会社のAIプロジェクトの中で、Modelの管理を以下の条件を満たすような条件でしたいと考えてそれにあうMLOpsサービスを探していました。
- 定期的にデータを学習させ得られたModelをバージョニングして管理したい
- それぞれのModelで簡単にDeployしてAPI化させRESTでアクセスできるようにしたい。
- できるだけ管理画面は簡単なUIでありたい。
上記の結果に合うもので、以前Udemyで勉強したこともあって、MLFlowで管理できないかを考えました。
ちなみにMLflowを高速で学べるコースは以下
話はさておき、MLflowを選択したとはいえ、更なる以下の課題が発生します。
-
AI Modelはサービスの一部で使用し、そのサービス全体はGCPで稼働してるので、MLflow及び学習等もGCPの中で稼働させて管理したい。
-
MLFlowを立てるにしても、MLflowで要求されるインフラを用意したりする時間はあまりかけたくない
これを満たすような条件は、MLflowの開発元である、DataBricksをGCPで動かすことでした。
DataBricksを使用することでMLflowをマネージドで使用できます。
幸いにもDataBricksをGCPで動かすマーケットプレイスがあったので
決定したは良いが、コスト感がわからなかったので、
Databricks on GCPの2週間のトライアルを申し込んで使い勝手を調べてみました。
ジョブ$0.07/DBUなど、どれぐらいかがピンと正直きませんでした。


というわけで、当記事では、Databricks on GCPを初心者が使ってみた感想を書いてみたいと思います。
最低限成し遂げたいアーキテクチャの構想
学習コードを定期実行処理させるためのDatabricks上での仕組みとかは一旦おいておいて、
最低限の理想系については、
- jupyterNotebookで学習コードを管理
- mlflowにmodelやmetrics情報を送ってmlflowマネージドで管理を行う
- mlflowから推論用endpointを排出する。
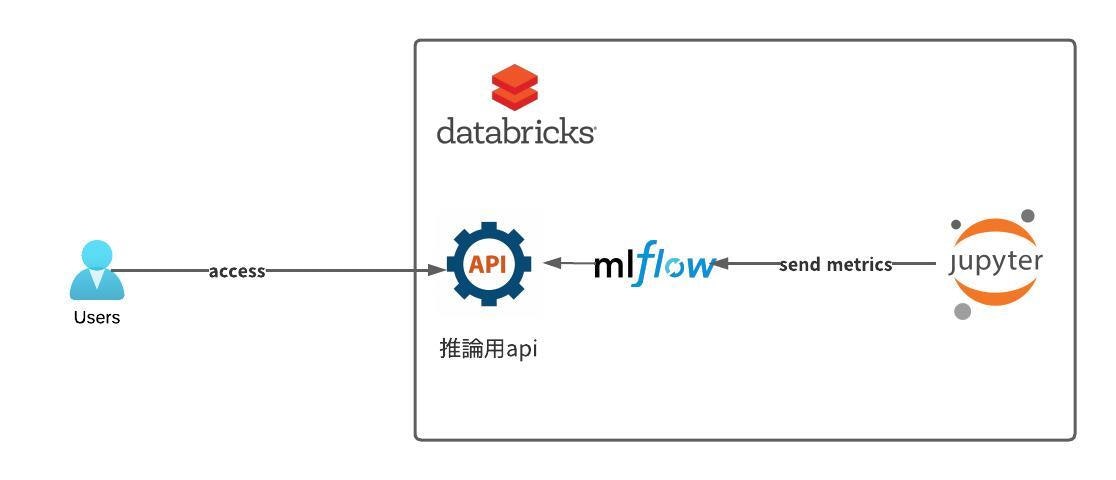
スタート
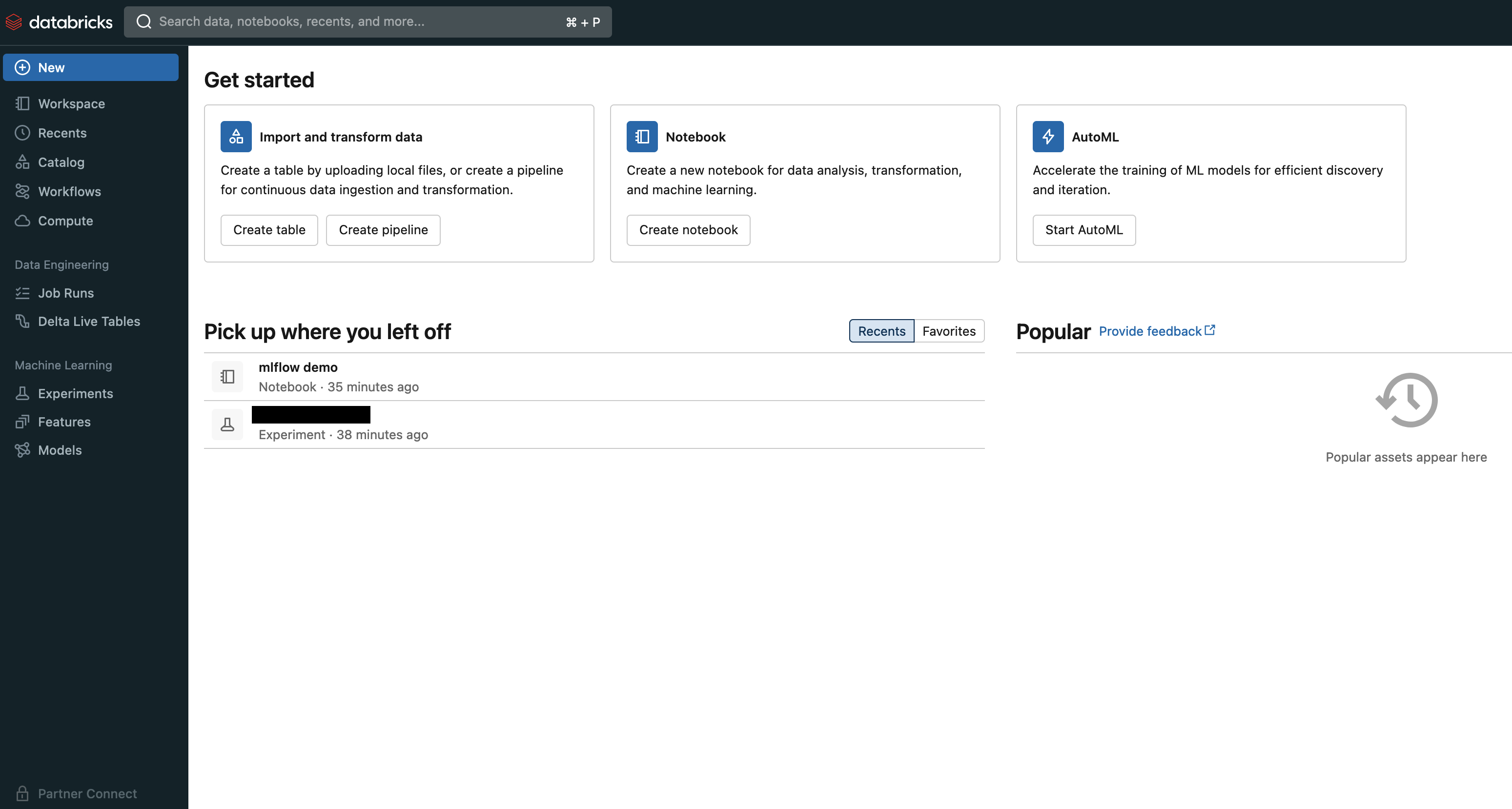
DataBricks on GCPを立ち上げると、最初にworkspaceを立ち上げる。実際にworkspaceを立ち上げるとメールの中にアクセスURLが届く。

URLを開くとworkspaceが開くが、まず、何をしていいかわからないから始まる。
(Pick up where you left offは後から私が追加したもの)
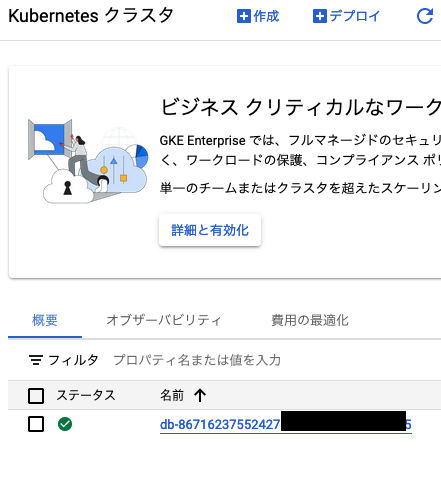
GCPのconsoleを見たら、DataBricks用のGKE Clusterが出来上がっていた。どうやらこのGKE中でコントロールされるらしい。
まず、何していいかわからない....
youtubeと記事でやりかを調べてみるがよくわからない。というか、説明をしてる記事が少ない。...AIアシスタントとかそうゆうのじゃなくて基本的な使い方についての説明が少なくて困った。
そして行き着いたのがこの記事で一番わかりやすかった。
まず、左サイドバーがなんの役割とどのように連携するかがわからなかったので調べ上げたところ、
さらに、実際にworkspaceでコードをrunさせるときに、どこのサーバーで動かすかを決定するためにComputeというところで、instanceを作る。
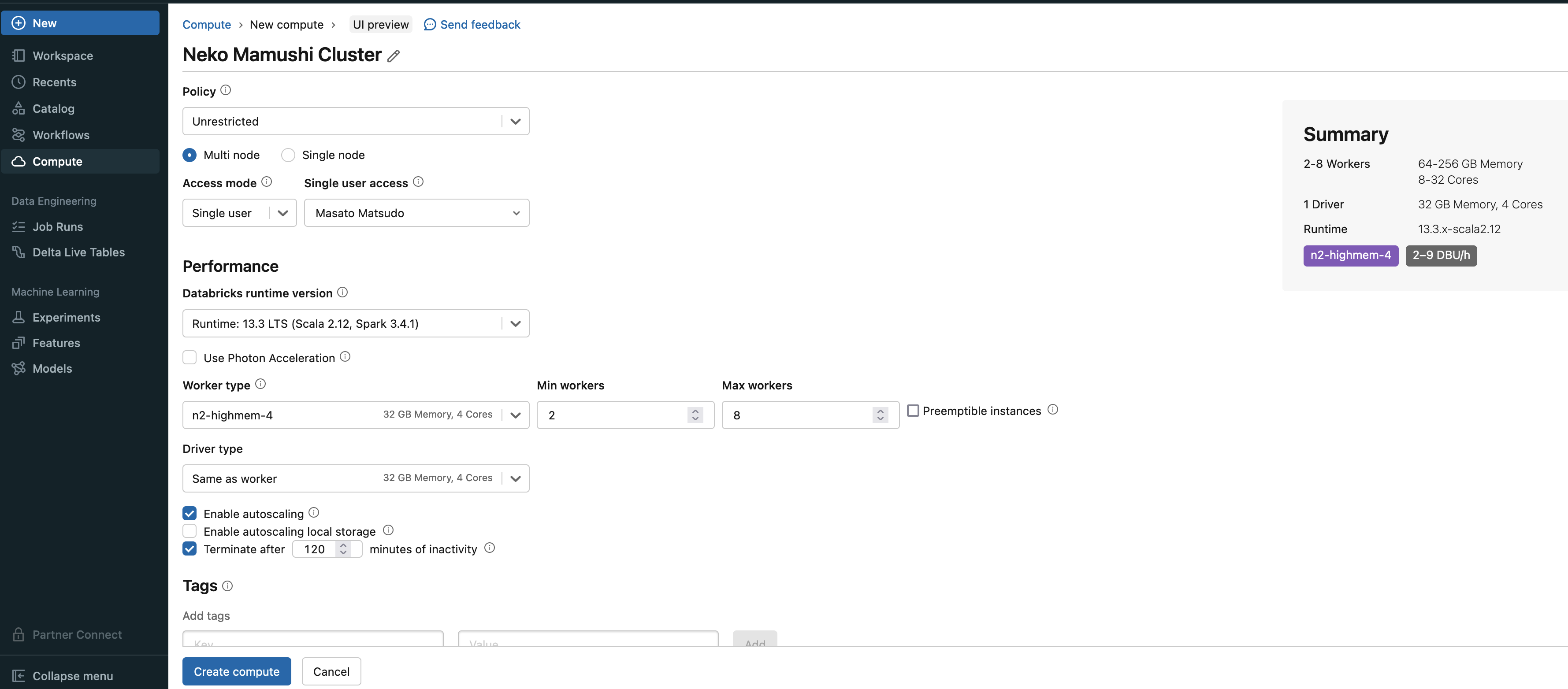
基本Computeで立てたinstanceでJupyterのコードを動かすみたい
実際にGKE上の動きとしては、DataBricks GKE Cluster上に指定したスペックのinstanceがGKEのノードとして追加されるみたいです。
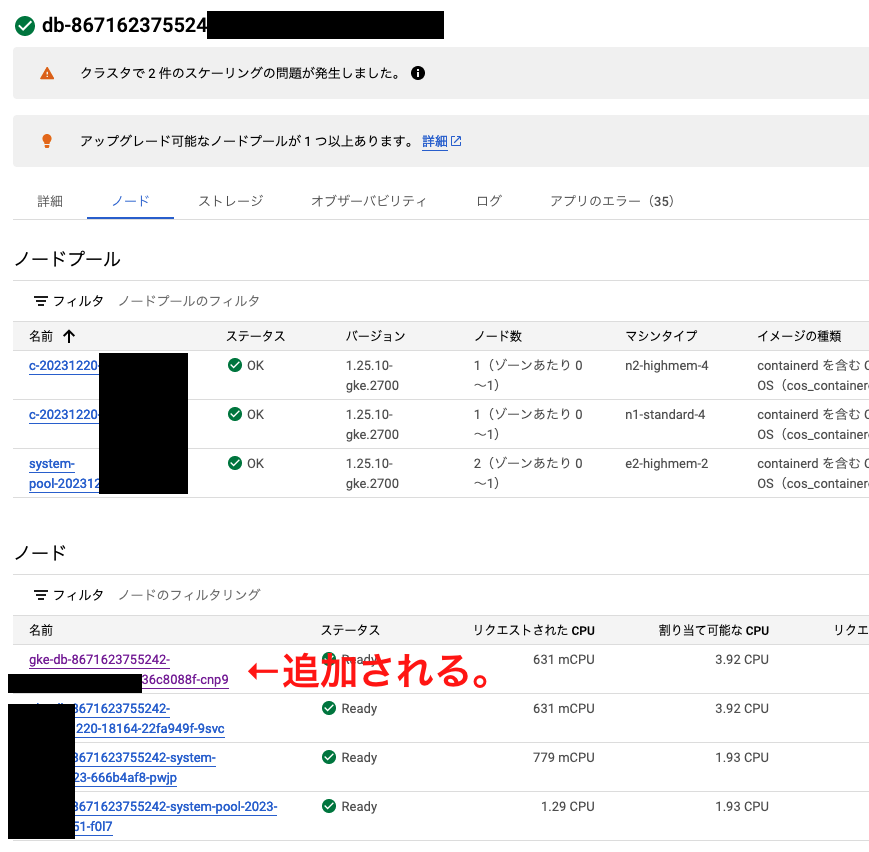
追加されたNodeの中に自動でPodがapplyされて、下記のPodが立ち上がるまで、待ちになります。
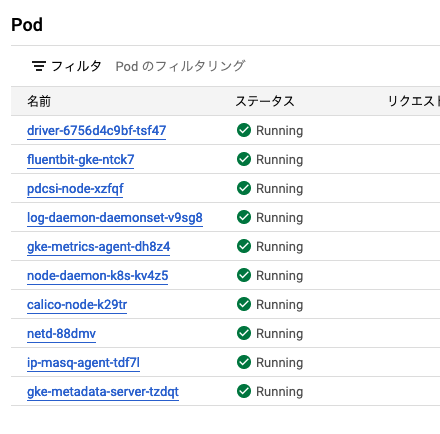
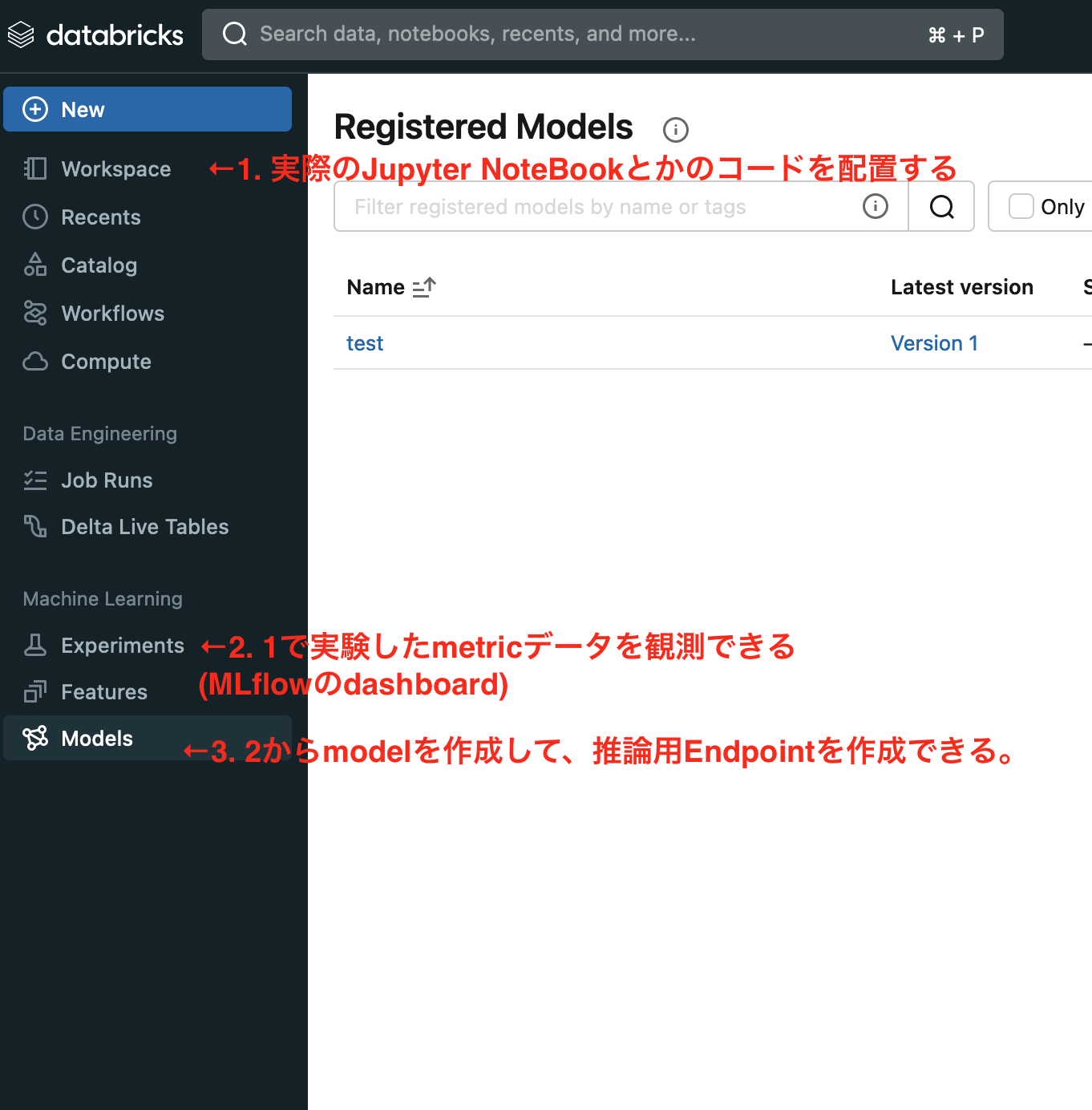
Workspaceで、コードを書いて、書いてる中で実行した時に、発生したmetricsをExperimentsで収集して、Modelsで実際にmodel化してdeployを行うらしい。
実際にworkspaceでnotebookを作ってCompute(Databricks上の指定したスペックのinstanceで動くnode)を選択する画面
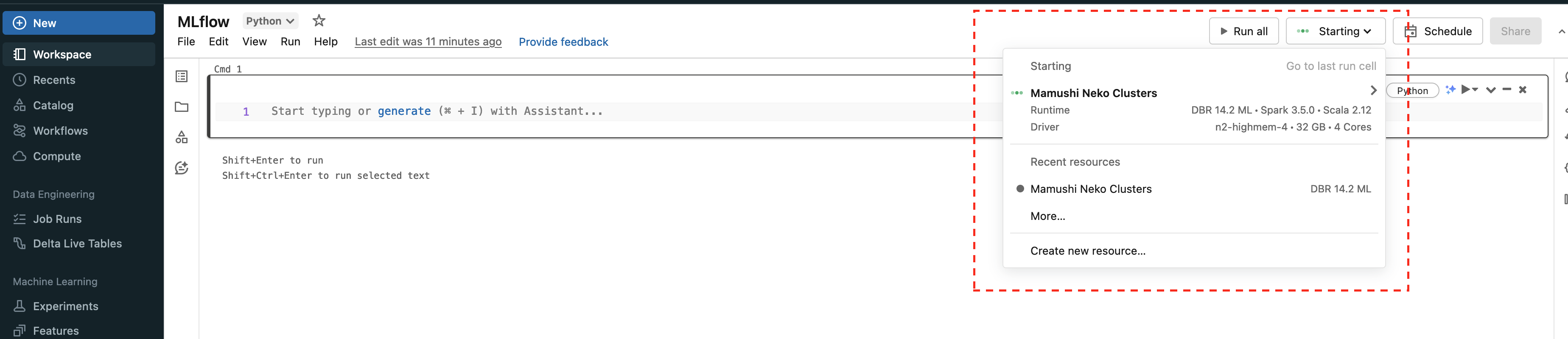
workspaceとExperimentsの連携は、Workspaceの右バーのMLflowのexperimentsのコピーマークから連携できる。
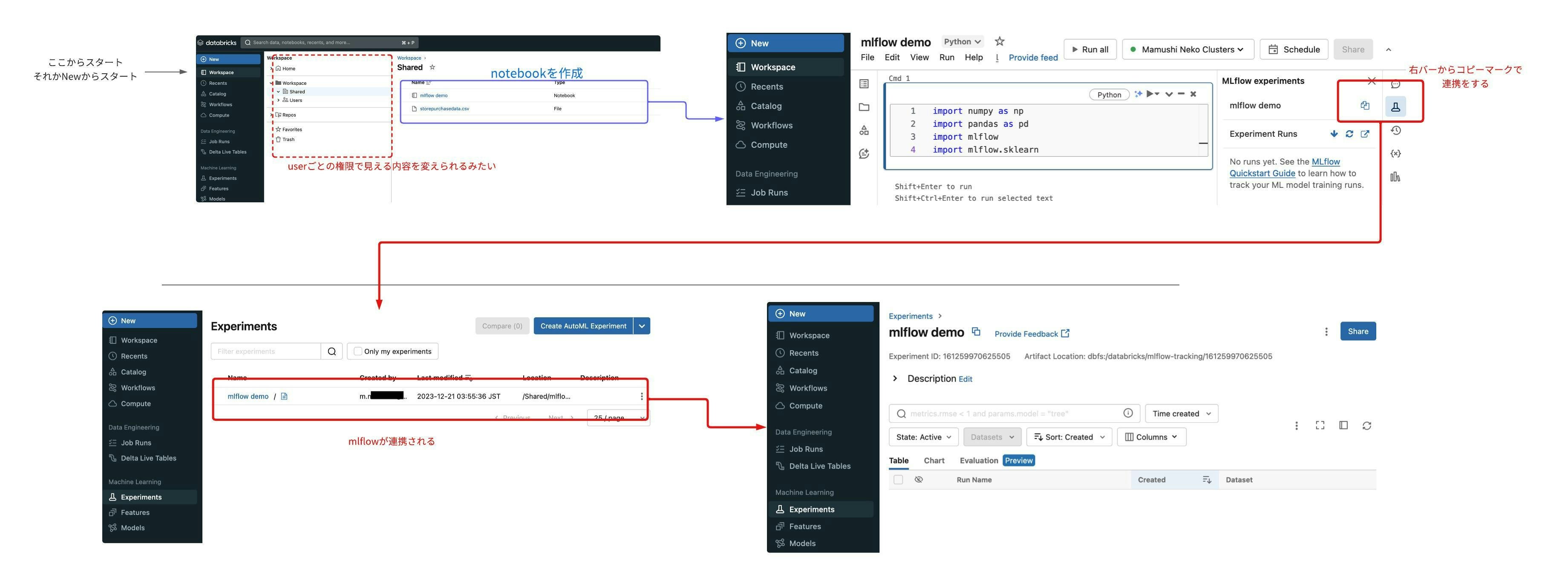
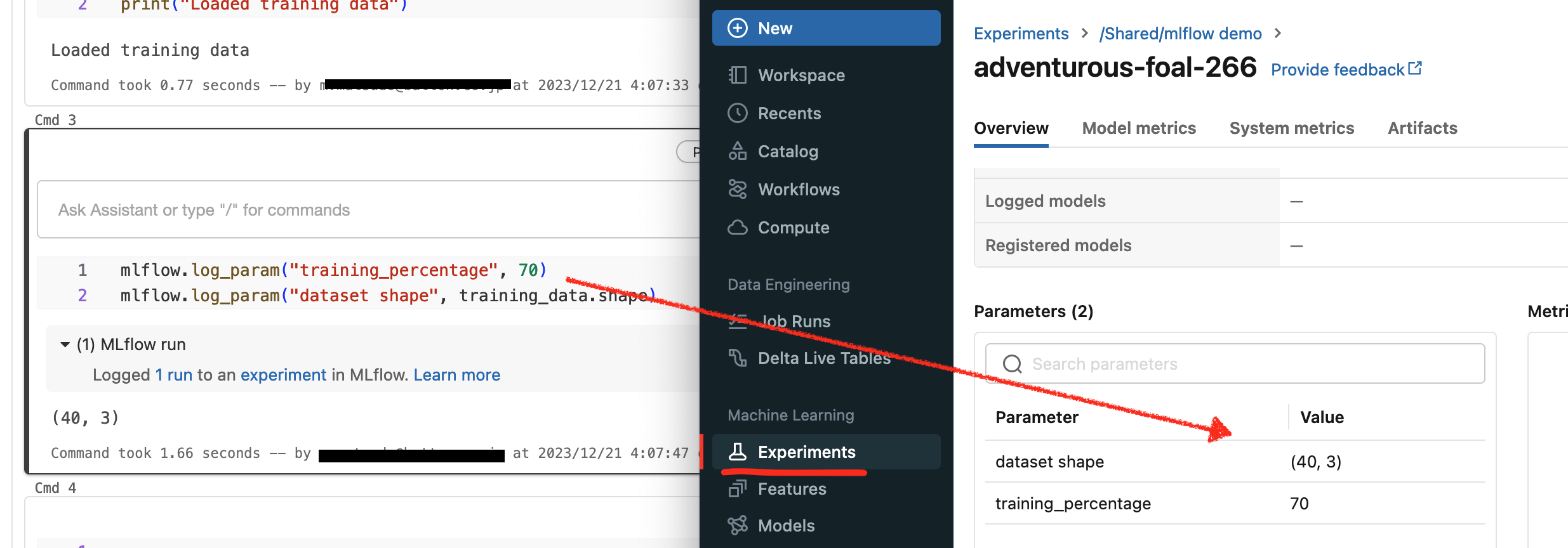
この連携が完了すると、jupternotebookで以下のようなmetircsを送ったときに、Experienceの
DashBoardで可視化されるようになる。
mlflow.log_param("training_percentage", 70)
mlflow.log_param("dataset shape", training_data.shape)
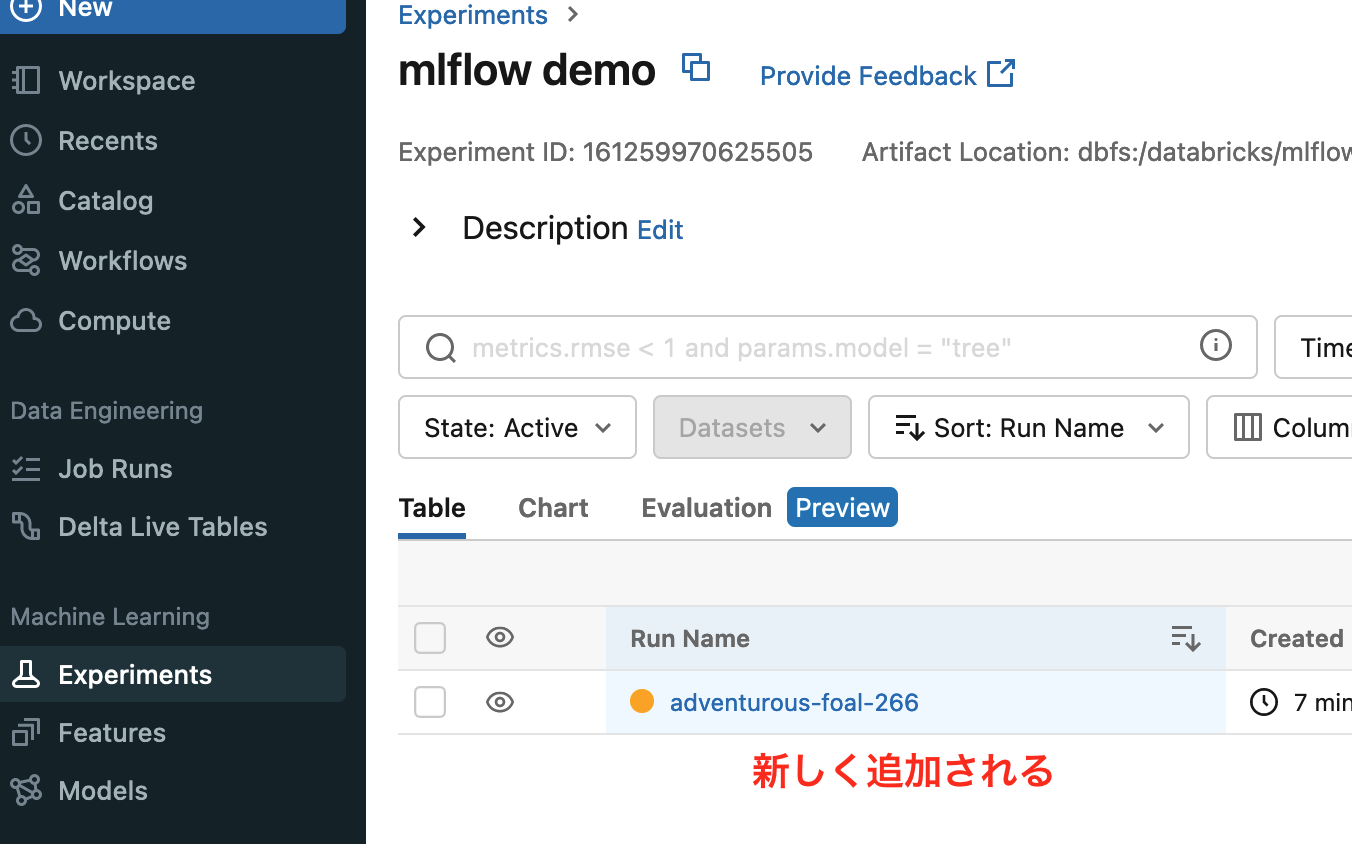
Experimentsから、ModelをDeployする
jupyternotebookで、modelのアーキテクチャを以下で送ったら(コードは最後に貼ってあります。)
Experienceでmodelをregisterできるようになります。
mlflow.sklearn.log_model(classifier, "model")
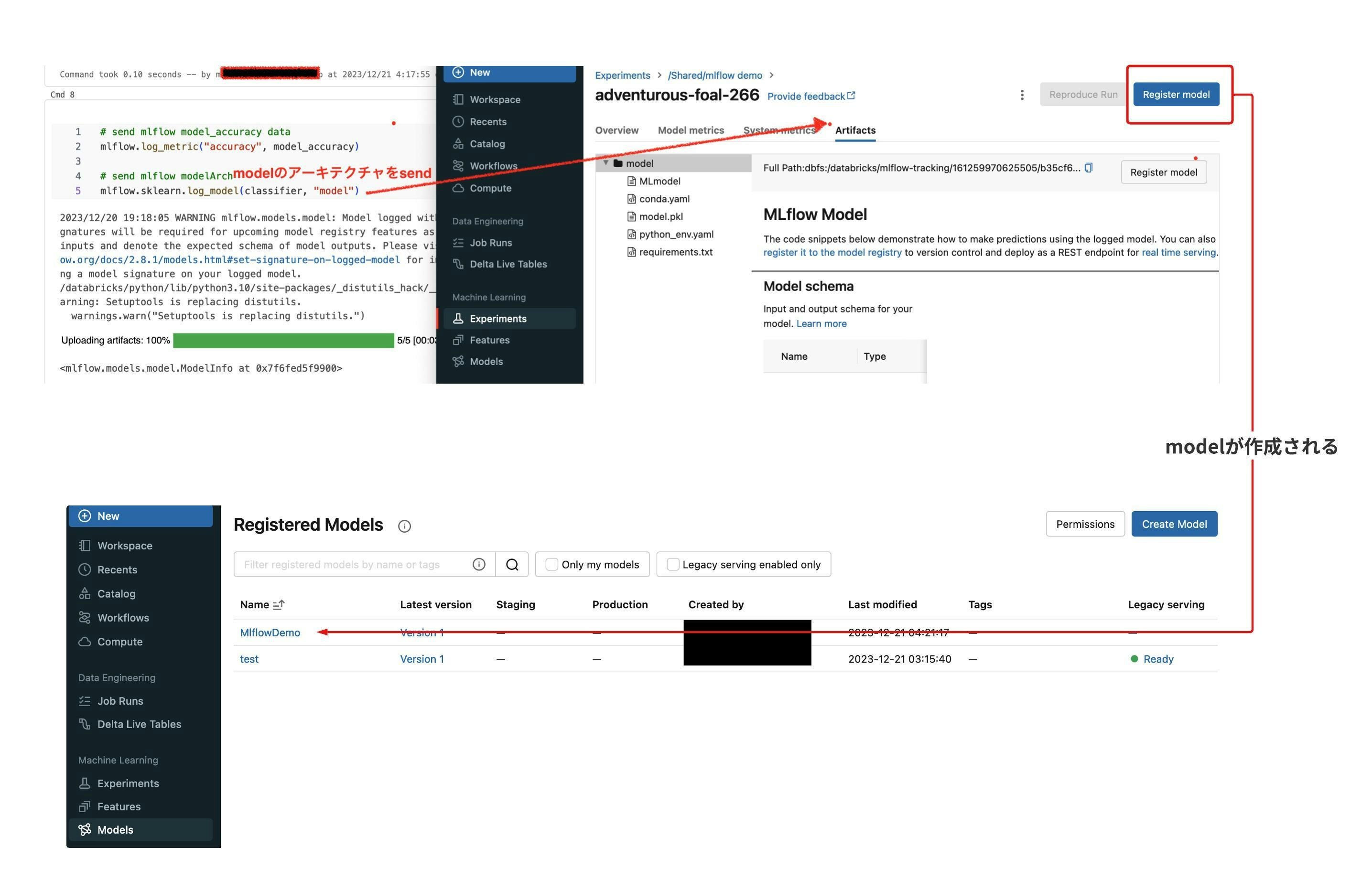
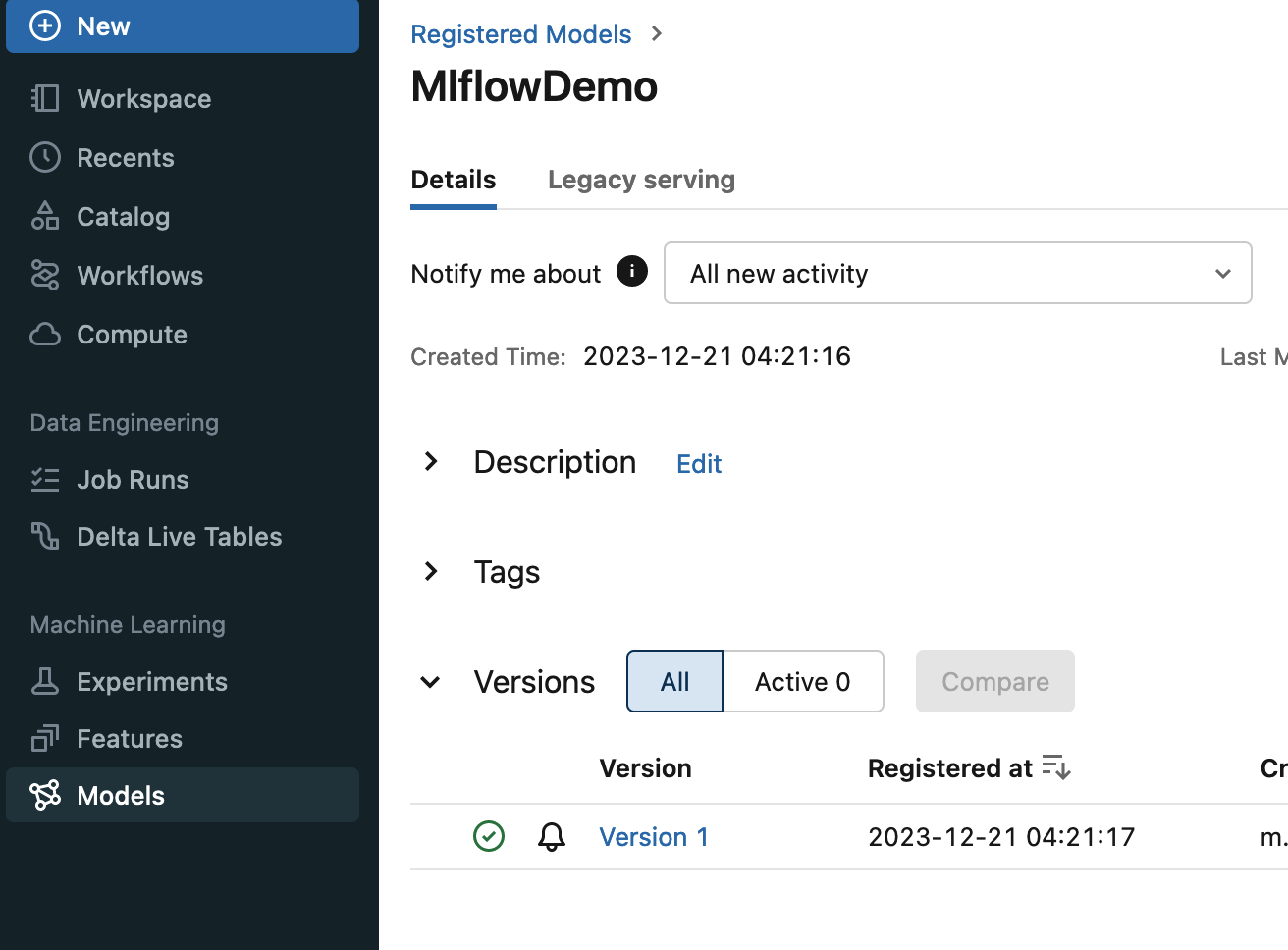
Legacy ServingというTabよりAPI Endpointを有効化します。
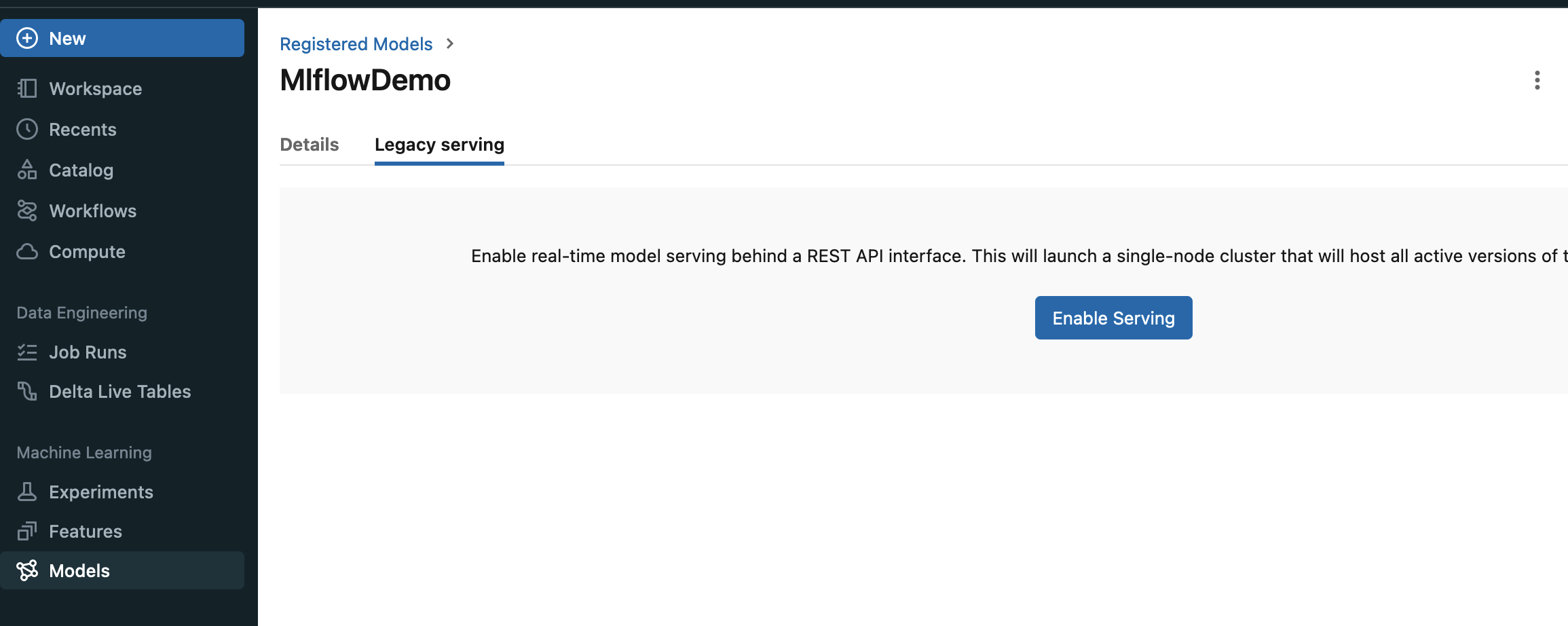
実際にEnableにすると、APIが用意されて、アクセスとmodelごとにできるようになるみたいです。
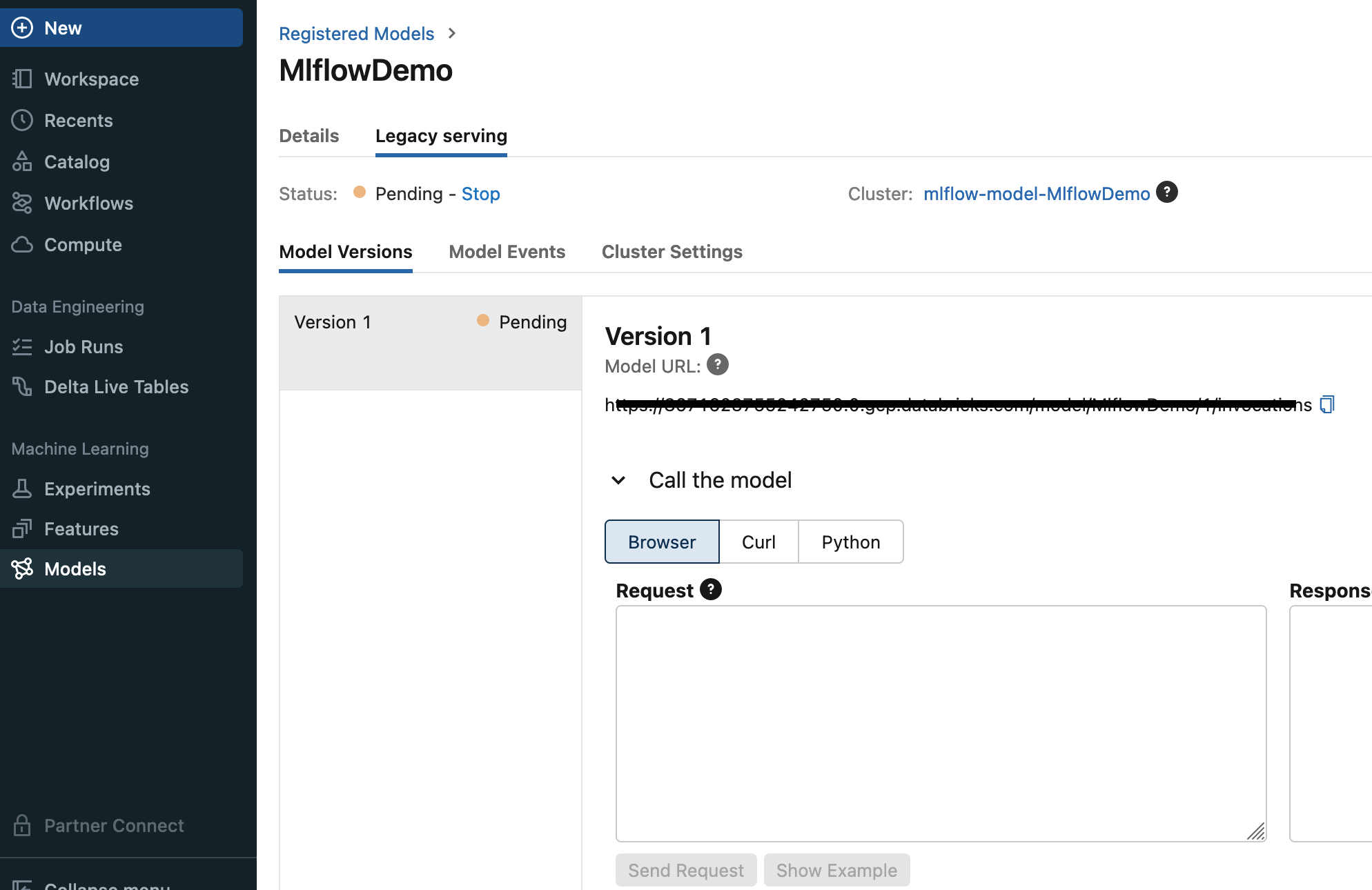
一旦ここまで!
次の記事では、定期実行とか実際の運用とか実際のコストとかを書きます。多分
あと、学習後のcomputeを消し忘れるとコストがとんでもないことになるので、消すのは忘れずに
次はこちら
今回、DataBricks上で、Model-API化するコードは以下で試してみます。
下記のsampleコードをdatabricks上においたときに、肝心のデータ部分であるstorepurchasedata.csvがworkspace/のnotebookのおいた同ディレクトリに置かないと動かないので注意ください。
import numpy as np
import pandas as pd
import mlflow
import mlflow.sklearn
# mlflow.set_experiment(experiment_name="mlflow demo")
#NOTE:これは、DataBricksでコピーiconを押したときにやってくれるのでいらない。
training_data = pd.read_csv('storepurchasedata.csv')
print("Loaded training data")
training_data.describe()
mlflow.log_param("training_percentage", 70)
mlflow.log_param("dataset shape", training_data.shape)
X = training_data.iloc[:, :-1].values
y = training_data.iloc[:, -1].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.70, random_state=0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
print("Completed Feature Scaling")
from sklearn.neighbors import KNeighborsClassifier
# minkowski is for ecledian distance
classifier = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=2)
# Model training
classifier.fit(X_train, y_train)
print("Model training")
y_pred = classifier.predict(X_test)
y_prob = classifier.predict_proba(X_test)[:, 1]
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
from sklearn.metrics import accuracy_score
model_accuracy = accuracy_score(y_test, y_pred)
print(model_accuracy)
# send mlflow model_accuracy data
mlflow.log_metric("accuracy", model_accuracy)
# send mlflow modelArch
mlflow.sklearn.log_model(classifier, "model")
次は、workspace内でのgit管理方法について