内容
今回は AWS Lambda Tool MCP Server を利用してみる。
そして MCP を利用した場合と利用していない場合の回答結果を比較しそもそも MCP 自体がどのようなときなら必要か考えてみたいと思います。
AWS Lambda Tool MCP Server とは
AWS Lambda Tool MCP Server は、MCP クライアントと AWS Lambda 関数間のブリッジとして機能し、生成 AI モデルが Lambda 関数をツールとしてアクセスして実行できるようにします。
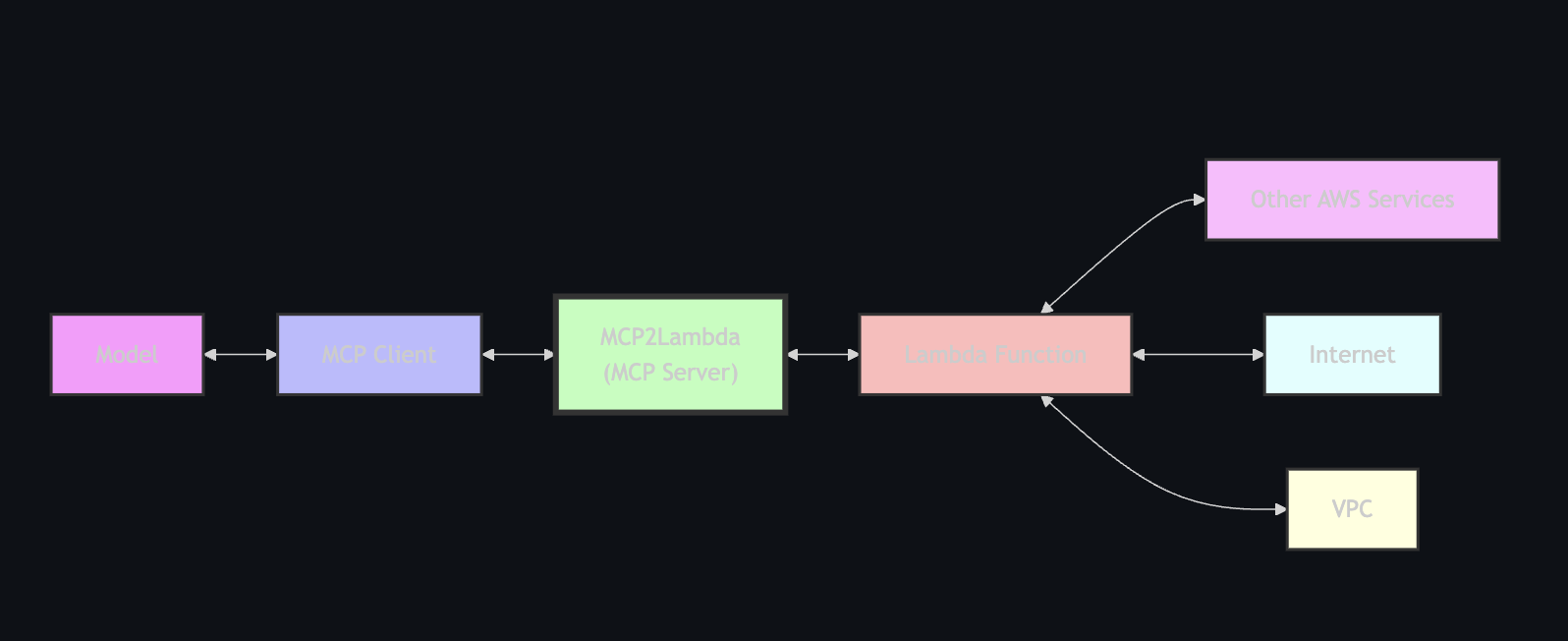
AWS Lambda Tool MCP Server を使うと嬉しいことは下記の記事の「Lambda MCP サーバーのセキュリティ」あたりで大変よく紹介されていましたので、そちらを参考にしていただいた方がわかりやすいです。
Lambda 関数の準備
2 つの Lambda 関数をデプロイします。
- Lambda1
- 役割: グラフの「設定ファイル」を作成
- 出力: JSON設定
- ❌ しないこと: 実際のグラフの描画
- ✅ すること: グラフを描くための「レシピ」を作成
lambda-functions/chart_data_processor.py
import json
import logging
import statistics
from datetime import datetime, timedelta
import random
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""
MCP Tool: chart_data_processor
データを処理し、さまざまな可視化タイプ用のチャート用JSONを生成します
期待される入力スキーマ:
{
"data": [{"label": "Q1", "value": 100}, ...] または [[1,2,3], [4,5,6]],
"chart_type": "bar|line|pie|scatter|area|histogram",
"options": {
"title": "チャートタイトル",
"x_label": "X軸ラベル",
"y_label": "Y軸ラベル",
"colors": ["#FF6384", "#36A2EB", "#FFCE56"],
"calculate_trend": true,
"include_statistics": true
}
}
"""
logger.info(f"Received event: {json.dumps(event)}")
try:
data = event.get('data', [])
chart_type = event.get('chart_type', 'bar').lower()
options = event.get('options', {})
if not data:
raise ValueError("Data is required")
# チャートの種類に基づいてデータを処理する
processed_data = process_data_for_chart(data, chart_type, options)
# チャート構成を生成する
chart_config = generate_chart_config(processed_data, chart_type, options)
# 要求に応じて統計を計算する
stats = {}
if options.get('include_statistics', True):
stats = calculate_statistics(data)
# 要求に応じてトレンド分析を生成する
trend = {}
if options.get('calculate_trend', False):
trend = calculate_trend(data)
return {
'statusCode': 200,
'body': json.dumps({
'chart_config': chart_config,
'processed_data': processed_data,
'statistics': stats,
'trend_analysis': trend,
'chart_type': chart_type,
'success': True
})
}
except Exception as e:
logger.error(f"Error: {str(e)}")
return {
'statusCode': 400,
'body': json.dumps({
'error': str(e),
'success': False
})
}
def process_data_for_chart(data, chart_type, options):
"""生データをチャート用フォーマットに変換する"""
if chart_type in ['bar', 'line', 'area']:
return process_categorical_data(data)
elif chart_type == 'pie':
return process_pie_data(data)
elif chart_type == 'scatter':
return process_scatter_data(data)
elif chart_type == 'histogram':
return process_histogram_data(data, options.get('bins', 10))
else:
raise ValueError(f"Unsupported chart type: {chart_type}")
def process_categorical_data(data):
"""棒グラフ・折れ線グラフ・エリアチャート用データ処理"""
if not data:
return {"labels": [], "datasets": []}
# 入力フォーマットの違いに対応
if isinstance(data[0], dict):
# 形式: [{"label": "Q1", "value": 100}, ...]
labels = [item.get('label', f'項目{i+1}') for i, item in enumerate(data)]
values = [item.get('value', 0) for item in data]
elif isinstance(data[0], list) and len(data[0]) >= 2:
# 形式: [["Q1", 100], ["Q2", 150], ...]
labels = [item[0] for item in data]
values = [item[1] for item in data]
else:
# 形式: [100, 150, 200, ...]
labels = [f'項目{i+1}' for i in range(len(data))]
values = data
return {
"labels": labels,
"datasets": [{
"data": values,
"backgroundColor": generate_colors(len(values)),
"borderColor": generate_colors(len(values), True)
}]
}
def process_pie_data(data):
"""円グラフ用データ処理"""
if isinstance(data[0], dict):
labels = [item.get('label', f'スライス{i+1}') for i, item in enumerate(data)]
values = [item.get('value', 0) for item in data]
else:
labels = [f'スライス{i+1}' for i in range(len(data))]
values = data if not isinstance(data[0], list) else [item[1] for item in data]
# 割合(パーセンテージ)を計算
total = sum(values)
percentages = [round((v / total) * 100, 1) if total > 0 else 0 for v in values]
return {
"labels": labels,
"data": values,
"percentages": percentages,
"backgroundColor": generate_colors(len(values))
}
def process_scatter_data(data):
"""散布図用データ処理"""
if isinstance(data[0], dict):
# 形式: [{"x": 1, "y": 2}, ...]
points = [{"x": item.get('x', 0), "y": item.get('y', 0)} for item in data]
elif isinstance(data[0], list) and len(data[0]) >= 2:
# 形式: [[1, 2], [3, 4], ...]
points = [{"x": item[0], "y": item[1]} for item in data]
else:
# x値はインデックスとして自動生成
points = [{"x": i, "y": value} for i, value in enumerate(data)]
return {
"datasets": [{
"data": points,
"backgroundColor": "#FF6384"
}]
}
def process_histogram_data(data, bins):
"""ヒストグラム用データ処理"""
# 必要に応じてデータを平坦化
values = []
if isinstance(data[0], dict):
values = [item.get('value', 0) for item in data]
elif isinstance(data[0], list):
values = [item[1] if len(item) > 1 else item[0] for item in data]
else:
values = data
# ヒストグラムのビンを作成
if not values:
return {"labels": [], "data": []}
min_val = min(values)
max_val = max(values)
bin_width = (max_val - min_val) / bins
bin_labels = []
bin_counts = []
for i in range(bins):
bin_start = min_val + i * bin_width
bin_end = min_val + (i + 1) * bin_width
bin_labels.append(f'{bin_start:.1f}-{bin_end:.1f}')
count = sum(1 for v in values if bin_start <= v < bin_end)
# 最後のビンには最大値も含める
if i == bins - 1:
count = sum(1 for v in values if bin_start <= v <= bin_end)
bin_counts.append(count)
return {
"labels": bin_labels,
"data": bin_counts,
"backgroundColor": generate_colors(bins)
}
def generate_chart_config(processed_data, chart_type, options):
"""チャート設定全体を生成"""
config = {
"type": chart_type,
"data": processed_data,
"options": {
"responsive": True,
"plugins": {
"title": {
"display": bool(options.get('title')),
"text": options.get('title', '')
},
"legend": {
"display": chart_type in ['pie', 'line', 'area']
}
}
}
}
# 軸ラベルをサポートするチャートの場合は追加
if chart_type in ['bar', 'line', 'area', 'scatter', 'histogram']:
config["options"]["scales"] = {
"x": {
"title": {
"display": bool(options.get('x_label')),
"text": options.get('x_label', '')
}
},
"y": {
"title": {
"display": bool(options.get('y_label')),
"text": options.get('y_label', '')
}
}
}
return config
def calculate_statistics(data):
"""データから基本統計量を計算"""
# 数値データを抽出
values = []
if isinstance(data[0], dict):
values = [item.get('value', 0) for item in data if isinstance(item.get('value'), (int, float))]
elif isinstance(data[0], list):
values = [item[1] if len(item) > 1 else item[0] for item in data if isinstance(item[-1], (int, float))]
else:
values = [v for v in data if isinstance(v, (int, float))]
if not values:
return {}
return {
"count": len(values),
"sum": sum(values),
"mean": statistics.mean(values),
"median": statistics.median(values),
"min": min(values),
"max": max(values),
"range": max(values) - min(values),
"std_dev": statistics.stdev(values) if len(values) > 1 else 0
}
def calculate_trend(data):
"""トレンド分析を計算"""
values = []
if isinstance(data[0], dict):
values = [item.get('value', 0) for item in data]
elif isinstance(data[0], list):
values = [item[1] if len(item) > 1 else item[0] for item in data]
else:
values = data
if len(values) < 2:
return {}
# 単純な線形トレンド計算
n = len(values)
x_values = list(range(n))
# 傾き(トレンド)を計算
x_mean = statistics.mean(x_values)
y_mean = statistics.mean(values)
numerator = sum((x_values[i] - x_mean) * (values[i] - y_mean) for i in range(n))
denominator = sum((x_values[i] - x_mean) ** 2 for i in range(n))
slope = numerator / denominator if denominator != 0 else 0
# トレンド方向を判定
if slope > 0.1:
direction = "増加傾向"
elif slope < -0.1:
direction = "減少傾向"
else:
direction = "安定"
# パーセント変化を計算
if values[0] != 0:
pct_change = ((values[-1] - values[0]) / abs(values[0])) * 100
else:
pct_change = 0
return {
"slope": slope,
"direction": direction,
"percentage_change": round(pct_change, 2),
"start_value": values[0],
"end_value": values[-1]
}
def generate_colors(count, darker=False):
"""チャート用の色リストを生成"""
base_colors = [
"#FF6384", "#36A2EB", "#FFCE56", "#4BC0C0",
"#9966FF", "#FF9F40", "#FF6384", "#C9CBCF"
]
if darker:
# 境界線用の濃い色バージョンを生成
base_colors = [
"#FF4069", "#2E8BC0", "#E6B800", "#3AA8A8",
"#7F4FFF", "#FF8C1A", "#FF4069", "#A8AAAD"
]
# 必要に応じて色を繰り返す
colors = []
for i in range(count):
colors.append(base_colors[i % len(base_colors)])
return colors
- Lambda2
- 役割: 文書の形式変換
- 出力: HTML/Markdown/プレーンテキスト
- ❌ しないこと: グラフやチャートの可視化
- ✅ すること: 文書フォーマットの変換のみ
lambda-functions/document_formatter.py
import json
import logging
import re
import html
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""
MCP Tool: document_formatter
ドキュメントを異なるフォーマット間(Markdown、HTML、プレーンテキスト)で変換します
期待される入力スキーマ:
{
"content": "変換する入力コンテンツ",
"input_format": "markdown|html|plain",
"output_format": "markdown|html|plain",
"options": {
"include_toc": true,
"preserve_whitespace": false
}
}
"""
logger.info(f"Received event: {json.dumps(event)}")
try:
content = event.get('content', '')
input_format = event.get('input_format', 'plain').lower()
output_format = event.get('output_format', 'markdown').lower()
options = event.get('options', {})
if not content:
raise ValueError("Content is required")
# Convert content based on input and output formats
if input_format == output_format:
converted_content = content
elif input_format == 'markdown' and output_format == 'html':
converted_content = markdown_to_html(content, options)
elif input_format == 'html' and output_format == 'markdown':
converted_content = html_to_markdown(content, options)
elif input_format == 'html' and output_format == 'plain':
converted_content = html_to_plain(content, options)
elif input_format == 'markdown' and output_format == 'plain':
# Convert markdown to HTML first, then to plain text
html_content = markdown_to_html(content, options)
converted_content = html_to_plain(html_content, options)
elif input_format == 'plain' and output_format == 'markdown':
converted_content = plain_to_markdown(content, options)
elif input_format == 'plain' and output_format == 'html':
converted_content = plain_to_html(content, options)
else:
raise ValueError(f"Conversion from {input_format} to {output_format} not supported")
# Generate document statistics
stats = generate_document_stats(content, converted_content)
return {
'statusCode': 200,
'body': json.dumps({
'original_content': content,
'converted_content': converted_content,
'input_format': input_format,
'output_format': output_format,
'statistics': stats,
'success': True
})
}
except Exception as e:
logger.error(f"Error: {str(e)}")
return {
'statusCode': 400,
'body': json.dumps({
'error': str(e),
'success': False
})
}
def markdown_to_html(content, options):
"""MarkdownをHTMLに変換(正規表現ベース)"""
html_content = content
# 見出しを変換
html_content = re.sub(r'^# (.*$)', r'<h1>\1</h1>', html_content, flags=re.MULTILINE)
html_content = re.sub(r'^## (.*$)', r'<h2>\1</h2>', html_content, flags=re.MULTILINE)
html_content = re.sub(r'^### (.*$)', r'<h3>\1</h3>', html_content, flags=re.MULTILINE)
html_content = re.sub(r'^#### (.*$)', r'<h4>\1</h4>', html_content, flags=re.MULTILINE)
html_content = re.sub(r'^##### (.*$)', r'<h5>\1</h5>', html_content, flags=re.MULTILINE)
html_content = re.sub(r'^###### (.*$)', r'<h6>\1</h6>', html_content, flags=re.MULTILINE)
# 太字・斜体を変換
html_content = re.sub(r'\*\*\*([^*]+)\*\*\*', r'<strong><em>\1</em></strong>', html_content)
html_content = re.sub(r'\*\*([^*]+)\*\*', r'<strong>\1</strong>', html_content)
html_content = re.sub(r'\*([^*]+)\*', r'<em>\1</em>', html_content)
# インラインコードを変換
html_content = re.sub(r'`([^`]+)`', r'<code>\1</code>', html_content)
# コードブロックを変換
html_content = re.sub(r'```([^`]+)```', r'<pre><code>\1</code></pre>', html_content, flags=re.DOTALL)
# リンクを変換
html_content = re.sub(r'\[([^\]]+)\]\(([^)]+)\)', r'<a href="\2">\1</a>', html_content)
# 箇条書きリストを変換
lines = html_content.split('\n')
result_lines = []
in_list = False
for line in lines:
if re.match(r'^[\s]*[-*+]\s+', line):
if not in_list:
result_lines.append('<ul>')
in_list = True
list_item = re.sub(r'^[\s]*[-*+]\s+', '', line)
result_lines.append(f' <li>{list_item}</li>')
else:
if in_list:
result_lines.append('</ul>')
in_list = False
result_lines.append(line)
if in_list:
result_lines.append('</ul>')
html_content = '\n'.join(result_lines)
# 番号付きリストを変換
lines = html_content.split('\n')
result_lines = []
in_list = False
for line in lines:
if re.match(r'^[\s]*\d+\.\s+', line):
if not in_list:
result_lines.append('<ol>')
in_list = True
list_item = re.sub(r'^[\s]*\d+\.\s+', '', line)
result_lines.append(f' <li>{list_item}</li>')
else:
if in_list:
result_lines.append('</ol>')
in_list = False
result_lines.append(line)
if in_list:
result_lines.append('</ol>')
html_content = '\n'.join(result_lines)
# 段落を変換
paragraphs = html_content.split('\n\n')
wrapped_paragraphs = []
for para in paragraphs:
para = para.strip()
if para and not para.startswith('<'):
wrapped_paragraphs.append(f'<p>{para}</p>')
else:
wrapped_paragraphs.append(para)
return '\n\n'.join(wrapped_paragraphs)
def html_to_markdown(content, options):
"""HTMLをMarkdownに変換(正規表現ベース)"""
md_content = content
# 見出しを変換
md_content = re.sub(r'<h1[^>]*>(.*?)</h1>', r'# \1', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<h2[^>]*>(.*?)</h2>', r'## \1', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<h3[^>]*>(.*?)</h3>', r'### \1', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<h4[^>]*>(.*?)</h4>', r'#### \1', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<h5[^>]*>(.*?)</h5>', r'##### \1', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<h6[^>]*>(.*?)</h6>', r'###### \1', md_content, flags=re.IGNORECASE | re.DOTALL)
# 太字・斜体を変換
md_content = re.sub(r'<strong[^>]*>(.*?)</strong>', r'**\1**', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<b[^>]*>(.*?)</b>', r'**\1**', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<em[^>]*>(.*?)</em>', r'*\1*', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<i[^>]*>(.*?)</i>', r'*\1*', md_content, flags=re.IGNORECASE | re.DOTALL)
# コードを変換
md_content = re.sub(r'<code[^>]*>(.*?)</code>', r'`\1`', md_content, flags=re.IGNORECASE | re.DOTALL)
md_content = re.sub(r'<pre[^>]*><code[^>]*>(.*?)</code></pre>', r'```\n\1\n```', md_content, flags=re.IGNORECASE | re.DOTALL)
# リンクを変換
md_content = re.sub(r'<a[^>]+href=["\']([^"\']+)["\'][^>]*>(.*?)</a>', r'[\2](\1)', md_content, flags=re.IGNORECASE | re.DOTALL)
# リストを変換
md_content = re.sub(r'<ul[^>]*>', '', md_content, flags=re.IGNORECASE)
md_content = re.sub(r'</ul>', '', md_content, flags=re.IGNORECASE)
md_content = re.sub(r'<ol[^>]*>', '', md_content, flags=re.IGNORECASE)
md_content = re.sub(r'</ol>', '', md_content, flags=re.IGNORECASE)
md_content = re.sub(r'<li[^>]*>(.*?)</li>', r'- \1', md_content, flags=re.IGNORECASE | re.DOTALL)
# 段落を変換
md_content = re.sub(r'<p[^>]*>(.*?)</p>', r'\1\n', md_content, flags=re.IGNORECASE | re.DOTALL)
# その他のHTMLタグを除去
md_content = re.sub(r'<[^>]+>', '', md_content)
# HTMLエンティティをデコード
md_content = html.unescape(md_content)
# 空白を整理
md_content = re.sub(r'\n\s*\n\s*\n', '\n\n', md_content)
return md_content.strip()
def html_to_plain(content, options):
"""HTMLをプレーンテキストに変換"""
# HTMLタグを除去
text = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.IGNORECASE | re.DOTALL)
text = re.sub(r'<style[^>]*>.*?</style>', '', text, flags=re.IGNORECASE | re.DOTALL)
# 見出しは大文字に
text = re.sub(r'<h[1-6][^>]*>(.*?)</h[1-6]>', lambda m: m.group(1).upper() + '\n', text, flags=re.IGNORECASE | re.DOTALL)
# リストを変換
text = re.sub(r'<li[^>]*>(.*?)</li>', r'- \1\n', text, flags=re.IGNORECASE | re.DOTALL)
text = re.sub(r'<[uo]l[^>]*>', '', text, flags=re.IGNORECASE)
text = re.sub(r'</[uo]l>', '', text, flags=re.IGNORECASE)
# 段落・改行を変換
text = re.sub(r'<p[^>]*>(.*?)</p>', r'\1\n\n', text, flags=re.IGNORECASE | re.DOTALL)
text = re.sub(r'<br[^>]*/?>', '\n', text, flags=re.IGNORECASE)
# 残りのHTMLタグを除去
text = re.sub(r'<[^>]+>', '', text)
# HTMLエンティティをデコード
text = html.unescape(text)
# 空白を整理
if not options.get('preserve_whitespace', False):
text = re.sub(r'\n\s*\n\s*\n', '\n\n', text)
text = re.sub(r' +', ' ', text)
return text.strip()
def plain_to_markdown(content, options):
"""プレーンテキストを簡易的にMarkdownへ変換"""
lines = content.split('\n')
result = []
for line in lines:
line = line.strip()
if not line:
result.append('')
continue
# 簡易的なMarkdown変換のヒューリスティクス
if line.isupper() and len(line.split()) <= 6:
# 全て大文字かつ短い行は見出しに
result.append(f'# {line.title()}')
elif line.endswith(':') and len(line.split()) <= 8:
# コロンで終わる短い行はサブヘッダーに
result.append(f'## {line[:-1]}')
elif line.startswith('- ') or line.startswith('* ') or line.startswith('+ '):
# 既にリスト項目
result.append(line)
elif re.match(r'^\d+\.?\s', line):
# 番号付き項目
result.append(line)
else:
# 通常の段落
result.append(line)
return '\n'.join(result)
def plain_to_html(content, options):
"""プレーンテキストをHTMLに変換"""
# HTML文字をエスケープ
escaped = html.escape(content)
# 改行をHTMLの改行または段落に変換
if options.get('preserve_whitespace', False):
escaped = escaped.replace('\n', '<br>\n')
else:
# ダブル改行を段落に変換
paragraphs = escaped.split('\n\n')
escaped = '</p>\n<p>'.join(paragraphs)
escaped = f'<p>{escaped}</p>'
return escaped
def generate_document_stats(original, converted):
"""ドキュメントの統計情報を生成"""
return {
'original_length': len(original),
'converted_length': len(converted),
'original_word_count': len(original.split()),
'converted_word_count': len(converted.split()),
'original_line_count': len(original.split('\n')),
'converted_line_count': len(converted.split('\n'))
}
SAM でサクッと 2 つの Lambda をデプロイしてしまいます。
template.yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: Document Creation MCP Tools - Lambda functions for efficient document creation and processing
Globals:
Function:
Timeout: 60
MemorySize: 512
Runtime: python3.11
Tags:
MCPTool: "true"
Environment: "development"
Purpose: "document-creation"
Parameters:
Environment:
Type: String
Default: dev
Description: Environment name
Resources:
# Document Formatter Lambda Function
MCPDocumentFormatterFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "mcp-document-formatter-${Environment}"
CodeUri: lambda-functions/
Handler: document_formatter.lambda_handler
Description: "MCP Tool: Convert documents between Markdown, HTML, and Plain Text formats"
Tags:
MCPFunction: "document-formatter"
MCPSchema: "document-formatter-schema"
# Chart Data Processor Lambda Function
MCPChartDataProcessorFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "mcp-chart-data-processor-${Environment}"
CodeUri: lambda-functions/
Handler: chart_data_processor.lambda_handler
Description: "MCP Tool: Process data and generate chart-ready JSON with statistics and trend analysis"
Tags:
MCPFunction: "chart-data-processor"
MCPSchema: "chart-data-processor-schema"
Outputs:
FunctionPrefix:
Description: "Function prefix for MCP configuration"
Value: "mcp-"
Export:
Name: !Sub "${AWS::StackName}-FunctionPrefix"
FunctionList:
Description: "Comma-separated list of function names for MCP configuration"
Value: !Sub "${MCPDocumentFormatterFunction},${MCPChartDataProcessorFunction}"
Export:
Name: !Sub "${AWS::StackName}-FunctionList"
クライアント側の設定
クライアント側の権限
この時、クライアントからは必要最小権限の法則にのっとり Lambda を呼び出す権限だけあれば良いので、次のような権限だけ持たせてあげれば良いと言うことになります。
今回は Lambda 側で何か API キーが必要だったり、他の AWS サービスを呼び出したりするようなことはありませんが、こういったものをクライアント側ではなく、Lambda 側に持たせてあげれば良いと言うことになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"lambda:InvokeFunction"
],
"Resource": [
"arn:aws:lambda:ap-northeast-1:123456789012:function:mcp-document-formatter",
"arn:aws:lambda:ap-northeast-1:123456789012:function:mcp-chart-data-processor",
],
"Effect": "Allow"
}
]
}
MCP サーバーの構成
現在色々なクラアントを試している最中であり今回 クライアントには claude_desktop を利用してみます。
ドキュメント を参考に claude_desktop_config.json に設定します。今回は "FUNCTION_PREFIX": "mcp-" の Lambda 関数のものに指定してあげています。
{
"mcpServers": {
"awslabs.lambda-tool-mcp-server": {
"command": "uvx",
"args": ["awslabs.lambda-tool-mcp-server@latest"],
"env": {
"AWS_PROFILE": "<your-aws-profile>",
"AWS_REGION": "ap-northeast-1",
"FUNCTION_PREFIX": "mcp-"
}
}
}
}
下記のような形で「running」になっていれば OK です。
動作確認
同じ質問を投げ、
MCP を利用した場合
MCP を利用しない場合
との結果を比較してみたいと思います。
モデルは、Claude 4 Sonet です。
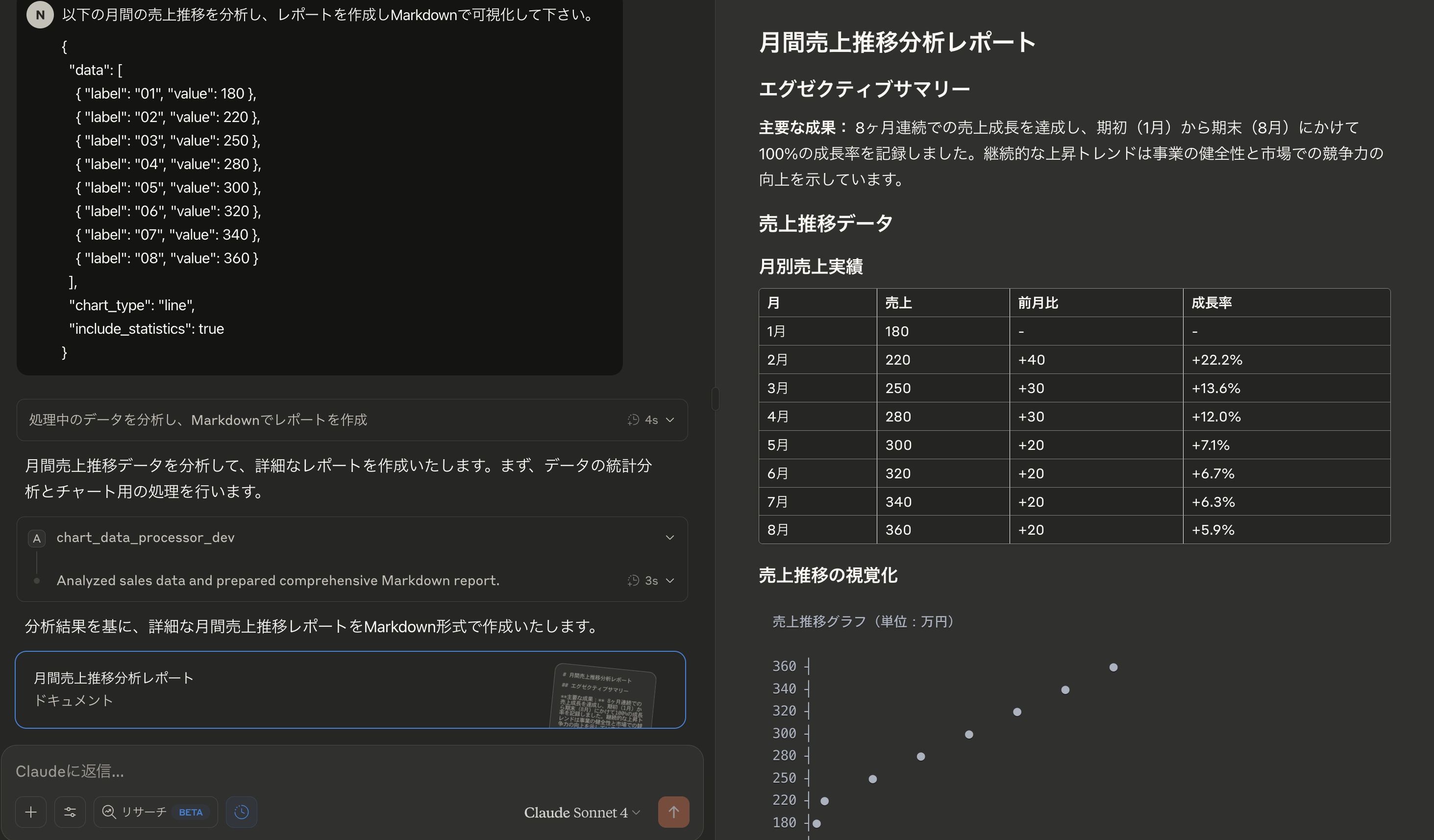
MCP を利用した場合
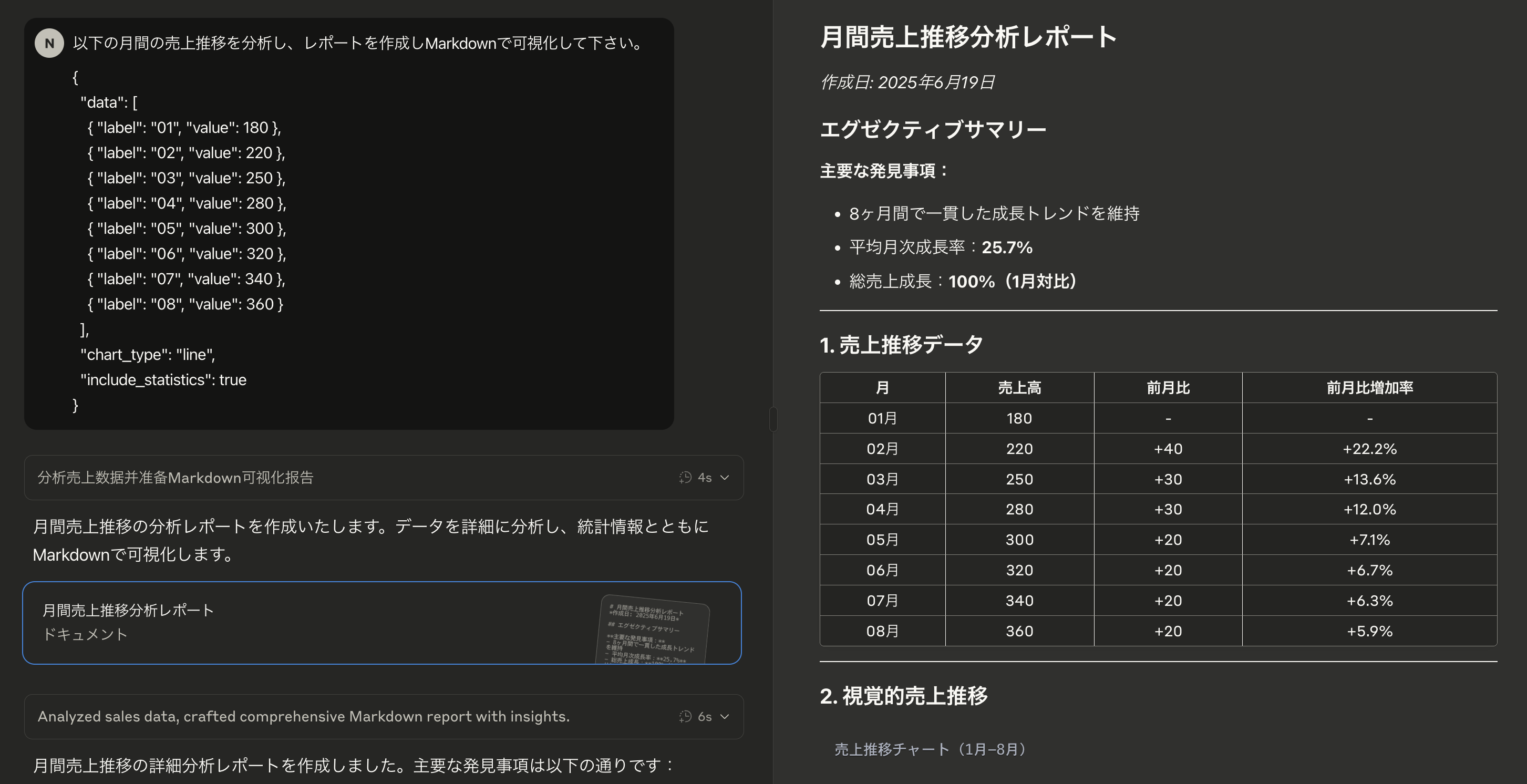
chart_data_processor が使われます。
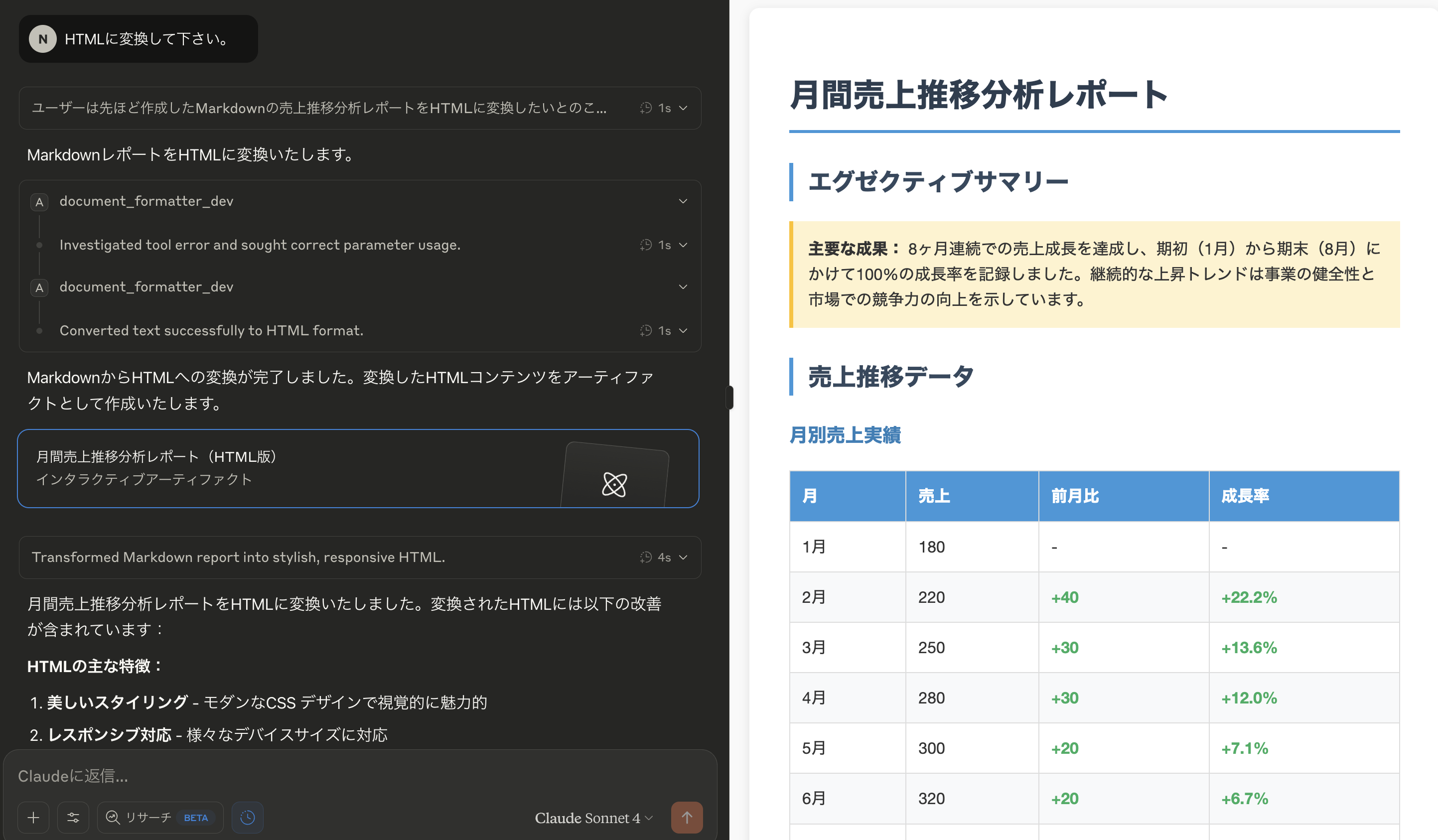
document_formatter.py が使われます。
MCP を利用しない場合
ツールを無効化します。
所感
🤔 問題提起
chart-data-processor-dev や document-formatter-dev を使った場合と使わなかった場合で回答精度が変わらない?
利用するモデルが賢ければ、必ずしもツールを使う必要はない?
📊 実際の比較検証
統計計算の場合
| 手法 | 平均値 | 標準偏差 | 精度 |
|---|---|---|---|
| ツール使用 | 281.25 | 61.51 | 高精度 |
| 手動計算 | 281.25 | 61.51 | 同等 |
結論: 基本的な統計計算では差はほとんどない
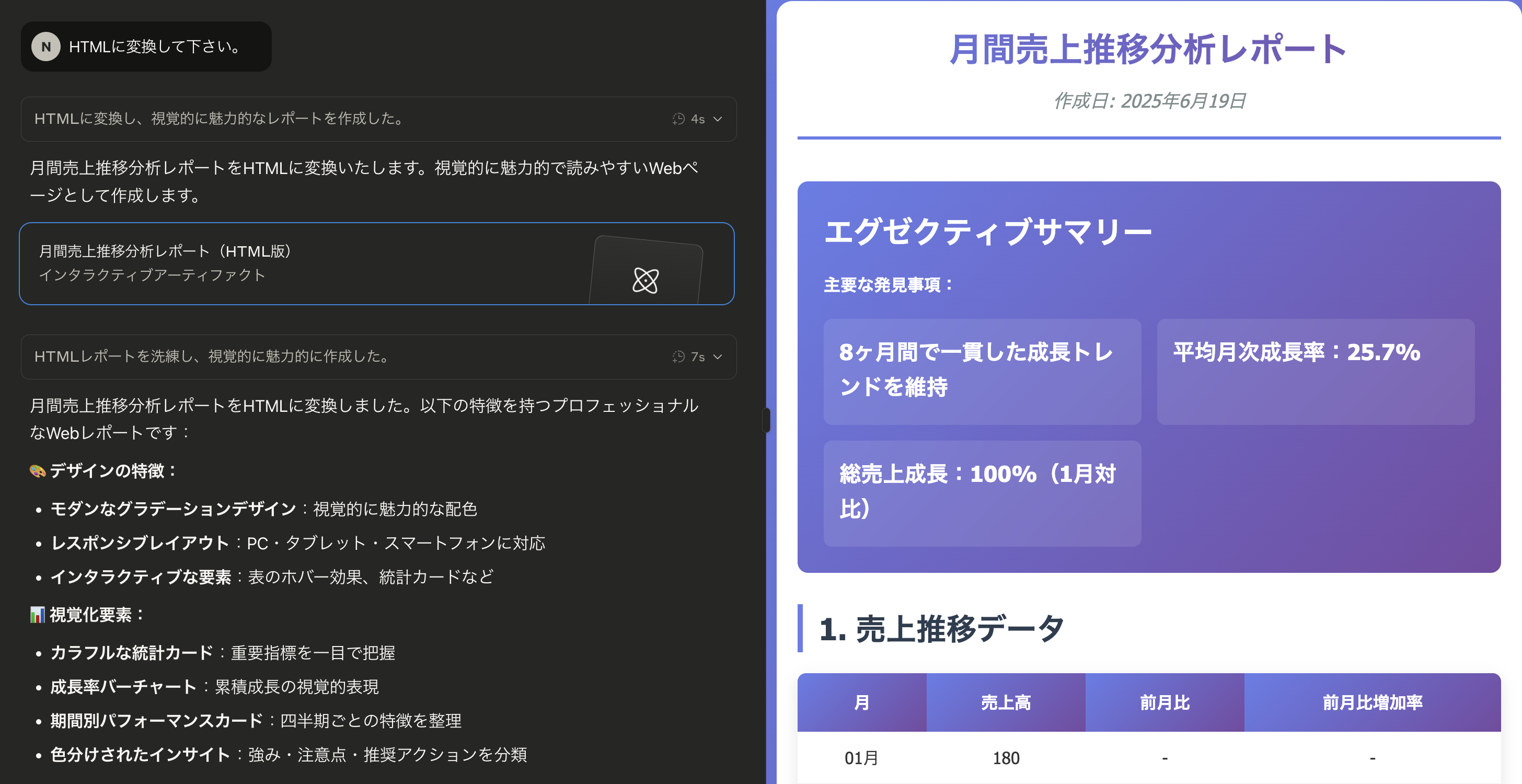
フォーマット変換の場合
| 手法 | 構造化 | 品質 | 効率 |
|---|---|---|---|
| ツール使用 | 自動 | 高品質 | 高効率 |
| 手動変換 | 手動 | 同等品質 | 中効率 |
結論: 小規模なフォーマット変換では大きな差はない
💡 ツール使用の真の価値
1. 検証可能性と信頼性
モデル単体の場合:
• "私が計算しました"
• 主観的信頼性
• 検証が困難
ツール使用の場合:
• "専門ツールが検証済み"
• 客観的信頼性
• 結果の再現性
2. スケーラビリティの違い
| データ規模 | モデル単体 | ツール使用 | 優位性 |
|---|---|---|---|
| 小規模(〜100点) | ◎ | ◎ | 互角 |
| 中規模(〜1,000点) | ○ | ◎ | ツール優位 |
| 大規模(〜10,000点) | △ | ◎ | ツール圧倒的 |
| 超大規模(10万点〜) | × | ◎ | ツール必須 |
3. 専門的な高度分析
基本統計:
モデル単体 = ツール(同等レベル)
高度分析:
モデル単体 < ツール(時系列、機械学習、最適化など)
🎯 使い分けの指針
シナリオ別推奨アプローチ
| シナリオ | 推奨手法 | 理由 | 具体例 |
|---|---|---|---|
| 簡単な分析 | モデル単体 | 効率的、迅速 | 8点の売上データ分析 |
| 重要な意思決定 | ツール使用 | 検証可能性重視 | 投資判断用レポート |
| 大量データ | ツール必須 | パフォーマンス | 数万件の顧客データ |
| 監査が必要 | ツール使用 | 証跡の記録 | 規制対応レポート |
| 探索的分析 | モデル単体 | 柔軟性重視 | 初期データ調査 |
| 定期レポート | ツール使用 | 自動化・標準化 | 月次売上分析 |
判断フローチャート
データ分析の必要性が発生
↓
データ規模は?
├─ 小規模(〜100点) → モデル単体でOK
└─ 大規模(100点〜) → ツール使用を検討
↓
分析の重要度は?
├─ 低い(探索的) → モデル単体
└─ 高い(意思決定用) → ツール使用
↓
検証可能性は必要?
├─ 不要 → モデル単体
└─ 必要 → ツール使用
📈 具体的な差が出るケース
モデル単体が有利なケース
- 迅速な概算分析
- 創造的なデータ解釈
- 文脈を考慮した分析
- 柔軟なアプローチ
ツールが有利なケース
- 大量データの処理
- 複雑な統計モデル
- リアルタイム分析
- 監査可能な結果
- 標準化された手法
🔍 結論
率直な評価
今回のような基本的な分析(8点の売上データ)では、Claude Sonnet 4のような高性能モデルなら、ツールを使わなくても同等の結果を出せる。
しかし、ツールの価値は
- 計算の客観性と検証可能性
- より複雂な分析への拡張性
- 大規模データでの性能差
- 業務での信頼性要求への対応
- 結果の再現性と標準化
最終的な判断基準
| 要素 | 重要度 | 考慮点 |
|---|---|---|
| データ規模 | 高 | 100点を超えるとツールが有利 |
| 分析の複雑さ | 高 | 基本統計以上ならツール検討 |
| 結果の重要性 | 中 | 意思決定用ならツール推奨 |
| 時間的制約 | 中 | 迅速性重視ならモデル単体 |
| 検証必要性 | 低 | 監査要件があればツール |
💭 示唆
「ツールを使うべきか?」ではなく「どの場面でツールが真価を発揮するか?」 が重要な問いである。
高性能なAIモデルの登場により、多くの基本的なタスクでツールの優位性は薄れている。
しかし、スケール、複雑性、信頼性が要求される場面では、依然としてツールの専門性が重要な価値を持つ。
つまり、適材適所の判断力こそが、効率的なデータ分析における鍵となる。