内容
過去に以下のような記事を書きましたが、この時は Amazon S3 Vector が新しく登場したため、とりあえず Amazon Bedrock Knowledge Bases のベクトルストアに Amazon S3 Vector を指定して触ってみようといったところでプレイグラウンドから試していました。
今回は、Amazon Bedrock Knowledge Bases Retrieval MCP Server を使って、Amazon Bedrock Knowledge Bases を呼び出せるか、また課題となりそうな点がないか試してみます。
確か JAWS-UG Presents - AI Builders Day
AgentCore で Bedrock KB を噛ませるなら? Strands retrieve tool vs Bedrock KB MCP Server の登壇で呼び出す時に一部利用できない機能などもあった気がします。
イメージ
やってみよう
Amazon S3 へデータの格納
今回は、総務省の 大正9年~令和6年(エクセル:39KB)の人口の推移 のデータを Amazon S3 に格納しておきます。
実際にはもっと多くのデータソースをあった方がいいのだと思いますが、個人検証となりコストもかかりますので、必要最小限のデータとなります。

Amazon Bedrock Knowledge Bases の設定
Amazon Bedrock Knowledge Bases の設定は多くの方が既に記事を公開していると思いますので詳細は割愛します。
Amazon Bedrock Knowledge Bases Retrieval MCP Server から呼び出す際の 2 つのポイントだけ紹介します。
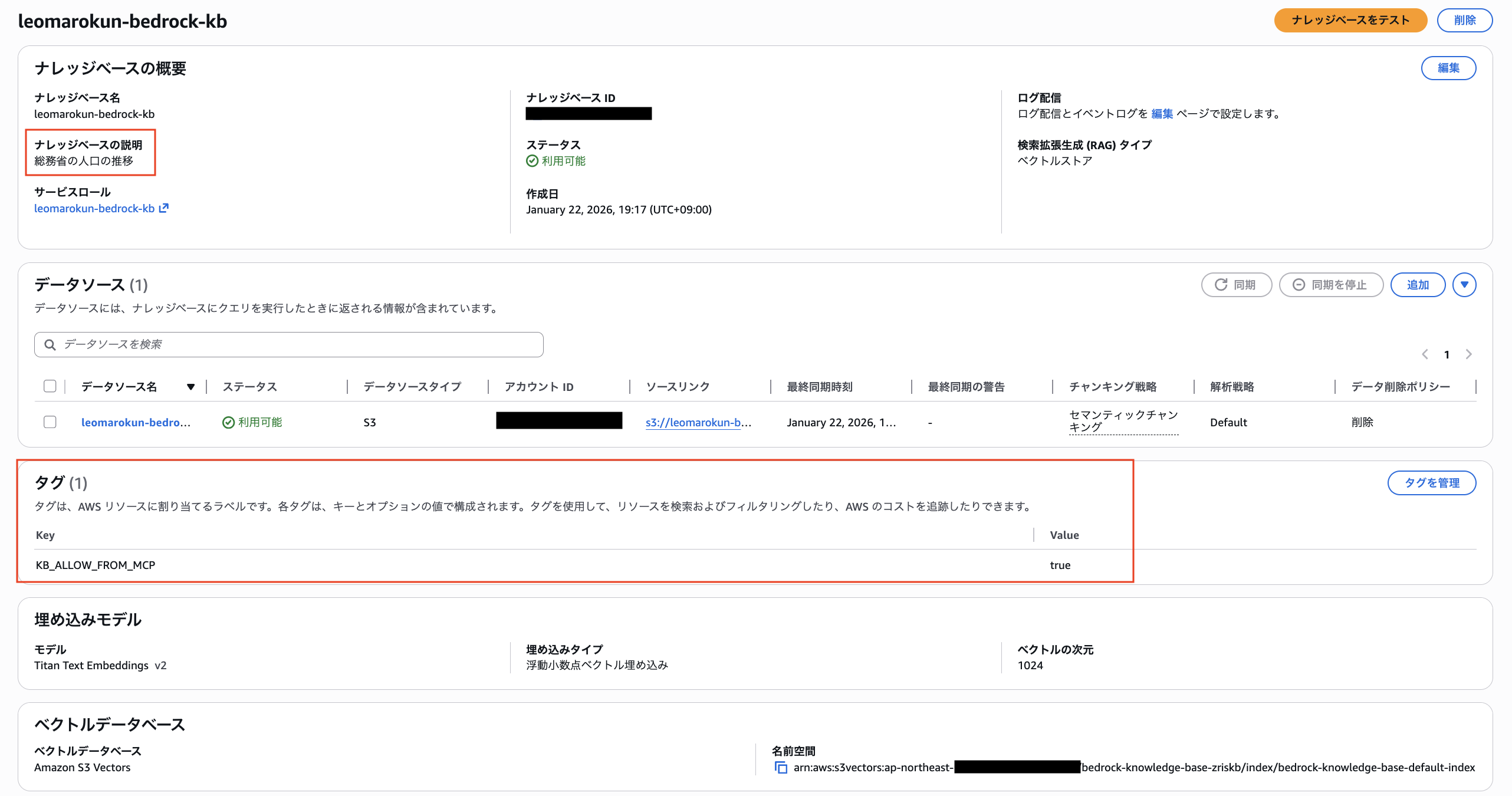
- ナレッジベースの説明
「総務省の人口の推移」と記載しておきます。
これを記載しておかないと、クライアントから Amazon Bedrock Knowledge Bases を呼び出す時にこの Amazon Bedrock Knowledge Bases は何のデータが格納されているものかが認識されないため呼び出されません。
- タグ
"KB_ALLOW_FROM_MCP": "true" を付与しておきます。
後述 の MCP の設定で詳しくでてきますが、このタグを付与しておくことによりクライアントはこのタグが付与されている Amazon Bedrock Knowledge Bases を対象とし呼び出すことができます。
MCP の設定
.vscode/mcp.json を以下の通り設定します。
{
"servers": {
"awslabs.bedrock-kb-retrieval-mcp-server": {
"command": "uvx",
"args": ["awslabs.bedrock-kb-retrieval-mcp-server@latest"],
"env": {
"AWS_PROFILE": "default",
"AWS_REGION": "ap-northeast-1",
"FASTMCP_LOG_LEVEL": "ERROR",
"KB_INCLUSION_TAG_KEY": "KB_ALLOW_FROM_MCP",
"BEDROCK_KB_RERANKING_ENABLED": "false"
},
"disabled": false,
"autoApprove": []
}
}
}
先程、Amazon Bedrock Knowledge Bases でタグを
"KB_ALLOW_FROM_MCP": "true"
に指定しました。
mcp.json では
"KB_INCLUSION_TAG_KEY": "KB_ALLOW_FROM_MCP"
を設定します。
"BEDROCK_KB_RERANKING_ENABLED": "false"
のように、Rerank もできるようです。
ただし、今回は Rerank のモデルを呼び出すとコストが発生するため、"false" とします。
Rerank とは何かについては詳しく触れませんが、過去以下の記事でも書いておりますので、よければ参考にしてください。
VSCode に必要な IAM ポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:GetKnowledgeBase",
"bedrock:Retrieve"
],
"Resource": "arn:aws:bedrock:ap-northeast-1:123456789012:knowledge-base/ナレッジベースID"
},
{
"Effect": "Allow",
"Action": [
"bedrock:ListDataSources",
"bedrock:ListTagsForResource",
"bedrock:ListKnowledgeBases",
"bedrock:Rerank"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.rerank-v1:0"
}
]
}
"Resource": "arn:aws:bedrock:ap-northeast-1:123456789012:knowledge-base/ナレッジベースID" で特定の Amazon Bedrock Knowledge Bases のアクセスに絞るようしましょう。
呼び出してみる
では、まずはシンプルに GitHub Copilot Chat から呼び出してみます。
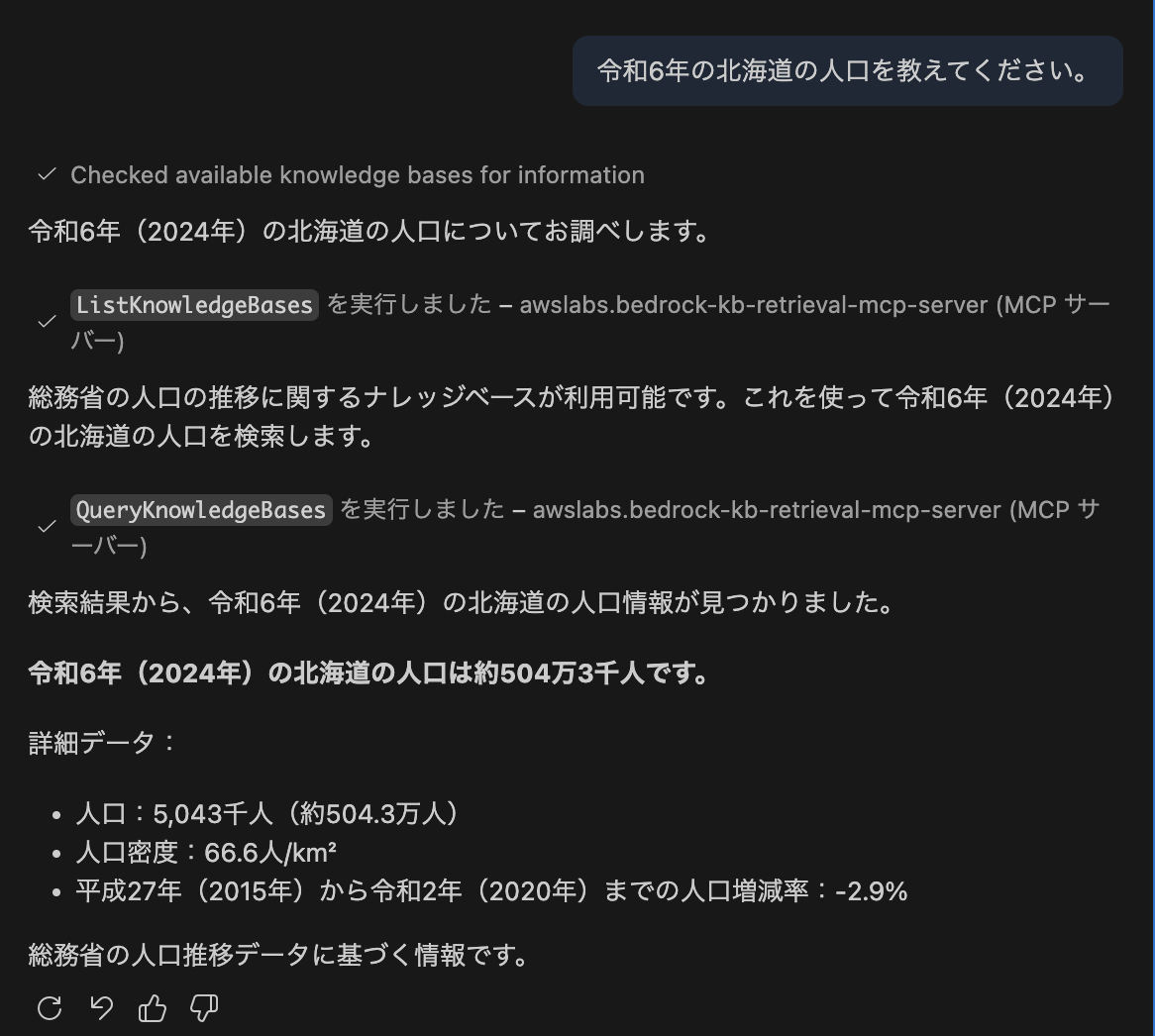
次にこのデータはどこのソースから取得してきたものかわかるか確認してみます。

深掘りしてみよう
QueryKnowledgeBases の input
先程 【呼び出してみる】で実施した、QueryKnowledgeBases のツールの実装を Git から確認してみます。
input のパラメータの仕様は以下の通りのようです。
- 必須
- knowledge_base_id
- query
- number_of_results
- data_source_ids
- reranking
- reranking_model_name
【呼び出してみる】で実施した内容では、次の通りとなっていました。

気になった点としては、2025 年 1 月 時点では、metadata によるフィルタリングが、Amazon Bedrock Knowledge Bases Retrieval MCP Server からではできなさそうということです。
QueryKnowledgeBases の output
output は以下の情報が返却されます。
- content
- location
- score
【呼び出してみる】で実施した内容の中に s3Location があり、ここからファイル名を返却していることがわかりました。
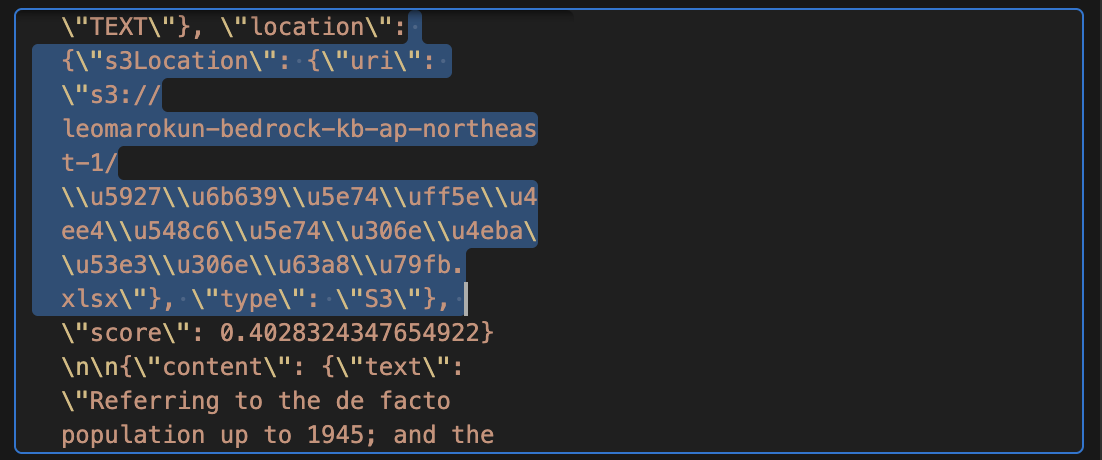
気になった点として、score があまり良くないという点ですが、そもそも今回は、総務省の 大正9年~令和6年(エクセル:39KB)の人口の推移 のデータ 1 ファイルのみです。
要因として、
- ドキュメントの内容が広範囲 - 全都道府県・複数年度のデータを含む大きな表なので、クエリとの完全一致度が低い
- 単一の結果 - Amazon Bedrock Knowledge Bases 内に他と比較対象になるドキュメントがない
などが考えられるため、気にする必要はなさそうです。
最後に
とは言っても、RAG の性能が上手く上がらない場合、
- Markdown に変換してからベクトル化する
- 適切なチャンク戦略をとる
などの対策が必要と思っています。
これは、カスタム変換の Lambda 関数を定義し、ナレッジベースの取り込みプロセスに独自のロジックを挿入することで実現可能です。