TD;TL
- Google Speech to Text APIとWeb Speech APIを併用することで実現する
- 音声検出のみWeb Speech APIを使い、文字起こし自体はGoogle Speech to Text APIを使うことで、ブラウザ文字起こしにおいてリアルタイム感と精度の高さを両立する
発端
現在開発中のプロダクトの中で、Speech to Textの仕組みを導入するために様々な方法を調べていました。
オンライン会議中の会話を文字起こししたり、アジェンダや議事録を一括で管理できるサービス「Telelogger」というサービスなのですが、コアとなる機能が会議中の会話の文字起こしです。
サービスはWebアプリケーションとして提供するため、ブラウザでの文字起こしを想定しています。
対象ブラウザをGoogle Chromeに絞った上で、最初はWeb Speech APIを試していましたが、ところどころ文字変換の精度がきになる箇所があり、さらに精度高く文字起こしできるサービスを諸々試していた中で、Gogole Speech to Text APIにたどり着きました。
個人的にWeb Speech APIとGogole Speech to Text API(以下GoogleAPI)を比較した図が下記になります。

あくまで個人的な主観ですが、GoogleAPIの方がWebSpeechAPIよりも文字起こしの精度が高く感じます。
また、GoogleAPIはREST形式なので、どのプラットフォームでも使うことができます。
そしてgRPC版であれば、GoogleAPIもストリーミング入力に対応しているのでリアルタイム性ある文字起こしができそうなのですが、gRPC版は現状ブラウザには対応していないようです。
ブラウザでのリアルタイム性についてはWebSpeechAPIに軍配が上がります。
GoogleAPIを使ったブラウザでのリアルタイム文字起こし
どうにかGoogleAPIの文字起こし精度を使いつつ、ブラウザでリアルタイムな文字起こしを行いたいと色々と試行錯誤した結果たどり着いたやり方が、音声検出(Voice Activity Detection)を用いるやり方です。
GoogleAPIはREST形式であり、音声ファイルをリクエストすると文字起こしテキストがレスポンスされます。
通常多いのは、「録音開始」ボタンを押して録音し、「録音終了」ボタンを押した際に録音終了しつつ、作成された音声ファイルをAPIに投げ、受け取ったテキストデータを表示する、というやり方だと思います。
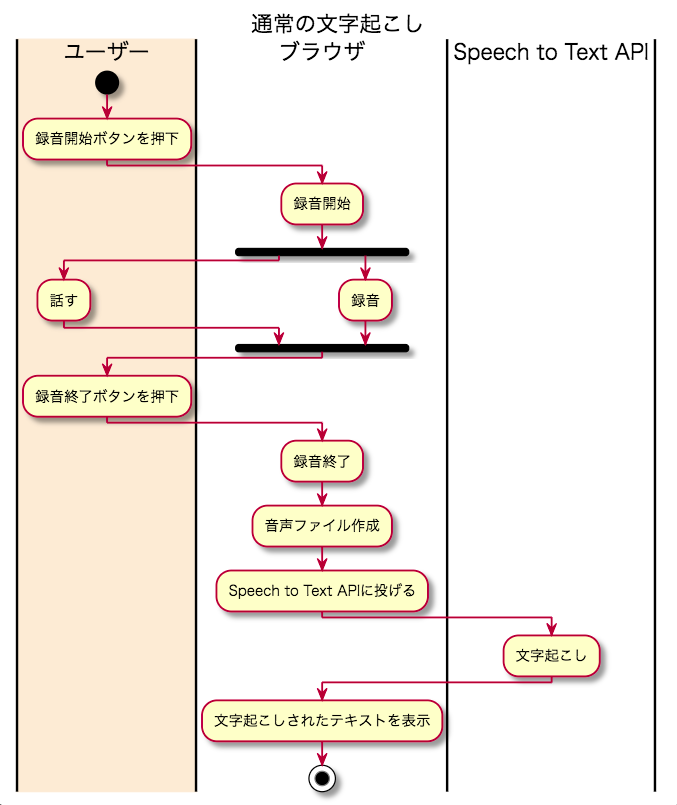
この録音開始・録音終了のトリガーを、ボタンではなく音声検出イベントをトリガーにすることで、リアルタイム感ある文字起こしを実現します。

voice-activity-detectionというライブラリがあるため、これを使いつつ文字起こししてみた結果が下記になります。

上が原文、下の枠の中に書かれているのが実際に文字起こしされたテキストになるのですが、最初の文字だけ文字起こしがうまくいっていません。
これは、音声検出が発話を始めてから2~3ワード後に開始されているからです。「OK,Google」のようなウェイクワードがないため、人間の発話タイミングに音声検出が追いついていないため、このような現象がおきます。
Web Speech APIとの併用でうまくいった!
voice-activity-detectionライブラリの中には、音声検出のための様々なパラメータがあるため、それらをいじりながら試行錯誤していたのですが、ふと「音声検出の部分はWeb Speech APIが優れているわけだし、そこと併用できないか?」という考えに思い至り、試しに組んでみたらうまくいきました!
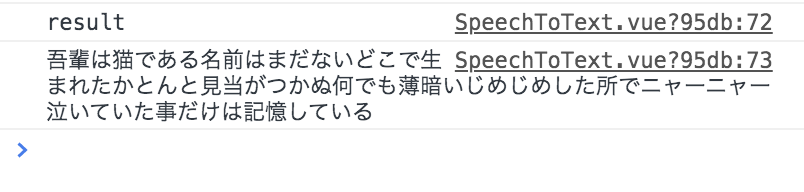
上記の通り、話し始めもバッチリ文字起こしできています。
実装したソースコードは下記のようなものになります。(今回はVueで書いてます)
<template>
<div class="wrapper">
<!-- header -->
<header class="header">
<button outlined @click="mediaRecordStart">音声認識開始</button>
<button outlined @click="stopDetection">音声認識終了</button>
</header>
<!-- body -->
</div>
</template>
<script>
export default {
asyncData() {
return {
recognition: {},
recorder: null,
status: 'init',
stream: null
};
},
methods: {
mediaRecordStart () {
const _this = this
navigator.mediaDevices.getUserMedia({ audio: {
echoCancellation: true,
echoCancellationType: 'system',
noiseSuppression: false
}})
.then(stream => {
_this.stream = stream
this.recorder = new MediaRecorder(_this.stream)
this.RunSpeechRecog(_this.stream)
this.recorder.addEventListener('dataavailable', e => {
this.audioData.push(e.data)
})
this.recorder.addEventListener('stop', () => {
const audioBlob = new Blob(this.audioData)
let reader = new FileReader()
// reader.readAsDataURL(audioBlob)
reader.onload = function () {
let result = new Uint8Array(reader.result)
let file = _this.arrayBufferToBase64(result)
// 文字起こし
const content = {
'config': {
'language_code': 'ja-JP',
'sample_rate_hertz': 44100,
'encoding': 'MP3',
'enable_automatic_punctuation': true,
'model': 'default',
'enableWordTimeOffsets': false
},
//'audio': {'uri': file}
'audio': {'content': file}
}
const apiKey = 'YOUR-API-KEY'
fetch('https://speech.googleapis.com/v1p1beta1/speech:recognize?key='+apiKey, {
method: 'POST',
headers: {
'Content-Type': 'application/json; charset=utf-8'
},
body: JSON.stringify(content)
}).then(function (response) {
return response.text()
}).then(function (text) {
const resultJson = JSON.parse(text)
if (resultJson.results[0].alternatives[0].transcript !== '') {
console.log('result')
console.log(resultJson.results[0].alternatives[0].transcript)
}
}).catch(function (error) {
console.log('error1')
console.log(error)
})
}
reader.readAsArrayBuffer(audioBlob)
})
this.status = 'ready'
})
},
RunSpeechRecog (stream) {
var flagSpeech = 0
var _this = this
// window.SpeechRecognition = window.SpeechRecognition || webkitSpeechRecognition
this.recognition = new window.webkitSpeechRecognition(stream)
this.recognition.lang = 'ja'
this.recognition.interimResults = true
this.recognition.continuous = true
this.recognition.onaudiostart = function () {
// console.log('認識中')
_this.startRecording()
}
this.recognition.onnomatch = function () {
// console.log('もう一度試してください')
}
this.recognition.onerror = function () {
// console.log('エラー')
if (flagSpeech === 0) {
_this.RunSpeechRecog(stream)
}
}
this.recognition.onsoundend = function () {
// console.log('停止中')
_this.RunSpeechRecog(stream)
}
this.recognition.onresult = function (event) {
var results = event.results
for (var i = event.resultIndex; i < results.length; i++) {
if (results[i].isFinal) {
_this.stopRecording()
_this.RunSpeechRecog(stream)
} else {
// console.log('途中経過' + results[i][0].transcript)
flagSpeech = 1
}
}
}
flagSpeech = 0
this.recognition.start()
},
stopDetection() {
this.stopVoiceDetection()
this.destroyRecording()
},
stopVoiceDetection () {
this.recognition.stop()
},
startRecording () {
this.status = 'recording'
this.audioData = []
this.recorder.start()
},
stopRecording () {
this.recorder.stop()
this.status = 'ready'
},
destroyRecording () {
this.stream.getTracks()[0].stop()
},
arrayBufferToBase64 (buffer) {
let binary = ''
let bytes = new Float32Array(buffer)
let len = bytes.byteLength
for (let i = 0; i < len; i++) {
binary += String.fromCharCode(bytes[i])
}
return window.btoa(binary)
}
}
}
</script>
↑雑モックなのでところどころエラー出ますが許してください・・・(改善コメント募集です)
ポイントは、WebSpeechAPIのonaudiostartメソッドを利用する部分です。
WebSpeechAPIにはもう一つ、onsoundstartというメソッドがありますが、こちらは音声が鳴った後、それが認識可能な音声かどうかAPI側で判断して発火するもののようで、こっちだと最初の音声認識のタイムラグは改善されませんでした。
onaudiostartであれば、音声が発せられた瞬間を検知し発火できるので、話し始めの録音に間に合います。
まとめ
これでリアルタイムかつ高精度な文字起こしを、ブラウザで実現できそうです。
ただWebSpeechAPIを使っている以上、今の所Chromeのみ対応となる点は注意です。
昨今オンラインでのやりとりが増えてきている中で、文字起こしの技術はそれを手助けするのに相性のいい技術ですので、今後こういった技術がもっと世の中に浸透するといいですね!