この記事では、2020/10/26に公開されたMicrosoftの機械学習モデル構築アプリケーション「Lobe」で機械学習による推論を行うための最小構成、ラベル当たり5枚の画像でどこまで推論できるかを調査しました。
結論、結構使える気がします。
Lobeとは
機械学習におけるモデルの作成を容易に行うことができる、PCへインストールするタイプのアプリケーション(ソフトウェア)です。
2018年にMicrosoftが買収した後にパブリックプレビューとして公開されました。
Lobeで何ができるのかについてはLobeの動画を見ていただくのが一番わかりやすいです。全編英語で字幕も英語のみですが、「水を飲んでる/飲んでない」をどのように分類するのかを10分程度で解説されています。
Lobeに読み込ませる画像の数
Lobeは1つのラベルに対して5枚以上の画像(Lobe has a minimum requirement of 5 images per label.)があればトレーニングが開始できます。
例えば物体の有無であれば「有」に5枚、「無」に5枚の、計10枚の画像で推論が開始できるという事です。
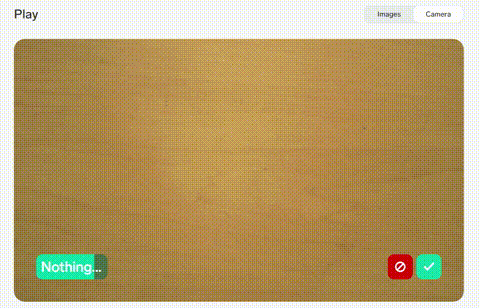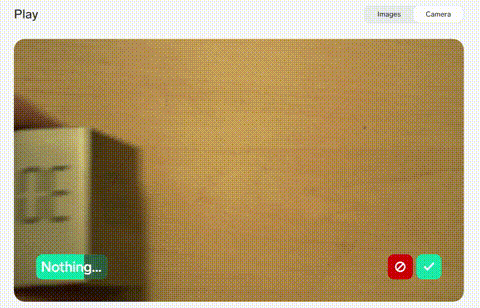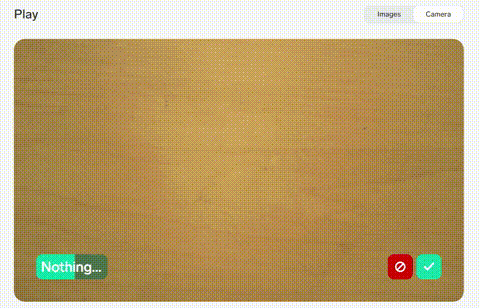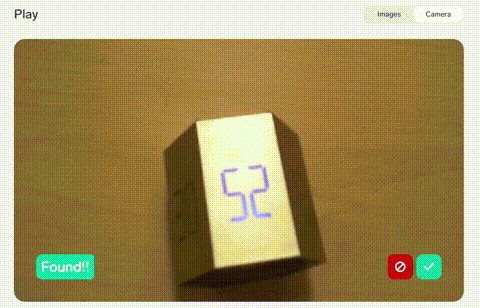
5+5=10枚の画像でやってみた様子
Found! = 5枚、Nothing... = 5枚の計10枚です。
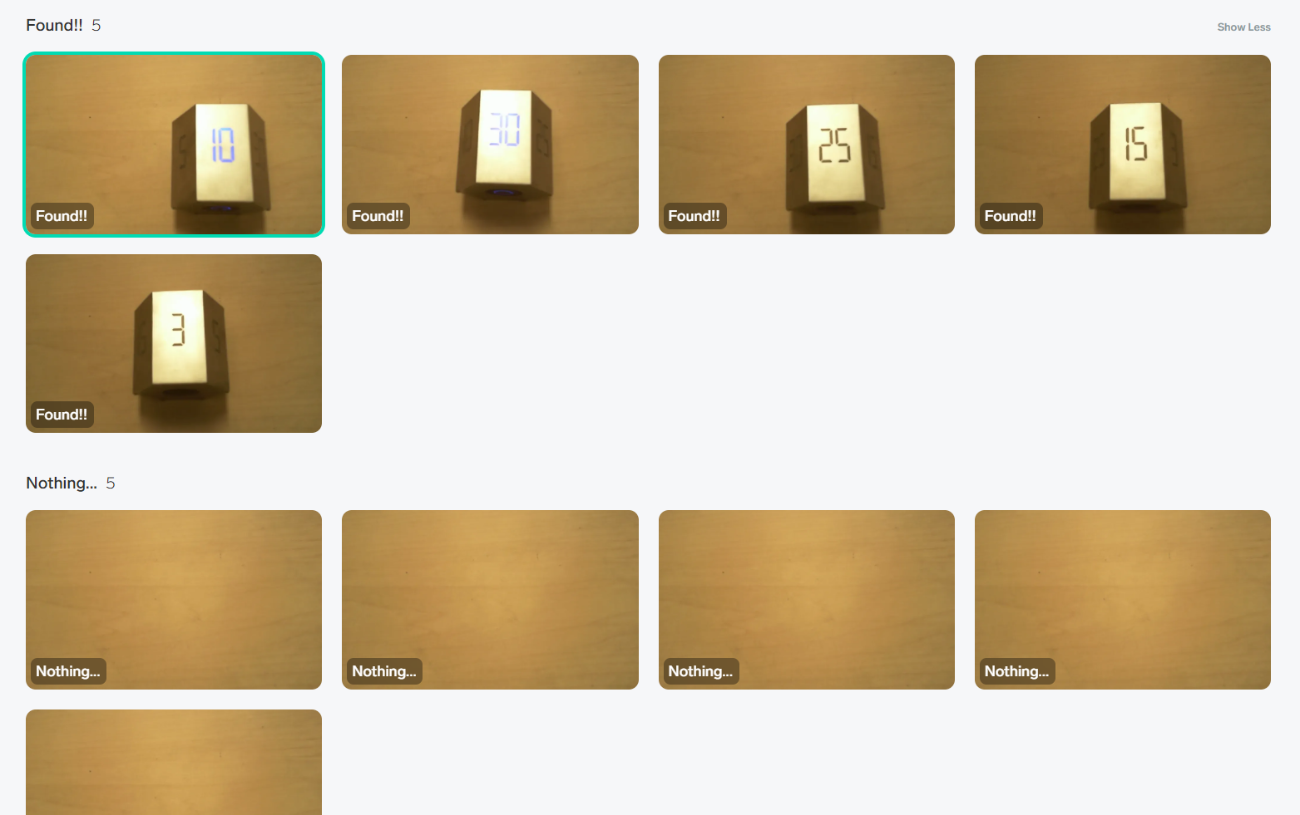
そして評価の様子が冒頭の動画です。左下の緑色が推論結果です。
位置が多少ぶれても、また、方向が変わっても推論できています。
これは「Nothing... ではない」という形での推論だと考えられ、実際、別の物体を置いても「Found!」と推論されることがありますので注意が必要ではあります。
カメラや検出したいもの、対象物の位置、光量など環境が固定化できるのであれば、かなり少ない画像量でも機械学習による推論ができるのではないでしょうか。
あとがき
IoTな視点から見るとLobeはモデルをTensorFlow、TensorFlow Liteで実行できる形式でエクスポートできるから、このモデルをRaspberry Piとかで動かせちゃうってところに魅力を感じますし、ようやっと「作る人、使う人の分業化」ができるようになったなと感じます。
[EoT]