こんにちは。
林@アイエンターです。
前回のブログでは、Pandasやデータ可視化用のSeabornを導入し、米国自動車株の解析を行いました。
今回は再びscikit-learnにフォーカスして、機械学習のクラスタリングで用いられる「k平均法(k-means)」で画像の減色処理を行ってみます。
また、今回は画像の扱いには「OpenCV」も使ってみることにします。
k平均法での画像減色
k平均法とはWikiに詳細が記載されておりますが、空間上の点群データをk個のグループに分類するアルゴリズムです。
アルゴリズムから、各点がどこのグループに所属するかと、その各グループの重心の座標が算出できます。
今回は画像データから画素ごとのRGBを取得して、3次元空間の点群として考えます。
例えば画像を8色に減色する場合は、点群を8グループに分類します。
その後に各グループに含まれる点(RGB)の値を、重心の座標(RGB)で
置き換えることで、画像の8色化を実現します。
OpenCVでの画像の読み込み
今回はこの猫の画像を8色に減色してみます。

まずは、jupyter notebookで解析をしていく際の、基本ライブラリをインポートします。
また、今回はOpenCVを用いるのでcv2ライブラリのインポートと、
scikit-learnのclusterライブラリから、k平均法のKMeansを用いることにします。

画像の読み込みは、cv2のimread関数で簡単に読み込みができます。

読み込まれたイメージデータの中身を確認してみます。
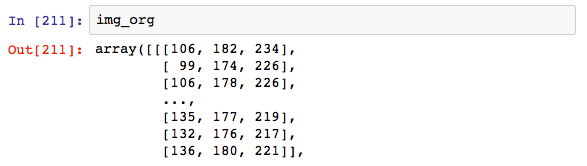
arrayになっているようです。shapeでarrayの構造を確認してみます。

縦幅640、横幅480でRGB要素が含まれた配列ということが見て取れます。
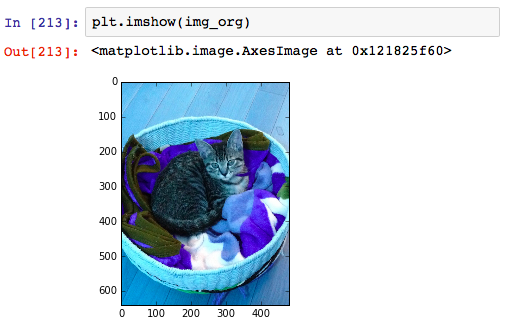
ただ、ここで注意が必要なのは、OpenCVで読み込まれたデータは、
色データはBGRの順番で格納されています。
試しにイメージをそのまま表示してみると、こんな見え方をします。
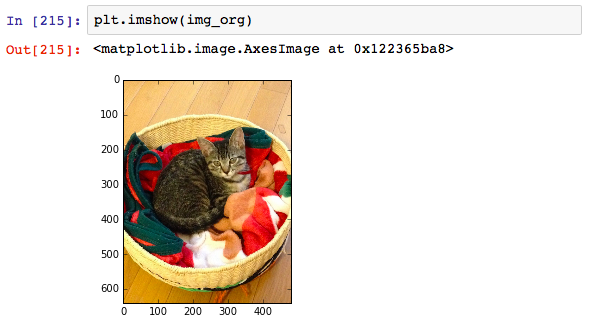
RGBの順番に変更するためには、cv2.cvtColorで変換を行います。

再度、表示してみると正しい色合いで表示されることが確認できるかと思います。
機械学習モデル KMeansでの色変換処理
KMeansのモデルデータを作成して、OpenCVで読み込んだデータを加工していきます。

イメージデータを機械学習のトレーニングデータとして扱うため、RGBデータが並んだフラットな配列に変換します。

トレーニングデータをKMeansモデルに適用します。

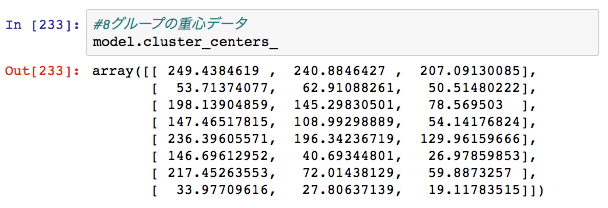
これによって、8グループの重心データ配列が取得できます。
モデルデータのcluster_centers_に格納されています。
次にトレーニングデータ自体を用いて、モデルデータで予測処理を行ってみます。

ワーニングが出ていますが以降の処理に影響しないので、そのまま進めていきます。
予測処理を行った結果のYの中身を確認してみます。

この配列は、各点群がどこのグループに所属されているかの配列データになっています。
OpenCVで扱うRGBデータは整数値なので、重心データの色配列の要素を整数化します。

変換後のイメージを生成します。
空の配列を用意して、各点について重心のRGBに変換したデータを追加して行きます。

上記で生成された配列は、OpenCVのイメージ配列の次元になっていません。
reshapeして(640×480×3)の配列に変換します。

生成されたイメージを表示してみます。
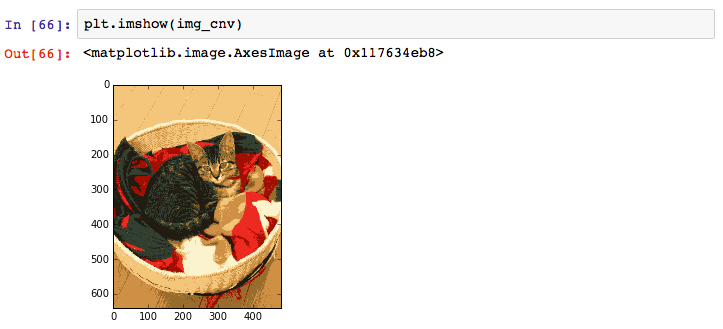
それっぽく減色されているように見えます。
最後にOpenCVで画像ファイルに出力します。
OpenCVでは色の並びはBGRでしたので、変換したイメージも同じように色の並びを変えてやります。

画像ファイルをcv2.imwriteで出力します。

以下が出力されたファイルになります。

scikit learnのKMeansモデルとOpenCVライブラリを用いることで
比較的簡単に画像の減色を行うことが出来ます。
今回のお話はここまで!