」という目的に注力して作ってみました。
【変更履歴】
(2019-08-11)
前提の動作環境を修正。
ファイル読込みに関して!pipをやめて、全部python APIを使うように変更しました。
(2018-07-13)
IBM DSX -> Watson Studioに変更になり、それに伴ってPythonがV3になったため、Python V3対応をしました。
(2018-02-12 追加)
Jupyter notebookをGithubにアップしたので、その使い方を最後に追記しました。
(2018-01-08全面改定)
・青空文庫からのダウンロードも!コマンドに含めてここに書いてあるコマンドだけですべて実行できるようにした。
・上の変更に伴い対象文書は「三四郎」一つに減らした。
・Word2Vecのパラメータの解説追加。Iterパラメータが重要なことがわかったので、その使い方のポイントも記載。
前提
解析元データ
青空文庫のデータ。
夏目漱石の小説「三四郎」を使っています。
URLをかえれば他の小説に差し替えることも可能です。
動作環境
次の2つの環境で動作確認しています。
Watson Studio + Jupyter Notebook + Python (3.6)
MAC anaconda + jupyter notebook + Python (3.7)
コードは可能な限りプラットフォームに依存しない形にしていますので、動作テストはしていませんが、Windowsのanaconda等でも動くと思います。
コード解説
ここから先はJupyter notebook上のスクリプトになります。
形態素解析は一番簡単に導入できるjanomeを使っています。
コードの全体は次のリンクから確認できます。
(備考1) 学習データの作成は、Text8Corpus 関数を使っているサンプルがほとんどですが、オリジナルのAPIリファレンスを読んで、配列の配列でよさそうなことがわかったのでその形で実装しています。
これでコードがシンプルになったかと思います。
STEP1
青空文庫より「三四郎」をダウンロードし整形するまで
# zipファイルダウンロード
url = 'https://www.aozora.gr.jp/cards/000148/files/794_ruby_4237.zip'
zip = '794_ruby_4237.zip'
import urllib.request
urllib.request.urlretrieve(url, zip)
# ダウンロードしたzipの解凍
import zipfile
with zipfile.ZipFile(zip, 'r') as myzip:
myzip.extractall()
# 解凍後のファイルからデータ読み込み
for myfile in myzip.infolist():
# 解凍後ファイル名取得
filename = myfile.filename
# ファイルオープン時にencodingを指定してsjisの変換をする
with open(filename, encoding='sjis') as file:
text = file.read()
# ファイル整形
import re
# ヘッダ部分の除去
text = re.split('\-{5,}',text)[2]
# フッタ部分の除去
text = re.split('底本:',text)[0]
# | の除去
text = text.replace('|', '')
# ルビの削除
text = re.sub('《.+?》', '', text)
# 入力注の削除
text = re.sub('[#.+?]', '',text)
# 空行の削除
text = re.sub('\n\n', '\n', text)
text = re.sub('\r', '', text)
# 整形結果確認
# 頭の100文字の表示
print(text[:100])
# 見やすくするため、空行
print()
print()
# 後ろの100文字の表示
print(text[-100:])
うまくいくと、下記のように「三四郎」の冒頭と最後の部分がprint文で表示されるはずです。
一
うとうととして目がさめると女はいつのまにか、隣のじいさんと話を始めている。このじいさんはたしかに前の前の駅から乗ったいなか者である。発車まぎわに頓狂な声を出して駆け込んで来て、いきなり肌を
取りかかる。与次郎だけが三四郎のそばへ来た。
「どうだ森の女は」
「森の女という題が悪い」
「じゃ、なんとすればよいんだ」
三四郎はなんとも答えなかった。ただ口の中で迷羊、迷羊と繰り返した。
STEP2
Janomeを使い三四郎テキストから単語リストを生成
# Janomeのインストール
!pip install janome | tail -n 1
# Janomeのロード
from janome.tokenizer import Tokenizer
# Tokenizerインスタンスの生成
t = Tokenizer()
# テキストを引数として、形態素解析の結果、名詞・動詞・形容詞(原形)のみを配列で抽出する関数を定義
def extract_words(text):
tokens = t.tokenize(text)
return [token.base_form for token in tokens
if token.part_of_speech.split(',')[0] in['名詞', '動詞']]
# 関数テスト
# ret = extract_words('三四郎は京都でちょっと用があって降りたついでに。')
# for word in ret:
# print(word)
# 全体のテキストを句点('。')で区切った配列にする。
sentences = text.split('。')
# それぞれの文章を単語リストに変換(処理に数分かかります)
word_list = [extract_words(sentence) for sentence in sentences]
# 結果の一部を確認
for word in word_list[0]:
print(word)
最後のprint文の結果は下記のようになります。
一
する
目
さめる
女
隣
じいさん
話
始める
いる
STEP3
準備したデータを用いてWord2Vecのモデル作成、学習実施
# Word2Vecライブラリの導入
!pip install gensim
# Word2Vecライブラリのロード
from gensim.models import word2vec
# size: 圧縮次元数
# min_count: 出現頻度の低いものをカットする
# window: 前後の単語を拾う際の窓の広さを決める
# iter: 機械学習の繰り返し回数(デフォルト:5)十分学習できていないときにこの値を調整する
# model.wv.most_similarの結果が1に近いものばかりで、model.dict['wv']のベクトル値が小さい値ばかりの
# ときは、学習回数が少ないと考えられます。
# その場合、iterの値を大きくして、再度学習を行います。
# 事前準備したword_listを使ってWord2Vecの学習実施
model = word2vec.Word2Vec(word_list, size=100,min_count=5,window=5,iter=100)
学習が終わったら、下記のコマンドを実行して、ベクトルの値を確認します。
各要素の値が0に近いものばかりの場合は学習不足なので、繰り返し回数を多くして学習量を増やします。
# 結果の確認1
# 一つ一つの単語は100次元のベクトルになっています。
# 「世間」のベクトル値を確認します。
print(model.__dict__['wv']['世間'])
出力例
[-0.88293612 -0.3013185 -0.35126361 0.60957962 0.00221068 -0.14672852
0.34758356 0.3130497 -0.26381639 0.01039159 0.74854016 0.22990224
0.53207207 0.35894531 -0.18870777 -0.14299707 -0.17026021 -0.39226729
-0.55686295 -1.03862309 0.34342393 -0.38474649 0.22264372 0.2148834
-0.57690299 0.50958228 0.21316393 -0.45058063 -0.01531385 0.21411817
-0.13765882 0.36555257 0.18961851 0.30552268 0.28690419 0.44103289
0.3616772 -0.08265762 0.23465481 0.64508522 0.10984603 -0.18975797
-0.62102526 0.34013692 -0.21108685 0.67358649 -0.05548109 0.71970463
0.15951402 -0.20287114 0.22480334 -0.1657704 0.14321537 -0.83973724
0.16383708 -0.0184148 0.0983168 0.68461138 -0.6305806 -0.15764654
0.34798717 0.70214379 0.81783944 -0.1100878 -0.10086756 0.17223099
-0.22010259 0.09154502 -0.24891852 -1.10598886 0.25330281 0.80425018
-0.1590014 -0.61868459 0.48295951 0.44533521 0.06305817 0.06332487
-0.28006056 -0.18927498 0.01776602 -1.24161541 0.02164695 -0.32259813
-0.04557931 0.28612074 -0.65266812 0.70790166 0.0689275 0.02587064
-0.10913479 0.00144786 -0.39569286 -0.35063615 0.00839228 -0.51497662
0.14879608 -0.16675428 0.51165235 0.60493296]
学習の終わったモデルの使い方については、いろいろなところに解説があるのでそちらを見ていただきたいですが、一つの例として下記のような類似単語を調べることができます。
# 結果の確認2
# 関数most_similarを使って「世間」の類似単語を調べます
ret = model.wv.most_similar(positive=['世間'])
for item in ret:
print(item[0], item[1])
結果サンプル (学習に乱数を使っているので、同じ結果にはなりません)
喝采 0.537174940109
聞こえる 0.535886764526
自己 0.532948195934
外国 0.522415161133
堪える 0.479213744402
文学 0.46687990427
賛成 0.466347366571
決心 0.464796662331
喜ぶ 0.456098258495
社会 0.453751981258
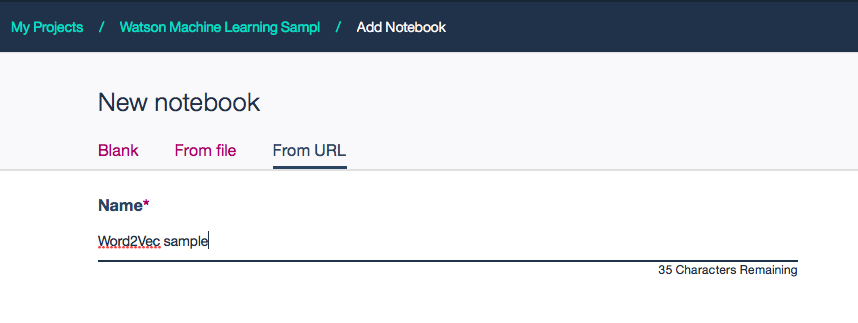
Jupyter Notebookの利用
上記のコマンドをすべて記載したJupyter NotebookをGithubにアップしておきました。
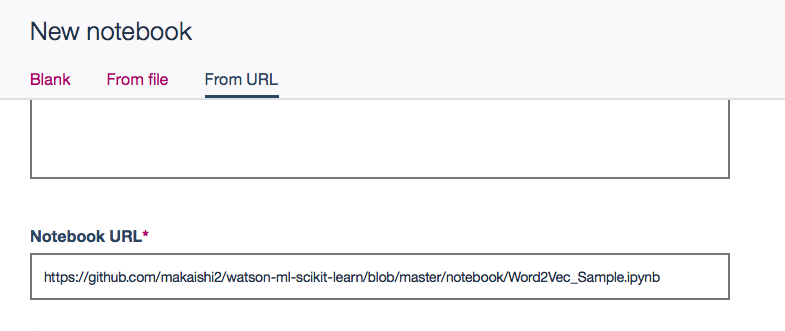
Watson Studioの環境から「Create Notebook」-> 「From URL」
Name: (適当な名前)
Notebook URL: https://raw.githubusercontent.com/makaishi2/sample-data/master/notebooks/word2vec.ipynb
を指定すると、すぐに上のコマンドを試すことが可能です。
関連リンク
【マメ知識】青空文庫からテキスト解析用のプレーンテキストを入手
【マメ知識】(改訂版)青空文庫テキストからテキスト解析用の名詞リストを作成する