はじめに
Watson Studioの特徴はいろいろとあり、一言ではいえません。
しかし、従来からPython - Jupyternotebookを使ってscikit-learningによる機械学習モデルを利用していたユーザーにとってのメリットは何かといえば、sckit-learningで学習した機械学習モデルを、クラウド上にアップしてWebサービスとして簡単に使えるようになる点です。
Watson StudioのJupyter Notebook上で作ったscikit-learn機械学習モデルをデプロイし、Webサービス化する手順を簡単に解説します。
[2021-01-11] 過去の情報がほとんど役に立たなくなっているので、ゼロから全面的に書き直しました。
モデルの説明
(ここも改訂しました)
Iris Datasetを学習データとして、scikit-learnのライブラリのうちRandom Forestをアルゴリズムとしたモデルを使いました。
Python 3.7 scikit-learn 0.23.1 という比較的新しいバージョン(2021-01-11時点のクラウドのWatson Studioのデフォルト)環境を利用しています。
1. 前提
1.1 環境の前提
IBM Cloud上で、Watson Studioのインスタンスとプロジェクトは作成済みであることを前提とします。まだの場合は、下記記事を参考にプロジェクト作成まで済ませて下さい。
無料でなんでも試せる! Watson Studioセットアップガイド
また、デプロイメントスペースの作成と、デプロイメントスペースへのWatson MLインスタンスの関連付けも必要です。
これらの手順については、下記リンク先を参照して下さい。
ちなみに、デプロイメントスペースとは、下の図のようにWatson Machine Learningと紐付く実行環境用の作業スペースのことです。Watson ML v2になって新たに導入された概念です。以下の実習の中で重要な意味を持ちますので、下の図のイメージとともにしっかり理解するようにして下さい。
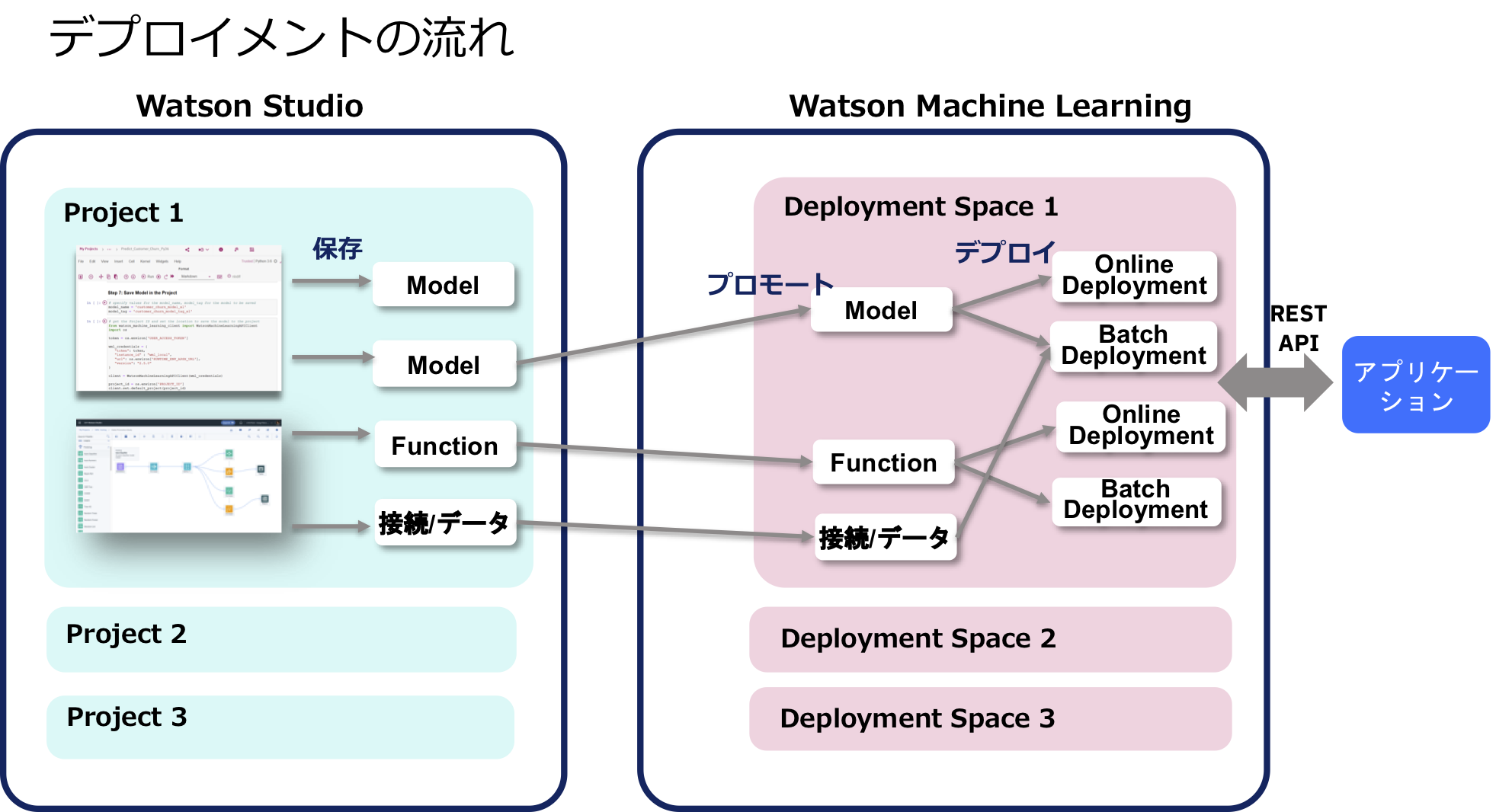
ただし、以下の実習では上の図と一カ所異なる部分があります。AutoAIやSPSS Modeler Flowといったツールを利用する場合、いったんプロジェクト用にモデルを「保存」し、そのコピーをデプロイメントスペースに作る(「プロモート」と呼ぶ操作)形になります。
これからの手順では、Jupyter Notebook上に作ったモデルは、いきなりデプロイメントスペースに保存します。その先のデプロイに関しては同じ手順になります。
1.2 サンプルノートブックの読み込み
以下で説明するNotebookは、githubにアップしてあります。
URLは下記になります。
Watson Studioのプロジェクト管理の画面から、このNotebookを読み込むための手順は次のとおりです。
「プロジェクトに追加」から下の画面で「Notebook」を選択

下のNotebook新規作成の画面になったら
① 「URLから」のタブ選択
② 名前に「Watson ML scikit-learn」と入力 (ここはなんでもいいです)
③ URLに以下のURLをコピペして入力
https://raw.githubusercontent.com/makaishi2/sample-data/master/notebooks/Watson%20ML%20scikit-learn.ipynb
④ 画面右下の「作成」ボタンをクリック

しばらく待って、正常にnotenook作成が終了すると、下のような画面になるはずです。

このNotebookは冒頭に目次があり、Notebookでの手順全体がわかるようになっています。また、各項目をクリックすると、Notbookの該当部分にジャンプできます。
1.3 API Keyの取得
このNotenookを動かす前に準備として必要なのは、API Keyの取得です。少し前のWatson Machine Learningでは、API Keyはインスタンスの管理画面から「資格情報」として取得していましたが、以下は、手順が変わり、下記のリンクで生成したAPIキーがIBM Cloud上のどのインスタンスからも使えるようになりました。API Keyを未取得の場合は、下記のリンクから生成して、結果はテキストエディタなどに保存しておきます。
これで、必要な事前準備はすべて終わりました。あとは、Notebookのガイドに従ってセルを順に実行していきます。
以下は、Notenookの目次に沿った説明となります。
2. データロードと学習
2章ではデプロイの対象となるscikit-learnのモデルを作成します。当記事は、モデルの作り方が目的ではないので、モデル作成はサンプルデータ(iris dataset)を用いた必要最小限の方法となります。
2.0 バージョンの確認
下のセルを実行し、Notebookの環境のバージョンを確認します。
import sys
print('Python: ', sys.version)
import sklearn
print('scikit-learn: ', sklearn.__version__)
2021-01-11の時点では、次のような結果でした。
Python: 3.7.9 (default, Aug 31 2020, 12:42:55)
[GCC 7.3.0]
scikit-learn: 0.23.1
もし、Pythonのバージョンが3.8以上、あるいはscikit-learnのバージョンが0.24以上になった場合、下記の手順でうまくいかなくなる箇所があり、見直しが必要なはずです。(具体的には3.3のところ)
2.1 データのロード
次の2つのセルを実行します。特別なことはしていないので、解説は省略します。
# IRIS Dataset を利用する
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
Y = iris.target
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,train_size=0.7, random_state=99)
# 学習データの先頭10行
print(X_test[:10])
print(Y_test[:10])
2つめのセルの実行結果は、下のようになるはずです。
[[6.9 3.1 5.4 2.1]
[4.4 2.9 1.4 0.2]
[6.4 2.9 4.3 1.3]
[6.9 3.2 5.7 2.3]
[5. 3.6 1.4 0.2]
[5.5 2.5 4. 1.3]
[6. 2.9 4.5 1.5]
[6.7 2.5 5.8 1.8]
[4.8 3.4 1.9 0.2]
[5.9 3.2 4.8 1.8]]
[2 0 1 2 0 1 1 2 0 1]
2.2 学習
ここも特別なことはしていないので、解説はしません。学習済みモデルはmodelという変数に保存されます。
# アルゴリズムはRandom Forestを利用
# 作成後のモデルインスタンス変数名はmodel
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
model = clf.fit(X_train, Y_train)
3. モデルの保存
ここからがWatson Machine Learning固有の話になります。
3.1 必要ライブラリの導入
最初に必要なライブラリであるibm-watson-machine-learningを導入します。
念のため最新版を入れる目的で、-Uオプションを追加しています。
# 必要ライブラリの導入
!pip install -U ibm-watson-machine-learning | tail -n 1
結果については省略します。
3.2 APIClient インスタンスの生成とデプロイメントスペースの関連付け
下に示した 3.2の最初のセルが設定の必要な箇所となります。
まず、locationという変数には、Watson Machine Learingをどのサイトで作ったかによって変更します。
ダラスに作った場合がデフォルトの状態でOKです。
東京に作った場合は、'jp-tok'に変更して下さい。
apikeyに関しては、1.3の手順で説明した値を設定します。
# ロケーションの指定
# ロケーションは下記のコマンドの結果得られたものを使う
#
# $ ibmcloud resource service-instance
location = 'us-south' # Dallas
# location = 'jp-tok' # Tokyo
# location = 'au-syd' # Sydney
# APIKeyの指定
# API key は次のリンク先から生成する
#
# https://cloud.ibm.com/iam/apikeys
apikey = "xxxx"
wml_credentials = {
"apikey": apikey,
"url": 'https://' + location + '.ml.cloud.ibm.com'
}
設定が正しい場合は、次のセルの実行結果が正常終了します。(結果は何も表示されない)
エラーがでた場合は、locationかapikeyの値が正しくないはずですので、調べて下さい。
# API Clientインスタンスの生成
from ibm_watson_machine_learning import APIClient
client = APIClient(wml_credentials)
上の実行が正常に終わった場合、次のセルも実行して、デプロイメントスペースのスペースIDを調べます。
# space_idの取得
client.spaces.list()
下のような結果が返ってくればOKです。そうでない場合は、事前準備としてガイドしたデプロイメントスペースの作成ができていない可能性がありますので、その手順を見直して下さい。
Note: 'limit' is not provided. Only first 50 records will be displayed if the number of records exceed 50
------------------------------------ ------- ------------------------
ID NAME CREATED
9336c80e-574d-442c-a031-90765b925770 space01 2020-11-28T11:37:15.555Z
------------------------------------ ------- ------------------------
上の結果を基に、次のようにspace_idを手で設定します。
余談ですが、こんな設定はAPIでできそうなのですが、何度API Referenceをみてもidをきれいに取得する関数がみつからず、こんな回りくどいことをうやっています。
# 上の結果を基に手で設定する
space_id = '9336c80e-574d-442c-a031-90765b925770'
設定が終わったら、その次のセルを実行して下さい。
# デプロイメントスペースIDの設定
client.set.default_space(space_id)
このセルの実行結果が下のように「SUCCESS」となればOKです。
'SUCCESS'
3.3 Software Specification ID の取得
次のステップが、Matson MLへのデプロイに際して最大の難関である、Software Specification IDの取得です。
登録用の関数の引数に、わけのわからないIDを指定する必用があり、ID取得のために別の関数を呼び出すことが必要です。
どう考えても、関数のインターフェイス仕様を間違えている気がするのですが、以下はこの手順に従うしかないので、そのように理解して下さい。
どのフレームワークを使うときに、どういう名称でIDを引けばいいかのリストは下記リンク先にあります。
リンク先の表の一部は画面コピーもつけておきます。
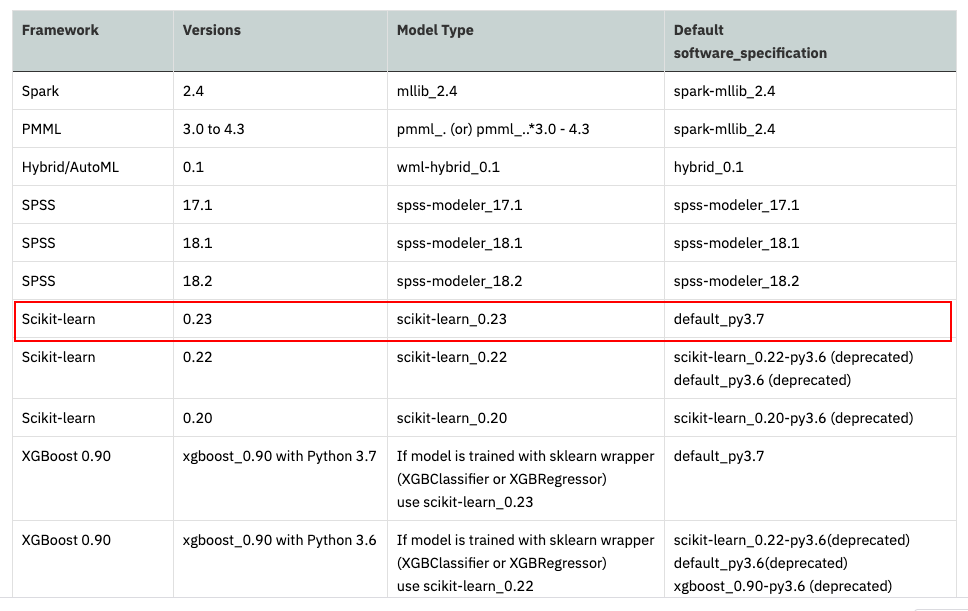
赤枠で囲んだ行が今回のモデルに該当するものであることがわかります。名前はdefalut_py3.7となっています。
そこで、この名前を使って、IDを取得します。その実装が以下のコードです。
sofware_spec_uid = client.software_specifications.get_id_by_name("default_py3.7")
print(sofware_spec_uid)
こんな結果がかえってくるはずです。
e4429883-c883-42b6-87a8-f419d64088cd
3.4 モデルの保存
3.3でsofware_spec_uidの取得をクリアできれば、あとは簡単です。
(ちなみにWatson MLの解説ブログではこの一番ややこしいところの言及がまったくなく、初めて読むと混乱します。。)
metadata = {
client.repository.ModelMetaNames.NAME: 'Scikit IRIS random forest', # モデル名称
client.repository.ModelMetaNames.TYPE: 'scikit-learn_0.23', # モデル種別 scikit-learn 0.23
client.repository.ModelMetaNames.SOFTWARE_SPEC_UID: sofware_spec_uid # 上で取得したsofware_spec_uidを指定
}
published_model = client.repository.store_model(
model=model,
meta_props=metadata,
training_data=X_train,
training_target=Y_train)
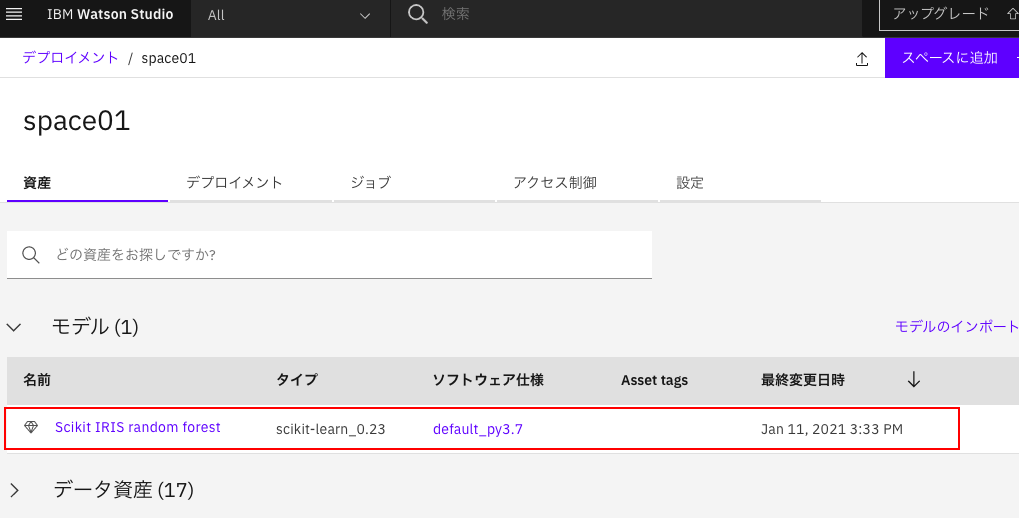
セルの実行でエラーがなければ登録に成功しています。
あるいは、デプロイメントスペース管理画面に赤枠で示した行ができていることからも確認ができます。
3.5 モデルの詳細確認
登録できていることはAPIを使っても確認可能です。次のセルでそれを行います。
import json
published_model_uid = client.repository.get_model_uid(published_model)
model_details = client.repository.get_details(published_model_uid)
print(json.dumps(model_details, indent=2))
うまく登録できていると、下記のような結果が返ってくるはずです。
{
"entity": {
"label_column": "l1",
"software_spec": {
"id": "e4429883-c883-42b6-87a8-f419d64088cd",
"name": "default_py3.7"
},
"training_data_references": [
{
"connection": {
"access_key_id": "not_applicable",
"endpoint_url": "not_applicable",
"secret_access_key": "not_applicable"
},
"id": "1",
"location": {},
"schema": {
"fields": [
{
"name": "f0",
"type": "float"
},
{
"name": "f1",
"type": "float"
},
{
"name": "f2",
"type": "float"
},
{
"name": "f3",
"type": "float"
}
],
"id": "1",
"type": "ndarray"
},
"type": "s3"
}
],
"type": "scikit-learn_0.23"
},
"metadata": {
"created_at": "2021-01-11T06:32:59.865Z",
"id": "dfc072c0-3dad-42b0-9951-4827271fd868",
"modified_at": "2021-01-11T06:33:02.146Z",
"name": "Scikit IRIS random forest",
"owner": "IBMid-550004D4D4",
"space_id": "9336c80e-574d-442c-a031-90765b925770"
},
"system": {
"warnings": []
}
}
最後にlist_models関数を呼び出して同じことを確認します。
client.repository.list_models()
こんな結果になればOKです。
------------------------------------ ------------------------- ------------------------ -----------------
ID NAME CREATED TYPE
dfc072c0-3dad-42b0-9951-4827271fd868 Scikit IRIS random forest 2021-01-11T06:32:59.002Z scikit-learn_0.23
------------------------------------ ------------------------- ------------------------ -----------------
4. モデルのデプロイ
モデルの保存までできたら、次のステップはモデルのデプロイです。最新のWatson MLでは「オンライン」「バッチ」の2通りのデプロイが可能になりました。以下では、Pythonと親和性の高い、オンラインのデプロイを行います。
バッチのデプロイの関しては、以下の別記事を参照して下さい。下の記事は、元のModelをSPSS Modeler Flowで作っていますが、モデルの保存から先の手順はまったく同じなので、下記の記事の内容がそのまま使えます。(予測用CSVは別途作る必要がありますが)
4.1 モデルのデプロイ
モデルのデプロイはUIの管理画面からもできますが、そんなに難しくないので、今回はAPIを使ってデプロイします。
client.deployments.ConfigurationMetaNames.ONLINEのパラメータが、今回のデプロイがオンラインであることを示しています。
metadata = {
client.deployments.ConfigurationMetaNames.NAME: "Scikit-Learn Iris Model online",
client.deployments.ConfigurationMetaNames.ONLINE: {}
}
created_deployment = client.deployments.create(published_model_uid, meta_props=metadata)
うまくいくと、下のような結果が返ってくるはずです。
#######################################################################################
Synchronous deployment creation for uid: 'dfc072c0-3dad-42b0-9951-4827271fd868' started
#######################################################################################
initializing
ready
------------------------------------------------------------------------------------------------
Successfully finished deployment creation, deployment_uid='864aec72-15c1-4008-b96a-6ce1c1776af4'
------------------------------------------------------------------------------------------------
デプロイメントに関してもlist関数で一覧表示が可能です。
# デプロイメントの一覧表示
client.deployments.list()
下のような結果になるはずです。
------------------------------------ ------------------------------ ----- ------------------------
GUID NAME STATE CREATED
864aec72-15c1-4008-b96a-6ce1c1776af4 Scikit-Learn Iris Model online ready 2021-01-11T06:46:10.762Z
------------------------------------ ------------------------------ ----- ------------------------
今回作ったdeploymentのIDは、この後の予測で必要になるので、下記のコードを実行してdeployment_uid変数にセットしておきます。
# depolyment_uid 取得
deployment_uid = client.deployments.get_uid(created_deployment)
print(deployment_uid)
864aec72-15c1-4008-b96a-6ce1c1776af4
4.2 デプロイメントの詳細確認
get_details関数を使って、今新規に作ったデプロイメントの詳細を確認します。
client.deployments.get_details(deployment_uid)
下のような結果が返ってくるはずです。
{'entity': {'asset': {'id': 'dfc072c0-3dad-42b0-9951-4827271fd868'},
'custom': {},
'deployed_asset_type': 'model',
'hardware_spec': {'id': 'Not_Applicable', 'name': 'S', 'num_nodes': 1},
'name': 'Scikit-Learn Iris Model online',
'online': {},
'space_id': '9336c80e-574d-442c-a031-90765b925770',
'status': {'online_url': {'url': 'https://us-south.ml.cloud.ibm.com/ml/v4/deployments/864aec72-15c1-4008-b96a-6ce1c1776af4/predictions'},
'state': 'ready'}},
'metadata': {'created_at': '2021-01-11T06:46:10.762Z',
'id': '864aec72-15c1-4008-b96a-6ce1c1776af4',
'modified_at': '2021-01-11T06:46:10.762Z',
'name': 'Scikit-Learn Iris Model online',
'owner': 'IBMid-550004D4D4',
'space_id': '9336c80e-574d-442c-a031-90765b925770'}}
5. 予測(Watsonライブラリを利用する方法)
以上で、モデルをWebサービス化するための手順を一通り説明しました。基本的には「モデル登録」「デプロイ」の2つのAPIを呼んでいるだけなので、簡単にWebサービスを作れることがわかったと思います。
これからの手順は、作ったモデルを呼び出して予測するための手順です。
この方法については、Watson MLのAPIを使う方法とそうでない方法の2とおりがあります。それぞれ一長一短あるので、両パターンについて説明します。5章は、このうち、Watson MLライブラリを利用するパターンです。
5.1 入力用変数の組み立て
予測は、検証用にリザーブしてあったデータのうち、先頭20行を使うことにします。
下記のコードは、このデータをWatson ML APIの入力用に加工するコードとなります。
# 検証データの先頭N個で予測する
N = 20
# 予測用入力変数 scoring_payload の組み立て
# 先頭のN個を抽出し、リスト化する
values = X_test[:N].tolist()
# valuesを元にscoring_payload変数を設定
scoring_payload = {"input_data": [{"values": values}]}
5.2 予測実施
予測を実施するためには、deployment_uidを取得する必要があります。今回は、deployの直後に予測するため、流れでdeployment_uidの値が取得できていますが、そうでない場合は、上で説明したclient.deployments.list()関数を使ってこの値を調べて下さい。
UIからも調べることは可能です。
逆にこのIDがわかっているなら、予測の実行はとても簡単で、下記の1行で済むことになります。
# 予測の実施
predictions = client.deployments.score(deployment_uid, scoring_payload)
5.3 結果確認
まずは、predictionの中身を直に表示してみます。
print(predictions)
こんな結果になるはずです。
{'predictions': [{'fields': ['prediction', 'probability'], 'values': [[2, [0.0, 0.0, 1.0]], [0, [0.99, 0.01, 0.0]], [1, [0.0, 0.98, 0.02]], [2, [0.0, 0.0, 1.0]], [0, [1.0, 0.0, 0.0]], [1, [0.0, 0.99, 0.01]], [1, [0.0, 0.98, 0.02]], [2, [0.0, 0.01, 0.99]], [0, [1.0, 0.0, 0.0]], [2, [0.01, 0.15, 0.84]], [2, [0.0, 0.0, 1.0]], [1, [0.0, 0.96, 0.04]], [2, [0.0, 0.07, 0.93]], [1, [0.0, 1.0, 0.0]], [2, [0.0, 0.0, 1.0]], [0, [1.0, 0.0, 0.0]], [0, [1.0, 0.0, 0.0]], [1, [0.0, 1.0, 0.0]], [1, [0.0, 1.0, 0.0]], [1, [0.0, 0.82, 0.18]]]}]}
予測値と、それぞれの値に対する確率値の配列が返ってきていることがわかります。
こんなコードを使うと、この結果から予測値だけを抽出できます。
# 予測値のみを抽出
import numpy as np
w1 = predictions['predictions'][0]['values']
w2 = np.array([x[0] for x in w1])
print(w2)
結果は以下のようになりました。
[2 0 1 2 0 1 1 2 0 2 2 1 2 1 2 0 0 1 1 1]
ちなみに、この10件のデータの正解値は、こんな感じです。
# 正解値
print(Y_test[:N])
[2 0 1 2 0 1 1 2 0 1 2 1 2 1 2 0 0 1 1 2]
細かいコードの解説は省略しますが、Notebookでは混同行列も表示しています。その結果のみを下に示します。

なんとなく、よさそうな感じです。
6. 予測(Watsonライブラリを使わない方法
最後にWatson MLのAPIを使わずにWebサービスを呼び出す方法を説明します。Pythonの環境によっては、Watson MLのライブラリ導入が、環境全体を重くしてしまう可能性があります。そういう場合は、下に示す方法で呼び出すことで、基本的なライブラリだけでWebサービスを呼び出すことも可能です。必要に応じて使い分けるようにして下さい。
6.1 Token取得
このパターンの場合の最初のステップはトークンの取得です。実装コードは次のようになります。
apikeyに関しては、3.2で使ったのと同じものが使えます。
import urllib3, requests, json
# トークン取得
# apikeyは3.2で使ったのと同じものを利用
url = "https://iam.cloud.ibm.com/identity/token"
headers = { "Content-Type" : "application/x-www-form-urlencoded",
"Accept" : "application/json" }
data = "apikey=" + apikey + "&grant_type=urn:ibm:params:oauth:grant-type:apikey"
response = requests.post( url, headers=headers, data=data)
iam_token = response.json()["access_token"]
print('iam_token = ', iam_token)
うまくいくとこんな結果になるはずです。(機密情報なのですが、すぐ無効になるので、そのまま貼り付けておきます)
iam_token = eyJraWQiOiIyMDIwMTIyMTE4MzQiLCJhbGciOiJSUzI1NiJ9.eyJpYW1faWQiOiJJQk1pZC01NTAwMDRENEQ0IiwiaWQiOiJJQk1pZC01NTAwMDRENEQ0IiwicmVhbG1pZCI6IklCTWlkIiwianRpIjoiNzljYjljNTktMTE2MS00NTBlLWI1ZGEtM2Q1NDFhMGIzN2MxIiwiaWRlbnRpZmllciI6IjU1MDAwNEQ0RDQiLCJnaXZlbl9uYW1lIjoibWFzYTA3IiwiZmFtaWx5X25hbWUiOiJha2EiLCJuYW1lIjoibWFzYTA3IGFrYSIsImVtYWlsIjoiZGxfbWF0aF9ib29rX3N0MDdAeWFob28uY28uanAiLCJzdWIiOiJkbF9tYXRoX2Jvb2tfc3QwN0B5YWhvby5jby5qcCIsImFjY291bnQiOnsidmFsaWQiOnRydWUsImJzcyI6IjZkYzgwZmVhOWUxYjRjYjdiNzU1MDNlMmMyZDkwY2Q4IiwiZnJvemVuIjp0cnVlfSwiaWF0IjoxNjEwMzQ5MDk3LCJleHAiOjE2MTAzNTI2OTcsImlzcyI6Imh0dHBzOi8vaWFtLmNsb3VkLmlibS5jb20vaWRlbnRpdHkiLCJncmFudF90eXBlIjoidXJuOmlibTpwYXJhbXM6b2F1dGg6Z3JhbnQtdHlwZTphcGlrZXkiLCJzY29wZSI6ImlibSBvcGVuaWQiLCJjbGllbnRfaWQiOiJkZWZhdWx0IiwiYWNyIjoxLCJhbXIiOlsicHdkIl19.q32IpK8J3PZ6FAmU9wDyJnq5neAbhDRMcwK352kLc5mNRkzAMf7Sym2pIEhpg1AXz5FLrsnfsp_4ggYvTdHkBujQa-dzfxb9AqiUiDsd3n3MnvYNp7yakztMSaMyE72CilS0ZG4az2fs94afrd60RE5vAt_AwfJSAHDsA2jUuKuAjlxYui8aPFZ_kGT1JlW2WtQj-aS856z6r3EjWhFqkXxZJslohSfEOHt9irlHl-fslZRJZMhTUXOIUblbyX_OiWzjEurvCsS3mFaSQAhzcsPxx6tiKiHLjJ7CDw-7lPcwLxiMtvNYTHf7JQ3ODg4OD5wnS-OrAxJQVm-_xMfuGQ
6.2 Header組み立て
次のステップは、今取得したTokenを利用したリクエストヘッダの組み立てです。
具体的な実装は次のようになります。
# headerの組み立て
header = {'Content-Type': 'application/json', 'Authorization': 'Bearer ' + iam_token}
6.3 URL取得
次にscoring_urlと呼ばれる、呼び出し用のURLを入手します。このURLはデプロイメントの管理画面から取得することも可能ですが、今のnotebookでは、deploy時の情報が変数で残っているので、それを使う方法を用います。
# URLの取得
scoring_url = client.deployments.get_scoring_href(created_deployment)
# scoring_urlはデプロイメント管理画面からも取得可能です。その場合は、下記のコメントをはずして直接指定します。
# scoring_url = "xxxx"
print(scoring_url)
こんな結果になります。
https://us-south.ml.cloud.ibm.com/ml/v4/deployments/864aec72-15c1-4008-b96a-6ce1c1776af4/predictions
Watson ML v2では、このURLにバージョン情報を追加する必要があります。
具体的な実装は次のようになります。
# バージョンの付加
# Watson ML v2の場合、バージョンをURLパラメータで追加することが必須です。
scoring_url2 = scoring_url + '?version=2020-09-01'
6.4 入力用変数組み立て
入力用変数であるscoring_payload の作り方は5章の場合とまったく同じです。説明は省略してコードのみ再掲します。
# scoring_payloadの組み立て
# 検証データの先頭N個で予測する
N = 20
# 予測用入力変数 scoring_payload の組み立て
# 先頭のN個を抽出し、リスト化する
values = X_test[:N].tolist()
# valuesを元にscoring_payload変数を設定
scoring_payload = {"input_data": [{"values": values}]}
6.5 予測実施
お疲れ様でした。これで、予測に必要な準備はすべて終わりました。以下のコードで、予測呼び出しができるはずです。
この呼び出しでは、Watson ML APIを使わず、標準的なライブラリrequestsのpost関数を利用していることがわかると思います。
# 予測の実施
direct_scoring = requests.post(scoring_url2, json=scoring_payload, headers=header)
呼び出し結果がエラーになっていなければ、呼び出しはうまくいっています。
次の節で、その結果を確認してみます。
6.6 結果確認
まずは、戻り値をそのままprint関数のかけてみます。
# 結果確認 (リターンコード表示)
print(direct_scoring)
requests関数の戻りなので、URLのリターンコード(200=正常)が返ってきます。
<Response [200]>
次に、結果を内容を表示してみます。
# 結果確認 (戻り値表示)
print(direct_scoring.text)
こんな結果になるはずです。
{"predictions": [{"fields": ["prediction", "probability"], "values": [[2, [0.0, 0.0, 1.0]], [0, [0.99, 0.01, 0.0]], [1, [0.0, 0.98, 0.02]], [2, [0.0, 0.0, 1.0]], [0, [1.0, 0.0, 0.0]], [1, [0.0, 0.99, 0.01]], [1, [0.0, 0.98, 0.02]], [2, [0.0, 0.01, 0.99]], [0, [1.0, 0.0, 0.0]], [2, [0.01, 0.15, 0.84]], [2, [0.0, 0.0, 1.0]], [1, [0.0, 0.96, 0.04]], [2, [0.0, 0.07, 0.93]], [1, [0.0, 1.0, 0.0]], [2, [0.0, 0.0, 1.0]], [0, [1.0, 0.0, 0.0]], [0, [1.0, 0.0, 0.0]], [1, [0.0, 1.0, 0.0]], [1, [0.0, 1.0, 0.0]], [1, [0.0, 0.82, 0.18]]]}]}
この結果はjson形式のテキスト情報なので、pythonで扱うためにはjson.loads関数を使う必要があります。
予測値の一覧を取得するコードは次のようになります。
# 予測値のみを抽出
w0 = json.loads(direct_scoring.text)
w1 =w0 ['predictions'][0]['values']
w2 = np.array([x[0] for x in w1])
print(w2)
[2 0 1 2 0 1 1 2 0 2 2 1 2 1 2 0 0 1 1 1]
5章のときと、同じ結果がかえってきているのがわかるかと思います。
関連記事
Deploy a Machine Learning Model from a Jupyter Notebook
IBM Watson Machine Learning samples
Use scikit-learn to recognize hand-written digits with ibm-watson-machine-learning