概要
文字コードを自動判別する様な仕組みを持ったソフトウェアがたまに存在する。その努力を否定するものでは無いが、そういった状況のため、 文字コードは自動判別できる という誤解をしている人もしばしばいる。たまにそういう提案してくる人もいて、割と困ることもある。
しかし。
- テキストの内容だけで文字コードを判別することは、 原理的には不可能
- 自動判別機能は 作業の一助 にはなるが、結局化けているかどうかは人間が見たときの判断であり、結果論でしかない。
- テキスト以外の様々な状況や運用によってある程度の潰しこみをするしか無い。
である。
昔撮った、誤判定による文字化けの面白いサンプルがあったので、参考に記載したい。

(2016年頃にGALAXY NOTE II にカスタムROM入れた当時に、面白いサンプルが得られて、ゲラってた)
環境
- OS
- GALAXY NOTE II
- Android CM12 (カスタムROM。 S-JISで無いことは確か。)
- サンプル ファイル
- CD:洲崎西 - Smile☆Revolution
- CDをリッピングしてスマホ端末へ
- MP3 + ID3 Tag
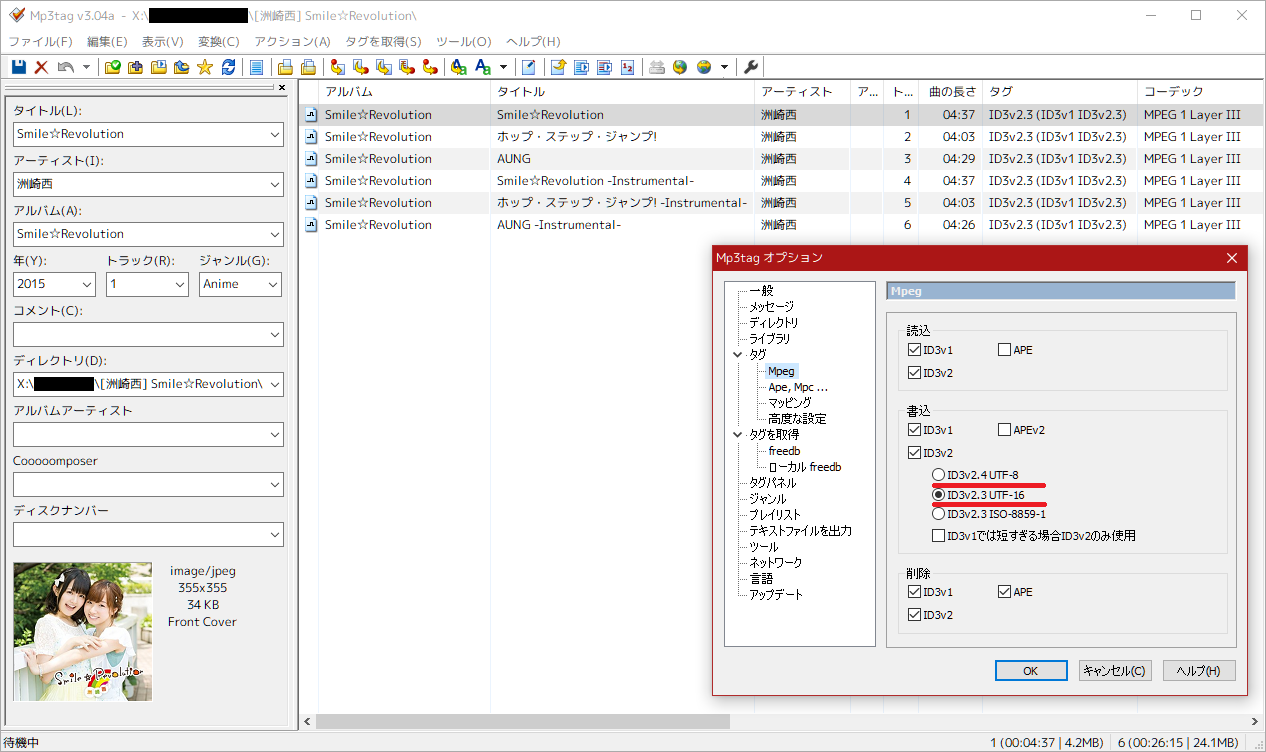
- ID3での 文字コードの設定はなし ※諸悪の根源
- 日本語Windows (S-JIS環境) で作成
サンプルのCDとトラック
使用文字がバラけている、 サンプルには 良いアルバム。
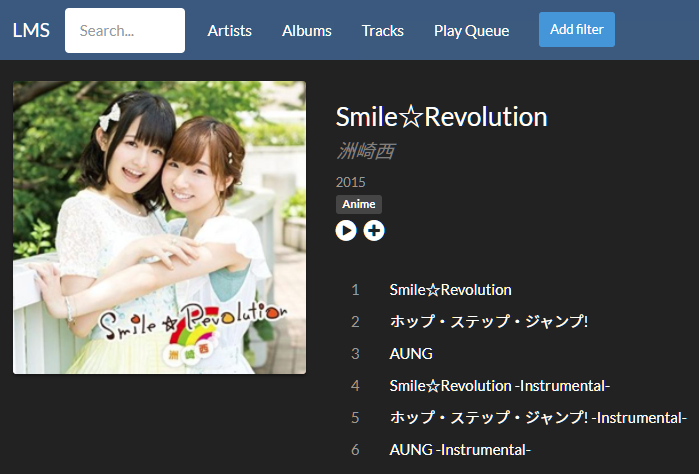
(自宅でのRaspberry Piで運用している LMS でのSS)
自動判別による誤判定例
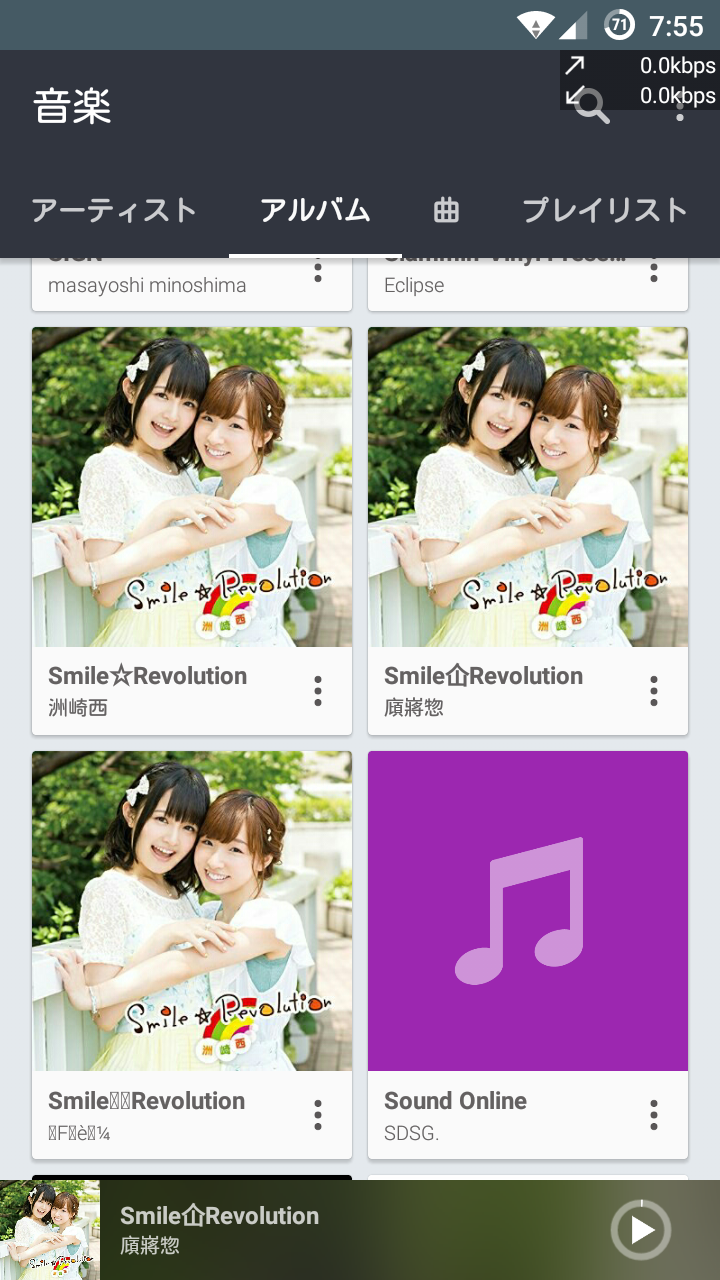
① アルバム全体 👎
トラックごとに異なる文字コード判定により異なる文字化けを起こし、異なるアルバム扱いになっている。Android (CM12当時) のメディア ストレージは、トラック名で文字コードを判断し、ファイル全体の文字コードとして扱う模様。そのため、アーティスト名がトラック名の傾向によって異なってしまっている。
② Track.1 Smile☆Revolution 👎
☆が面白い形に化けている。繁体字のBig5あたりにでも同じコードポイントがあったのだろうか?その判定にひっぱられ、アーティスト名も誰やねん状態。(しかも居そうな印象すら感じるから面白い)
③ Track.2 ホップ・ステップ・ジャンプ! 👍
先に探索される文字コードに見つからない文字があってか、日本語文字コード(S-JIS)になんとかお鉢が回ってきた様子。その判定にひっぱられ、アーティスト名も正しく 洲崎西 、アルバム名もちゃんと☆が化けていない。
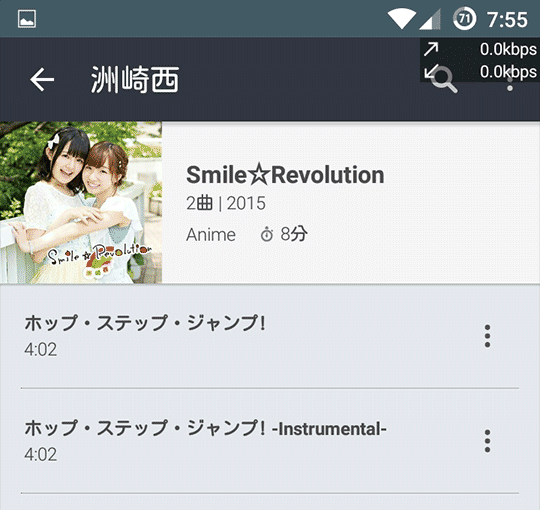
※ EUC-JPじゃなくてよかったね!
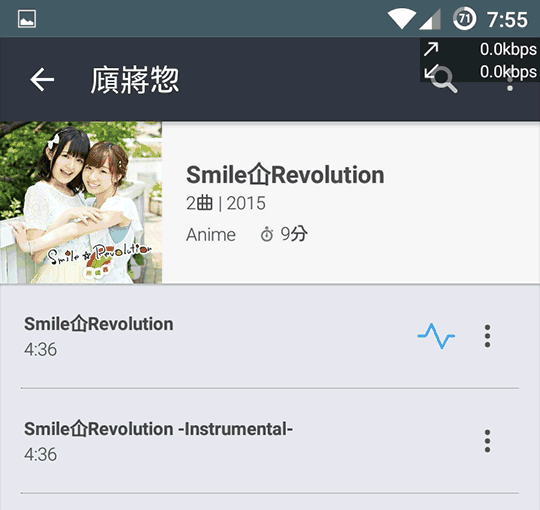
④ Track.3 AUNG 👎
ASCIIしかなかったために、おそらくLaten-1扱いになったのだと思われる。
(流石にASCIIではない)
アーティスト名やアルバム名に欧米文字や豆腐が見られる。
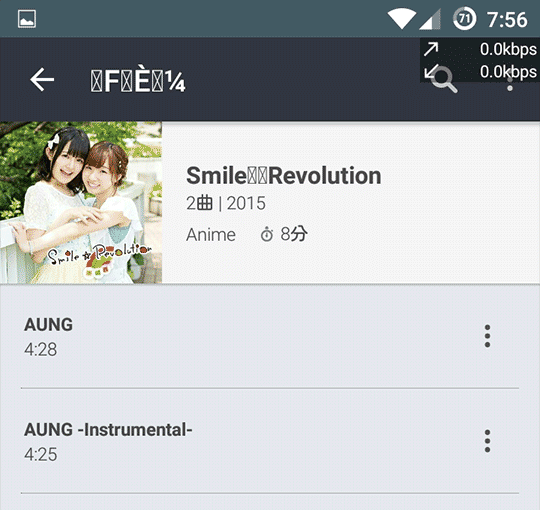
※ ¼ も欧米文字。
まとめ
-
テキストから文字コードの自動判別することは原則出来ない
-
マルチ プラットフォームな昨今において、旧来の
システム文字コードを基点にして運用されていた時代のデータのままでは、もう運用できない。- 例1) スマホやカーナビに昔の音楽データを転送したら文字化けした
- 流石にSJISの端末なんかあるか!😡 (S-JIS優先の端末はある様だけど、Xperiaとかだって基本海外端末だぜ?)
- データにちゃんと文字コードを定義しろ (古いデータ仕様が悪い)
(例えばID3 TagならID3v2.3 or ID3v2.4の何れかでUNICODEを設定するのが望ましい。)
- 例2) ZIP圧縮するWEBアプリを作ったら文字化けした
- WEBアプリこそマルチ プラットフォームを本懐とするシステム
- 日本国内ですら、WEBブラウジング可能なクライアントOSの文字コードがバラけている
- ZIPに追加された仕様であるUNICODE ZIPを使え (その準備はほぼ整っている)
- UNICODE ZIPに対応しないOS、ソフトウェアを排除しろ (Win7, Lhaplus, Java6など)
- 例1) スマホやカーナビに昔の音楽データを転送したら文字化けした
-
文字コード (キャラ セット) 運用について、パラダイム シフトが起きていることを自覚する必要がある。
- 国ごとに文字コード (キャラ セット) ⇒ 文字コードはUNICODEで統一
- 実行ファイル ⇒ 内部処理をUNICODEで統一して行える様になった (WCHAR, Java VM, .NET CLR)
- ID3 Tag ⇒ 文字コード情報を持てる様になり、UNICODEで統一出来る様になった (ID3v2.3, ID3v2.4)
- ZIP ⇒ 文字コード情報を持てる様になり、UNICODEで統一出来る様になった (UNICODE ZIP)