1. はじめに
私は今、NLG(自然言語生成)について勉強しているのですが、生成した文章を全て人手で評価するのは大変だと考えていたところ、G-Evalというものを見つけたので、Colabで頑張って実装してみました。
この記事では、Ollamaとdeepevalを使用して、ローカル環境で大規模言語モデル(LLM)の評価を、Colabで実装する方法を解説します。特に、生成されたテキストの正確性を評価するためのG-Evalメトリックの設定と評価の実行方法について説明します。
自然言語処理の勉強を始めて歴が浅いので、万が一間違っているところや改善点があれば、教えていただけると助かります![]()
※この記事の作成にもLLMを一部活用しています。
2. 必要な準備
評価を行うためにはいくつかの準備が必要です。以下の手順でライブラリのインストールや環境の設定を行います。
2.1 Google Driveのマウント
- Google Colab環境で作業する場合、Google Driveをマウントしてファイルの読み書きができるようにします。
from google.colab import drive
drive.mount('/content/drive/')
2.2 必要なライブラリのインストール
-
deepeval,ngrok,pyngrokをインストールします。これらはLLMの評価やサーバーの設定に必要です。 - Colab上でシェルコマンドを実行するためには、コマンドの前に
!を付けて実行します。
!pip install deepeval # deepeval: LLMの評価のためのライブラリ
!pip install ngrok # ngrok: ローカルサーバーを外部に公開するためのツール
!pip install pyngrok # pyngrok: ngrokをPythonから操作するためのライブラリ
3. OllamaとCUDAのセットアップ
OllamaはLLMをローカルで実行するためのツールです。以下の手順でOllamaとCUDAドライバーをインストールし、設定を行います。
3.1 Ollamaのインストール
- Ollamaのインストールスクリプトを実行してインストールします。
!curl https://ollama.ai/install.sh | sh
3.2 CUDAドライバーのインストール
- 必要に応じて、CUDAドライバーをインストールします。
!echo 'debconf debconf/frontend select Noninteractive' | sudo debconf-set-selections
!sudo apt-get update && sudo apt-get install -y cuda-drivers
3.3 環境変数の設定
-
LD_LIBRARY_PATHを設定して、CUDAライブラリへのパスを指定します。
import os
os.environ.update({'LD_LIBRARY_PATH': '/usr/lib64-nvidia'})
4. Ollamaサーバーの起動
バックグラウンドでOllamaサーバーを起動します。これにより、ローカル環境でLLMを実行できます。
!nohup ollama serve &
また、セッション終了時にサーバーを停止するためのコードも設定します。
import atexit
import os
def stop_ollama_server():
os.system("pkill ollama")
atexit.register(stop_ollama_server)
5. モデルのダウンロードとライブラリの設定
OllamaのPythonライブラリをインストールし、llama3.2モデルをダウンロードします。
!ollama pull llama3.2
!pip install ollama
6. deepevalでローカルモデルを設定
deepevalライブラリを使用して、ローカルのllama3.2モデルを設定します。
import ollama
!deepeval set-local-model --model-name=llama3.2 \
--base-url="http://localhost:11434/v1/" \
--api-key="ollama"
7. タイムアウト時間を設定
tsvファイルの評価を行うと、まれに固まってしまう事があります。1時間で終わるはずの評価が一晩終わらない、なんてことを防ぐために、タイムアウト時間を設定して、固まってしまったらその行の評価をスキップします。
※経験上、スキップして次の行の評価に移れば、問題なく動きます。
import signal
class TimeoutException(Exception):
pass
def timeout_handler(signum, frame):
raise TimeoutException("60秒タイムアウトしました")
# タイムアウト時間を設定 (秒)
timeout_duration = 60
8. 評価メトリックの定義
ここでは、GEvalメトリックを使用して生成されたテキストの正確性を評価します。
#@title 評価メトリックを定義する
from deepeval.metrics import GEval # deepevalからGEvalメトリックをインポートします.GEvalは,生成されたテキストの正確性を評価するためのメトリックです.
from deepeval.test_case import LLMTestCaseParams # deepevalからLLMTestCaseParamsをインポートします.LLMTestCaseParamsは,テストケースのパラメータを定義するためのクラスです.
'''
correctness_metric = GEval(
name="ここでメトリックの名前を設定.評価にはおそらく直接的には影響しない.",
criteria="ここで評価基準を定義する",
evaluation_params=[評価に使用するパラメータを設定.このサンプルでは,入力,実際の出力,期待される出力を使用する.],
model = "llama3.2" # 使用するモデルを"llama3
'''
correctness_metric = GEval(
name="Correctness", # メトリックの名前を"Correctness"に設定します.
criteria="Determine whether the actual output is factually correct based on the expected output.", #@param {type:"string"} # メトリックの基準を設定します.この基準は,生成されたテキストが事実的に正しいかどうかを判断するために使用されます.
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT], # 評価に使用するパラメータを設定します.ここでは,入力,実際の出力,期待される出力が使用されます.
model = "llama3.2" # 使用するモデルを"llama3
)
Colabでは#@paramをパラメータの後ろに書くことで、写真の様にインタラクティブにパラメータを設定するウィジェットを作成できます。
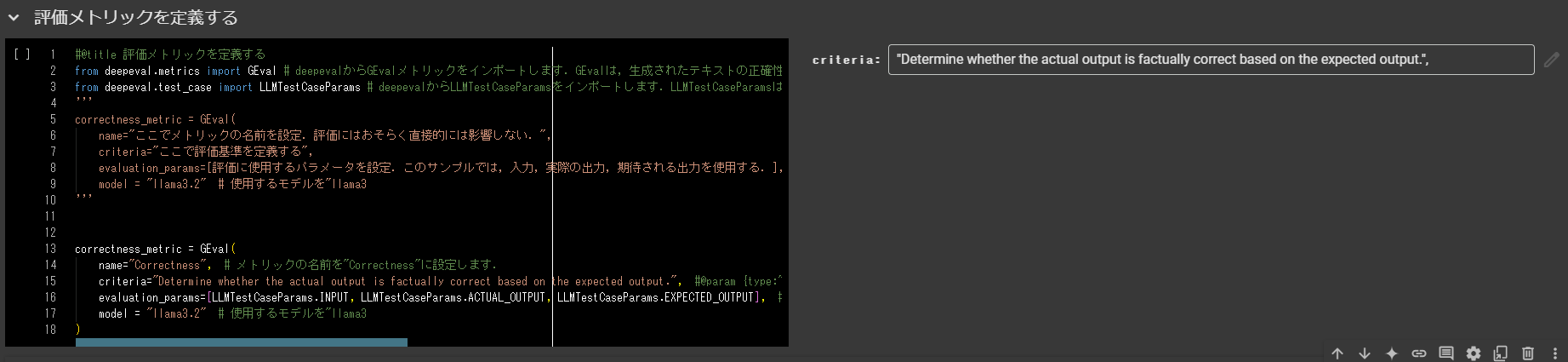
本記事のコードでは、評価基準など皆様が各自変更するであろう部分に#@paramをつけてありますので、是非ご参考ください。
9. 評価の実行と結果の出力
実際の評価を行い、その結果をTSVファイルとして保存します。
import pandas as pd
from deepeval.test_case import LLMTestCase
from tqdm import tqdm
# 入力ファイルと出力ファイルのパスを設定
input_file = 'your_input_file(tsv)_path'
output_file = 'your_output_file(tsv)_path'
# TSVファイルを読み込み
data = pd.read_csv(input_file, sep='\t', nrows=None)
# 評価結果を格納するリストを初期化
scores = []
reasons = []
# 各行に対して評価を実行
for _, row in tqdm(data.iterrows(), total=data.shape[0], desc="Evaluating"):
try:
test_case = LLMTestCase(
input=row['input_column'], #@param
actual_output=row['actual_output_column'], #@param
expected_output=row['expected_output_column'] #@param
)
correctness_metric.measure(test_case)
scores.append(correctness_metric.score)
reasons.append(correctness_metric.reason)
except Exception as e:
print(f"Error evaluating row {row.name}: {e}")
scores.append(None)
reasons.append(None)
# 結果をデータフレームに追加して出力
data['Score'] = scores
data['Reason'] = reasons
data.to_csv(output_file, sep='\t', index=False)
10. ランタイムの切断
作業が終了したら、ランタイムを切断してリソースを解放します。
from google.colab import runtime
runtime.unassign()
11. まとめ
このノートブックでは、Ollamaとdeepevalを使用して、ローカル環境で大規模言語モデル(LLM)の評価を行う方法を紹介しました。評価メトリックの設定、評価の実行方法、および結果の保存方法について説明しました。
※LLMの勉強を始めて歴が浅いので、もし間違いや改善点などあれば、是非教えていただけると幸いです!