みなさん、機械学習(以下、MLにします)やってますか?私は今年になってやり始めました。今年ももう終わるんですけどね。
やり始めた背景は、MLを取り巻く環境が特に今年で一気に変化しており、例えばMicrosoftのLobeやAmazon Lookout for Vision、Google のCloud AutoML Visionなど、「振り分け済みの画像を用意すればいいんだよ」というサービスがバンバン出まして、ついに私のような人間でもMLを使える時代が来ました、ヤッホー!!!!!というお気持ちだからです。
ただ、困ったのが「画像って、どうやって準備するの?」でした。
ここでは「MLの学習に使うデータが無ければ作ればいいじゃない、デジタルなのだから!」というお話です。
ちなみに私のAI/MLに関する知識レベルは皆無と言っても過言ではありません。これを読めば程度がわかります。
MLはデータが全てなのに。
MLでは「データが全て」というのは常識のようです。これは、推論を行うモデル作成がデータを基に行われているからですね。ゴミを入れたらゴミが出てくるを地で行くのがMLでしょう。
ただ、このデータを用意するのがめちゃんこ大変!
そもそもどのくらい用意すればいいのかわからない。本当にわからない。"機械学習 画像 用意 枚数" でググってみても、明確な答えが得られない!
MLのデータを集めてたら「仕事が終わってた」
こんな感じの「製品へのラベル貼りの品質判定をMLで行う」を考えてみます。

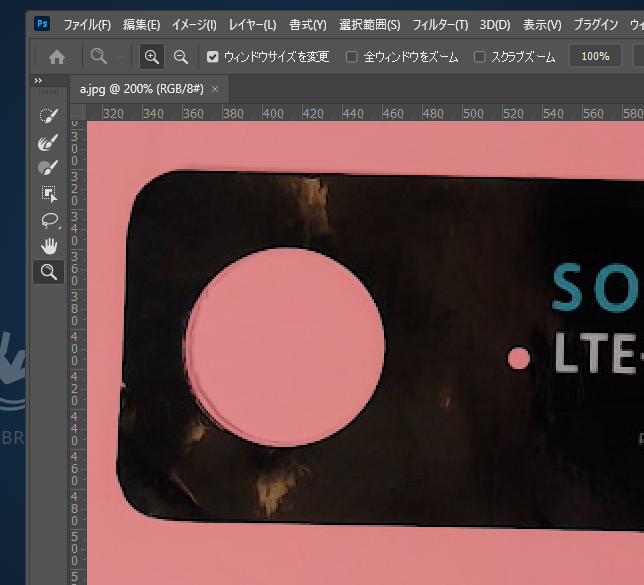
左が正常、右が異常です。あきらかにずれてますね。
最初はもちろん人間が正常/異常を判定し、振り分けつつ写真撮影をして、データ収集することになります。
さて、学習には画像が正常、異常それぞれ30枚(計60枚)必要とされた時、出荷数が60未満だったら既に仕事が終わってるわけです。また、異常率が50%というのはあり得ないので、実際は「学習用のデータを集めてたら仕事が終わってた」となります。
学習用データの準備にはある程度の「規模」が必要
異常率を2%とした場合で異常品の画像を30枚集めるためには、出荷総数は1500になります。1500って結構な数字です。しかもこの1500は学習するための母体であるため、MLの恩恵を受けられるのは「1501個め」からです。
物体の有無や顔の識別といった、特徴がとても異なったものを推論させる場合は情報量が少なくても良い例もあります。ラベル貼りのような微細な違いによる正常/異常の判定は、規模が大きくないと活用すらできません。
無ければ作ればいいじゃない、デジタルなのだから!
前置きが長くなりましたが、ここからが本題です。
画像と言ってもデジタルデータですから、捏造加工して作り出してしまえばいいじゃない、というのがこの記事の主旨とです。
画像の加工にはPhotoshopが便利
先のラベル貼りを例にしますが、ここではラベルがずれた状態を作りたいわけです。
正常品を撮影し、ラベルだけ切り抜いて別画像(別レイヤー)にし、ずらしていけば異常品のできあがり!ということになります。
もちろんラベルを貼る前の製品とラベルを別々に撮影して、ラベルを切り抜いても同じことですね。
この切り抜きにはPhotoshopが大活躍です。この辺は "Photohsop 切り抜き" でググれは、いっぱいやり方が書いてありますので、そっちを見てください。
ちなみにラベルが貼られてしまったものしか用意できなくてもコンテンツに応じた塗りつぶしという魔法機能で塗り潰し、ラベルを貼る前の製品を作り出すことも条件によっては可能です。
最終的にはラベル貼り付け前の製品と、ラベルだけの画像と2枚用意できればOKとなります。
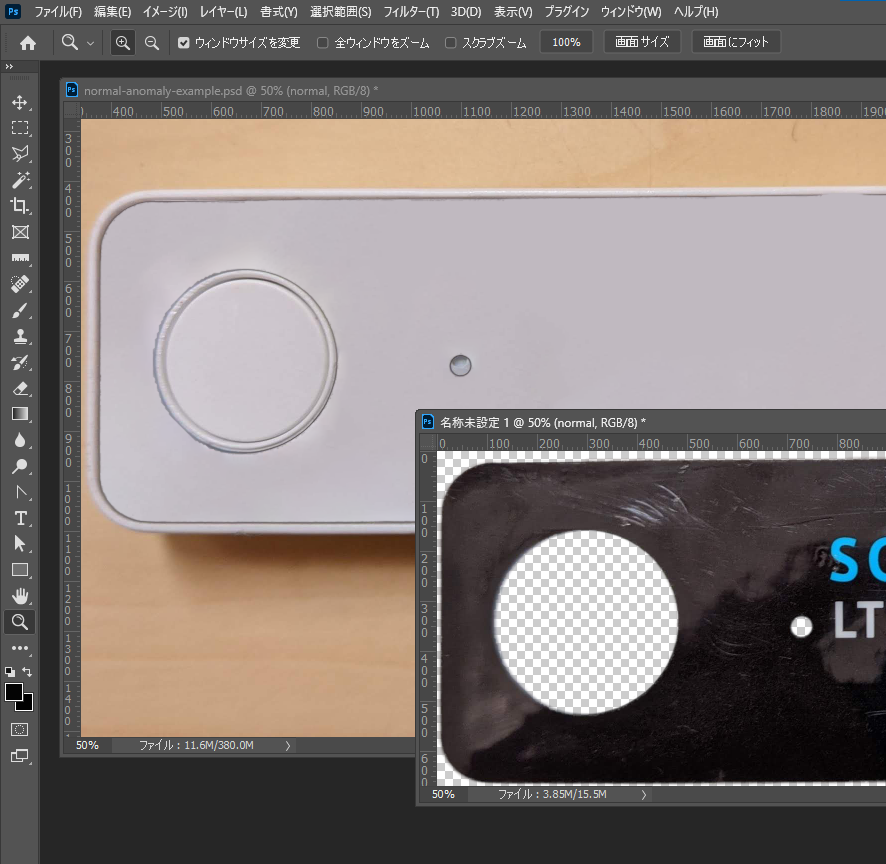
画像の合成にはImageMagickを利用
Photoshopでレイヤーをずらして保存を繰り返せば画像を作ることができますが、それを何度も繰り返すのはかなりの労力です。Photoshopにもスクリプトはありますが、今回はコマンドラインで画像操作ができるImageMagickを使います。
スクリプトで自動化できますから、大量の画像を一気に生成できます。まあ、MLの利用を考えている現場であれば「これはズルだ!」とか言われることも無いでしょうから、ここはツールの力を借りましょう。
ImageMagickを使う
ImageMagickをインストールします。いろんなOS向けのバイナリがあるので困ることは無いでしょう。
繰り返し処理自体はBashに行わせるので、Windowsの場合はWSL2 + Ubuntu等の環境をお薦めします。(私はWSL2のUbuntu 20.04で sudo apt install imagemagick としてインストールしており、以降この環境を前提に進めます)
最終的には composite が入っていればOKです。
$ convert --version
Version: ImageMagick 6.9.10-23 Q16 x86_64 20190101 https://imagemagick.org
Copyright: © 1999-2019 ImageMagick Studio LLC
License: https://imagemagick.org/script/license.php
Features: Cipher DPC Modules OpenMP
Delegates (built-in): bzlib djvu fftw fontconfig freetype jbig jng jpeg lcms lqr ltdl lzma openexr pangocairo png tiff webp wmf x xml zlib
コマンドラインで合成する
-
base.jpg= ラベル貼り付け前の製品画像 (jpg) -
label.png= ラベル画像 (png)
とした場合、以下を実行すると「正常品」を合成できます。(出力画像はjpgにしています)
$ composite -geometry +323+249 -compose over label.png base.jpg composited.jpg
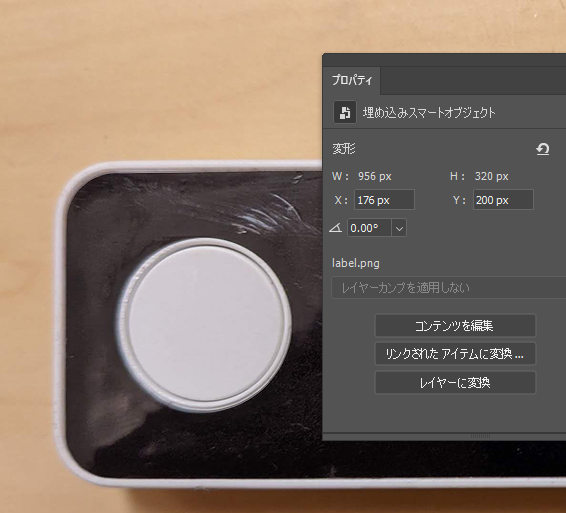
この時のポイントは -geometry です。これで label.png を重ねる位置をpxで指定します。このpxを知るにはPhotoshop上で重ねてみた後、プロパティで見るのが手っ取り早いです。
あとはこれで -geometry をずらしていく事で、正常/異常の画像を作ることができます。
seq で X と Y を生成
Bashで連番を生成するのに使えるのが seq です。for と組み合わせれば XとYを生成することができます。
もし入っていなければ coreutils あたりのキーワードで探して入れてください。
私の画像では "正常" とできる X の範囲が 321px ~ 325px、Yの範囲が 246px ~ 251px だったので、以下のようにして X と Y を生成できるようにしました。
以下の例は echo を使っていますが、ここに composite コマンドを当てはめていけば生成できることになります。
$ for X in $(seq 321 325) ; do for Y in $(seq 246 251) ; do echo "$X, $Y" ; done ; done
321, 246
321, 247
321, 248
321, 249
321, 250
321, 251
322, 246
322, 247
...
$ for X in $(seq 321 325) ; do for Y in $(seq 246 251) ; do composite -verbose -geometry +${X}+${Y} -compose over label.png base.jpg for_train/normal/${X}-${Y}.jpg ; done ; done
30枚の画像が約15秒で生成できました。
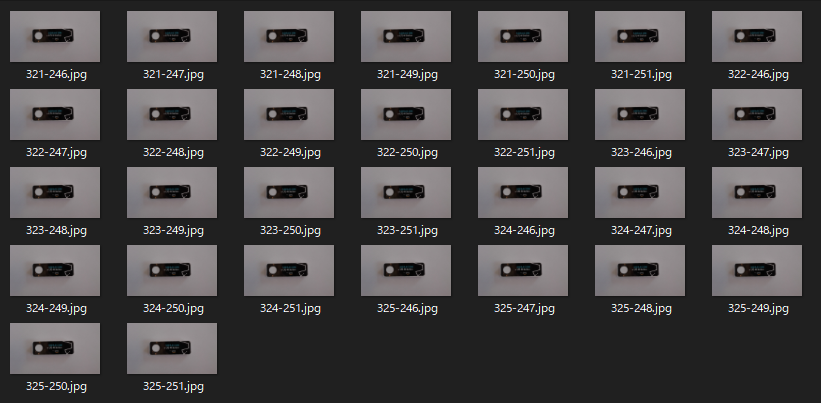
最初と最後の画像を比べると、たしかに微妙にずれています。成功ですね。
※ 左の画像を正常としていいか悩みますがw

この仕組みを使えば、今度は異常品を作り出すことができるわけです。同様に X と Y を求めて seqとforで一気に作りましょう。
出力先フォルダは "normal" と "anomaly" と分けておくと、サービスへの読み込みが楽になります
Lobeを始めとして自動でMLを調整してくれるサービス(AutoML)のほとんどが、フォルダ名をアノテーション名(ラベル名)として使う仕様になっています。そのため、出力先をそれぞれ normal と anomaly というフォルダ名にして、そこに出力しておくとこの後が便利です。
データの数は同じくらいになるように生成した方が良いようです (実際に使った画像ファイル群)
不均衡データと言うそうですが、正常/異常それぞれのケースのデータ数がかけ離れてしまうと、うまく推論できないそうです。(実際、できませんでした)
自動生成できるようになるとデータの数自体は無限に作れてしまうため、気をつけたい点です。
試した結果から言えば、ピクセル単位でのギリギリのずれを正常/異常として作るのではなく、「明らかに異常」というケースだけ作って学習させる方が意図通りに動きます。(動きました)
私は正常=30枚、異常=42枚で後半の「試してみた」を行っています。
実際に使用した画像ファイルはこちら(ZIP/24MB)です。ライセンスはCC BY-NC-ND 4.0です。
ちなみに:xargs を利用した並列処理
for; for; だと1件ずつになるため時間がかかります。xargsを使うと並列化できるので終了までの時間を短縮できます。先の例を xargs で書き換えたのが以下です。
$ for X in $(seq 321 325) ; do seq 246 251 | xargs -I YPOS -P 4 composite -verbose -geometry +${X}+YPOS -compose over label.png base.jpg for_train/normal/${X}-YPOS.jpg ; done
xgargsの詳細やオプションについてはこちらをご覧ください。
ちなみに:回転も可能
-rotate で重ね合わせる画像を回転させつつ合成できます。
重ね合わせの対象となる label.png に対しての指示をカッコで与える形です。 -rotate の値には角度を指定します。回転方向は +- で、 値には少数点もOKです。カッコはエスケープが必要になり、また前後にはスペースも必要です。-background none は label.png の背景を透過するのに必須の指定となります。
$ composite -geometry +323+249 -compose over \( -rotate -1.12 -background none label.png \) base.png rotate_composited.jpg

試してみた
Microsoft Lobe
PC上で簡単に機械学習を行えるMicrosoftのLobeを使って検証してみました。使い方は マイクロソフトが公開した機械学習モデルの訓練を容易にできる「Lobe」を試してみた。 に詳しく載っています。
まずまずの結果が得られたと思います。ちゃんと貼れているラベルに対しては安定的にnormalと推論していますし、ラベルを分離した試験用のものでも推論できています。

分離したラベルはチョット反っているため、本体から少し離れてしまっているのを検知しているのかもしれません。そう考えるとエライ。
すこし気になったのが、Lobeに画像を読み込ませた直後の学習では、normalとしてアノテーションを付与したのに「anomalyと判定しましたよ」となってしまい、まったく学習してくれませんでした。Trainメニューからアノテーションの付け替えを行いたかったのですが、なぜか行えなかったので、Playから1枚だけ normal な画像を読み込ませて手動で判定したところ、急にすべての画像が normal と推論されるようになりました。これはLobeの不具合な気がします。(説明が不自由でスミマセン)
まとめ
現物が無くてもMLができる!可能性は開かれた!?
現物が無くともML用のデータが捏造作成できたことは、今後MLに取り組む際のデータ収集の手段の一つとして使えそうです。例えば小ロット生産品の品質検査や、新製品のCADデータから作成したモデルで初回ロットから不良検査をする等、適用できそうな範囲は多そうです。
デバッグしづらいよ
ただ、思った通りの結果が出せない時の対応がロジカルでは無く、「んじゃ、この画像食わせてみるか?」みたいな、総当たり的対応をする必要があるんだなという感想でした。
この辺は "解釈可能性" というのがキーワードになりそうで、実際、GCPのExplainable AI や、AWS の Amazon SageMaker Clarifyは、MLの「なぜその結果?」に向けたサービスになっていますし、これからこういうツールを使って調整(デバッグ??)していく事になるのだと思います。
時間もお金もかかるよ
あとは推論を始められるようになるまでの時間が長い、、、Linux kernelのコンパイルか!って言うくらい長い。100枚にも満たない画像で学習に約1時間というのが早いのか遅いのがわからないけど、これじゃあ1日に5~6回しか試せない。
総当たりが求められるのに、この程度の試行回数というのが厳しいなあという感想です。クラウドサービスなので同時に複数のプロジェクトやインスタンスを動かせばいいのでしょうけれど、費用がかかるので考えちゃいますね。
あとがき
本当はLobeだけじゃなくて、別のとあるサービスも使ったんだけどプレビューなんですよね。
プレビューサービスについてはブログにしないで、、、という経験があるため、今回は掲載お見送りです!
また機会があれば公開します。(試験結果はすでに持っているので)
EoT