はじめに
fastai2でディープラーニングするにあたり、テンプレート・ベースラインになるようなNotebookを作成しました。
参考:公式チュートリアル Computer vision | fastai
🪐JupyterNotebook・ソースコード:【fastai2ベースライン】PETS、単一ラベル多クラス分類、転移学習、混同行列、モデル保存・復元、運用時の推論.ipynb - GitHub
環境
本スクリプトは、以下の環境で動作確認した。
- OS : Windows-10
- python : 3.9.10
- GPU : RTX3070Ti
- cuda : 11.3
本スクリプトでやること
- 📁データ読み込み:PETSデータセット
- 🔪前処理:256x256へ変換
- 📝学習の準備:fastaiの学習オブジェクト組立て
- 👨🎓学習:犬・猫の品種を分類
- 📊評価:混同行列
- 💾モデル保存・復元
- 📈運用:1画像だけ推論
テクニック
混合精度(Mixed Precision)
- 半精度浮動小数点数 (FP16) を使って、精度を落とさずに学習を高速化
- GPUメモリの消費が減る分、計算時のバッチサイズを大きくできる。
累積勾配(Accumulated Gradient)
Google Brainの論文「学習率を落とすな、バッチサイズを増やせ」を読む - Qiita
バッチサイズを大きくしても同様に学習率も大きくすればだいたい同じ精度でかつ高速化のメリットだけ得られる
- 計算時のバッチサイズはGPUメモリの制限で上限がある。
- 勾配を累積することで実効バッチサイズを大きくすることで、学習率が高めでも学習を安定させる。
- 例)パラメータ更新を64バッチ・1024バッチに変えたときのAccuracyの変動
- 1024バッチの方がAccuracyの収束が速く、学習が安定していることが分かる。

早期打ち切り(Early Stopping)
- モデルトレーニング中に指標が改善しなくなった時点で学習を打ち切ることで、モデルが過学習するのを防ぐ手法
- 学習エポック数を多めに指定しておけば自動的に終了してくれるので、作業が楽になるメリットもある。
その他
以下の項目は前記事参照のこと。 fast.ai初心者目線の道案内 - Qiita
- 転移学習
- WeightDecay(荷重減衰、L2正則化)
- 学習率の探索
- 1 Cycle Rule
- FineTuning(ファインチューニング)
🌱初期化
%reload_ext autoreload
%autoreload 2
%matplotlib inline
fastaiのimport
from fastai.vision.all import *
from fastai.callback.fp16 import * # Mixed Precisionで学習するときに必要
その他のライブラリのimport
from pathlib import Path
import tqdm
import json
import glob
from torchsummary import summary
import datetime
環境とfastaiのバージョン確認
%%script false
from fastai.test_utils import show_install; show_install()
# 出力例
# === Software ===
# python : 3.9.10
# fastai : 2.6.3
# fastcore : 1.3.27
# fastprogress : 1.0.2
# torch : 1.11.0+cu113
# nvidia driver : 512.77
# torch cuda : 11.3 / is available
# torch cudnn : 8200 / is enabled
# === Hardware ===
# nvidia gpus : 2
# torch devices : 2
# - gpu0 : NVIDIA GeForce RTX 3070 Ti
# - gpu1 : NVIDIA GeForce GTX 1070
# === Environment ===
# platform : Windows-10-10.0.19044-SP0
# conda env : Unknown
# python : C:/Users/User/AppData/Local/Programs/Python/Python39/python.exe
# sys.path : ...
🎨パラメータ
- 計算時のバッチサイズ(
bs_step)はGPUメモリが許す限り大きい値とした。- 計算バッチサイズがなるべく大きい方が学習が速いため。
- パラメータ更新するときのバッチサイズ(
bs_update)は、データセットサイズの約1/4以下でなるべく大きい2の倍数とした。- 1/4以下にした理由
- 前提1:確率的勾配降下法(オンライン学習、1サンプルずつ勾配更新)では、サンプル数が少ないためサンプル個体差によるノイズが大きい。このノイズには、「局所解から抜け出す」良い効果と「学習が不安定になる」悪い効果がある。
- 前提2:逆に、バッチ学習(全サンプルから勾配更新)ではノイズが最小になる。
- 全サンプルを4等分するぐらいのミニバッチサイズなら、バッチ学習の状況から遠く、ノイズが十分確保できるのではないかと考えた。
- 1/4以下にした理由
bs_step = 64
bs_update = 1024
imsize_pre=256
imsize_croped=224
np.random.seed(42)
📁データ読み込み
fastaiの機能でデータセット取得、約1.8GB
# データのルートフォルダ
img_root_path = untar_data(URLs.PETS)
データセットのフォルダ構成確認。imagesフォルダなどがある。
[p.relative_to(img_root_path) for p in img_root_path.ls()]
[Path('annotations'),
Path('crappy'),
Path('images'),
Path('image_gen'),
Path('models')]
今回はimagesフォルダのデータだけ使う。
# 前処理前の画像のフォルダ
img_original_path = img_root_path/'images'
# 前処理後の画像を配置するフォルダ
img_preprocessed_path = Path('D:/bulk/dataset/image/PETS/train256')
画像のpathへのリストを取得。画像は約7000件
files = get_image_files(img_original_path); len(files)
7390
🔪前処理
- 全画像を256x256に変換して保存する。
- 学習時に毎回リサイズしなくてよいようにするため。
前処理内容の確認
動作確認用に1枚画像を取得
img = PILImage.create(files[0])
print(img.shape)
img
(400, 600)

アス比を保ったまま、長辺が256pxになるようにリサイズ
resized = RatioResize(256)(img); resized

正方形になるようにpadding
padded = CropPad(256, pad_mode='border')(resized); padded

まとめて変換
全画像のpathのリストを取得。
ファイル名がラベルになっていて、大文字で始まるのは猫、小文字なら犬。
original_files = get_image_files(img_original_path);
[p.relative_to(img_original_path) for p in original_files[0:3]]
[Path('Abyssinian_1.jpg'),
Path('Abyssinian_10.jpg'),
Path('Abyssinian_100.jpg')]
変換実施
%%script false
%%time
folder = img_preprocessed_path
folder.mkdir(parents=True,exist_ok=True)
for p in tqdm.tqdm(original_files):
img = PILImage.create(p)
resized = RatioResize(256)(img)
padded = CropPad(256, pad_mode='border')(resized)
padded.save(folder/p.name, quality=95)
# break
📝学習の準備
DataLoadersの作成
- Data Block APIでデータセットの画像・ラベルの読み込み方法を指定。
- DataBlockからDataLoadersを作成
def label_from_path(p:Path)->str:
"画像のパスから正解ラベルを取得"
return str(p.name).split('_')[0]
dblock = DataBlock(blocks=(ImageBlock, CategoryBlock), # ImageとCategoryを1サンプルとする
get_items=get_image_files, # itemの集合の取得関数の指定。get_image_files(path)の出力、つまりPathのリストをitemsとする。
splitter=RandomSplitter(valid_pct=0.2), # train/validの分割方法。 20%をvalidにする
get_y=label_from_path, # ラベルの取得方法。 label_number(path)
item_tfms=CropPad(256), # 入力画像を読込むときの変換
batch_tfms=aug_transforms(size=imsize_croped), # バッチ処理するときの変換。オーグメンテーションを指定。
n_inp=1
)
dls = dblock.dataloaders(img_preprocessed_path, batch_size=bs_step)
Due to IPython and Windows limitation, python multiprocessing isn't available now.
So `number_workers` is changed to 0 to avoid getting stuck
クラス数の確認
dls.c
35
データ数の確認
len(dls.train_ds), len(dls.valid_ds)
(5912, 1478)
train/validの変換を確認
trainはオーグメンテーション(aug_transforms)が有効で、「歪み・見切れ」のある画像となる。
dls.train.show_batch(max_n=7**2)

validはオーグメンテーションが無効
dls.valid.show_batch(max_n=7**2)

Learnerの作成
🧩Model
今回は自作Modelを定義する。転移学習時のパラメータ固定範囲のためにsplitterが必要。
class Net(Module):
def __init__(self, arch=resnet34, nc=dls.c, pretrained=True):
self.body = create_body(arch, pretrained=pretrained)
nf = num_features_model(nn.Sequential(*self.body.children()))
self.head = create_head(nf,nc,lin_ftrs=[nc*4])
def forward(self, x):
x = self.body(x)
return self.head(x)
def splitter(model:Net):
"""
Model分割方法の指示。
転移学習のとき、どこまでパラメータ固定するか判断するのに使用する。
今回は、Modelパラメータをbodyとheadの2つに分けた。
"""
return [params(model.body), params(model.head)]
Metrics
学習中に表示する評価指標。fastai標準の関数のほかに、任意の関数を定義して利用できる。
今回は、「MAP(Mean Average Precision)@10」をMetricに追加する。
SCORE_TEMPLATE = (1/(torch.arange(10)+1)).cuda() # 例)tensor([1.0000, 0.5000, 0.3333, 0.2500, 0.2000, 0.1667, 0.1429, 0.1250, 0.1111, 0.1000])
def map10(preds:Tensor, ans:Tensor):
"評価関数「MAP(Mean Average Precision)@10」"
assert preds.ndim==2, f'期待:preds.ndim==2, actual:{preds.ndim}. (batch_size, cls_confidence)'
confidence = preds.argsort(descending=True)[:,:10]
n_sample = len(preds)
score = 0
for pred, y in zip(confidence, ans):
mask = torch.eq(pred,y).type(torch.uint8) # 正解なら1のマスク 例)TensorCategory([1, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=torch.uint8)
score += torch.sum(SCORE_TEMPLATE*mask)
return score/n_sample
Learnerを作成
model = Net()
learn = Learner(dls, model=model,
splitter=splitter,
loss_func=CrossEntropyLossFlat(), #`F.cross_entropy`だと混同行列の描画時にエラーになるので、Flat版を選択
metrics=[accuracy, map10],
cbs=[CSVLogger(), ShowGraphCallback()]
).to_fp16()
※備考
-
ShowGraphCallback() : 学習中にtrain/validのロスをグラフ表示
-
.to_fp16(): Mixed Precisionを使用

👨🎓学習
転移学習
パラメータ固定
headだけを学習対象にする。
learn.freeze()
learn.summary()
Net (Input shape: 64 x 3 x 224 x 224)
============================================================================
Layer (type) Output Shape Param # Trainable
============================================================================
64 x 64 x 112 x 112
Conv2d 9408 False
BatchNorm2d 128 True
ReLU
____________________________________________________________________________
64 x 64 x 56 x 56
MaxPool2d
Conv2d 36864 False
BatchNorm2d 128 True
ReLU
(中略)
Conv2d 36864 False
BatchNorm2d 128 True
Conv2d 36864 False
BatchNorm2d 128 True
ReLU
Conv2d 36864 False
BatchNorm2d 128 True
Conv2d 36864 False
BatchNorm2d 128 True
ReLU
Conv2d 36864 False
BatchNorm2d 128 True
____________________________________________________________________________
64 x 128 x 28 x 28
Conv2d 73728 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
Conv2d 8192 False
BatchNorm2d 256 True
Conv2d 147456 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
Conv2d 147456 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
Conv2d 147456 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
____________________________________________________________________________
64 x 256 x 14 x 14
Conv2d 294912 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 32768 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
____________________________________________________________________________
64 x 512 x 7 x 7
Conv2d 1179648 False
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 False
BatchNorm2d 1024 True
Conv2d 131072 False
BatchNorm2d 1024 True
Conv2d 2359296 False
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 False
BatchNorm2d 1024 True
Conv2d 2359296 False
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 False
BatchNorm2d 1024 True
____________________________________________________________________________
64 x 512 x 1 x 1
AdaptiveAvgPool2d
AdaptiveMaxPool2d
____________________________________________________________________________
64 x 1024
Flatten
BatchNorm1d 2048 True
Dropout
____________________________________________________________________________
64 x 140
Linear 143360 True
ReLU
BatchNorm1d 280 True
Dropout
____________________________________________________________________________
64 x 35
Linear 4900 True
____________________________________________________________________________
Total params: 21,435,260
Total trainable params: 167,612
Total non-trainable params: 21,267,648
Optimizer used: <function Adam at 0x0000021ADEDE6040>
Loss function: FlattenedLoss of CrossEntropyLoss()
Model frozen up to parameter group #1
Callbacks:
- TrainEvalCallback
- MixedPrecision
- Recorder
- ProgressCallback
- CSVLogger
- ShowGraphCallback
bodyだけパラメータ固定され(Trainable列がFalse)、head(AdaptiveAvgPool2d以降)は学習対象であることが分かる。
- bodyのBatchNormはTrainableがTrueの理由
- 転移学習では統計量が異なるケースが多いため、転移学習時にbodyの正規化層も学習する。
- 参考 Why are BatchNorm layers set to trainable in a frozen model - Part 1 (2019) - Deep Learning Course Forums
学習率の探索
一般的には、「Valley > Slide > Steep > Minimum」の順に良い精度が得られる。
- valley : 最も長い谷の部分
- slide : interval slide ruleに従って学習速度を提案
- steep 傾きが最も急な部分
- minimum : Lossが最も小さい部分より、1/10小さい値
参考:新しい(2021年6月)学習率探索の概要 New LR Finder Output?! - fastai users - Deep Learning Course Forums
lrs = learn.lr_find(suggest_funcs=(minimum, steep, valley, slide))

今回は簡単のため、最も学習率の高いものを採用した。
lr = max(lrs); lr, lrs
(0.019054606556892395,
SuggestedLRs(minimum=0.010000000149011612, steep=0.019054606556892395, valley=0.0012022644514217973, slide=0.004365158267319202))
学習実行
備考
- 累積勾配(Gradient Accumulation):実効バッチサイズを
bs_update相当にする。- 複数ステップ(ミニバッチ)の勾配を累積してまとめて更新する。
- 参考 GradientAccumulation
- EarlyStopping:「map10」メトリックが過去のベストを3エポック上回らなかったら早期終了させる。
learn.fit_one_cycle(30, lr_max=lr,
cbs=[
GradientAccumulation(n_acc=bs_update), # 累積勾配
EarlyStoppingCallback(monitor='map10', min_delta=0.01, patience=3), # 早期終了
])
| epoch | train_loss | valid_loss | accuracy | map10 | time |
|---|---|---|---|---|---|
| 0 | 2.757626 | 1.852016 | 0.713126 | 0.815030 | 00:21 |
| 1 | 1.514403 | 0.787316 | 0.855210 | 0.916997 | 00:20 |
| 2 | 0.869610 | 0.408244 | 0.903248 | 0.943415 | 00:20 |
| 3 | 0.516415 | 0.298472 | 0.905277 | 0.946489 | 00:20 |
| 4 | 0.367728 | 0.269805 | 0.906631 | 0.948079 | 00:20 |
| 5 | 0.322179 | 0.263880 | 0.904601 | 0.945956 | 00:20 |

No improvement since epoch 2: early stopping
GPUメモリ使用量の確認
f'{torch.cuda.max_memory_allocated()*1e-9:.3g}GB'
'2.72GB'
ファインチューニング
パラメータ固定の解除
全パラメータを学習対象にする。
learn.unfreeze()
learn.summary()
Net (Input shape: 64 x 3 x 224 x 224)
============================================================================
Layer (type) Output Shape Param # Trainable
============================================================================
64 x 64 x 112 x 112
Conv2d 9408 True
BatchNorm2d 128 True
ReLU
____________________________________________________________________________
64 x 64 x 56 x 56
MaxPool2d
Conv2d 36864 True
BatchNorm2d 128 True
ReLU
(後略)
Conv2d 36864 True
BatchNorm2d 128 True
Conv2d 36864 True
BatchNorm2d 128 True
ReLU
Conv2d 36864 True
BatchNorm2d 128 True
Conv2d 36864 True
BatchNorm2d 128 True
ReLU
Conv2d 36864 True
BatchNorm2d 128 True
____________________________________________________________________________
64 x 128 x 28 x 28
Conv2d 73728 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
Conv2d 8192 True
BatchNorm2d 256 True
Conv2d 147456 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
Conv2d 147456 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
Conv2d 147456 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
____________________________________________________________________________
64 x 256 x 14 x 14
Conv2d 294912 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 32768 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
____________________________________________________________________________
64 x 512 x 7 x 7
Conv2d 1179648 True
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 True
BatchNorm2d 1024 True
Conv2d 131072 True
BatchNorm2d 1024 True
Conv2d 2359296 True
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 True
BatchNorm2d 1024 True
Conv2d 2359296 True
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 True
BatchNorm2d 1024 True
____________________________________________________________________________
64 x 512 x 1 x 1
AdaptiveAvgPool2d
AdaptiveMaxPool2d
____________________________________________________________________________
64 x 1024
Flatten
BatchNorm1d 2048 True
Dropout
____________________________________________________________________________
64 x 140
Linear 143360 True
ReLU
BatchNorm1d 280 True
Dropout
____________________________________________________________________________
64 x 35
Linear 4900 True
____________________________________________________________________________
Total params: 21,435,260
Total trainable params: 21,435,260
Total non-trainable params: 0
Optimizer used: <function Adam at 0x0000021ADEDE6040>
Loss function: FlattenedLoss of CrossEntropyLoss()
Model unfrozen
Callbacks:
- TrainEvalCallback
- MixedPrecision
- Recorder
- ProgressCallback
- CSVLogger
- ShowGraphCallback
学習率の探索
lrs = learn.lr_find(suggest_funcs=(minimum, steep, valley, slide))
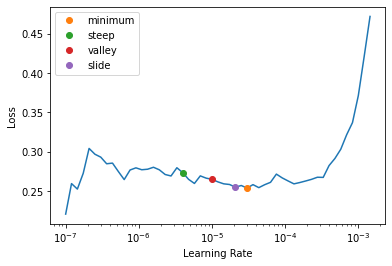
簡単のため、最も学習率の高いものを採用した。
lr = max(lrs); lr, lrs
(2.0892961401841603e-05,
SuggestedLRs(minimum=3.0199516913853586e-06, steep=3.981071586167673e-06, valley=9.999999747378752e-06, slide=2.0892961401841603e-05))
学習実行
lr_max=slice(...) : 入力に近い層は低い学習率とする(Discriminative Learning Rates)
learn.fit_one_cycle(30, lr_max=slice(lr*1e-2,lr),
cbs=[
GradientAccumulation(n_acc=bs_update), # 累積勾配
EarlyStoppingCallback(monitor='map10', min_delta=0.01, patience=3), # 早期終了
])
| epoch | train_loss | valid_loss | accuracy | map10 | time |
|---|---|---|---|---|---|
| 0 | 0.291610 | 0.262367 | 0.901218 | 0.944829 | 00:36 |
| 1 | 0.274321 | 0.266308 | 0.901894 | 0.944724 | 00:23 |
| 2 | 0.279457 | 0.265085 | 0.901218 | 0.944401 | 00:29 |
| 3 | 0.281349 | 0.262056 | 0.901894 | 0.944968 | 00:24 |

No improvement since epoch 0: early stopping
📊評価
学習結果を簡単にイメージで見れる
learn.show_results(max_n=7**2)

混同行列
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(24, 24))

誤りの多かったクラスの確認
interp.most_confused()
[('american', 'staffordshire', 10),
('Russian', 'British', 8),
('British', 'Russian', 6),
('Egyptian', 'Bengal', 6),
(後略)
('Ragdoll', 'Birman', 6),
('staffordshire', 'american', 6),
('Bengal', 'Egyptian', 4),
('Birman', 'Ragdoll', 4),
('Siamese', 'Birman', 4),
('basset', 'beagle', 4),
('Maine', 'Ragdoll', 3),
('chihuahua', 'miniature', 3),
('english', 'newfoundland', 3),
('yorkshire', 'havanese', 3),
('Maine', 'Persian', 2),
('beagle', 'basset', 2),
('great', 'samoyed', 2),
('newfoundland', 'leonberger', 2),
('scottish', 'havanese', 2),
('shiba', 'chihuahua', 2),
('staffordshire', 'boxer', 2),
('wheaten', 'great', 2),
('wheaten', 'scottish', 2),
('Abyssinian', 'Bengal', 1),
('Abyssinian', 'British', 1),
('Abyssinian', 'shiba', 1),
('Bengal', 'Abyssinian', 1),
('Bengal', 'Maine', 1),
('Birman', 'Siamese', 1),
('Bombay', 'British', 1),
('Bombay', 'Russian', 1),
('British', 'Abyssinian', 1),
('British', 'Ragdoll', 1),
('Egyptian', 'Russian', 1),
('Persian', 'Bombay', 1),
('Persian', 'Maine', 1),
('Ragdoll', 'British', 1),
('Ragdoll', 'Maine', 1),
('Ragdoll', 'Persian', 1),
('Ragdoll', 'Siamese', 1),
('Russian', 'Abyssinian', 1),
('Russian', 'Bombay', 1),
('Siamese', 'British', 1),
('Sphynx', 'Abyssinian', 1),
('american', 'Sphynx', 1),
('american', 'boxer', 1),
('american', 'german', 1),
('american', 'miniature', 1),
('american', 'saint', 1),
('basset', 'german', 1),
('beagle', 'american', 1),
('beagle', 'chihuahua', 1),
('beagle', 'german', 1),
('boxer', 'Sphynx', 1),
('boxer', 'american', 1),
('boxer', 'beagle', 1),
('boxer', 'saint', 1),
('boxer', 'staffordshire', 1),
('chihuahua', 'Russian', 1),
('chihuahua', 'scottish', 1),
('english', 'beagle', 1),
('english', 'chihuahua', 1),
('english', 'scottish', 1),
('german', 'newfoundland', 1),
('havanese', 'yorkshire', 1),
('japanese', 'havanese', 1),
('japanese', 'pomeranian', 1),
('keeshond', 'leonberger', 1),
('miniature', 'Sphynx', 1),
('miniature', 'staffordshire', 1),
('newfoundland', 'staffordshire', 1),
('pomeranian', 'Ragdoll', 1),
('pomeranian', 'newfoundland', 1),
('pomeranian', 'samoyed', 1),
('pomeranian', 'yorkshire', 1),
('saint', 'basset', 1),
('samoyed', 'pomeranian', 1),
('shiba', 'Siamese', 1),
('shiba', 'miniature', 1),
('wheaten', 'leonberger', 1)]
interp.plot_top_losses(9, figsize=(24,24))

💾モデル保存・復元
保存
pytorchモデルだけ保存する。
(fastaiのLearnerを保存して運用環境で復元する方法もある(Learner#export, Learner#save/load)。しかし、保存・復元が失敗したり、運用環境にLearnerやDataLoadersのコードが必要で煩雑だったため不採用とした。)
import datetime
modelname = 'baseline1'
model_no = len(list(Path('./models').glob('*.pth')))
save_id = f'{str(model_no).zfill(3)}_{datetime.date.today()}_{modelname}'
model_output_path = f'./models/{save_id}_model.pth'
model_output_path
'./models/000_2022-06-24_baseline1_model.pth'
モデル本体(torch.nn.Module)のパラメータだけ保存
torch.save(learn.model.state_dict(), model_output_path) # Modelだけを保存
モデル出力のidxとラベル名の対応(vocab)をファイルに保存
p = Path(model_output_path)
model_vocab_output_path = str(p.parent/p.stem)+f'_vocab.txt'
model_vocab_output_path
'models\\000_2022-06-24_baseline1_model_vocab.txt'
with open(model_vocab_output_path, 'w') as f: f.write(','.join(learn.dls.vocab))
復元
ただのpytorchモデルとして読込む。
事前学習済みモデルを外部サイトからダウンロードする必要はないので、pretrained=Falseとした。
model = Net(pretrained=False)
model = model.to("cuda")
model.load_state_dict(torch.load(model_output_path), strict=True)
model.eval() # モデルを実行可能にするために必要
Net(
(body): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(後略)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(head): Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten(full=False)
(2): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25, inplace=False)
(4): Linear(in_features=1024, out_features=140, bias=False)
(5): ReLU(inplace=True)
(6): BatchNorm1d(140, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5, inplace=False)
(8): Linear(in_features=140, out_features=35, bias=False)
)
)
モデル出力のidxとラベル名の対応(vocab)をファイルから読み込み
with open(model_vocab_output_path, 'r') as f: vocab = f.read().split(',')
vocab
['Abyssinian',
'Bengal',
'Birman',
(後略)
'Bombay',
'British',
'Egyptian',
'Maine',
'Persian',
'Ragdoll',
'Russian',
'Siamese',
'Sphynx',
'american',
'basset',
'beagle',
'boxer',
'chihuahua',
'english',
'german',
'great',
'havanese',
'japanese',
'keeshond',
'leonberger',
'miniature',
'newfoundland',
'pomeranian',
'pug',
'saint',
'samoyed',
'scottish',
'shiba',
'staffordshire',
'wheaten',
'yorkshire']
📈運用
入力画像と正解ラベルの取得
前処理を定義
fastaiのLearnerで行われていた変換(ミニバッチの次元合わせや、0~1に正規化など)を行うため。
def preprocess(img:PILImage)->PILImage:
"""
前処理
1. 画像をモデル入力サイズに変換
2. PILImageをFloatTensorに変換して、0~1に正規化
3. Tensorの形状をNCHW形式に変換
"""
_img = CropPad(imsize_croped, pad_mode='border')(img)
_X = torch.tensor(np.array(_img)).float().cuda()/255
X = torch.permute(_X,[2,0,1])[None,:] # [None,:] ミニバッチの次元を追加
return X
画像を読込んで、Tensorに変換。正解ラベルも読み込む
imgpath = files[0]
X = preprocess(PILImage.create(imgpath))
y = label_from_path(imgpath)
y, X.shape, X
('Abyssinian',
torch.Size([1, 3, 224, 224]),
tensor([[[[0.3843, 0.3843, 0.3882, ..., 0.7529, 0.7686, 0.7804],
[0.3804, 0.3843, 0.3882, ..., 0.7765, 0.7843, 0.7922],
[0.3725, 0.3804, 0.3882, ..., 0.7882, 0.8000, 0.8000],
...,
[0.1686, 0.1686, 0.1725, ..., 0.1725, 0.1804, 0.1843],
[0.1686, 0.1725, 0.1725, ..., 0.1686, 0.1725, 0.1765],
[0.1686, 0.1725, 0.1725, ..., 0.1647, 0.1686, 0.1725]],
[[0.4196, 0.4196, 0.4235, ..., 0.6941, 0.7098, 0.7216],
[0.4157, 0.4196, 0.4235, ..., 0.7098, 0.7255, 0.7333],
[0.4078, 0.4157, 0.4235, ..., 0.7216, 0.7412, 0.7373],
...,
[0.1843, 0.1843, 0.1882, ..., 0.1882, 0.1961, 0.2000],
[0.1843, 0.1882, 0.1882, ..., 0.1843, 0.1882, 0.1922],
[0.1843, 0.1882, 0.1882, ..., 0.1804, 0.1843, 0.1882]],
[[0.3451, 0.3451, 0.3490, ..., 0.6667, 0.6902, 0.7098],
[0.3412, 0.3451, 0.3490, ..., 0.6824, 0.7059, 0.7216],
[0.3333, 0.3412, 0.3490, ..., 0.6941, 0.7216, 0.7373],
...,
[0.1294, 0.1294, 0.1333, ..., 0.1333, 0.1412, 0.1451],
[0.1294, 0.1333, 0.1333, ..., 0.1294, 0.1333, 0.1373],
[0.1294, 0.1333, 0.1333, ..., 0.1255, 0.1294, 0.1333]]]],
device='cuda:0'))
1画像推論
モデル出力は-inf~infの値を返すが、多クラス分類なのでsoftmax関数で合計が1になるような確率値に変換する。
with torch.no_grad():
out = nn.Softmax(dim=1)(model(X))
out.shape, out.sum(), out
(torch.Size([1, 35]),
TensorBase(1.0000, device='cuda:0'),
TensorBase([[9.9877e-01, 2.6242e-04, 2.4370e-06, 4.6254e-06, 1.6050e-04, 1.4321e-05,
2.2727e-05, 2.1453e-06, 2.1390e-05, 2.8081e-04, 2.1475e-04, 1.5450e-04,
1.0967e-06, 1.9131e-06, 5.1935e-06, 7.6392e-06, 2.0327e-06, 5.0545e-08,
5.2137e-06, 9.4197e-07, 3.2433e-08, 2.0186e-08, 5.0262e-08, 1.8544e-06,
3.8601e-06, 7.7373e-08, 4.5021e-07, 2.2699e-06, 3.6550e-06, 3.3962e-07,
1.0858e-07, 5.5254e-05, 1.4583e-07, 1.5566e-06, 5.3693e-07]],
device='cuda:0'))
推論した確率を、ラベルに置き換える。
def pred2labels(preds:Tensor, vocab:list, k=10)->{str:[]}:
"""
推論結果のTensorから上位`k`件までを、ラベルで表示
"""
prob_list, idx_list = [x[:,:k].detach().numpy().flatten().tolist() for x in preds.cpu().sort(descending=True)]
return {vocab[i]:p for i,p in zip(idx_list, prob_list)}
y, pred2labels(out, vocab)
('Abyssinian',
{'Abyssinian': 0.998765230178833,
'Russian': 0.0002808065328281373,
'Bengal': 0.00026241858722642064,
'Siamese': 0.00021474898676387966,
'British': 0.000160503841470927,
'Sphynx': 0.00015449656348209828,
'shiba': 5.525376400328241e-05,
'Maine': 2.272747406095732e-05,
'Ragdoll': 2.1389962057583034e-05,
'Egyptian': 1.4321315575216431e-05})
💯まとめ
Abyssinianの画像を、99%以上の自信で正しく分類できた。