DynamoDBを開き、「テーブル」から「テーブルの作成」をクリック。

ここでは書籍情報を保存することとするので、[テーブル名]に Books と入力してください。
[パーティションキー]を指定します。
パーティショニングとインデックス化は、パーティションキーにより実行されます。
ここでは、著者によって、書籍を検索するようにするので、Author と入力しておきます。
しかし、複数の著作がある著者もいるので、著者のみでは識別できません。
そこで、著者と著者によって識別できるように、ソートキーに Title を追加します。
テーブル設定では、Auto Scalingを使うか、スループットを手動でプロビジョニングするか、テーブルにセカンダリインデックスを定義するかどうかです。
ここでは、デフォルト設定を使用します。この場合、テーブルはDynamoDBにより自動でモニタリングされ、それに応じて読み取りおよび書き込みスループットが設定されます。
・セカンダリインデックスなし。
・Auto Scaling のキャパシティーを AnyScale のデフォルト機能を示すテーブルの作成ページで 70% のターゲット使用率 (最低キャパシティーは 5 つの読み込みと 5 つの書き込み) に設定。
・Encryption at Rest with DEFAULT encryption type

以下のようにテーブルが作成されました。
・テーブル名:Books
・プライマリキー:Author
・検索キー:Title
早速データを「項目」に追加していきます。「項目の作成」をクリック。

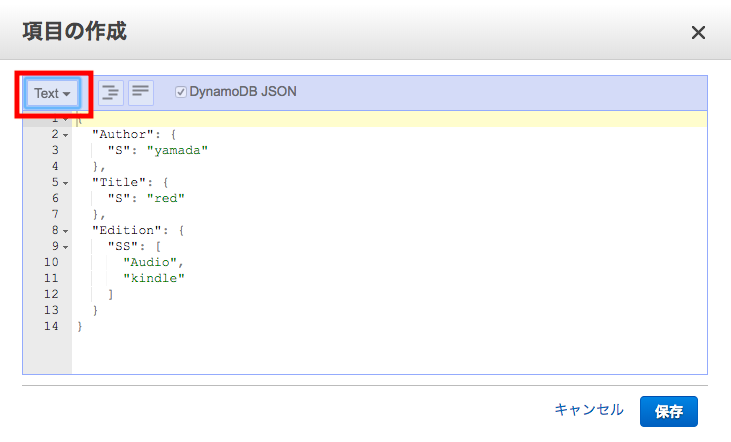
Author に、yamada 、Title に red と入力してみましょう。
また、この項目に別の属性を追加してみましょう。
「Append」-「StringSet」で、Edition で Audio と Kindle を入力。

また、表示方法を Tree → Text に変更してみます。
なお、項目の上限サイズである400キロバイト以内であれば、いくつでも属性を追加することができます。
同じようにいくつか追加してみましょう。
項目によって属性が異なっていても構いませんが、Author と Title は必須です。

では、テーブルが作成されたことでクエリオペレーションを使って、書籍を探してみましょう。
パーティションキーの値の指定が必要です。今回は yamada の書籍を探します。
2冊の書籍が出てきました。

次に、スキャンオペレーションです。
Edition を Audio にすると何冊かの書籍が検索されました。