Linuxカーネルパラメータのチューニング&設計
0.目的
【カーネルパラメータのチューニング】を修得する目的は、サーバの特性を理解し、それぞれに合ったカーネルパラメータのチューニングすることでリソースの有効活用をできるようになることを目的とし、私個人の経験を元にした見解を以下の記事に掲載します。
1.最初に
サーバには、それぞれ必要なリソース特性があり、それに合わせたカーネルパラメータのチューニングが必要となります。
世の中の流れはオンプレよりクラウドに移行してはいるので、カーネルパラメータのチューニングよりスケールアップなりスケールアウトするなりの対応をすべきなのでしょう。
ですが、カーネルパラメータのチューニングを知らないとどちらを選択すべきかも理解しずらいと思いますので軽率には出来きません。(待ち行列理論もしらないといけませんが)
また、最近のLinuxはデフォルト値が大きくなっているので、検討したが結局デフォルトになることが多いですが、意味は知っている必要があるので残しておきます。
まずは、アプリケーション(業務)、運用を実務に近い実行状態にしサーバの状態を確認。
状況に合わせたカーネルパラメータをチューニングしていきます。
そのためのフロー図を示し、判断するための指標を参考に残しておきます。
サーバ、アプリケーションの特性をじゅうぶんに理解し、設計段階でカーネルパラメータをチューニングをすることも重要となります。
また、カーネルパラメータのチューニング結果は、きちんと引き継がれないことが多く副作用により、後にトラブルが発生した場合、原因判明まで時間を要することが多いようなので、チューニングする際は、根拠・評価結果・変更後の効果査定結果(パフォーマンスレポート)など,詳細なレポートを残すようにしてください。
2.リソースボトルネックの確認フロー
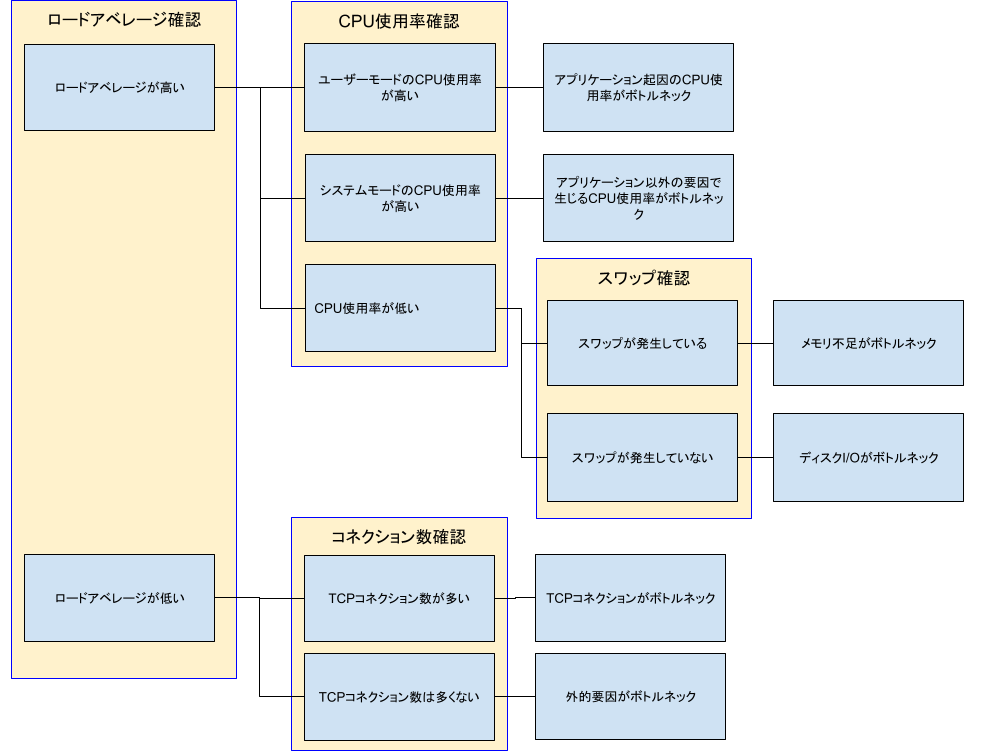
2.1.ロードアベレージの確認
カーネルチューニングのとっかかりとして、まずはロードアベレージの確認をします。
ロードアベレージはtopコマンドのload averageなどで確認できます。
ロードアベレージが高いかの判断の目安は、オンラインサーバの場合はCPU1コアあたり1以上あると高いと判断できます。
CPUのコア数はgrep cpu.cores /proc/cpuinfoで確認ができます。
ただし、バッチ処理を実行するサーバや運用サーバは、設計段階でチューニング(DiskI/Oやメモリ)は必要ですが、各処理時間が要件を満たすかどうかにかかってますので、以降カーネルパラメータのチューニングに関しては記載しません。
2.2. ロードアベレージが高い場合
2.2.1.CPU使用率の確認
ロードアベレージが高い場合はCPU使用率を確認する必要があります。
以上の状態は、vmstat、sarコマンドなどで確認できます。
・ユーザーモードCPU使用率の高騰
vmstatでcpu usが70%以上が続く場合、CPU使用率高騰と判断できます。
アプリケーション、ミドルウェア起因のCPU使用率がボトルネックのため、ミドルウェアの設定値の見直しやアプリケーションの処理方法の見直しが必要です。
また、CPUの増設、処理を分散処理できなければスケールアップ、分散処理可能であればスケールアウトしてください。
・システムモードCPU使用率の高騰
vmstatでcpu syが70%以上が続く場合、CPU使用率高騰と判断できます。
アプリケーション要因以外のCPU使用率がボトルネックだが、アプリケーションで fork,vfork,clone などのシステムコールが多発するようなプログラムが原因もあるため注意が必要です。(そもそもシステム起因でCPUが高騰する場合はパッチ適用などの対応が必要)
fork数は、vmstatの-fオプションで確認することができます。
fork関数を多用しているアプリケーションやミドルウェアを見直ししてください。
・CPU使用率が低い
CPU使用率が低い場合は、次のスワップ確認を実施してください。
2.2.2.スワップの確認
スワップの使用状況は、freeコマンドもしくはvmstatコマンドで確認できます。
また、各プロセスごとのスワップ使用状況は、 grep VmSwap /proc/*/status | sort -nr -k 2 | head -10で確認できます。
・メモリ使用率高騰
swapが使用されておりvmstatでfreeが極端に低い場合、メモリ使用率高騰と判断できます。メモリ使用率70%以上が続く場合は、メモリ使用率高騰と判断できます。
メモリの場合は、psコマンドやtopコマンドでメモリを多く使用しているプロセスを特定してください。
アプリケーションやDBなどのキャッシュ、バッファサイズやJavaのヒープサイズ、Webサーバのようにプロセスを複数起動する数の見直しを実施する必要があります。
ただし、見直しした結果削れるところがない場合は、メモリの増設、分散処理ができなければスケールアップ、分散処理可能であればスケールアウトを検討してください。
また、アプリケーション起因のメモリ使用率がボトルネックのため、カーネルパラメータでのチューニングも必要となります。
・I/O待ち状態
swapが使用されてなくbo(block out)が発生しており、cpu us(user)およびcpu sy(system)高騰もせず、cpu wa(cpu wait)が高騰している場合、I/O待ち状態と判断できます。
以下の例のようにcpu wa(cpu wait)が、0->82->96->94->52->0と推移しているためI/O待ち状態と判断できます。
cpu wa(cpu wait)が70%以上が続くことがI/O待ち状態が高い指標と言えます。
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 1004 283272 51228 442416 0 0 0 0 59 48 0 0 100 0 0
0 1 1004 281440 51232 442480 0 0 80 137216 438 419 0 5 13 82 0
0 1 1004 281440 51240 442516 0 0 4 153600 446 446 0 4 0 96 0
0 1 1004 281440 51256 442568 0 0 16 153600 480 458 0 6 0 94 0
0 0 1004 282404 51256 442772 0 0 232 79872 270 272 0 2 46 52 0
0 0 1004 282404 51256 442796 0 0 0 0 56 42 0 0 100 0 0
カーネルパラメータでのDiskに関連するチューニングも必要となります。
また、以下対策も検討もしてください。
・アプリケーションの改善でI/O頻度を軽減する。
・データの分散やキャッシュサーバの導入。
・メモリ増設でキャッシュ領域を拡大させられる場合はメモリを増設する。
・I/Oスケジューラの変更を検討してください。
2.3. ロードアベレージが低い場合
2.3.1. ロードアベレージが低く、ターンアラウンドタイムが遅い場合
ロードアベレージが3以下と低く、ミドルウェアのターンアラウンドタイムが遅い場合は、TCPコネクション数が足りないため、ミドルウェアの接続数設定やConnectionに関連するカーネルパラメータでのチューニングも必要となります。
ただし、ポートは番号65535個しかないので、数万個のTCPコネクションが貼られている場合は、スケールアウトのような対応をとる必要があります。
2.3.2. ロードアベレージが低く、ターンアラウンドタイムが遅くない場合
ロードアベレージが3以下と低く、ミドルウェアのターンアラウンドタイムが遅くない場合は、接続元の接続数やネットワーク帯域の問題、もしくは自サーバのネットワークがボトルネックになっている可能性があるためNetworkに関連するカーネルパラメータでのチューニングも必要となります。
3.カーネルパラメータのチューニング
「2.リソースボトルネックの確認フロー」で確認した結果から各ボトルネックで必要なカーネルパラメータをチューニングしてください。また、設定後にも確認フローで想定通りにリソースが使われていることを確認してください。
場合によっては、カーネルパラメータをチューニングすることで他リソースが圧迫することもあるので注意してください。
3.1. カーネルパラメータとボトルネック
| パラメータ | 説明 | CPU | Memory | Disk | Network | Connection |
|---|---|---|---|---|---|---|
| msgmax | メッセージの最大サイズ | 〇 | ||||
| msgmnb | 1つのメッセージキューに保持できるメッセージの最大値 | 〇 | ||||
| msgmni | メッセージキューIDの最大値 | 〇 | ||||
| net.ipv4.tcp_wmem | データ最大送信バッファ サイズ | 〇 | ||||
| net.ipv4.tcp_rmem | データ受信バッファ サイズ | 〇 | ||||
| net.core.wmem_max | TCPとUDPの送信バッファのデフォルトサイズと最大サイズ | 〇 | ||||
| net.core.rmem_max | TCPとUDPの受信バッファのデフォルトサイズと最大サイズ | 〇 | ||||
| net.core.somaxconn | backlog値のhard limit | 〇 | ||||
| net.core.netdev_max_backlog | NIC に対する受信パケットの最大キューイング数 | 〇 | ||||
| net.ipv4.tcp_max_syn_backlog | ソケット当たりのSYNを受け付けてACKを受け取っていない状態のコネクションの保持可能数 | 〇 | ||||
| kernel.shmmax | 共有メモリの最大サイズ。サーバーの搭載メモリに合わせて変更 | 〇 | ||||
| kernel.shmall | システム全体の共有メモリ・ページの最大数 | 〇 | ||||
| kernel.sem | セマフォ設定値 | 〇 | ||||
| vm.swappiness | 実メモリがある状態でスワップを使うかどうか | 〇 | ||||
| vm.max_map_count | mmapやmalloc時にメモリを仮想空間にマッピングできる最大ページ数 | 〇 | ||||
| vm.overcommit_memory | 実メモリ以上にメモリをプロセスに割り当てるオーバーコミットを許すかどうか | 〇 | ||||
| kernel.threads-max | システム全体のプロセス数の上限 | 〇 | ||||
| net.ipv4.tcp_tw_reuse | TIME_WAITの長さ変更の有効化 | 〇 | 〇 | |||
| net.ipv4.tcp_fin_timeout | TIME_WAITの長さ | 〇 | 〇 | |||
| net.core.somaxconn | TCPソケットが受け付けた接続要求を格納するキューの最大長 | 〇 | ||||
| net.ipv4.ip_local_port_range | TCP/IPの送信用ポート範囲の変更 | 〇 | ||||
| fs.file-max | ファイルシステムでのオープンファイルの上限 | 〇 | ◯ | |||
| fs.nr_open | ユーザーモード環境で開くことができる最大ファイル数 | 〇 | 〇 | |||
| kernel.threads-max | カーネルが一度に使用できるスレッドの最大数 | 〇 | ||||
| net.core.netdev_max_backlog | ネットワークデバイス別にカーネルが処理できるように貯めておくqueueのサイズ | 〇 | 〇 | |||
| net.netfilter.nf_conntrack_max | netfilterでの最大同時コネクション数 | 〇 | 〇 | |||
| net.ipv4.tcp_syn_retries | tcpのSYNを送信するリトライ回数 | 〇 | ||||
| fs.aio-max-nr | システム全体の予約可能な I/O 記述子の総数 | 〇 |
4.設計フェーズでのカーネルパラメータチューニング
サーバに役割および乗せるミドルウェアにより想定されるボトルネックにより設計フェーズでカーネルパラメータを設定してください。
以下の各ボトルネックになりうるサーバに該当する場合は、設計段階でカーネルパラメータを設計してください。
4.1.ボトルネック Network
FTP,HULFTなどのファイル転送を実行するサーバなど、ボトルネックがNetworkとなる可能性があるサーバの場合は、設計フェーズで 『3.1. カーネルパラメータとボトルネック』のNetworkをチューニングしてください。
4.2.ボトルネック Memory
Javaなどのメモリを必要とするAPサーバやバッファやキャッシュを必要とするDBサーバなど、ボトルネックがMemoryとなる可能性があるサーバの場合は、設計フェーズで 『3.1. カーネルパラメータとボトルネック』のMemoryをチューニングしてください。
4.2.ボトルネック Connection
Webサーバ、OLTPサーバ、アプリケーションサーバ、LDAPサーバなどの接続数を必要とするサーバなど、ボトルネックがConnectionとなる可能性があるサーバの場合は、設計フェーズで 『3.1. カーネルパラメータとボトルネック』のConnectionをチューニングしてください。
4.4.ボトルネック Disk
DiskI/Oを必要とするバッチ処理を実行するサーバ、DBサーバ、ファイル転送するサーバなど、ボトルネックがDiskとなる可能性があるサーバの場合は、設計フェーズで 『3.1. カーネルパラメータとボトルネック』のDiskをチューニングしてください。
最後に
カーネルパラメータのチューニングは、経験がモノを言うので一概にこれって言うのは難しいですが、チューニングした後に性能試験にて評価すれば結果は分かります。(効果が殆どない場合もあります)
場合によっては、アプリケーションの改修が必要であったり、スケールアップ・スケールアウトする場合もあるでしょう。ですが、このリソース分析なくして必要なリソースは語れないので是非トライしてください。
おすすめ記事
性能分析
ネットワーク帯域チューニング