この記事はなに?
この記事はソフトウェアテスト Advent Calendar 2025の13日目の記事です。
私は、Web系の企業でWebシステムの保守運用をしています。
その際、特にジュニアエンジニアから、パフォーマンスチューニングと負荷試験をどう進めればよいのかについて聞かれることが多いので、どういった基礎知識があればよいのかを一度まとめてみることにしました。
Webシステムのパフォーマンスは奥が深い(し、まとまった本も少ない)ので、網羅できている気は全くしませんが、自分と同じところでハマる方を減らせればと思います。
I. パフォーマンスを理解するために
そもそも、なんとなくサクサク動くことを「パフォーマンスが良い」と言ってしまいがちですが、パフォーマンスとはいったいなんなのでしょうか?
パフォーマンスとは?
本記事中では、「Webシステムのパフォーマンス」とは、システム非機能要件のひとつであり、対象のシステムが、
- システムのユーザが期待する速度で、
- 安定的に(時間帯や操作方法、ユーザの利用環境、他ユーザからのアクセスの有無によらず)、
- 期待する出力を返し続ける
ことができるかどうかである、と定義します。
Webシステムも中身は機械なので、その処理速度には物理的な限界があります。
その制約の中で、パフォーマンスに関する要件を満たすことで、そのサービスは市場における優位に立つことができます。(例えば、どれだけ役に立つサービスであっても、ページ遷移に毎回10秒かかるサービスを使いたいとは思わないですよね。逆に、早く表示されるページはユーザの離脱率減少や検索エンジンにおけるランク上昇(SEO対策)などのメリットがあります)
また、同じパフォーマンスを少ないサーバ台数で実現できれば、コスト削減もできます。
パフォーマンスチューニングとは?
Webシステムがパフォーマンスに関する要件を満たせていない状態をよく、「遅い」、「重い」や「負荷が高い」と表現しますが、これらは、以下の2つか、その両方に分類されます。
- レイテンシが大きい
- スループットが小さい
ここで 「レイテンシ」 、 「スループット」 という言葉が出てきましたが、これらはシステムパフォーマンスを理解するために非常に重要な言葉です。

「レイテンシ」は、一般的に「システムがリクエストを受け付けてからそれが処理されるまでの時間(sec, ms, μs)」を指します(Webシステムの場合は、いわゆるレスポンスタイムと同一視されることも多いと思います)。
レイテンシは処理時間なので、小さい方がパフォーマンスとしては良くなります。
これに対し、「スループット」は、「単位時間にシステムが処理可能なリクエスト数(RPS)」を指します。
Webシステム(とその構成要素)は、同時に処理できるリクエスト数に限界があり、これを超える同時リクエストが来た場合、何らかの形でそのリクエストをキューイング(つまり、後回しにして処理しようとする)します。その結果、処理開始までの待ち時間がかかり、レスポンスタイムとしては遅くなります。
スループットは同時に処理できるリクエスト数なので、大きい方がパフォーマンスとしては良くなります。
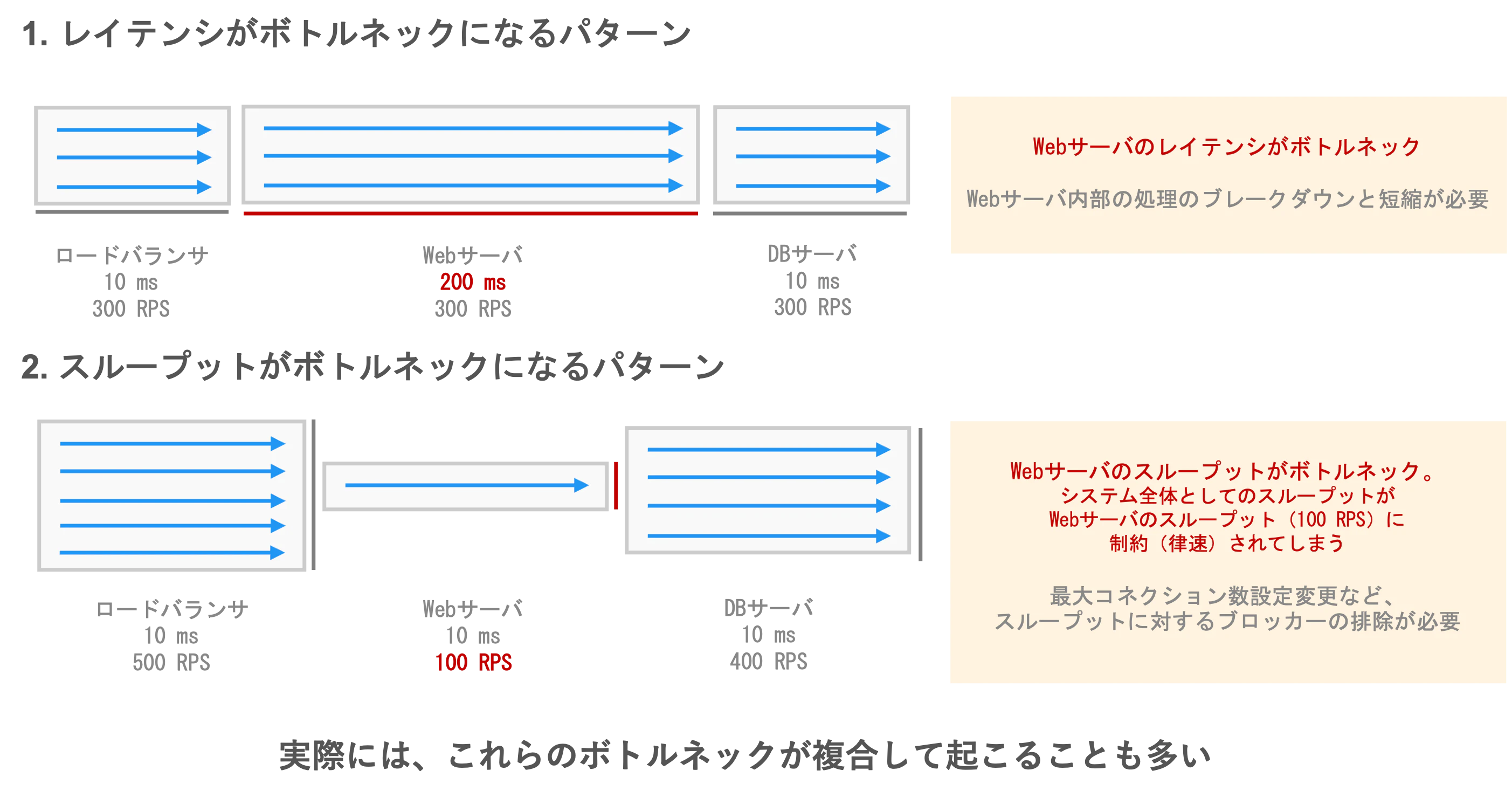
現在のWebシステムは、ロードバランサ、Webサーバ、アプリケーションサーバ、データベースなど、複数の構成要素に分かれているため、ある特定の構成要素のみにレイテンシが大きい、スループットが小さいなどのパフォーマンス上の問題があることで、全体としてのパフォーマンスを下げてしまっている場合があります。これを「パフォーマンスボトルネック(あるいは単に「ボトルネック」)」と呼びます。
また、それぞれの構成要素のレイテンシとスループットを計測し、パフォーマンスボトルネックを解消することでパフォーマンスの向上を図る作業を「パフォーマンスチューニング」と呼んでいます。
ここで重要なこととして、ボトルネックではない箇所(、あるいはボトルネックではあるものの、全体から見た影響としては小さい箇所)を改善しても、システム全体としてのパフォーマンスは大きく改善しません。
パフォーマンスチューニングのプロセスには費用対効果(金銭的なコストに加え、変更工数やその後の拡張性、セキュリティへの影響など)の問題があり、何でもかんでも一つの方法でチューニングしようとするのはおすすめできません。
対象となるシステムにおいて、どの程度のパフォーマンスが必要なのか、そのために何がボトルネックになっているのかをしっかり特定し、その箇所に効くチューニングを行うことが重要です。
パフォーマンスを理解するために
私は、Webシステムにおけるパフォーマンスを理解するために必要なスキルは以下の3つだと考えています。
- 計算機科学(特にネットワーク、データベース、プログラミング、OS、コンピュータアーキテクチャ)への理解
- 自分が運用しているシステム(アプリケーションロジックやインフラなどのアーキテクチャはもちろん、システムが保有するデータの特性やビジネス的な要件・ユースケース)への理解
- これらの知識を用いてボトルネックについての仮説を生み出し、検証し、検証した結果(ログやメトリクス)をうまく読み解いてまた仮説を導くための論理的思考力(と、目標を達成するまで思考し続けられる根気)
これらはいずれも一朝一夕で身につくものではなく、大学等で専門教育を受けていたとしてもすぐに実践レベルで使えるものではないので、実務で少しづつ学んでいかないと難しいのかなと思います(少なくとも私はそうでした)。
II. Webシステムについての基礎知識
ここからは、特にWebシステムの文脈におけるパフォーマンスを理解するための知識について解説します。
と言っても、現在のWebシステムは非常に複雑で、すべてを書ききることはできないので、概要を理解するのに必要な知識にとどめます。
一般的なWebシステムの処理フロー
最初に、一般的なWebシステムの構成要素がどうなっていて、どのような処理をしているのかについてはイメージを持っておくとよいかと思います。
(非常に雑な図ですが、)例えばこんな感じ。
そこから、注目すべき箇所について深堀るようにしていくとよいのではないかと思います。
1.~2. DNSリクエスト
DNSリクエストは、DNSサーバへの問い合わせによって、URL内のドメイン名(FQDN)から宛先サーバのIPアドレスを得る工程です。
通常、リクエストの結果はローカルPC内にキャッシュされ、何度も問い合わせが発生することはありません。
この工程において、ブラウザからのHTTPリクエストは送信されないので、Webシステムのパフォーマンス観点でDNSが焦点になることはまれかと思います。
3.~5. HTTPリクエスト送信(往路)
DNSリクエストの結果をもとに、ブラウザ側でHTTPリクエストが組み立てられ、TCP/IPプロトコルにて送信されます。
通常のインターネットを介したアクセスでは、PCやスマホからホームルータを介して宛先のサーバへリクエストを送信します。
ISP(いわゆるプロバイダ)は、ホームルータとインターネットの経路上にあるネットワーク機器を管理しており、適切なルートでリクエストが送信されるようにしてくれます。
この工程も、実際にはコントロールできるものが少ないため(本当は電波状態やインターネットにおける帯域保証など、考えることはあるはずなのですが)、Webシステムのパフォーマンス観点で話題に上がることは少ないと思います。
6. ロードバランサからデータベースサーバまで
ロードバランサからデータベースサーバまでをもう少し細かく書くと、以下のようになります。
- ロードバランサがTLSの終端処理(リクエストが初回の場合はTLSセッションの確立も)と負荷分散を行う
- WebサーバがTCPコネクションの管理と静的コンテンツの処理を行う。動的な値を返すべきリクエストについては、アプリケーションサーバに転送する
- アプリケーションサーバがビジネスロジックの処理を行う。データベースへのアクセスや他のAPI呼び出しが必要な場合はそれらも含めて行う
- データベースサーバにて、クエリを実行し、必要なデータをアプリケーションサーバに返す
Webバックエンド(サーバサイド)のパフォーマンスチューニングでは、このあたりが主眼になります。
7.~9. HTTPリクエスト送信(復路)
復路なので省略します。
10.~11. 追加のコンテンツ取得とブラウザによる描画(レンダリング)
現代のWebページは、HTMLを一度送受信して終わりというものではなく、その後様々なコンテンツ(CSSやJavaScript、画像など)を送受信し、それらを最終的なページのコンテンツ描画に利用しています。
一般的に、Webブラウザは以下の順序で処理を行います。
- Loading:HTMLやCSSをダウンロードし、それらの構造を記載したDOMツリー、CSSOMツリーを構築します。まず、最初にリクエストして得られたHTMLから<link>、<img>、<src>タグなどを取り出し、リンクに記載されたURLからコンテンツをダウンロードします。CSSやJavaScriptをダウンロードする際にはDOMツリーの構築がブロックされる可能性があるため、コンテンツのダウンロード順序は非常に重要になってきます
- Scripting:JavaScriptを読み込み、実行します
- Rendering:DOMツリーとCSSOMツリーをマージして、「レイアウトツリー(何を描画すべきか)」を作成します。具体的には、スタイルの計算(DOMツリー内のどの要素にどのCSSが適用されるかの検索)と、要素のサイズや位置などのレイアウト情報を計算し、木構造として保持します
- Painting:レイアウトツリーをもとに、実際に画面上のピクセルとして描画します。CPUやGPUなどにより描画項目が計算され、画面に描画されます
これらはクリティカルレンダリングパスと呼ばれ、ここをいかに早めるかがWebフロントエンドにおけるパフォーマンスチューニングの主眼になります。
この他にも、最近のWebページでは、一度コンテンツを描画し終えたあとにも、動画やアニメーションの描画、ユーザからのボタンクリックなどの操作の受け付けなど、パフォーマンス観点で考えるべき箇所が多々あります。
個々の要件に応じた対応が必要になります。
おすすめ文献
- MDN Document Web開発をするなら一度読んでおいてほしいドキュメントです。日本語でここまで網羅的にWebについて書かれているドキュメントは他にないと思います
- ネットワークはなぜつながるのか 第2版 知っておきたいTCP/IP、LAN、光ファイバの基礎知識 「ブラウザにURLを入力してからWebページが表示されるまでの道筋を探検」と帯に銘打っているように、リクエストのパケットがどのようにサーバに送信されていくのか、非常に細かく丁寧に記載されている、ネットワーク関連の名著です
- DNSがよくわかる教科書 DNSの入門書です。DNSはとっつきづらいと(今でも)思いますが、処理フローが多数の具体例とともに書かれており、非常にわかりやすかったです
III. 負荷試験をどう行うか?
では、どのようにシステムのパフォーマンスを担保するのでしょうか?
ここからは、具体的に負荷試験をどう設計、実施、解釈していくかについて解説します。
負荷試験の目的
負荷試験は、システムが性能要件(非機能要求グレードで言う可用性、性能・拡張性)を満たしているかを確認することを目的としたテスト(の一群)です。
一般的には、以下を目的として行われることが多く、Performance Testing Guidance for Web Applicationsでは、それぞれ名前を付けているようです。
| 種類 | 目的 |
|---|---|
| パフォーマンステスト | 現状のシステムのパフォーマンスを明らかにする |
| 負荷テスト(ロードテスト) | システムが、想定されるユースケースに対して、パフォーマンスについての要件を満たし続けられるかを確認する。アクセスピーク帯のテストだけでなく、例えば夜間バッチの実行と同時に動かしても問題ないかのテストや、長時間動かしても問題ないかのテスト(耐久テスト)もここに含まれる |
| ストレステスト | システムが、高負荷下においてもシステムとしての応答ができるか、高負荷下特有のアプリケーションバグやセキュリティ上の問題が生じないかを確認する |
| キャパシティテスト | システムが、ユーザ数やトランザクションの増加など、将来を見据えた形での拡張可能か、また、拡張のためにどのようなチューニングが必要かを明らかにする。システムのパフォーマンスボトルネックを特定し、今後のチューニング作業やスケールアウト計画のために必要な情報を収集する |
実際には、これらのテストを別々に行うことは少なく、いくつか、あるいはすべての種類のテストを同じテストシナリオで確認することが多いのではないかと思います。
負荷試験の流れ
多くの場合、負荷試験は以下のようなPDCAサイクルにて行われます。

テスト計画
最初に、目的に応じたテストの計画を行います。
負荷試験においてよくハマるパターンとして、「なんとなくシステムに負荷をかけてはみたが、何が良かった/悪かったのかがわからず、ズルズルと続けてしまう」というのがあります。
テストの目的を明らかにしたうえで、やるべきこと、確認すべきことを事前に計画しておけば、こういったことになりにくいです。
私は、計画を策定する際、以下のように進めています。
1. テスト目的を決める
テストの目的は、他人に簡潔に伝えるため、2〜3文で箇条書きにします。
例えば以下のようなものです。
1. xxx APIに新しいエンドポイントyyyを追加したが、これが事前に策定した性能要件を満たすかを確認する(負荷テスト的な観点)
2. 新しいエンドポイントyyyの追加が、既存エンドポイントのパフォーマンス劣化を招かないかを確認する(回帰テスト的な観点)
3. xxx API全体として、秒間何リクエスト程度までなら異常値を返さずに一定時間内に処理可能なのかを確認する(ストレステスト、キャパシティテスト的な観点)
コツとして、ここであまりテストシナリオの詳細(何RPS必要か、どういったデータの準備が必要かなど)を書かないようにするとよいかと思います。あくまで簡潔に書くようにします。
2. システムアーキテクチャの理解
次に、テスト対象のシステムを眺めるところに移ります(まだテストは書かないです!)。
アーキテクチャについてはこの記事の主眼ではないので割愛しますが、対象となるシステムの構造を理解することは必須です。
特に、システムの構成要素がどのように依存し合っているのか、それらを誰がどう管理しているのかを事前に把握しておくことは重要です。
開発エンジニアとコミュニケーションを取ったり、ドキュメントを確認する必要があるでしょう。
3. アクセスパターンの計測/推測
上述した通り、テスト対象となるシステムの実際のユースケースを理解することは重要です。
その上で、テスト計画の段階において、対象システムのアクセスパターン、その現在・将来の傾向についての情報を収集しておきます。
例えば、以下のような点を調べておく必要があるかと思います。
- 現在のアクセスパターン
- 秒間リクエスト数(RPS)
- ユニークユーザ数(UU、DAU等)
- 各機能のおおよそのレスポンスタイム
- 保持しているデータ量。データベースのレコード数やバッチが処理するファイルサイズ等
- 機能的な特性。検索・集計などのいわゆる「重い処理」が存在するか?絶対にダウンさせたくない機能、または最悪落としてもよい機能が存在するか?それぞれのトランザクションの中に、Read(参照)が多いのかWrite(更新)が多いのか?
- 時期的な傾向
- 短中期的・周期的なもの(例えば「毎日夜7時台がアクセスピーク帯になる。以前の実績値は xxx RPS」、「月末月初には月締め用のバッチ処理が走るため、対象となるAPIと共有しているデータベースに負荷がかかる」など)
- 季節的なもの(例えば、「正月期間はアクセス数がそれ以外の期間と比較して平均1.5倍になる。以前のピーク帯の実績値はxxx RPS」など)
- 単発的なもの(例えば、「CM放映直後にアクセス数がピークになる。以前の実績値はxxx RPS」など)
- 長期的なもの(例えば、「ここ2〜3年については、日次ユーザ数(DAU)が年間10%程度増加している」)
すでにシステムが稼働中なら、ログやモニタリングツールを用いて、アクセスパターンを眺めるとよいかと思います。新規開発等、ログを参考にできなさそうな場合であれば、想定されるユーザ数やユースケースからある程度概算することになると思います(これは正直かなり難しいと思うので、最悪ケースを想定して十分なバッファを持つことをおすすめします)。
また、情報が足りていないなら、プロダクトオーナーやアーキテクトに相談することも忘れないでください。
きっとテスターが持ち得ない情報を持っているはずです。
4. シナリオと期待値の策定
ここまで来たら、テストシナリオ(テストケース)と、その期待値を明確化します。
例えば以下のようなものです。
1. xxx API(新しいエンドポイントyyyを含む)に、本番環境からコピーしたデータを与えたうえで、アクセスピーク帯想定の1.5倍の負荷(600 RPS)を30分間かけ続ける
期待値:エラー率(秒間リクエストにおける)が0.1%以下であること。全リクエストのうち99%(99 percentile)のレスポンスタイムが1秒以内であること。xxx API内のyyyエンドポイント以外のすべてのエンドポイントについて、以前の負荷試験で計測された99 percentileとレスポンスタイムを比較し、20%以上の増加がないこと
2. xxx APIへの負荷を段階的に上げ続け、システムが限界を迎えるポイントを探る。エラー率が1%を超えた際にテストを打ち切る
期待値: テストを打ち切った際のRPSが1000 RPS以上であること。99 percentileのレスポンスタイムが2秒以内であること
3. xxx APIに、昼間帯アクセス想定の負荷(50 QPS)を3時間かけ続ける
期待値:エラー率(秒間リクエストにおける)が0.1%以下であること。99 percentileのレスポンスタイムが1秒以内であること。xxx API内のyyyエンドポイント以外のすべてのエンドポイントについて、以前の負荷試験で計測された99 percentileとレスポンスタイムを比較し、20%以上の増加がないこと。テスト中、APIサーバのCPU/メモリ/ディスク、JVMのヒープメモリ(ガベージコレクション)に異常がないこと
上のシナリオ例は、前述したテスト目的の例と符合させるように書いています。
こうすることで、「何ができればテスト完了と言えるのか」が明確になり、その後の工程で迷うことがなくなると思います。
もし、書いたシナリオがテスト目的と符合しない、あるいは違和感がある場合は、性能要件かテスト目的、あるいはシナリオのいずれかを見直してみるとよいと思います。
実施
シナリオと期待値が明確になったら、実際にテスト環境を構築して実施していきます。
1. ケース記述
テストシナリオを負荷試験ツール(Locustやk6など)で実行可能なスクリプトに落とし込みます。
すでにテスト対象のアプリケーションが存在する場合は、小さいRPSに置き換えたテストシナリオを一度流し、負荷試験の前に挙動をテストしておくとよいかと思います。
2. 環境構築
負荷試験用の環境を構築します。
構築すべきなのは、大きく分けて、負荷試験の対象となるシステム(対象システム)と、結果を計測するシステム(モニタリングシステム)、実際に負荷をかけるためのシステム(負荷ジェネレータ)の3つになるかと思います。
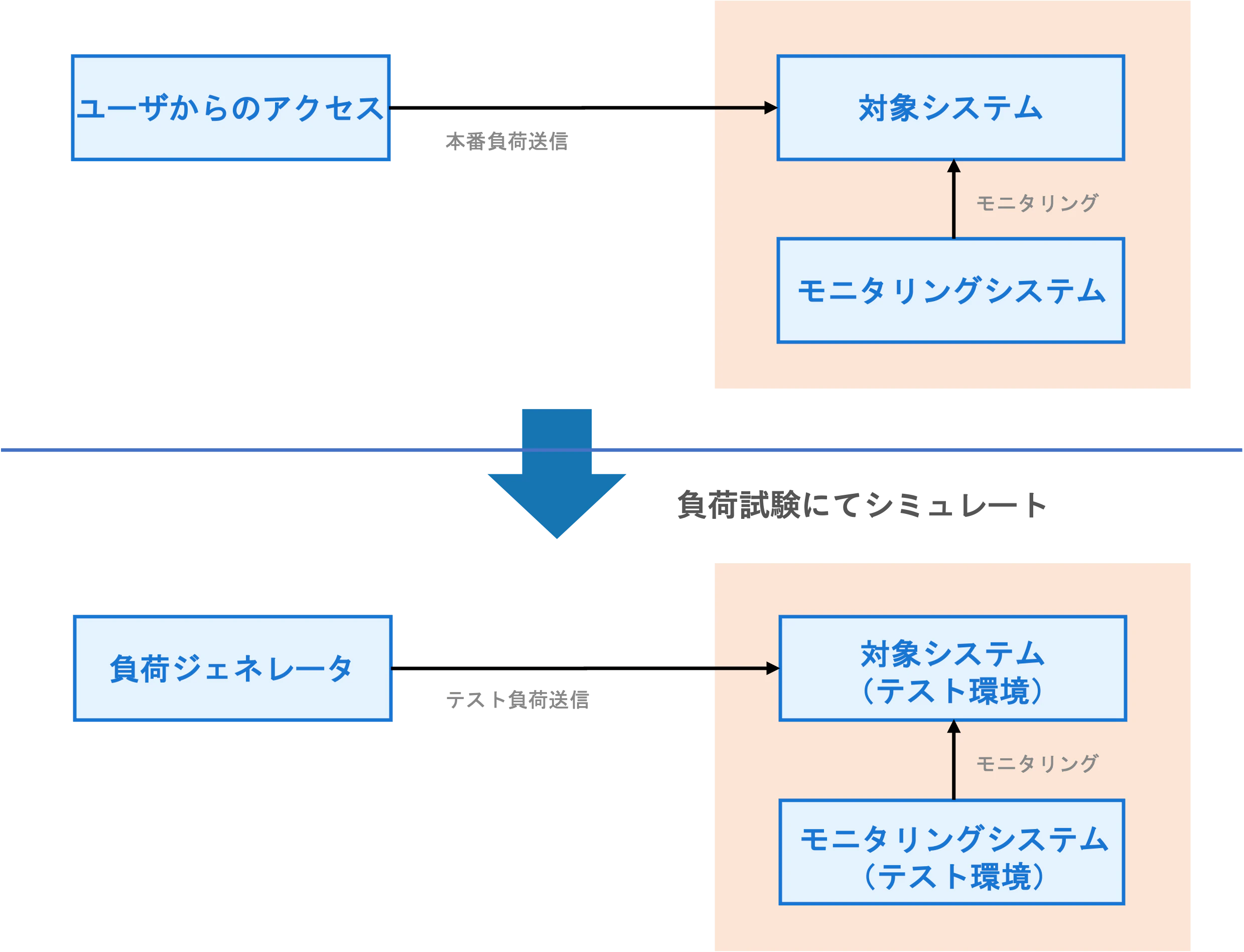
1. 対象システム
理想としては(データ等含め)本番環境と全く同じ構成を再現すべきですが、構築にかかる労力やコスト的に難しい場合がほとんどです。テストの目的に沿うように、サーバの台数を減らしたり、スペックを落としたりといったことをするとよいかと思います。
また、対象システムが外部のシステムに依存している場合は、モックに置き換えることで、テストによるトランザクションが外部システムに影響しないようにすることも検討する必要があります。これらを行う場合、行った変更によってパフォーマンスボトルネックが変わり、正しいテスト結果を得られなくなる可能性があることには注意が必要です。
2. モニタリングシステム
こちらも、基本的に本番環境と同じ構成を再現すべきです。特に、新規開発であれば、上述したテストの目的に「モニタリングシステムが期待通り動作するかどうかの確認」も含めるべきでしょう。
多くの場合、モニタリングシステムには、アプリケーション側から送られてくるログの集約・可視化、サーバのリソース(CPU、メモリ、ネットワーク等)やミドルウェアのメトリクス(Webサーバのスレッド数やデータベースのコネクション数、JVMのヒープメモリ等)が含まれるべきです。負荷試験の前に、これらが計測可能な状態になっているかを確認しておくとよいでしょう。
3. 負荷ジェネレータ
負荷ジェネレータについては、実際に負荷元になるネットワークと同じネットワーク(インターネット上からアクセスが来るシステムであればインターネット上、データセンター内からアクセスが来るシステムであればそのデータセンター内のサーバ)に構築するのが、実際の負荷をシミュレートするという観点からはよいかと思います。
また、大きな負荷をかけようとした際に負荷がかかり切らない、つまり、負荷ジェネレータの側にボトルネックがある場合があります(これを対象システムにボトルネックがある場合と切り分けるのは地味に難しいです)。複数台のサーバから同時に対象システムにアクセスする(ソケットディスクリプタなど、ボトルネックになっているカーネルパラメータを変更することも有効です)、(負荷試験ツールがサポートしていれば)クラスタ構成を組むなど、工夫が必要になってきます。
以下に、代表的な負荷試験ツールと、計測ツールを挙げておきます(具体的な使い方については記事がたくさんあるので割愛)。
負荷試験ツール
- k6:Go製のツールで、JavaScriptでシナリオを書ける。パフォーマンスが高く、シングルバイナリなのでCIへの組み込みも容易。迷ったらこれでよいかなと
- Locust:Pythonでシナリオを書ける
計測ツール
- ELK Stack (Elasticsearch, Logstash/Fluentd, Kibana): ログ集約・可視化ツール。Logstash、あるいはFluentdでアプリケーションから転送したログを、Kibanaの可視化UIを介してElasticsearchで検索、といった形で、ひとまとまりで使われることが多い
- Prometheus / Grafana:Prometheusがサーバのリソースやミドルウェアのメトリクスをモニタリングするツールで、Grafanaはそれを可視化するUIとしてよく使われる
3. スケジュールを決める
負荷試験には以下のような性質があります。
- 実施が開発プロジェクトの後工程になる傾向がある。機能テストなどと異なり、単体テストなど部分に切り出してテストすることが難しいため、どうしてもインフラ構築の完了後や、機能が出揃ったあとでの実施になってしまう
- 負荷試験で性能要件を満たせなかった場合、(一般的に)パフォーマンスボトルネックの分析、発見、改善にはかなりの知識と時間を要する
いずれもスケジュールへの大きなリスクになるので、スケジュールには十分なバッファを持って実施すべきです(最低でも2週間程度)。
また、インフラや依存システムの運用チームなど、関係各所への周知についてもスケジュールに織り込んでおきます。大規模なシステムだと、負荷試験による影響範囲も大きくなりがちなので、早めに動いておきます。
4. 実施
さて、ここまで来たらテストを実施します。
基本的に、これまで記載した通りに負荷ジェネレータからテストシナリオを流すだけなのですが、他のシステムとテスト環境を共有している場合、それらのシステムの動作が原因で期待した結果が出ない場合があります。何か余計なプログラムやプロセスが動いていそうであれば、それらを忘れずに止めておきます。
結果の解釈
ここが負荷試験において最も難しい箇所です。
実際にモニタリングツールの表示を見ながら、どこがボトルネックになっていそうかを判断します。
1. 結果の確認
最初は外形的に判断できる点(スループットやレスポンスタイム、ステータスコード等)から調べていき、それだけでは判明しないものについて、より細かいメトリクス(CPU/メモリ/NWなど)を見ていくとよいでしょう。
私はいつも以下の順で調べています。
1. 負荷ジェネレータ側から見たRPSとアプリケーション側(アプリケーションログ)から見たRPSが一致しているか
一致していない場合、負荷ジェネレータから対象システムまでのどこかの経路にスループット上のボトルネックがあり、負荷ジェネレータが対象システムに対し、テストシナリオにおける想定負荷をかけきれていない可能性があります(いわゆる「リクエストが詰まる」という状態)。この場合は、経路上のシステムのメトリクスを一つづつ確認し、ボトルネックを探していきます。
2. エラーログやスロークエリログ等、高負荷に起因する異常を示すログが出ていないか
すでに異常の内容がログから明らかであれば、その内容に沿ったチューニングを行うことを考えます。ログだけでは異常の内容が明らかでない場合であっても、原因を絞り込める場合があります。例えば、APIが高負荷の場合のみ500のHTTPステータスコードを返している場合、経路上のシステムのタイムアウト設定や、アプリケーション上のバグ(ロックのタイムアウトやレースコンディションなど)を疑います。
3. レスポンスタイム(レイテンシ)が性能要件に記載されている通りか
まず、負荷ジェネレータ側から測定したレスポンスタイムが要件を満たしているかどうかを、エンドポイントごとに確認していきます。要件を満たせていない場合、経路上のシステムのレスポンスタイムを一つづつ確認し、どの部分がレイテンシ上のボトルネックになっているかを探します。特定のエンドポイントのみが遅い場合、そのエンドポイントに絞って確認していきます。
4. 対象システム内の各構成要素のメトリクスが「問題ない」か
思いつく限り列挙すると、だいたいこのあたりは見ています。
| 種類 | 内容 |
|---|---|
| すべてのサーバに共通 | * ロードアベレージ(実行待ちになっているプロセス数):CPUのコア数以上になっているか * CPU利用率:100%で張り付いていないか、あるいは80%前後で推移していないか、あるいはまったく使っていないか(I/O待ちに時間を使いすぎている可能性がある)。また、Kubernetes環境など、共有コンテナ上で動作している場合、スロットリングしていないか * ディスクI/O:上限値を使い切っていないか |
| ロードバランサ | * TCPコネクション数:最大値で張り付いていないか * ネットワーク帯域:使い切っていないか |
| Webサーバ、リバースプロキシ(Apache、NGINX等) | * TCPコネクション数:最大値で張り付いていないか |
| アプリケーションサーバ | * TCPコネクション数:最大値で張り付いていないか。特にコネクションプーリングしている場合 * (JVMアプリケーションの場合)ヒープメモリ:適切にガベージコレクションされているか(定期的にヒープ領域が解放されているか) |
| データベースサーバ | * スレッド数:最大値で張り付いていないか |
5. ブラウザからアクセスした際に、性能要件に大きく反した挙動をしていないか
1.~4.に問題ない場合、最後にWebアプリケーション全体としてのパフォーマンスを確認しておきます(「結局アプリケーション全体としてリリースしてよいクオリティなのか?」という視点はテスターとして常に忘れてはいけません)。
ブラウザからの確認の場合、インターネット上の通信量や電波の状態等、テスターがコントロールできない要素が多くなってしまい、客観的な評価がしづらくなります。そのため、基本的には、実際にWebページを開いたうえで、ページが表示されるまでの時間が期待と大きくずれていないことを確認する感じになるかと思います。
その上で、Googleが中心になって提唱しているCore Web Vitalsは、ひとつの客観的な指標になりうるのではないかと思います。これは、Webサイトの健全性を示す指標で、2025年12月現在、以下の3つが指標とされています。
| 内容 | 目標値 | |
|---|---|---|
| LCP (Largest Contentful Paint) | 表示される最大の画像、テキスト ブロック、または動画(メインコンテンツ)のレンダリング時間 | 2.5秒以下 |
| CLS (Cumulative Layout Shift) | 読み込み中のガタつき(レイアウトシフト)の多さに関するスコア | 0.1未満 |
| INP (Interaction to Next Paint) | クリック、タップ、キーボード操作のレイテンシについてのスコア | 200ms以下 |
これらは、Google ChromeのDevToolで計測が可能です。
https://developer.chrome.com/docs/devtools/performance/overview?hl=ja
これらが必ずしもユーザの期待するパフォーマンスと一致するとは限りませんが、性能要件の一つとして含めておくと、プロジェクトメンバー間で共通理解が持てるようになるのではないかと思います。
ここまでが問題なさそうなら、負荷試験は完了です。
問題が発見された場合、次のステップに進みます。
2. 仮説立案と次のアクションの決定
もしボトルネックが明らかであれば、そこをチューニングすることが次のアクションになるかと思いますが、多くの場合、一度のテストシナリオ実行ですべてのボトルネックを明らかにすることは困難です。
その場合、ボトルネックとなり得る要因の可能性を列挙し、優先度を付けて検証していく必要があります。
例えば、データベースサーバにて特定のSQLにのみスロークエリログが観測され、その他のメトリクスに異常がない場合、可能性としては以下が考えられます。
- SQL文自体がチューニングできていない(例えば比較に
<>を使っている、サブクエリを使っているなど) - インデックスが適切でない
- SQLが処理すべきデータ量が多すぎる
- (トランザクションの場合)ロック待ちが発生している
前述の通り、ボトルネックではない箇所を改善しても、対象システム全体としてのパフォーマンスは改善しません。
ボトルネック解消の可能性、修正工数や影響範囲などをそれぞれ鑑み、検証の計画を立てていくとよいと思います。
チューニング
ボトルネックと思われるものの修正が完了したら、テストシナリオを再実行します。
ここで、なるべく小さい単位で修正を行い、前回の実施と結果を比較できるようにしておくと、何が要因だったのかがわかりやすくなると思います。
以上のプロセスを、性能要件を満たすまで繰り返します。
前述の通り、負荷試験は工数を読みにくい作業なので、十分なバッファを持つことをおすすめします。
負荷試験が完了したら、デバッグ用の設定(デバッグログやスロークエリログなど)を元通りにすることを忘れないでください。
IV. チューニングのTips
最後に、ボトルネックが見つかった際に使える「引き出し」として、代表的なチューニングのTipsを列挙しておきます。
記載している工数と効果はだいたいの感覚値になります。
改善のアイデアに詰まったときに見てもらえると嬉しいです。
共通
| 内容 | 工数 | 効果 | |
|---|---|---|---|
| スケールアウト | サーバの台数を増やし、負荷を分散することで全体としての処理能力の向上を図る。クラウド環境であれば非常に実施しやすいため、緊急性が高い場合はよく取られる手法(いわゆる「札束で殴る」)。だいたい真っ先に思いつくが、ボトルネックを考えず闇雲にやってもうまくいかないことが多い | 小 | 大 |
| スケールアップ | CPU/メモリ/ディスクなど、サーバのハードウェアを性能を良いものに置換する。これもボトルネックが明確なら非常に有効 | 中 | 大 |
| リトライ・タイムアウト値の最適化 | 他の構成要素に接続するタイプのサーバやミドルウェア、アプリケーション(ロードバランサ、Webサーバ、アプリケーション、ライブラリなどなど)において、リトライ値やタイムアウト値を正しく設定することは重要。デフォルト値はテスト用途に適していることが多く、高負荷下だと問題を起こすことが多い。一度確認しておくとよい | 小 | 中 |
| デバッグ用設定の無効化 | デバッグ用の設定については、本番環境ではすべて削除、あるいは無効化しておく。一部のWebフレームワークでは、開発用と本番環境用の設定が分かれているものがあるため、セキュリティ観点からも、必ず本番環境用の設定を利用するようにする。他にも、デバッグログを無効化することもパフォーマンスに大きく寄与する | 小 | 中 |
Webフロントエンド(配信)
| 内容 | 工数 | 効果 | |
|---|---|---|---|
| CDN(Content Delivery Network)の利用 | CDN事業者のサーバ(エッジサーバ)に画像等の静的コンテンツをキャッシュし、ユーザに近いサーバから配信することでレイテンシを削減する。AkamaiやFastly、Cloudflare、AWS CloudFrontなどが有名 | 大 | 大 |
| 画像、フォント等の最適化 | WebPやAVIFなどの画像形式、WOFFなどのフォント形式を使うことでサイズを削減する。ブラウザの後方互換性には気をつける | 中 | 中 |
| コンテンツの圧縮 | 転送時のファイルサイズを削減することで、転送時間を削減する。特に画像や動画などのファイルサイズが大きいファイルで有効。GzipやBrotliなど | 小 | 中 |
| キャッシュヘッダ (Cache-Control)の利用 | ブラウザやCDNに適切にファイルキャッシュさせ、サーバへのアクセス自体を減らす。キャッシュによるセキュリティ上の問題に注意 | 小 | 中 |
Webフロントエンド(ロジック部分)
| 内容 | 工数 | 効果 | |
|---|---|---|---|
| SSG (Static Site Generation)の導入 | 動的な処理が不要なページをビルド時にHTML化してしまう。ユーザからのリクエスト時に動的な処理を行わないため、高速化が期待できる | 大 | 大 |
| APIの呼び出しの見直し | バックエンドAPIの呼び出し回数を減らしたり、呼び方を変える。探すと意外と改善箇所が見つかる | 中 | 中 |
| リダイレクトの削減 | 不要なリダイレクトを削減することで、不要なネットワーク通信を削減できる。特に、リンクに記載するURLの末尾に"/"がないなど、設定不備によって意図せず発生するリダイレクトもあるので注意 | 小 | 大 |
| JavaScriptの非同期読み込み | <script>タグにdefer属性(あるいはasync属性)を加えることで、JavaScriptファイルを非同期に読み込むようにし、ブラウザのLoading時にDOMツリーの構築がブロックされる時間を削減する。JavaScriptの実行順が変わるので、挙動の変化に注意 | 小 | 中 |
| CSSセレクタの見直し | CSSセレクタについて、子孫セレクタなどを削減することで、ブラウザのRendering(レイアウト計算)時の検索処理の時間を削減する | 小 | 小 |
| CSSのimportの削減 | CSSのimport(@import)を削減することで、CSSの不要な読み込みを削減し、ブラウザのLoading時にDOMツリーの構築がブロックされる時間を削減する。最近はCSSもビルドツールでバンドルされていることがほとんどなので、あまり気にする機会はないかも | 小 | 小 |
| 画像のサイズ固定 | <img>タグにheight属性やwidth属性を明示的に指定することで、ブラウザのRendering(レイアウト計算)にかかる時間を削減する | 小 | 小 |
| Resource Hintsの導入 | よくアクセスされることが想定される、あるいはすでに必要であることが判明しているリソースに対して、<link>タグ内で明示的に宣言することで、ブラウザがリソースを必要とする前に先読みをさせる。DNS Prefetch(DNSリクエストの先読み)、Preconnect(リソースへのTCP接続の先読み)、Prefetch(リソース取得の先読み)、Prerender(リソースの描画の先読み)の4つがある | 小 | 中 |
| Service Workerによるブラウザ側へのキャッシュ | Service Workerを利用し、ブラウザ上にコンテンツをキャッシュすることで、仮コンテンツを取得するまでの時間を削減する。ブラウザがオフラインの場合でも動作するようにできるため、電波状態などによる通信遅延にも対応できる | 中 | 中 |
Webサーバ
| 内容 | 工数 | 効果 | |
|---|---|---|---|
| HTTP/2(gRPCを含む)化 | ストリーム多重化(特にブラウザの同時接続数上限の回避)やヘッダ圧縮(HPACK)による通信効率の向上。特に新規構築であれば、一度は考慮すべき | 中 | 大 |
| Keep-Aliveの設定 | TCPコネクションを使い回し、TCP接続確立(ハンドシェイク)におけるオーバーヘッドを減らす。基本的に有効だが、コネクションが切断されるタイミングを考えてタイムアウト値を適切に設定しないとバグのもとになるので注意 | 小 | 中 |
| 暖機運転(ウォームアップ) | アクセスピーク帯が来る前に、Webサーバにアクセスを流しておき、アクセス数が急激に増えること(アクセススパイク)による問題を回避する。アプリケーションサーバのコネクション数や、データベースサーバのメモリキャッシュや実行計画最適化、JVMにおけるJITコンパイルなどは、サーバの起動後ある程度アクセスが来ないとできない性質があり、暖機運転により、スムーズにピーク帯負荷を捌けるようになる。どちらかというと回避策の面が強いので、暖機運転せずにアクセスを捌けるようにしておいた方が安全ではある | 小 | 中 |
Webバックエンドアプリケーション(ビジネスロジック部分)
| 内容 | 工数 | 効果 | |
|---|---|---|---|
| アプリケーションサーバとWebサーバの分離 | Webサーバ(Apache、NGINX等)にコネクションの処理や静的コンテンツの配信を任せ、アプリケーションサーバ(Tomcat、WSGI、Unicorn等)にロジック部分の処理を任せることで、リソース利用率の効率化を行う。プログラミング言語によっては代表的な技術スタックがあるので、それを参考にするとよい | 中 | 大 |
| タスクの非同期(async)化 | サーバがこなすべき処理の一部を非同期化し、その終了を待たずにクライアントにレスポンスを返すことでレイテンシを削減する。処理の中に、メールの送信やログの出力など、クライアントに結果を応答する必要がないものがある場合に有効。実装としては、スレッドの生成によるものや、Kafkaなどのメッセージブローカーを用いたものが考えられる | 小 | 中 |
| タスクの並列(concurrent)化 | サーバがこなすべき処理の一部を並列処理により行うことで、リソース利用率の効率化を行う。例えば、ある処理がDBアクセスや外部のAPI呼び出しなど、CPUを利用せず待機している間に、他の処理がそのCPU時間を利用することで、全体としての処理時間を削減することができる。マルチスレッド化のほか、言語レベルでサポートされているコルーチンやGoroutine(いわゆる軽量スレッド)等がこれに含まれる(多くの場合プログラミングが難しくなる) | 中 | 中 |
| タスクの並行(parallel)化 | サーバがこなすべき処理の一部を並行処理により行うことで、複数のタスクを同時に進行させ、処理時間を短縮する。例えば、ある処理が複数回API呼び出しを行って結果を集約する場合、各々の呼び出しを並行して行うことで、処理時間を短縮できる。これも実装としてはマルチスレッドや軽量スレッドによるものが該当するが、これらの機能を利用していても、アプリケーションサーバのCPUコアが複数ないと、処理が並行に実行されないことに注意 | 中 | 中 |
| コネクションプーリング | 一般的には、TCPのクライアントサーバモデルの通信において、クライアント側で事前に複数のTCPコネクションを確立しておき、必要なときに使い回す技術のことを指す。都度コネクションを確立する必要がないため、処理時間やCPU/メモリのリソース利用の点で有効。アプリケーションサーバとデータベースサーバ間で行うことが多い。保持するコネクションの数が多すぎると、サーバのリソースを消費したり、無効なコネクションを使い回そうとしてしまったりするので、全体のスループットを見ながらほどほどに | 小 | 中 |
| コネクションオブジェクトの持ち回し | HTTPクライアントライブラリやDBクライアントライブラリを利用する際に、アクセスのたびに都度コネクション(あるいはコンテキスト)オブジェクトを生成するのではなく、シングルトン化などを行い、持ち回す形で利用することで、コネクションを生成する際のオーバーヘッドを削減する(毎回生成しちゃうのは初心者あるあるのミス) | 小 | 中 |
| サーキットブレーカーパターンの導入 | 外部のAPIやDB等の呼び出しにおいて、呼び出し数やエラー数がある一定の値を超えた際に、その呼び出しを打ち切るしくみ。JavaだとResilience4Jといったライブラリが有名。もとは呼び出し先の障害が呼び出し元に波及しないようにすることが目的のものだったが、負荷軽減の観点でも使える | 中 | 中 |
| データベースクエリチューニング | データベースのクエリチューニング一般について。まずはスロークエリログを確認するところから始める。スロークエリが見つかった場合、(RDBの場合は)実行計画を確認しつつインデックスの最適化やデータ転送量の削減を行う | 小 | 大 |
| N+1問題への対処 | DBアクセスにおける典型的なボトルネックの一つで、アプリケーションのループの内部で都度SQL文を発行する実装にしてしまい、本来不必要な大量のSQL文を発行してしまうこと。ほとんどの場合SQL文に問題があるだけなので、JOINを利用する形に修正する。O/Rマッパーを利用している場合は、発行されるSQL文をデバッグログから見つつ、ライブラリの指示に従うとよい | 小 | 大 |
| DBのロック粒度の見直し | ロックの粒度を小さくすることによって他のリクエストがロック待ちで待機させられる可能性を減らし、全体としてのスループットを向上する。クエリ自身に問題はないが遅くなる場合はだいたいがこれ。データ不整合を生じない程度にロックの粒度は小さくした方がよい(テーブル構成がしっかりしていれば、ほとんどの場合ロックは1行になるはず) | 中 | 大 |
| バルクインサート/アップデート/デリート | RDBにおけるトランザクションにおいて、更新SQLの完了のたびにコミットするのではなく、複数回更新SQLが完了してからコミットすることにより、コミットによるオーバーヘッドを削減する。コミット文の処理時間は意外と大きく、この回数を減らすだけでもかなりの速度改善とDBへの負荷軽減が見込める。特にバッチ処理の高速化において有効 | 小 | 大 |
| 外部DBへのデータキャッシュの導入 | 高速なアクセスが必要な一部のデータのみをデータベースから隔離し、KVS等のより高速な参照ができるデータベースにキャッシュとして保持することで、レイテンシを削減する。アプリケーションレイヤでキャッシュと言うと、このことを指すことが多い。もちろん有効な手法だが、同じデータを複数箇所で持つことになるので、元データとの同期やキャッシュの無効化のタイミングには常に気をつける必要がある | 中 | 大 |
| インメモリキャッシュの導入 | こちらは、アプリケーションのメモリ自体にデータを保存することにより、外部DBにアクセスすることによるオーバーヘッドを削減する。前述の「コネクションオブジェクトの持ち回し」もこれに当たる。アプリケーションが複数台に分散する場合、キャッシュしたデータの更新が難しくなるため、アプリケーション設定値などの、変更が極めて少ないデータに限ってキャッシュするようにする | 中 | 中 |
| 不要なログの削減 | 不要なログを削減することで、ディスクI/Oに利用する時間を削減する。ログに限らず不要な処理を入れるべきではないが、ログの対応は他の処理に比べて後回しにされやすい(デバッグログが本番環境に出てしまったり)。ロガーのログレベルを適切に設定するなど、設計時から管理しておくとよい | 小 | 小 |
データベースサーバ (DB)
| 内容 | 工数 | 効果 | |
|---|---|---|---|
| インデックスの最適化 | インデックスを追加、削除することで、SQL文の処理時間削減やDBへの負荷軽減を図る。(RDBの場合、)まずはテーブルに対して発行するSQL文を確認し、その実行計画を見るとよい。インデックスが効いていない場合、フルスキャンが実行されており、参照クエリが非常に遅くなる。インデックスはむやみに増やすと更新クエリを遅くする原因になるのでほどほどに | 小 | 大 |
| データ量の削減(データクリーニング) | 利用されないデータをアーカイブテーブルに移すなどして、ユーザからアクセスされるデータ量を小さく保つことで、SQL文の処理時間削減やDBへの負荷軽減を図る。定期的なデータ削除については、設計時に織り込んでおくとよい | 中 | 中 |
| リードレプリカの作成 | 参照専用のDBインスタンスを新たに作り、参照クエリについてはそこにアクセスさせることで、元のDBインスタンスへの負荷軽減を量る。最近のDBMSはネイティブでサポートしていることも多い | 中 | 大 |
| テーブルの水平分割 | テーブル内のデータを行単位で分割して複数のテーブルに保存することで、各テーブルのデータ量を削減し、SQL文の処理時間削減やDBへの負荷軽減を図る。特定のテーブルのデータ量が多くなってきたときに有効。最近のDBMSはネイティブでサポートしていることも多く、レコードのキー値等によって格納するテーブルを決定する | 大 | 大 |
| テーブルの垂直分割 | データベース内のデータを列単位で分割して複数のテーブルに保存することで、各テーブルのデータ量を削減し、SQL文の処理時間削減やDBへの負荷軽減を図る。パフォーマンスチューニングというよりは、リファクタリングの観点で使われることが多いような気がする | 大 | 大 |
体感速度の向上(UX観点でのチューニング)
こちらは厳密にはシステムパフォーマンスの改善ではないですが、ユーザに「遅い」と感じさせないための仕様/実装上の工夫により、ユーザの「体感速度」を短縮することができる可能性があります。
実際にシステムが早いか遅いかを判断するのはシステムのユーザです。
UX改善という意味では、こういった「小手先の」対応も結構重要だったりします。
| 内容 | 工数 | 効果 | |
|---|---|---|---|
| ローディングアイコンの導入 | 画面の描画がすべて完了する前に、「読み込み中」を示すアイコンを表示することで、何らかの処理がされていることをユーザに示す | 小 | 大 |
| スケルトンスクリーン(仮コンテンツ)の導入 | 画面の描画がすべて完了する前に、「読み込み中」を示す枠を表示し、何らかの処理がされていることをユーザに示す。ローディングアイコンに比べ、読み込み後の画面の変化が少ないので、不快に感じられにくい気がする | 中 | 大 |
| クライアント側でのアニメーション表示 | サーバとの通信中に、クライアントでアニメーションを表示し、何らかの処理がされていることをユーザに示す。スマホアプリだと、いわゆるスプラッシュ画面が標準で用意されており、ここにうまくアニメーションを表示させることで、ユーザの待たされている感覚を軽減できると思われる | 中 | 大 |
| ユーザ操作後の処理をフロントエンド上で表現する | ユーザからのインタラクティブな操作について、操作を行ったことを先にユーザに表示し、そのあとに実際の処理を行うことで、何らかの処理がされていることをユーザに示す。X(旧Twitter)における、いいねボタンの処理(先にいいねのアイコン(ハートマーク)が活性化し、(フロントエンド上で)ユーザに処理ができたことを伝えたあと、実際のバックエンドへのリクエストを非同期で行う)が有名 | 小 | 中 |
| リストのページネーション | 検索結果や購入履歴など、要素数が多くなりがちなリストの内容を表示する際に、例えば10件ずつなど、リストを分割した内容を表示するようにすることで、要素の取得にかかる時間を削減する。実装上はバックエンドAPI側でページネーションに対応したインタフェースを用意し、フロントエンド側で対応するページを用意する場合が多い。オフセット(呼び出し側で何番目の要素が必要かを指定)を用いる方法や、カーソル(応答側が各要素に対応するキーを用意し、呼び出し側は次の呼び出しでどの要素からのリストが必要かをキーで指定する)を用いる方法などがある | 中 | 大 |
| 要素の遅延読み込み化(Lazy Load) | ユーザのスクロール操作に対して、非同期なバックエンドAPI呼び出しやDOM要素の書き換えを行うことにより、ユーザに表示されている範囲内の要素だけが読み込まれるように実装することで、無駄な要素の読み込みを削減する。これをリストのページネーションに適用すると、いわゆる無限スクロールになる | 中 | 大 |
おすすめ文献
- MDN パフォーマンスの基礎 上述したMDN docのパフォーマンスについての記載です。網羅的なのでサッと一読することをおすすめします
- Amazon Web Services負荷試験入門 ――クラウドの性能の引き出し方がわかる 負荷試験について知りたい場合は一読することをおすすめします。AWSと名前がついていますが、負荷試験一般に言えることが多く記載されており、よく体系化されています
- 達人が教えるWebパフォーマンスチューニング 〜ISUCONから学ぶ高速化の実践 ISUCON(パフォーマンスチューニングコンテスト)の対策本です。パフォーマンスチューニングの、特に戦術的な面について知りたい際におすすめです。ISUCON自体がWebバックエンドとインフラのチューニングコンテストなので、内容もそのあたりが中心になっています
- Webフロントエンド ハイパフォーマンス チューニング こちらはWebフロントエンドのパフォーマンスチューニングについての本です。一通りブラウザの挙動を説明したうえで、チューニングのTipsを記載しています。ブラウザやJavaScriptの進化は目覚ましく、内容的に少し古くなってしまっている部分もあります
- Web配信の技術―HTTPキャッシュ・リバースプロキシ・CDNを活用する ブラウザキャッシュとCDNに焦点を置いた本です。結構難しいですが、読むとかなり知識を得られます
- Performance Testing Guidance for Web Applications 少し古いですが、Microsoftが作成した負荷試験のガイドラインです。体系化されていて、読みやすいです
まとめ
うまくまとまったような、雑多なTips集になってしまったような感じもしますが、Webシステムのパフォーマンスという観点で一本記事を書いてみました。
パフォーマンスチューニングや検証が一人でできるようになると、エンジニアとして一歩成長した感じがしますね。
この記事が役に立つと幸いです。
感想
- 2025年は仕事関連の負荷試験でパフォーマンスが出ず、本当にヒドい目にあったので、その供養も兼ねて、得られた知識を書いてみました。ソフトウェアテストの話からは若干逸れてしまったかもしれません
- Webフロントエンドまわりの知識はまだ曖昧だなと感じました
- 初めて技術記事の執筆に生成AIを使ってみました。ドラフトを書いてくれたり、SVGの図を生成してくれたりして、そこそこ役に立ちました。ありがとうGeminiくん
- この記事の初稿は、アドカレ担当日の23時54分に完成しました。間に合ってよかった