ごあいさつ
こんにちは、lucilleと申します。最近情報系を勉強したくなってpythonを独学し始めた、非情報系学生です。
この記事は、情報系を勉強する女子大生 Advent Calendar 2017 の18日目の記事です。ぜひ他の方々の記事もご覧ください。
本記事の目的
python3を使ってできることはたくさんあるらしいです。私は、「初心者でも取り掛かりやすく」て「ネットの海をかき分けて手軽に情報を集める楽しさ」を実感するために、スクレイピング(ウェブサイトに訪れ、一部を選択的に取り出す)にトライしてみることとしました。
具体的には、python3を使って、とある一つのウェブサイトをスクレイピングし(今回はビットコイン相場まとめサイト)、その内容(ビットコインの相場ごとの売買価格)をリストとしてCSVに出力するコードを書くことが本記事の狙いです。
スクレイピングやクローリングは、楽しいのですが、倫理的問題を発生させることもありうるので、気を付けます。気を付けていきましょう。岡崎市立中央図書館事件
私の環境や用意したもの
- bash on ubuntu on windows と Atom
- python3-5-2
- xpath (ウェブサイトのスクレイピングしたい要素を指定するもの)
- lxml version4.1.1
ちなみに私はpythonの仮想環境を作ってそこで処理していたので若干lxmlのインストールが煩雑です。方法は以下の通りです(参考書籍より引用)。
$brew install libxml2 libxslt #OS X の場合
$sudo apt-get install -y libxml2-dev libxslt-dev libpython3-dev zlib1g-dev #Ubuntu の場合
これを実行したあとにpip install lxmlです。
参考にしたもの
- 書籍 Pythonクローリング&スクレイピング (著:加藤耕太)※個人的圧倒的おすすめ書物。初心者がとっつきやすい。
- ウェブ記事 Python Webスクレイピング 実践入門
「時間間隔を設定しておいて、時間になったらサイトから情報を取って、スクレイピングして、出力する」という基本的な考え方を拝借しております。
解説
今回スクレイピングするサイトBitcoin相場 in 日本のうち、ページ上部の「相場データ」の表にある6つの取引所の、買板と売板をそれぞれ取得する。
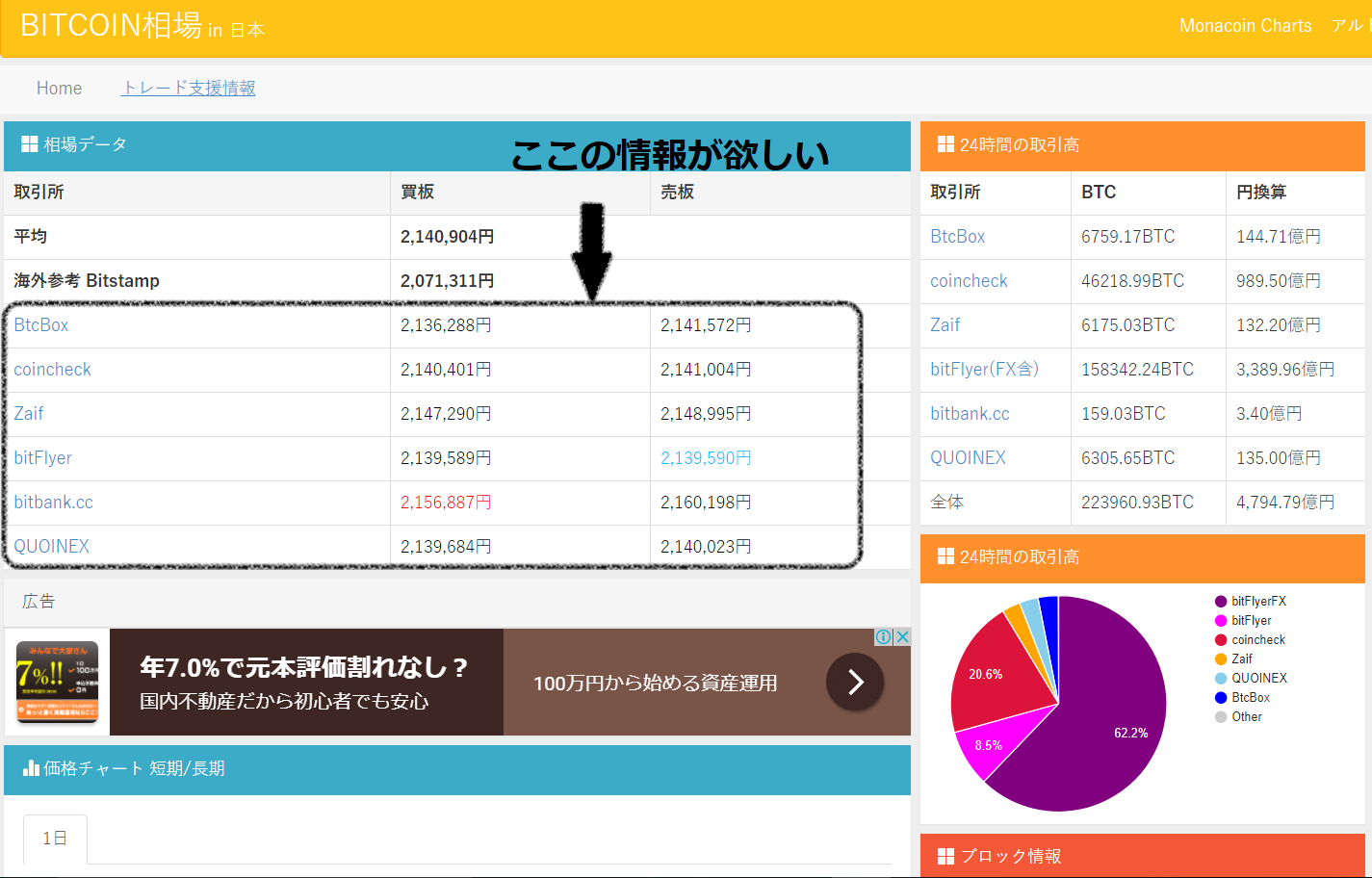
構造
ざっくり言うと、「スクレイピングする」「所定時間にファイルに書き込む」の二種の動作をやります。ただ前者は以下のような下部構造を持っています。
(1)欲しい行を複数文抜き出す
(2)(1)の1行に対して複数列抜き出す
適宜コード内にコメント書いておいたので見てみてください。
コード
# coding: UTF-8
import lxml.html
from datetime import datetime
import csv
import time
INTERVAL = 60 * 2 #待機時間の長さ設定。
# 抜き出した行から複数列を抜き出す
def get_item(tr):
exchange = None
if len(tr[0]) > 0:
exchange = tr[0][0].text
else:
return None
return (exchange, tr[1].text, tr[2].text)
# ウェブサイトから複数行を抜き出す
def do_snapshot(url, format):
snapshot = list()
retult = None
parse_html = lxml.html.parse(url)
tr_array = parse_html.xpath(format)
for tr in tr_array:
retult = get_item(tr)
if retult:
snapshot.append(retult)
return snapshot
# 取得したデータからリスト作成
def flush_handle(writer):
# 相場データ(0:取引所 1:買板 2:売板)
result = do_snapshot('http://xn--eck3a9bu7cul981xhp9b.com/',
'//div[@class="panel panel-info"]//table[@class="table table-bordered"]//tbody//tr')
# ページ下部の方の24時間の取引高(0:取引所 1:BTC 2:円換算)を取得する場合
# do_snapshot('http://xn--eck3a9bu7cul981xhp9b.com/','//div[@class="panel panel-warning"]//table[@class="table table-bordered"]//tbody//tr')
time_ = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
for item in result:
# item[0] は「取引所」の名前です。
writer.writerow([time_, item[1], item[2]])
print('APPEND:' + time_)
def do_idle():
# You can do something
pass
# 時間間隔を守りながらファイル書き込み操作
def main():
#bitcoin.csvというファイルを作り、開く。第2引数のaは追記モード。
with open('bitcoin.csv', 'a') as f:
#自動改行の設定
writer = csv.writer(f, lineterminator='\n')
#1行目に書き込む
writer.writerow(['時間', '売値', '買値'])
try:
check = 0
# 永久に実行させます
while True:
now = time.time()
#待機時間を超えた際
if now - check > INTERVAL:
flush_handle(writer)
writer.writerow(['___', '___', '___']) # 削除できます(テスト用)
f.flush()
check = time.time()
#待機時間
else:
do_idle()
#処理が中止された際の動作
except KeyboardInterrupt:
print('KeyboardInterrupt')
# Program entry
if __name__ == '__main__':
main()
おわりに
初心者と言いつつ長いコードなのは、友人の助けによるものです。コードを相当手直ししてくれた友人に感謝感激雨あられです。
みなさま、良きpython lifeを!