はじめに
居酒屋で店員さんを呼ぶ声が通らず、恥ずかしい思いをしたという経験はありませんか?
そんな日常の悩みを解消するため、自宅にいながら店員さんを呼ぶ練習ができるアプリを開発しました。
本記事では、「騒音の中で声が通るかどうかを判定する技術」について解説します。
1. サービス紹介
- タイトル: 『すいませんチェッカー』
- URL: https://suimasen.jp/
- ソースコード: https://github.com/masa-oh/suimasen/
※現在はPCのみ対応しており、スマートフォンは非対応です。

-
遊び方
- 初めにステージを選びます。
- マイクボタンを押して、「すいませーん」と店員さんを呼びます。
- 判定結果が表示されます。
-
デモ動画

2. 使用技術
2-1. 主な使用技術
音声処理には、JavaScriptのブラウザーAPI(Web Audio API / MediaStream Recording API / Web Speech API)と、外部API(Google Speech-to-Text)を使用します。
フロントエンドはVue.js、バックエンドはRuby on Railsで構成しています。
2-2. 実装方針の変遷(なぜ文字起こしAPIなのか)
このサービスのコアとなる機能は、「声が通るかを判定する」ことです。
ぴったり合致する機能を提供してくれるAPIやライブラリはないため、複数の技術を組み合わせる必要がありました。
技術検討段階で、「Web Audio API」なる便利なものを使えば、音量の取得とか音声の周波数解析とかいろいろできそう!と思ったので、軽い気持ちでサービス開発に着手しました。しかし、実装途中で何度か障壁に阻まれ、解決方法を模索することとなりました。
方針その1: 音量に着目する
まず初めの方針は、「音量が一定のdBを上回ったらよく通る声とする」というものでした。
しかしいざ開発を始めてみると、Web Audio APIによる音量の取得はあくまでも個々のマイクの集音性能に対する比率でしかないことがすぐに判明し、デバイスによって判定の基準が変わってしまうという懸念が浮上しました。また、通る声というのは、単に声が大きければ良いというものではないよなとも思い、別の方法を検討することにしました。
方針その2: 周波数に着目する
次に「周波数を解析し、事前に設定した特徴を検出したらよく通る声とする」という方針に転換しました。Web Audio APIはフーリエ解析を行う機能も備えているため、取得した音声の周波数をリアルタイムでグラフに表示する機能を実装してみました。
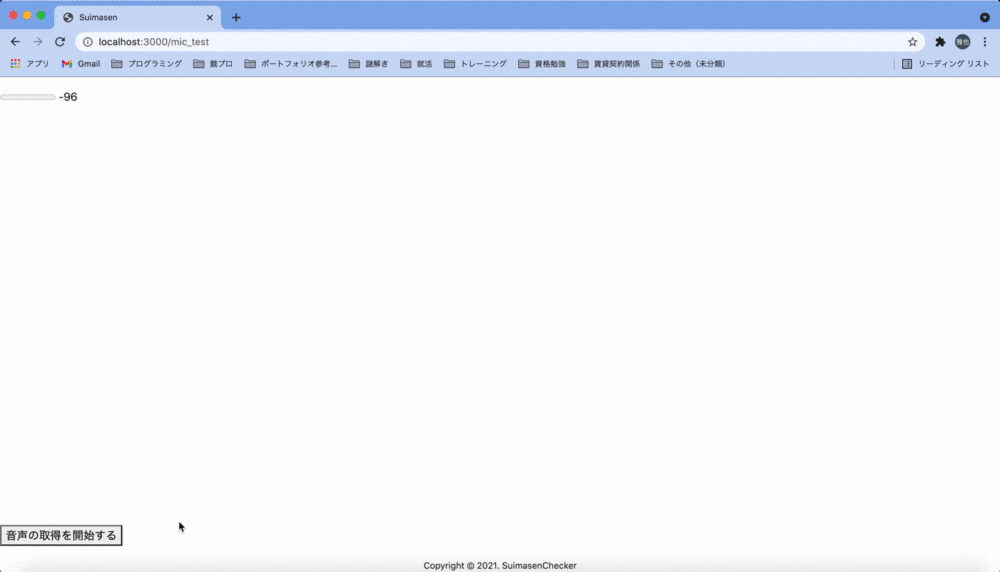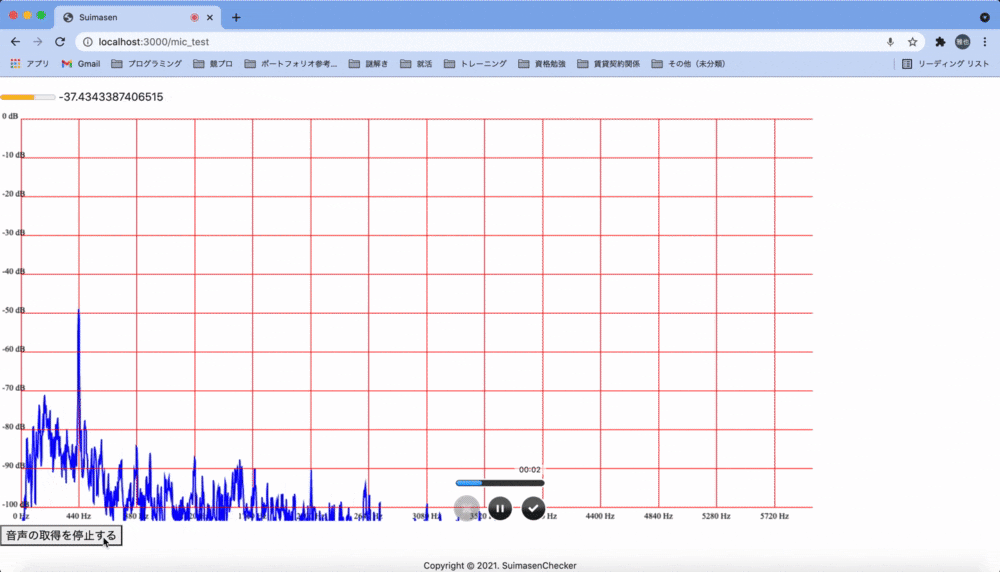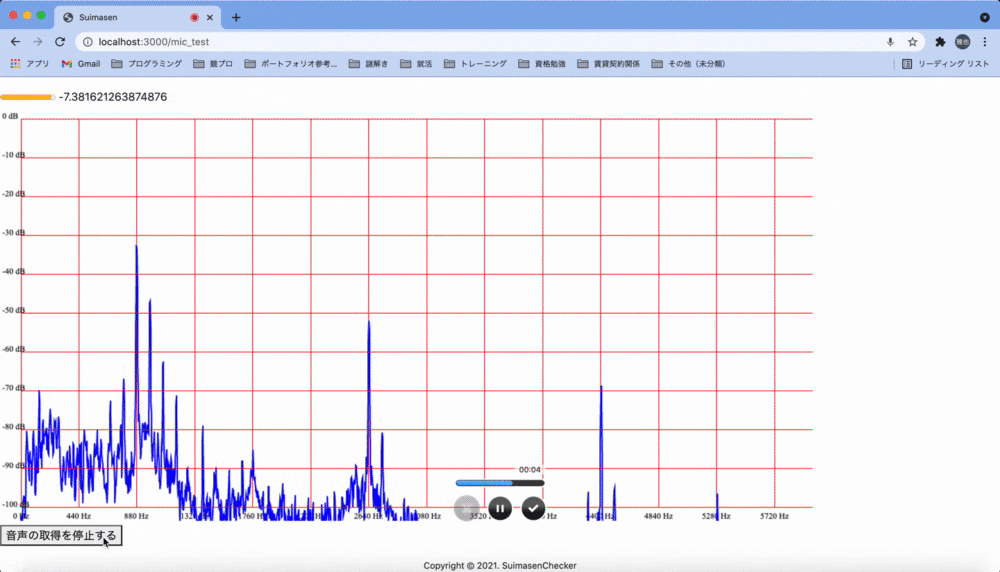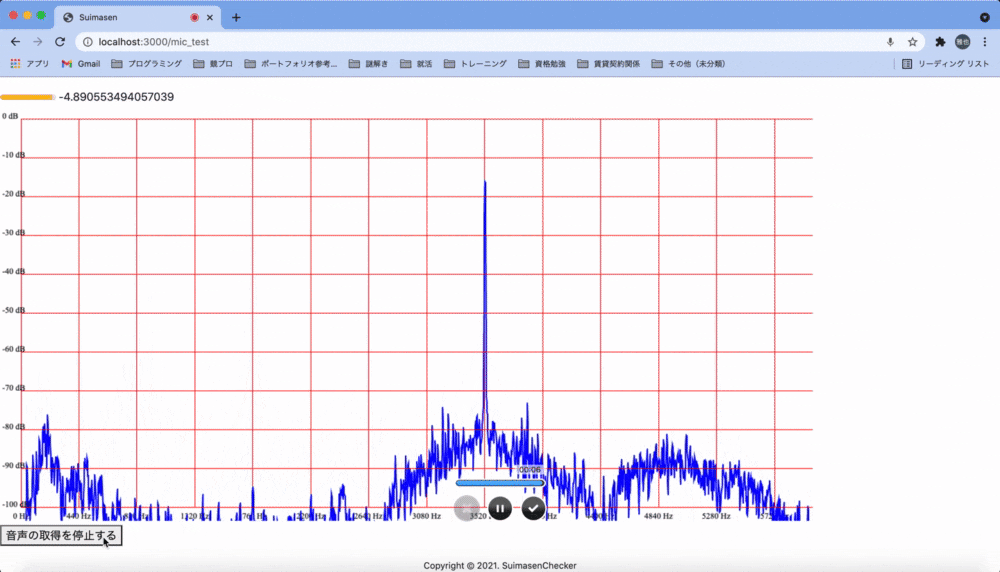
ここから極大、極小となっている点の分布データと、「3,000Hz付近の倍音が多く含まれる声はよく通る」などと言った通説を合わせることで判定ロジックを組み上げようとしましたが、私の技術力不足や音声解析についての知見の無さが露呈し、最終的には断念しました。
方針その3: 周りの環境音に着目する
また振り出しに戻ってしまいましたが、現実的に取りうる手段の中で最適な方法について思索を巡らせた結果、ふと周りの環境によって声の通りやすさが変わることに気がつきました。
そこで、いっそユーザーの音声と環境音を合成してみたらどうかと考え、「環境音との合成音声がすいませんと検出されるかどうか、文字起こしAPIで確かめる」という解決方法に至りました。
2-3. 具体的な処理の流れ
お手軽で強力な「Web Speech API」
文字起こし用の外部APIには、「Google Cloud Speech-to-Text」「Watson Speech to Text」「Amazon Transcribe」などがありますが、どれも継続的に利用するためには料金がかかり、また導入のためにアカウント登録やライブラリのインストール、設定ファイルの記述等の下準備が必要です。
その点「Web Speech API」であれば、完全無料かつ複雑な設定も一切無しで、JavaScriptで手軽にリアルタイム文字起こしを実装することができます。事前検証の結果、精度やレスポンスも悪くなかったため、これをメインに使っていくこととしました。
Web Speech APIの制約
ただ、難しい設定が要らないという強力なメリットがある一方で、デメリットもありました。Web Speech APIでは、文字起こしの入力ソースを選択することができず、デフォルトでデバイスのマイクから入力される音声を文字起こしします。少なくとも私の調べた限りでは、localStorageに存在するBlobや、mp3等の音声ファイルの中身を文字起こしすることはできないようでした。
この制約により、Web Speech APIに「環境音と合成した音声を再度文字起こしする」役割を担わせることはできませんでした。
別の文字起こしAPIとの併用
上記制約を回避するため、少々複雑にはなるものの、次のような手法を取りました。
- Web Speech APIで「すいません」と認識できた場合は、その音声を環境音と合成してBlobを作成する
- 作成したBlobを外部API(Google Speech-to-Text)に送り、文字起こしを行う
文字起こしAPIに投げるための音声データは、録音機能を持つMediaStream Recording API、音声合成機能を持つWeb Audio APIを利用して作成します。
なお、Google Speech-to-Textの選定理由の1つに、Web Speech APIとの親和性が挙げられます。
Web Speech APIは元々Chrome向けに作成されたAPIであり(参照1)、音声はGoogleのサーバーに送信された上で文字に変換される(参照2)ことから、2度の文字起こしでの認識の誤差を小さくするため、GoogleのAPIを使うことにしました。
概略図
音声処理の一連の流れを図に起こしたものがこちらです。
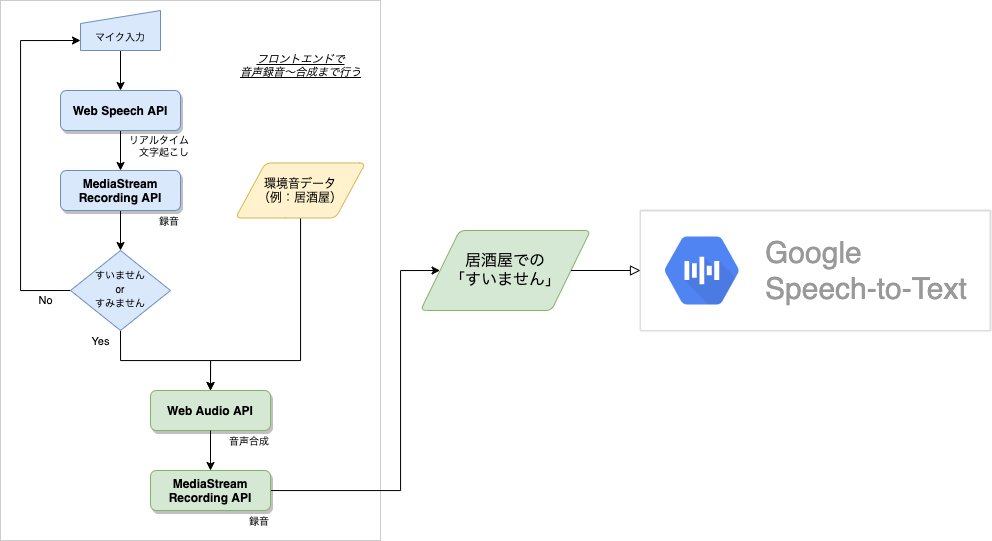
3. ソースコード解説
ここではマイク入力の取得→文字起こし→録音→合成→アップロード→判定の一連の流れについて、ポイントを絞って解説します。
実際のコードはGitHubに上げているので、詳しくはそちらをご覧ください。
音声測定画面の構造は以下のようになっており、ボタンのclickイベント発火時にstartListeningメソッドが実行されます。
<template>
<v-btn @click="startListening">
</template>
<script>
export default {
data() {
return {
// データを定義
}
},
methods: {
// メソッドを定義
}
}
</script>
3-1. マイク入力の取得
startListeningメソッドの中では、マイク入力によって生成されるMediaStreamオブジェクトをnavigator.mediaDevices.getUserMediaメソッドで受け取ります。
次にマイク入力のMediaStreamを指定して、MediaRecorderオブジェクトを作成することで、録音の準備が整います。
続いて、音声の文字起こしを行う処理を記述していきます。
<script>
export default {
methods: {
startListening() {
navigator.mediaDevices
.getUserMedia({ audio: {
echoCancellation: true,
echoCancellationType: 'system',
noiseSuppression: false
}})
.then(stream => {
this.stream = stream
// 録音APIの準備
this.recorder = new MediaRecorder(stream);
// 音声認識を開始
this.startSpeechRecognition(stream);
})
},
}
}
</script>
3-2. 文字起こし/録音
Web Speech APIが提供するのは文字起こし機能のみなので、ユーザーが「すいません」と発話している間に、別のAPIを用いて録音処理も並行して走らせるようにします。
実行タイミングの制御は、以下の記事を参考に、Web Speech APIのイベントハンドラーを利用することで行いました。
startSpeechRecognitionメソッドを作成し、文字起こしを開始する前に、各種イベント発火時の処理を定義しておきます。
音声入力開始時に発火するイベント(onaudiostart)、音声認識結果が返ってきた時に発火するイベント(onresult)を利用し、文字起こしの認識区間で録音処理が同時に実行されるように記述します。
<script>
export default {
methods: {
// Web Speech APIでリアルタイムに文字起こしを行う
startSpeechRecognition(stream) {
this.recognition = new webkitSpeechRecognition(stream);
this.recognition.lang = 'ja'
this.recognition.interimResults = true
this.recognition.continuous = false
this.statusText = '「すいません」を聞き取り中...'
if (this.voiceOrigin.url) {
window.URL.revokeObjectURL(this.voiceOrigin.url);
this.voiceOrigin.url = null;
}
// (声でなくても)音声入力を検知した時に発火する
this.recognition.onaudiostart = () => {
// MediaRecorderで録音を開始する
this.startRecording();
}
// 音声入力の終了を検知後、音声の認識に成功すると発火する
this.recognition.onresult = (e) => {
for (let i = e.resultIndex; i < e.results.length; i++) {
let transcript = e.results[i][0].transcript;
if (e.results[i].isFinal) {
this.interimTranscript = '';
this.finalTranscript += transcript;
this.stopSpeechRecognition();
this.statusText = '解析中...';
this.stopRecording();
} else {
this.interimTranscript = transcript;
}
}
}
// 文字起こし開始
this.recognition.start();
},
}
}
</script>
上記メソッド内のstopSpeechRecognition、startRecording、stopRecordingはそれぞれ以下のように定義しています。
MediaStream Recording APIのイベントハンドラー(ondataavailable)を利用し、録音を開始する前に、後続の処理を定義しておきます。これにより、録音データが使用可能になったタイミングでBlobにアクセスするためのURLが発行され、音声合成処理へと進むことができます。
<script>
export default {
methods: {
// Web Speech APIの処理を終了する
stopSpeechRecognition() {
this.recognition.stop();
},
// MediaRecorderで録音を開始する
startRecording() {
this.recorder.ondataavailable = async (e) => {
// クライアントのメモリ上に作成された録音データのURLを発行する
this.voiceOrigin.url = await window.URL.createObjectURL(e.data);
// 録音した声と環境音を重ねる
await this.startMixing(this.srcNoise, this.voiceMixed)
.then(() => {
this.judgeSuimasen();
});
}
this.recorder.start();
},
// MediaRecorderで録音を終了する
stopRecording() {
this.recorder.stop();
this.stream.getTracks()[0].stop();
},
}
}
</script>
3-3. 音声合成
音声合成は、かなり無理がありますが、全てフロントエンドで行っています。
まずJavaScriptでaudioタグ(HTMLElement)を2つ作成し、一方のsrc属性には「すいません」の録音データ、もう一方のsrc属性には事前に用意した環境音の音声ファイルを指定します。
Web Audio APIのAudioContextオブジェクトを作成し、各ノードを以下のように接続します。
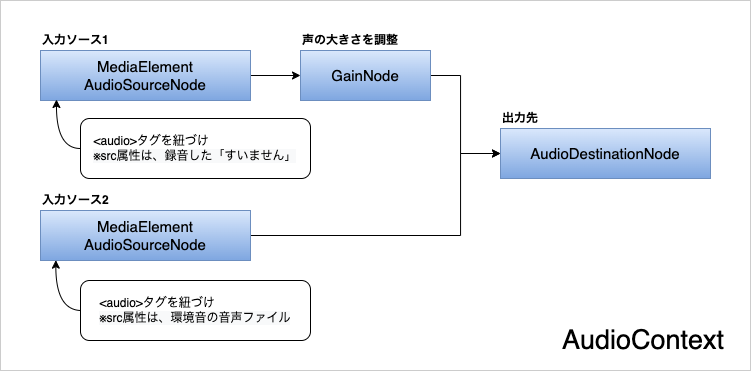
異なる2つのaudioタグを同時にplayすることで、AudioContextから2つの音源が合成された単一のMediaStreamが出力されるので、それをMediaStream Recording APIで受け取って録音するという方法で行っています。
ただしこのままだと、入力ソースが2つあるという情報が、最終的に生成されるバイナリデータのヘッダーに残ったままになってしまいます(audio_channel_countが2となる)。これにより、Google Speech-to-Textに音声ファイルを渡すところでエラーが発生します。
というのも、Google Speech-to-Textでは複数話者がいる場合の音声識別機能が提供されており、話者の数をファイルヘッダーのaudio_channel_countで判定しているのですが、今回は単一の話者として判定させたいので、audio_channel_countが1になるようにしなければなりません。
この問題は、出力ノードであるAudioDestinationNodeオブジェクトのプロパティをchannelCount = 1と明確に指定することで解決できます。AudioContextの仕様で、入力ノードの数と出力ノードのchannelCountが一致しない場合、ステレオからモノラルへのダウンミックスを自動で行ってくれるようです。(参照:Web Audio API 公式ドキュメント(英語))
<script>
export default {
methods: {
async startMixing(noiseFile, audioElement) {
console.log("startMixing");
// Audioの出力先を作る
this.ctx = new AudioContext();
this.destination = this.ctx.createMediaStreamDestination();
// 入力チャネルが複数あるので、ステレオからモノラルへのダウンミックスを行う
this.destination.channelCount = 1;
// 仮想のaudio要素を作り、src属性に録音した音声データを持たせる
let audioOrigin = document.createElement('audio');
audioOrigin.src = this.voiceOrigin.url;
// 仮想のaudio要素を作り、src属性に環境音データを持たせる
let audioNoise = document.createElement('audio');
audioNoise.src = noiseFile;
// それぞれのMediaSourceを作成する
this.srcOrigin = this.ctx.createMediaElementSource(audioOrigin);
this.srcNoise = this.ctx.createMediaElementSource(audioNoise);
// 音声はボリュームを小さくするフィルターを通す(gain.valueは最小が0、最大(デフォルト)が1)
this.gain = this.ctx.createGain();
this.gain.gain.value = this.stage.gain_value;
// 作成したMediaSourceに、両方とも同じ出力先を設定する
this.srcOrigin.connect(this.gain).connect(this.destination);
this.srcNoise.connect(this.destination);
// 仮想audio要素の音を再生する
audioOrigin.play();
audioNoise.play();
// MediaRecorderで録音を開始する
this.recorder = new MediaRecorder(this.destination.stream);
this.startMixRecording();
// 録音処理が終了するのを待つ
await (() => {
return new Promise(resolve => {
audioOrigin.addEventListener("ended", async () => {
await this.completeMixing(audioElement);
await resolve();
}, { once: true });
});
})();
},
completeMixing(audioElement) {
this.recorder.ondataavailable = (e) => {
this.audioChunks = [];
this.audioChunks.push(e.data);
audioElement.url = window.URL.createObjectURL(e.data);
}
this.recorder.stop();
this.srcOrigin.disconnect(this.gain);
this.gain.disconnect(this.destination);
this.srcNoise.disconnect(this.destination);
},
// MediaRecorderで録音を開始する
startMixRecording() {
this.recorder.start();
},
}
}
3-4. APIへのアップロード
APIとの通信は、バックエンド(Rails)で行わせるようにしました。
今回はformDataにBlobを詰め込み、axiosでRails APIのエンドポイントにPOSTすると、判定結果がJSONで返ってくる、といった実装方針としました。
Google Speech-to-Textの設定は、以下の記事などを参考にしました。
フロントエンド側のコードはこちらです。
<script>
export default {
methods: {
async judgeSuimasen() {
// 元の音声が「すいません」の場合処理を続行
if (this.pattern.test(this.finalTranscript)) {
// 録音した音声を環境音と重ねてサーバーに送る処理
this.statusText = '通信中...';
let formData = new FormData();
await this.waitAudioChunks();
this.audioBlob = new Blob(this.audioChunks, {
'type' : `${this.recorder.mimeType}`
});
formData.append('voice', this.audioBlob);
let config = {
headers: {
'content-type': 'multipart/form-data'
}
};
await axios.post('/api/games', formData, config)
.then(res => {
this.result.transcript = res.data.transcript
this.result.confidence = res.data.confidence
this.isJudged = true
this.isRunning = false
this.statusText = '測定完了!気づいてもらえたかな…?'
}).catch(err => {
console.log(err)
})
} else {
this.statusText = '「すいません」と言って店員さんを呼ぼう!'
this.isRunning = false
}
},
}
}
</script>
バックエンド側のコードはこちらです。
class Api::GamesController < ApplicationController
def index; end
def create
game = Game.new
game.transcribe(game_params[:voice])
if game.save
render json: game
else
render json: game.errors, status: :bad_request
end
end
private
def game_params
params.permit(:voice)
end
end
class Game < ApplicationRecord
def transcribe(audio_file)
require 'google/cloud/speech'
# サービスアカウントの接続情報を記したファイルのパスを環境変数に格納
ENV['GOOGLE_APPLICATION_CREDENTIALS'] = File.expand_path('../../../config/gcp_key.json', __FILE__)
speech = Google::Cloud::Speech.speech
config = { language_code: 'ja-JP' } # 日本語に設定
audio = { content: audio_file.read } # 文字起こししたいファイルの中身を渡す
# APIを叩いて、結果を受け取る
response = speech.recognize config: config, audio: audio
self.transcript = response.results.present? ? response.results.first.alternatives[0].transcript : ''
self.confidence = response.results.present? ? response.results.first.alternatives[0].confidence : 0
end
end
これで音声取得〜結果判定までの一通りの流れは完了です。
4. 注意点と今後の課題
音声合成処理の部分は、複数のAPIを駆使してかなり無理やり作っています。
正常に動作するかどうかはブラウザの仕様やフロントエンドAPIへの対応状況に大きく依存するところがあり、実際に今のコードではスマートフォンで動かない要因が至る所に存在しています。(一例を挙げると、音声合成処理の中でaudioタグのplayメソッドを実行していますが、モバイルSafariでは悪意のあるスクリプトの実行を防ぐために本処理がブロックされてしまいます。)
フロントエンドで行うのは一度目の音声の録音までにして、音声合成処理は別の方法でバックエンドで行うようにするなど、他の方法を模索していきたいところです。
おわりに
このサービスを具現化するにあたって、「声が通るかを判定する」方法を考えるところに多くの時間を費やしました。今の方法に至るまでに障壁は沢山ありましたが、既存の技術を組み合わせて、それらをどう料理するか考えて解決に導く過程が面白かったです。
本記事は、課題の解決方法に辿り着くまでの過程を残すとともに、音声処理を行うAPIの新たな活用方法を提案する目的で執筆しました。サービスを一から開発したのはこれが初めてということもあり、コードの書き方が綺麗でない箇所も多々ありますが、何卒ご容赦ください。
これから音声を使った技術に手を出そうと考えている方や、個人開発で何か作ってみたいと考えている方の参考になれば幸いです。ここまで読んでいただいてありがとうございました!