はじめに
従来のSPSSと比較したときにIBM Cloud上のSPSS Modeler Flowの利点は何かと聞かれたとき、
「作った予測モデルをWatson Machine Learningにデプロイすることで簡単にリアルタイム予測ができること」
というのがその質問に対する答えでした。
この答えは間違ってはいないのですが、実際に予測モデルを呼び出す手段を考えるとREST API呼び出し->Python実装が標準コースになってしまい、モデルを作る時と比較すると結構ハードルが高くなっていたのが実情です。
実は、最近Watson Studioに加わった機能をうまく使うと、CSVファイルを入力としたバッチ予測を、一切プログラミングなしに行うことができます。当記事はその手順を説明するものとなります。(ここで使っているすべての機能はクレジットカードなしに試すことのできるライトアカウントで可能です。)
なお、例によって、この記事に記載されている内容もOpenshift上のIBM製品であるCP4D(Cloud Pak for Data)でも動く機能となります。CP4D版の機能を検討したい方も、クラウド環境でお手軽に試すことが可能です。
(2020-12-10 定時ジョブの話を追記)
前提環境
以下の基盤的準備はすでに終わっていることを前提とします。
- IBM Cloudにライトアカウント登録
- Watson Studioのインスタンス・プロジェクト作成
- Watson Machine Learningのインスタンス作成
- Deployment Spaceを作成
- Deployment SpaceとWatson Machine Learningのインスタンスとの関連付け
1.と2.の手順については、以下の記事を参照して下さい。
無料でなんでも試せる! Watson Studioセットアップガイド
3.については、以下の記事を参照して下さい。
Watson Studioで追加サービスの登録を行う
また、4. 5.の手順については、以下の記事のうち、1章の「デプロイメントスペースの作成」を参考にして下さい。
AutoAIでお手軽機械学習(その3) Webサービス編
ファイルの準備
以下の実習では2つのCSVファイルを利用します。それぞれ、下記のリンク先からダウンロードしておいて下さい。
前のデータbank-train-jp-autoai.csvはモデル学習用に、後のデータbank-test-jp-autoai-2000.csvは予測用に利用します。
どちらも、元ネタはUCIデータセットの一つである「Bank Marketing」で、項目名を日本語化した後、学習用(4521件)と検証用(2000件)に分けています。
実習1 予測モデルの作成
それでは、いよいよ実習開始です。最初のステップは、SPSS Modeler Flowで予測モデルを作ります。
ここの手順は、この記事の主題ではないので、かなり手抜きで大急ぎでモデルを作ります。
CSVデータのアップロード
まず、事前に準備したCSVデータを「アセット」としてクラウド上にアップロードします。
プロジェクト管理の画面から「プロジェクトに追加」->「データ」を選びます。
その後で2つのCSVを下記の画面にdrap and dropします。

下の画面のように2つのCSVファイルが「データ資産」として登録されていることを確認して下さい。

フローの作成
次にModeler Flowの操作に入ります。
まず、最初に、プロジェクト管理画面から「プロジェクトに追加」->「Modelerフロー」を選択します。

下の画面になったら「名前」の欄に「Bank Merketing SPSS」と入力して、画面右下の「作成」ボタンをクリックします。

ノードの配置
下の画面になったら、次の3つのノードを編集エリアにdrag and dropして、ノード間を結線します。
(このあたりはかなり手抜きです。今回はモデルを作ることは目的でないので、最短手順になっていると理解して下さい。)
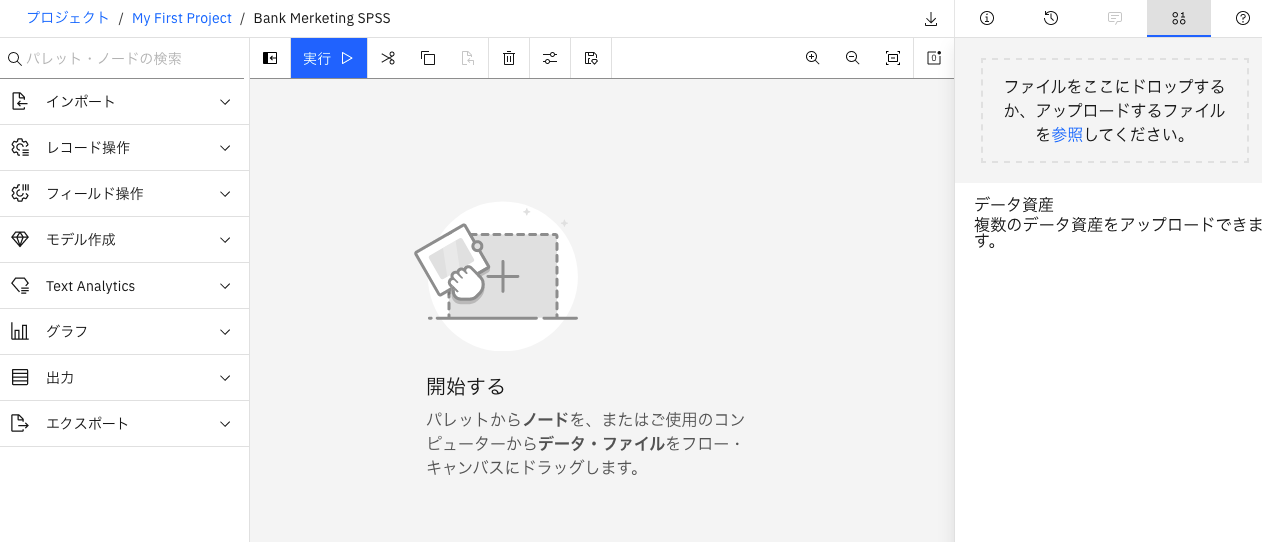
- 「インポート」->「データ資産」
- 「フィールド操作」->「タイプ」
- 「モデル作成」->「LSVM」
結線が終わると下のような画面になるはずです。

データ資産ノードの設定
次にそれぞれのノードの属性を設定します。まず、「データ資産」ノードです。このノードをダブルクリックすると、下のような画面が現れるので、左側の「データ資産の変更」を選択します。

下の画面になったら
① 「データ資産」
② bank-train-jp-autoai.csv
③ 右下の「OK」ボタン
を順にクリックします。

下の画面になったら、右下の「保存」ボタンをクリックして下さい。

タイプノードの設定
次は、真ん中のタイプノードです。
このノードをダブルクリックすると、下の画面になります。

画面を一番下までスクロールします。一番下の行「今回販促結果」のロールを「入力」から「ターゲット」に変更します。あとは、全部デフォルトのままで、画面右下の「保存」ボタンをクリックします。

学習
画面は、下のようになるはずです。この状態で「実行」アイコンをクリックして下さい。

下のように、オレンジ色のノードが新しくできていれば、学習に成功しています。引き続き、この画面で予測用のフローを作ります。

実習2 予測用フローの作成
フローの配置
まず最初に今、学習によりできたオレンジのアイコンを選んだ状態で、下の画面のように
① コピー
② ペースト
のアイコンを順にクリックします。

うまくいくと、下のようにオレンジのアイコンのコピーが作られます。
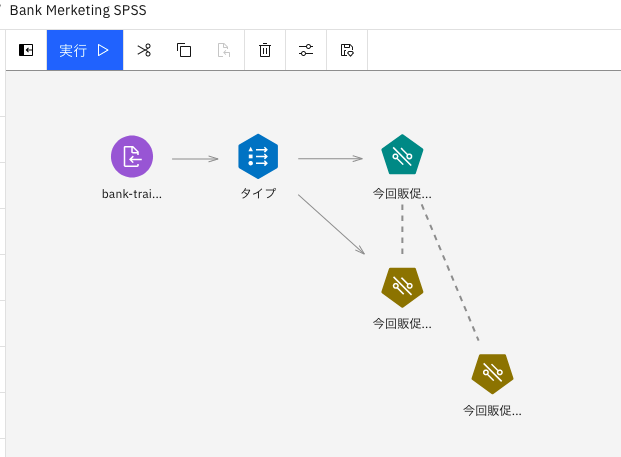
次に以下のアイコンを順にdrag and dropして、下のように結線して下さい。
「インポート」->「データ資産」
「フィールド操作」->「フィルター」
「エクスポート」->「データ資産エクスポート」

各ノードの設定
今、追加したノードの設定を行います。
データ資産ノードについては、2つめのCSVファイルであるbank-test-jp-2000.csvと紐付けます。具体的な手順は先ほどと同じなので省略します。
次にフィルターノードの設定を行います。
フィルターノードをダブルクリックすると、下の画面が表示されるので、
① 「選択されたフィールドの保持」を選択
② 「列の追加」をクリック
します。
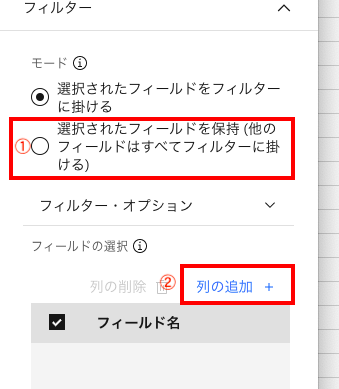
下のような「フィールドの選択」画面になったら、画面を下にスクロールして一番下の3つの項目を選択し、「OK」ボタンをクリックします。

下の画面になるので、右下の「保存」ボタンをクリックします。

なお、「今回販促結果」は目的変数(正解データ)であり、本当の予測時にはわかっていない訳ですが、今回は最後に正解データと予測値を比較してみるため、あえて入力データに含めています。本来の予測時と違うことをやっている点は理解しておいて下さい。
最後のデータ資産エクスポートノードは下の画面のようにファイル名をbank-spss-output.csvに変更して「保存」ボタンをクリックします。
最終的には下の画面のようになるはずです。

予測の実施
今、新たに作った予測用ストリームを実行します。
そのため、マウスポインタを表ノードの上に置いて、コンテキストメニューを表示します。
そして、一番下の「実行」を選んで下さい。

正常終了していれば予測に成功しています。そのことを確認するため、画面上部のプロジェクト名のリンクをクリックしてプロジェクト管理の画面に戻りましょう。

下のようにbank-spss-output.csvというファイルが増えているはずです。(もし、このファイルがない場合はいったんプロジェクト管理画面を閉じて、再度開き直して下さい)

ここでこのファイル名のリンクをクリックしてファイルの中身も確認します。
先ほど、フィルターで設定した3つの項目だけがCSVファイルとしてexportされているのがわかります。もともとこの学習データでは、「成功」の比率が10%程度と少ないのですが、赤枠で囲んだ行はその少ない「成功」をモデルが正しく予測できていることもわかります。

実習3 モデルの保存・プロモート・デプロイ・ジョブ実行
以上で、SPSS Modeler Flowによる「学習」「予測」は終わりです。次に最後に作った予測用のフローをWatson Machine Learningのモデルとして保存します。
予測モデルの保存
最初にモデルの保存をします。再び、表ノードにマウスポインタをあわせ、コンテキストメニューを表示させます。
今度は下から2つ目の「ブランチをモデルとして保存」を選択します。
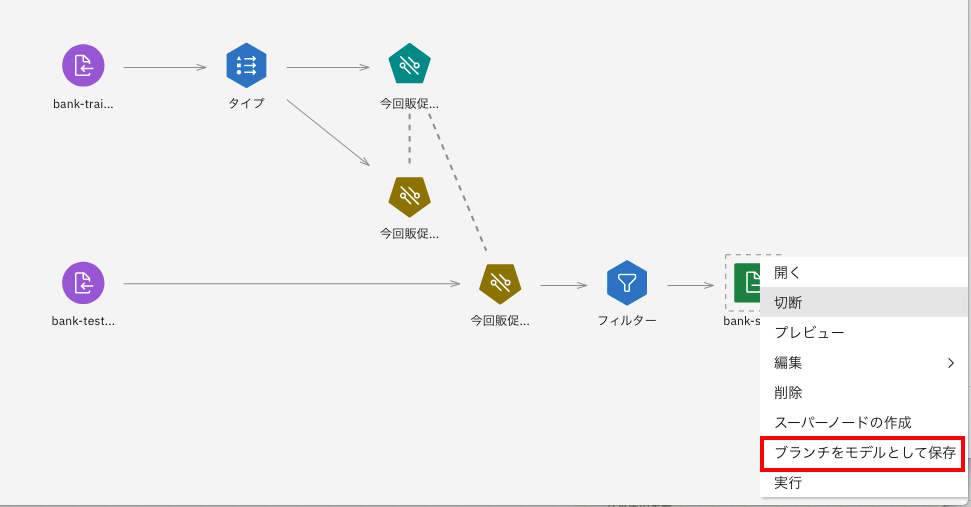
下のような画面になるので、モデル名のところは「bank merketing spss model」などと書き換えます。
それ以外はデフォルトの状態で、画面右下の「保存」ボタンをクリックします。

下のような画面になれば、モデルの保存に成功しています。「閉じる」ボタンをクリックして下さい。
プロジェクト管理画面に戻るため、画面右上のプロジェクト名のリンクをクリックします。
モデルのプロモート
次に今保存したモデルをデプロイメント・スペースにプロモートします。
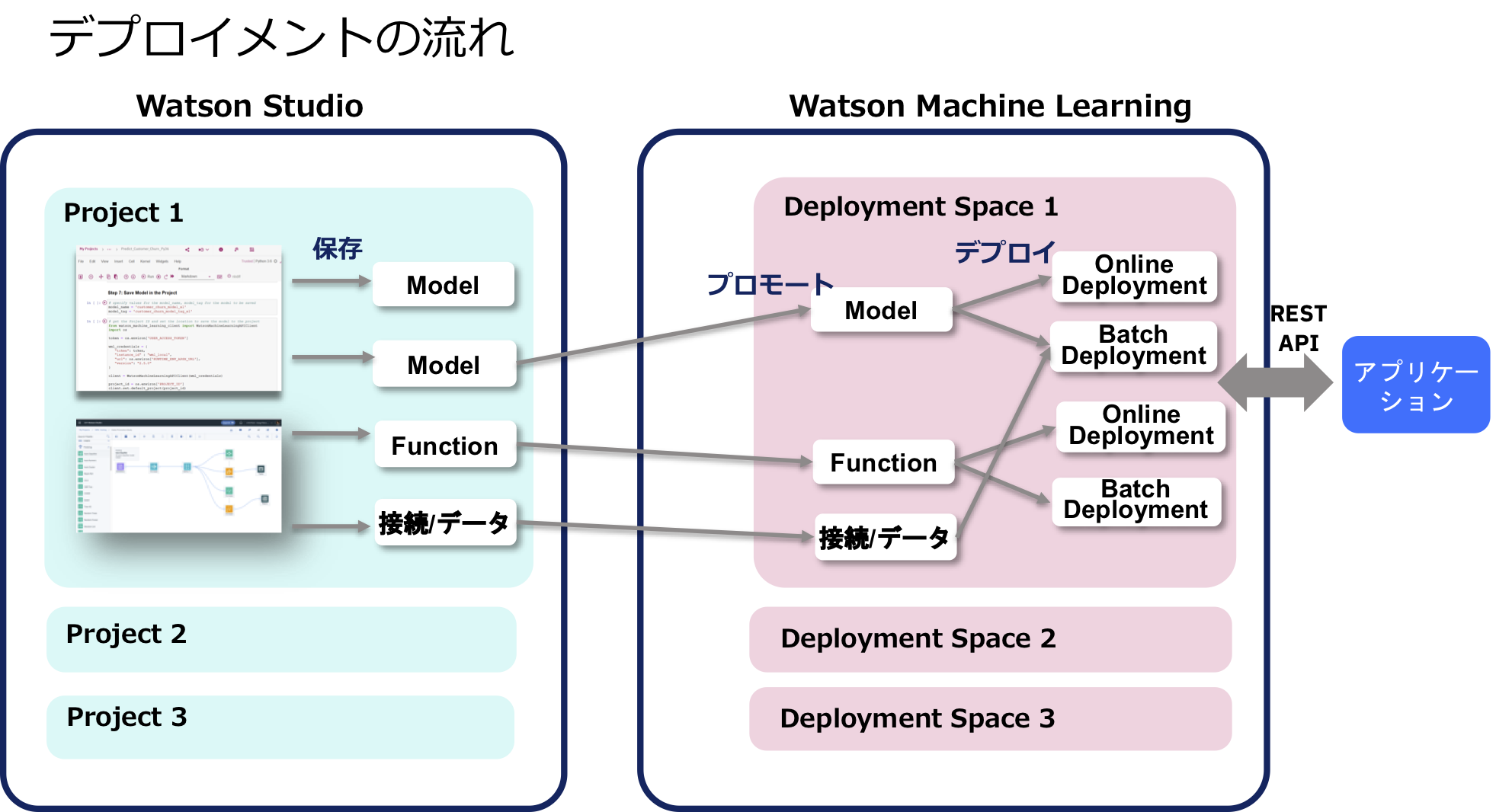
「デプロイメントスペース」「プロモート」の概念がわかりにくですが、下の図と、これからの操作を見比べると、今、何をやっているかがわかると思います。
資産タブの「Watson Machine Learningモデル」の欄に先ほど保存した「bank merketing spss model」という項目ができているはずです。このリンクをクリックします。
下のようなモデル管理画面になるので、右家の「デプロイメント・スペースにプロモート」をクリックします。

下の画面になるので、「ターゲット・スペース」に事前に準備したデプロイメント・スペースが選択されていることを確認した上で、画面右下の「プロモート」ボタンをクリックします。
下のような画面が出てくれば、モデルのプロモートに成功しています。改めて、上の概念図を見て下さい。

ここから先はすべてデプロイメント・スペース上の作業となります。
デプロイメント・スペース管理画面
最初に今まで作業したプロジェクト管理画面からデプロイメント・スペース管理画面に移動します。
具体的には、画面左上の「三」のようなアイコンをクリックします。

メニューから「すべてのスペースの表示」を選択します。

下の「デプロイメント」の画面になったら
① スペースタブを選択
② スペース名のリンクをクリックします。

バッチ入力ファイルのアップロード
下の画面になったら、先ほど予測で利用したCSVファイルをこの画面の右側にもアップロードします。これは、これから実行するバッチ処理の入力ファイルとなります。
アップロードが正しく終わると、下のように新しく「データ資産」の項目ができます。

バッチの定義
ここで、モデルからバッチ・デプロイメントを作るため、モデルのリンクをクリックします。

下の画面になるので、「デプロイメントの作成」ボタンをクリックします。

下の画面になるので、次の設定をします。
① オンライン・バッチ区分は「バッチ」を選択します。これが最近できた新機能です。ちなみに、「オンライン」を選択すると、従来からあったWebサービスを作ることになります。
② デプロイメント名称を入力します。この例では「bank maeketing spss batch」としました。
③ ハードウェア定義を選択します。ここでは、ちょっとリッチに「4vCPU 16GB memory」を選んでみました。
④ 最後に「作成」ボタンをクリックします。

ジョブ作成とバッチ実行
下のようなバッチ管理画面になります。ここで引き続きジョブ作成を行います。そのため、「ジョブの作成」ボタンをクリックします。

下の画面ではジョブ名称を入力して「次へ」ボタンをクリックします。
ジョブ名称はこの例では「bank maketing spss batch job」としました。

次の「構成」の画面はデフォルトの状態で「次へ」ボタンをクリックします。
この段階で、バッチ作成時と異なるvCPU環境を選択することも可能です。
次は「スケジュール」設定の画面です。ここもデフォルトのまま「次へ」をクリックします。
次の画面では、バッチ処理の入力ファイルと出力ファイルを指定します。
まず、「データソースの選択」のボタンをクリックします。

先ほど、デプロイメントスペースにアップロードしたcsvファイルが選べるはずなので、それを指定します。指定ができたら、画面下の「確認」ボタンをクリックします。

下のような画面になります。
① 入力ファイルが正しく設定できたことを確認します。
② 出力ファイルを入力します。ちなみに、ここで設定したファイル名に対して、勝手に拡張子 csvが付けられるようです。
③ 次へボタンをクリックします。

下のような最終確認の画面になります。この設定でよければ「保存」ボタンをクリックします。

下のような画面になります。ジョブ保存タイミングでジョブ自体も一回実行されるようです。その結果を確認するため、画面上部のデプロイメント名のリンクをクリックします。

下のように、バッチ出力ファイルができていることがわかります。デプロイメントスペース内では、プレビュー機能はないのですが、いったんパソコンにダウンロードすればバッチの結果が確認できます。
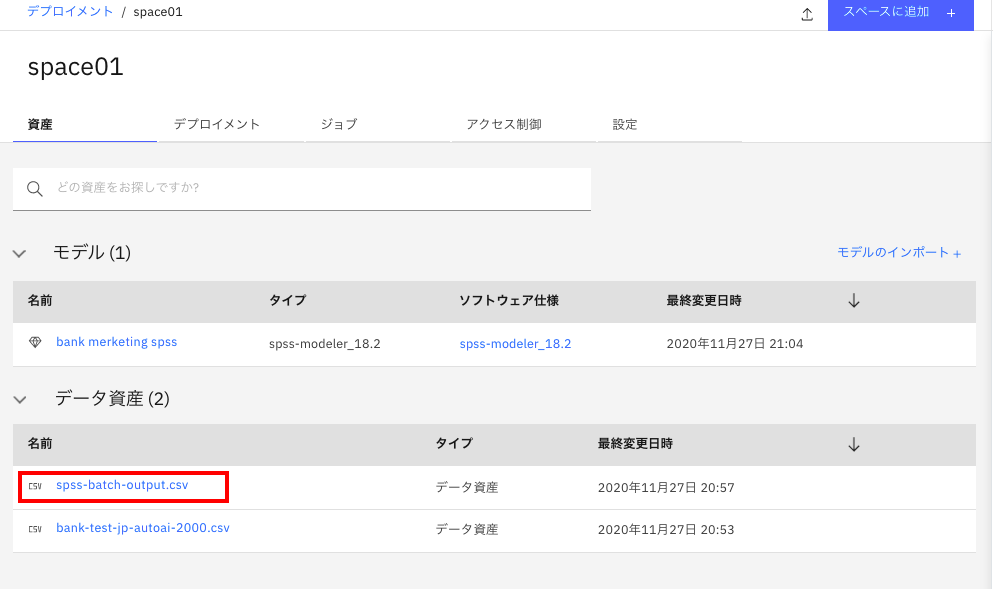
これで、Modeler Flowで作ったモデルに対してCSVファイルを入力としてバッチ起動する実習は終わりです。
例えばデプロイメントスペースにアップロードするCSVを、データが40690件ある下記のcsvに差し替えて同じことをすると、よりバッチ処理のイメージがわくかと思います。
定時起動ジョブの定義
以上で説明したジョブは、ユーザーがUI画面(あるいはAPIからも可能です)でユーザートリガーで起動するジョブの定義方法でした。定時起動ジョブも同じような方法で定義可能です。
本節でその手順を説明します。
バッチデプロイメントの管理画面を再度表示し、もう一度「ジョブの作成」ボタンをクリックしてください。
名前は「定時ジョブ」として、「次へ」ボタンをクリックします。
次の「構成」画面の操作は前と同じです。

次の「スケジュール」の画面で、以下の操作をする点が、先ほどとの違いです。
① 「実行をスケジュール」スイッチをオン(右)にする
② 「繰り返し」にチェックする
③ 「毎」の欄で「日」を選択し、時刻を適当に設定する
④ 右下の「次へ」ボタンをクリック

その後の操作も先ほどの非定期ジョブの設定と同様です。これで定期実行ジョブの定義ができました。
最終的には、下のような画面になります。

ジョブ結果確認
最後に個別ジョブの実行結果を確認してみましょう。
まず、上のジョブ一覧の画面から、「定時ジョブ」のリンクをクリックします。
すると、下のようにジョブの詳細画面になります。
また、この画面の下の方には「実行」という欄があり、定時ジョブの場合、日々の実行記録が個別に残されています。ここで、実行の配下のリンクをクリックしてみます。

すると、下のような画面になります。これが、個別の実行(Run)に関する詳細画面です。
この画面で、個別ジョブが成功したかどうか、時間がどの程度かかったかなどの情報が確認できます。
