本記事は、Kaggleの「Store Sales - Time Series Forecasting」に取り組んだ内容をまとめたものです。
コンペ名 :Store Sales - Time Series Forecasting
URL :[https://www.kaggle.com/competitions/store-sales-time-series-forecasting]
タスクの種類:回帰予測(Regression)
目的変数 :Sales(売り上げ)
評価指標 :Root Mean Squared Error(RMSE)
このコンペは初心者向けに設計されており、特徴量データ(石油価格・店舗情報・休日イベント情報・取引情報)を使用して売り上げを数値予測するというテーマです。
機械学習のことについて書籍で勉強していましたが、実践形式でアウトプットするために、Kaggleに参加しました。
またSQLの練習の為に、複数の生データの結合や、グラフで用いる為のデータをSQLで作成しました。
このコンペを通じて以下のようなことを学ぶことを目的に取り組みました。
- EDA(探索的データ分析)の実践
- 特徴量エンジニアリングの考え方
- モデル比較(LightGBM / CatBoost / XGBoost)
- パラメータチューニング(Optuna)
全体を通じて・・・
1.EDA編(データ理解・特徴量設計)→一部SQLで作成
2.可視化編(分布や相関の可視化)→グラフ作成時に使用するデータはSQLで作成
3.モデル編(モデル構築〜精度改善)
データの中身
train :訓練データ
store_nbr :店舗番号
family : 商品分類
onpromotion : プロモーション数
transactions :その日、その店舗で発行されたレシートの数(≒ 来客数),総取引数
locale_name :地域名
description :イベントや祝日の名称
transferred :祝日が別日に移動したか
dcoilwtico :石油価格
まずEDA編として、データの中身を確認し、どんな特徴量を作ったかを中心に紹介していきます。
1. データの読み込み・結合
SQLでデータの読み込みを行い、各データを結合して一つの解析用データセットを作成しました。
/*データの読み込み*/
CREATE TABLE "train" (
"id" INTEGER,
"date" TEXT,
"store_nbr" INTEGER,
"family" TEXT,
"sales" REAL,
"onpromotion" INTEGER
)
CREATE TABLE "test" (
"id" INTEGER,
"date" TEXT,
"store_nbr" INTEGER,
"family" TEXT,
"onpromotion" INTEGER
)
CREATE TABLE "event" (
"date" TEXT,
"type" TEXT,
"locale" TEXT,
"locale_name" TEXT,
"description" TEXT,
"transferred" INTEGER
)
CREATE TABLE "oil" (
"date" TEXT,
"dcoilwtico" REAL,
"dcoilwtico1" REAL
)
CREATE TABLE "stores" (
"store_nbr" INTEGER,
"city" TEXT,
"state" TEXT,
"type" TEXT,
"cluster" INTEGER
)
CREATE TABLE "transactions" (
"date" TEXT,
"store_nbr" INTEGER,
"transactions" INTEGER
)
/*結合キーを指定してデータの結合*/
create table data1 as
SELECT TR.* , T.transactions,S.city,S.state,S.type,S.cluster,O.dcoilwtico
FROM train as TR
LEFT JOIN transactions as T
ON TR.date = T.date and TR.store_nbr = T.store_nbr
LEFT JOIN stores as S
ON T.store_nbr = S.store_nbr
LEFT JOIN oil as O
ON T.date = O.date
create table data2 as
SELECT D.* , local.date as local_date , local.type as local_type , local.locale_name as local_name , local.description as local_description ,
Regional.date as Regional_date , Regional.type as Regional_type , Regional.locale_name as Regional_name , Regional.description as Regional_description ,
National.date as National_date , National.type as National_type , National.locale_name as National_name , National.description as National_description
FROM data1 as D
LEFT JOIN ( SELECT *
FROM event
WHERE locale = 'Local')
as local
ON D.date = local.date and D.city = local.locale_name
LEFT JOIN (SELECT *
FROM event
where locale = 'Regional'
)
as Regional
ON D.date = Regional.date and D.city = Regional.locale_name
LEFT JOIN (SELECT *
FROM event
where locale = 'National'
)
as National
ON D.date = National.date and D.city = National.locale_name
create table data3 as
SELECT * , EXTRACT (YEAR FROM date::DATE) as year ,
EXTRACT (MONTH FROM date::DATE) as month,
EXTRACT (DOW FROM date::DATE) as weekday_num,
TO_CHAR(date::DATE, 'Dy') AS weekday_str
FROM data2
/*testデータも上記と同様のことを行う*/
create table test1 as
SELECT TE.* , S.city,S.state,S.type,S.cluster,O.dcoilwtico
FROM test as TE
-- LEFT JOIN transactions as T
-- ON TR.date = T.date and TR.store_nbr = T.store_nbr
LEFT JOIN stores as S
ON TE.store_nbr = S.store_nbr
LEFT JOIN oil as O
ON TE.date = O.date
create table test2 as
SELECT D.* , local.date as local_date , local.type as local_type , local.locale_name as local_name , local.description as local_description ,
Regional.date as Regional_date , Regional.type as Regional_type , Regional.locale_name as Regional_name , Regional.description as Regional_description ,
National.date as National_date , National.type as National_type , National.locale_name as National_name , National.description as National_description
FROM test1 as D
LEFT JOIN ( SELECT *
FROM event
WHERE locale = 'Local')
as local
ON D.date = local.date and D.city = local.locale_name
LEFT JOIN (SELECT *
FROM event
where locale = 'Regional'
)
as Regional
ON D.date = Regional.date and D.city = Regional.locale_name
LEFT JOIN (SELECT *
FROM event
where locale = 'National'
)
as National
ON D.date = National.date and D.city = National.locale_name
create table test3 as
SELECT * , EXTRACT (YEAR FROM date::DATE) as year ,
EXTRACT (MONTH FROM date::DATE) as month,
EXTRACT (DOW FROM date::DATE) as weekday_num,
TO_CHAR(date::DATE, 'Dy') AS weekday_str
FROM test2
上記のようにSQLでtrain・testデータと他の生データの結合後にエクセルファイルとして出力しました。
以下からはPythonでの処理になります。
import numpy as np
import pandas as pd
# import sklearn
import matplotlib as mpl
from datetime import datetime as dt
import matplotlib.pyplot as plt
train_df= pd.read_csv(r'パス名')
test_df= pd.read_csv(r'パス名')
test_transactions= pd.read_csv(r'パス名')
trainデータとtestデータで同じ前処理をしております。
・日付型に変換
・石油価格の欠損補完(前日データで補完・1行目が欠損の場合は2行目の値で補完する)
・カテゴリ変数に欠損があったら "MISSING" に置き換える
・テストデータにトランザクション情報を追加
for data in [train_df , test_df]:
#data_oilの前処理
data['date_n'] = pd.to_datetime(data['date'] , format = '%Y-%m-%d')
#重複の確認
duplicates = data.duplicated()
#dcoilwtico(石油価格)に欠損値がある
#これを補うために前日のデータを使用して補完する
data['dcoilwtico1'] = data['dcoilwtico'].fillna(method = 'ffill')
#1行目が欠損値の場合は2行目のデータで補完する
#data_storesの前処理
cat_cols = ['city' , 'state' , 'type', 'family','local_type','local_name','local_description','regional_type', 'regional_name' , 'regional_description' , 'national_type' , 'national_name' ,'national_description']
for c in cat_cols :
data[c] = data[c].fillna('MISSING')
data[cat_cols] = data[cat_cols].astype('category')
# data.drop(['city', 'state', 'type', 'family'], axis=1, inplace=True)
if pd.isna(data['dcoilwtico1'].iloc[0]):
data['dcoilwtico1'].iloc[0] = data['dcoilwtico1'].iloc[1]
data.drop(['dcoilwtico', 'date'], axis=1, inplace=True)
test_df1 = pd.merge (test_df,test_transactions,on = ["weekday_str", "store_nbr"] , how = "left").rename(columns = { "avg_transactions" : "transactions" })
数値・文字変数の抽出
#数値変数のみ抽出
numeric_columns = train_df.select_dtypes(include = ["number"]).columns.sort_values(ascending=True)
print ("numeric columns: \n" , numeric_columns.tolist() )
#文字変数のみ抽出
chara_columns = train_df.select_dtypes(include = ["object" , "category"]).columns
print ("character columns: \n" , chara_columns.tolist())print ("文字列: \n" , chara_columns.tolist())
数値変数の偏りを調べます。
print(train_df[numeric_columns].skew())
train_df['sales_log'] = np.log1p(train_df['sales'])
目的変数である「売上」に大きな正の偏りがあることが分かりました。
このまま回帰モデルを学習させると、大きな値に引っ張られて予測精度が下がるリスクがあるので、売上データに対数変換(log変換)を適用し、分布を正規分布に近づけました。
2. 可視化
ここからはグラフで可視化していきます。
条件ごとにグラフを作成し、データの分布や傾向を直感的に理解できるようにしました。
これらのグラフは直接機械学習モデルには使用しないかもしれませんが、可視化を通して データの特徴を捉える力 や 前処理の方向性を考える力 を鍛えることを目的としました。
また作成する際にはSQLでグラフ作成時に用いるデータセットを作成し、その後Pythonで可視化しました。
以下は今回作成した条件別のグラフになります。
・売り上げ × 店舗 × 曜日
・売り上げ × 店舗 × 年
・売り上げ × 店舗 × 月
・店舗ごとの平均売上
・店ごとのトータル売り上げ
・売り上げ × 月
・売り上げ × 年
・売り上げ × 曜日
・売り上げ × 商品 × 年
・売り上げ × 商品 × 月
・売り上げ × 商品 × 曜日
・売り上げ × 地域名
・市ごとの平均売上
・市ごとの店舗数
・石油 × 年 × 月
・売り上げ × 年 × 月
・売り上げ × トランザクション
・トランザクション × 店舗 × 曜日
・売り上げ × プロモーション対象商品の数
・売り上げ × 店舗 × プロモーション対象商品の数
・売上 × 店舗クラスタ × 曜日
・売上 × 祝日フラグ(祝日 / transferred / work day)
・売り上げ × 商品名
・売り上げ × 商品名
・タイプごとの売り上げ
・売り上げ × 店舗
・type
・locale
ここでは以下の条件に絞りグラフ作成時の流れを説明します。
・売り上げ × 年
まずSQLでグループごとに平均の売り上げを算出し、任意のフォルダにエクセルファイルとして保存しました。
/*売り上げ*年*/
CREATE TABLE avg_sales_by_year AS
SELECT year , AVG(sales) as avg_sales
FROM data3
GROUP BY year
次に以下のコードを実行することでSQLで作成したグラフ用データをまとめて読みこみました。
folder_path = r"パス・ファイル名"
for filename in os.listdir(folder_path):
if filename.endswith(".csv"):
filepath = os.path.join(folder_path, filename)
var_name = os.path.splitext(filename)[0] # 拡張子なしのファイル名を変数名にする
globals()[var_name] = pd.read_csv(filepath)
# 日本語フォントを指定(Windowsでよく使われる)
plt.rcParams['font.family'] = 'MS Gothic' # 他に 'IPAexGothic', 'Meiryo' なども可
# avg_sales_by_year
#年ごとの売り上げ
plt.figure(figsize=(10, 6))
plt.bar(avg_sales_by_year["year"], avg_sales_by_year["avg_sales"], linewidth=2)
plt.title("年ごとの平均売上", fontsize=16, pad=15)
plt.xlabel("年", fontsize=14)
plt.ylabel("平均売上", fontsize=14)
plt.xticks(avg_sales_by_year["year"], fontsize=12)
plt.yticks(fontsize=12)
plt.tight_layout()
plt.show()
結果
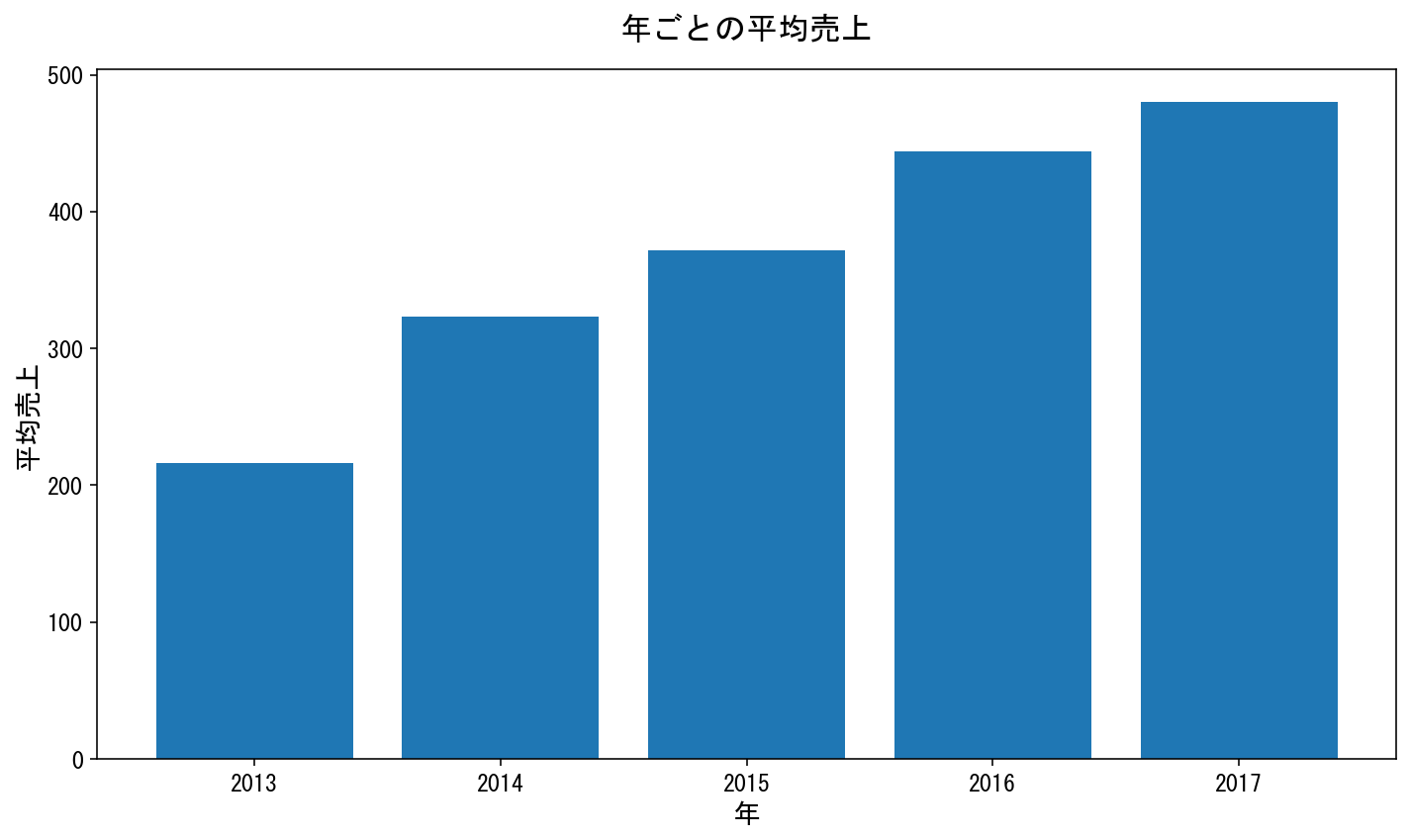
この店舗の全体売り上げの平均売上は年々増加していることが分かる
3. SHAP値
ここからは機械学習を行い売り上げ予測をしていきます。
目的変数である「売り上げ」にどの特徴量が特に効いているのかを調べる為にSHAP値を求めます。
from xgboost import XGBRegressor
from sklearn.model_selection import KFold, train_test_split
from sklearn.metrics import mean_squared_error, r2_score
import optuna
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from xgboost.callback import EarlyStopping
import xgboost as xgb
import shap
from lightgbm import LGBMRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
shpa_data = train_df.sample(100000, random_state = 42)
X_df = shpa_data.drop(['id' ,'year' ,'month' ,'weekday_num' ,'weekday_str' ,'date_n' , 'local_date' , 'regional_date' , 'national_date', 'sales' , 'sales_log'], axis=1)
y_df = shpa_data["sales"]
X_df.info()
# モデルのトレーニング
model = LGBMRegressor(random_state=42)
model.fit(X_df, y_df)
# SHAPの初期化
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_df)
# SHAPの可視化
#横軸が広く広がっているものはSHAP値の振れ幅が大きく目的変数に対する寄与度も高い
#重要な特徴量トップ 20がデフォルト出力
shap.summary_plot(shap_values, X_df)
shap.summary_plot(shap_values, X_df, plot_type="bar")
shap.summary_plot(shap_values, X_df, plot_type="bar", max_display=X_df.shape[1])
mean_abs_shap = np.abs(shap_values).mean(axis=0)
# 重要度の高い順にソート(インデックス取得)
top_indices = np.argsort(mean_abs_shap)[::-1]
# 対応する変数名を取り出してリスト化
top_features = X_df.columns[top_indices].tolist()
print("重要な特徴量リスト:")
print(top_features)
# 各特徴量の平均絶対SHAP値を計算
mean_abs_shap = np.abs(shap_values).mean(axis=0)
# 全特徴量を重要度の高い順にソート(インデックス取得)
sorted_indices = np.argsort(mean_abs_shap)[::-1]
# 特徴量名と重要度をペアにして取得
sorted_features = [(X_df.columns[i], mean_abs_shap[i]) for i in sorted_indices]
# 表示
print("全特徴量のSHAP重要度順一覧:")
for feature, importance in sorted_features:
print(f"{feature}: {importance:.6f}")
#TOP9位
# 変数名だけ取り出してリスト化
top9_vari = [X_df.columns[i] for i in sorted_indices[:9]]
print(top9_vari)
結果
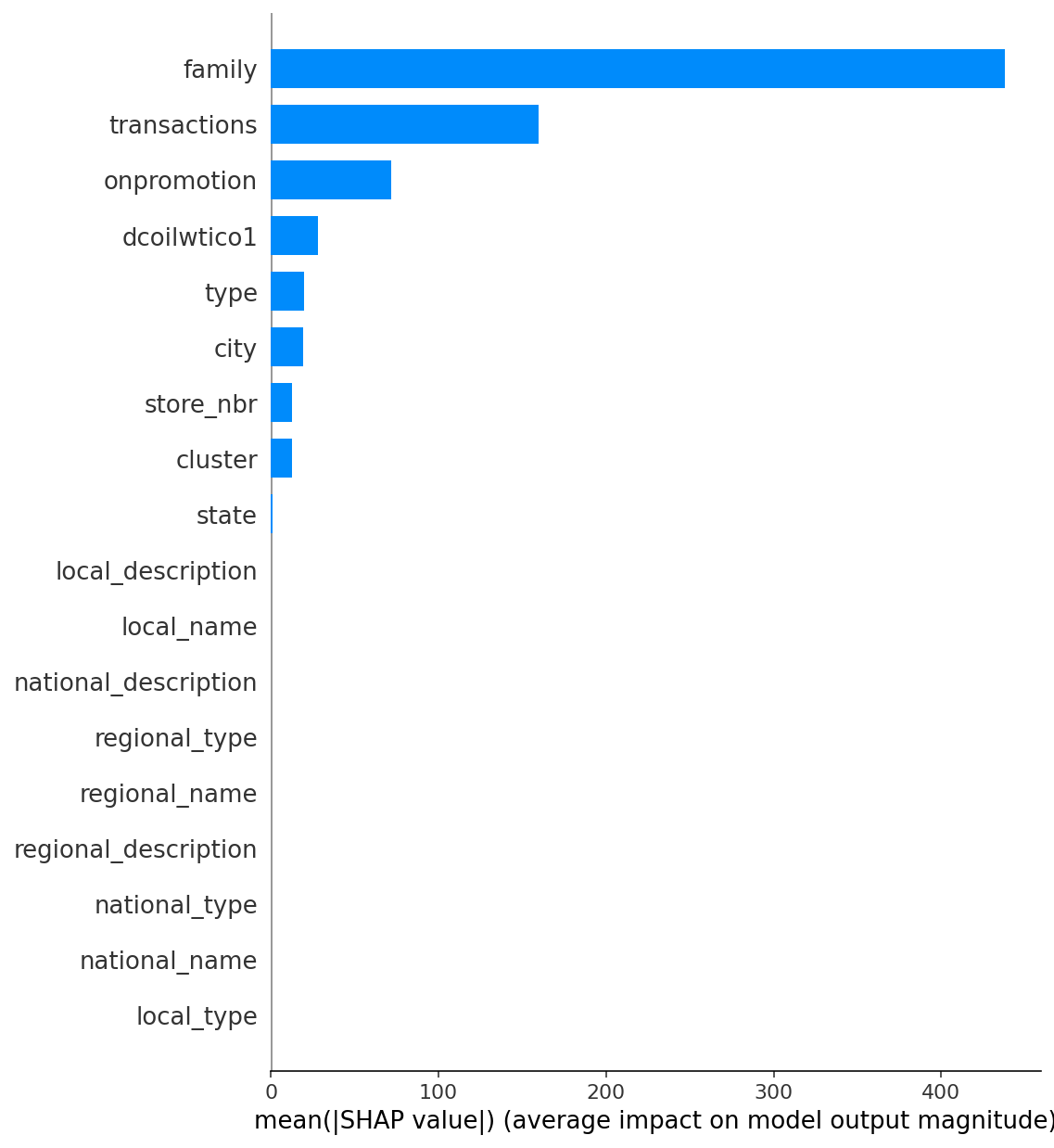
上記を実行することでSHAP値が求まり、その中から上位9位までの特徴量をTop9_variとして格納しました。
4.機械学習
次にTop9_variに絞ったtrainデータを使用してLightGBM・catboost・XGBoostの3つの手法を用いて売り上げを予測していきます。
各手法での全体の流れは以下になります。
1.データ前処理
学習用・検証用データに分割。
必要な特徴量を作成し、入力できる形に整備。
2.ハイパーパラメータ探索(Optuna)
重要なパラメータ(木の深さ、葉の数、正則化など)を自動的に探索。
精度が高く、かつ過学習しにくい設定を見つけることを目的とした。
3.モデル学習と評価
最適化したパラメータで学習。
4. 評価
RMSEとR²で精度を評価。
4-1.LightGBM
train_df1 = train_df[top9_vari]
test_df2 = test_df1[top9_vari]
# カテゴリ変数を category 型に
for df in [train_df, test_df]:
for col in df.select_dtypes(include='object').columns:
df[col] = df[col].astype('category')
# 特徴量と目的変数の分離
X = train_df1
Y = train_df["sales_log"].values
# 訓練・テスト分割
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, random_state=42)
def bayes_objective(trial):
params = {
'objective': 'regression',
'metric': 'rmse',
'random_state': 42,
'reg_alpha': trial.suggest_float('reg_alpha', 1e-8, 1.0, log=True),
'reg_lambda': trial.suggest_float('reg_lambda', 1e-8, 1.0, log=True),
'num_leaves': trial.suggest_int('num_leaves', 16, 512),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.4, 1.0),
'subsample': trial.suggest_float('subsample', 0.7, 1.0),
'subsample_freq': trial.suggest_int('subsample_freq', 1, 3),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
'learning_rate': trial.suggest_float('learning_rate', 0.005, 0.1, log=True),
'verbose': -1,
'boosting_type': 'gbdt',
'max_depth': trial.suggest_int('max_depth', 3, 12),
'device': 'cpu',
'gpu_use_dp': True
}
kf = KFold(n_splits=5, shuffle=True, random_state=42)
rmse_scores = []
for train_idx, val_idx in kf.split(X):
X_tr, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_tr, y_val = Y[train_idx], Y[val_idx]
model = LGBMRegressor(**params)
model.fit(
X_tr, y_tr,
eval_set=[(X_val, y_val)],
callbacks=[early_stopping(stopping_rounds=50)],
categorical_feature=['family', 'type', 'city', 'state']
)
y_pred = model.predict(X_val)
rmse = mean_squared_error(y_val, y_pred)
rmse_scores.append(rmse)
return -np.mean(rmse_scores) # Optunaはmaximizeするので、RMSEをマイナスにする
seed = 42
study = optuna.create_study(direction='maximize',
sampler=optuna.samplers.TPESampler(seed=seed))
study.optimize(bayes_objective, n_trials=100)
GBM_best_params = study.best_trial.params
#一番良かったパラメータのときのスコア(評価結果)を取り出す
best_score = study.best_trial.value
print(f'最適パラメータ {GBM_best_params}\nスコア {best_score}')
from optuna.importance import get_param_importances
importances = get_param_importances(study)
print(importances)
final_params = {
**GBM_best_params, # 上記で見つけた最終的にモデルに使うパラメータを示す
'objective': 'regression',
'metric': 'rmse',
'boosting_type': 'gbdt',
'random_state': seed,
'n_estimators': 3000,
'verbose': -1,
'device': 'cpu',
'gpu_use_dp': False
}
test_X = test_df2
# ========== ✅KFold で最終モデルを学習・予測 ========== #
kf = KFold(n_splits=5, shuffle=True, random_state=42)
test_pred_log_submit = np.zeros(len(test_X))
for fold, (train_idx, val_idx) in enumerate(kf.split(X)):
print(f"Fold {fold + 1}")
X_tr, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_tr, y_val = Y[train_idx], Y[val_idx]
model = LGBMRegressor(**final_params)
model.fit(
X_tr, y_tr,
eval_set=[(X_val, y_val)],
callbacks=[early_stopping(50)],
categorical_feature=['family', 'type', 'city', 'state']
)
test_pred_log_submit += model.predict(test_X, num_iteration=model.best_iteration_) / kf.get_n_splits()
# ========== 予測値を戻して提出形式に ========== #
test_pred_submit = np.expm1(test_pred_log_submit)
test_pred_submit = np.where(test_pred_submit < 0, 0, test_pred_submit)
submission = pd.DataFrame({
"id": test_df["id"],
"sales": test_pred_submit
})
submission.to_csv("パス名", index=False)
# 評価用:KFoldでの予測結果を蓄積してRMSE/R2を計算
oof_preds = np.zeros(len(X))
for fold, (train_idx, val_idx) in enumerate(kf.split(X)):
X_tr, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_tr, y_val = Y[train_idx], Y[val_idx]
model = LGBMRegressor(**final_params)
model.fit(
X_tr, y_tr,
eval_set=[(X_val, y_val)],
callbacks=[early_stopping(50)]
)
oof_preds[val_idx] = model.predict(X_val, num_iteration=model.best_iteration_)
# 評価指標(logスケール)
rmse = np.sqrt(mean_squared_error(Y, oof_preds))
r2 = r2_score(Y, oof_preds)
print(f"✅ KFoldによるCVスコア")
print(f"RMSE: {rmse:.4f}")
print(f"R² : {r2:.4f}")
# 可視化(元スケールに戻す)
Y_exp = np.expm1(Y)
oof_exp = np.expm1(oof_preds)
plt.figure(figsize=(8, 6))
plt.scatter(Y_exp, oof_exp, alpha=0.5)
plt.plot([0, max(Y_exp)], [0, max(Y_exp)], color="red", linestyle="--", label="完全一致ライン")
plt.xlabel("実際の値(正解)", fontsize=12)
plt.ylabel("予測値", fontsize=12)
plt.title("KFold予測値 vs 実測値", fontsize=14)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
4-2. Catboost
train_df1 = train_df[top9_vari]
test_df2 = test_df1[top9_vari]
X = train_df1
Y = train_df["sales_log"].values
test_X = test_df2
# Optuna 目的関数
def catboost_objective(trial):
params = {
'learning_rate': trial.suggest_float("learning_rate", 0.03, 0.1, log=True),
'depth': trial.suggest_int("depth", 6, 8),
'l2_leaf_reg': trial.suggest_float("l2_leaf_reg", 1, 10.0),
'bagging_temperature': trial.suggest_float("bagging_temperature", 0.0, 1.0),
'loss_function': 'RMSE',
'eval_metric': 'RMSE',
'task_type': 'GPU',
'verbose': False
}
kf = KFold(n_splits=5, shuffle=True, random_state=42)
rmse_scores = []
for train_idx, val_idx in kf.split(X):
X_tr, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_tr, y_val = Y[train_idx], Y[val_idx]
model = CatBoostRegressor(**params)
model.fit(X_tr, y_tr, cat_features=['family', 'type', 'city', 'state'], eval_set=(X_val, y_val), early_stopping_rounds=100)
preds = model.predict(X_val)
rmse = np.sqrt(mean_squared_error(np.exp(y_val), np.exp(preds)))
rmse_scores.append(rmse)
return -np.mean(rmse_scores)
# Optuna実行
study = optuna.create_study(direction='maximize', sampler=optuna.samplers.TPESampler(seed=42))
study.optimize(catboost_objective, n_trials=100)
print(f"成功した試行数: {len([t for t in study.trials if t.state.name == 'COMPLETE'])}")
best_params = study.best_trial.params
print(f"最適パラメータ: {best_params}\nスコア: {study.best_trial.value}")
from optuna.importance import get_param_importances
importances = get_param_importances(study)
print(importances)
# 最終学習パラメータ
final_params = {
**best_params,
'random_seed': 42,
'task_type': 'GPU',
'loss_function': 'RMSE',
'verbose': False
}
# KFoldで最終予測
kf = KFold(n_splits=5, shuffle=True, random_state=42)
test_pred_log_submit = np.zeros(len(test_X))
oof_preds = np.zeros(len(X))
for fold, (train_idx, val_idx) in enumerate(kf.split(X)):
print(f"Fold {fold + 1}")
X_tr, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_tr, y_val = Y[train_idx], Y[val_idx]
model = CatBoostRegressor(**final_params)
model.fit(X_tr, y_tr, cat_features=['family', 'type', 'city', 'state'], eval_set=(X_val, y_val), early_stopping_rounds=100)
oof_preds[val_idx] = model.predict(X_val)
test_pred_log_submit += model.predict(test_X) / kf.get_n_splits()
# logスケール戻し&マイナス予測の対処
test_pred_submit = np.exp(test_pred_log_submit)
test_pred_submit = np.where(test_pred_submit < 0, 0, test_pred_submit)
# 提出ファイル
submission = pd.DataFrame({
"id": test_df["id"],
"sales": test_pred_submit
})
submission.to_csv("パス名", index=False)
# 評価指標
rmse = mean_squared_error(np.exp(Y), np.exp(oof_preds), squared=False)
r2 = r2_score(Y, oof_preds)
print(f"✅ KFoldによるCVスコア\nRMSE: {rmse:.4f}\nR² : {r2:.4f}")
rmse = mean_squared_error(Y, oof_preds, squared=False)
r2 = r2_score(Y, oof_preds)
print(f"✅ KFoldによるCVスコア\nRMSE: {rmse:.4f}\nR² : {r2:.4f}")
# 可視化
plt.figure(figsize=(8, 6))
plt.scatter(np.expm1(Y), np.expm1(oof_preds), alpha=0.5)
plt.plot([0, max(np.expm1(Y))], [0, max(np.expm1(Y))], color="red", linestyle="--", label="完全一致ライン")
plt.xlabel("実際の値(正解)", fontsize=12)
plt.ylabel("予測値", fontsize=12)
plt.title("KFold予測値 vs 実測値(CatBoost)", fontsize=14)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
4-3. XGBoost
train_df1 = train_df[top9_vari]
test_df2 = test_df1[top9_vari]
X = train_df1
Y = train_df["sales_log"].values
# テストデータの整形(カテゴリがある場合は型変換も)
test_X = test_df1[top9_vari]
# Optuna の目的関数
def bayes_objective(trial):
params = {
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'tree_method': 'gpu_hist',
'predictor': 'gpu_predictor',
'max_depth': trial.suggest_int('max_depth', 6, 8),
'learning_rate': trial.suggest_float('learning_rate', 0.02, 0.1, log=True),
'subsample': trial.suggest_float('subsample', 0.85, 0.95),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.7, 1.0),
'min_child_weight': trial.suggest_float('min_child_weight', 1.0, 10.0),
'reg_alpha': trial.suggest_float('reg_alpha', 0.0, 1.0),
'reg_lambda': trial.suggest_float('reg_lambda', 1e-3, 1.0, log=True),
'max_bin': trial.suggest_categorical('max_bin', [256, 384, 512]),
'max_cat_to_onehot': 4,
'enable_categorical': True,
'verbosity': 0,
'seed': 42,
}
kf = KFold(n_splits=5, shuffle=True, random_state=42)
rmse_scores = []
for train_idx, val_idx in kf.split(X):
X_tr, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_tr, y_val = Y[train_idx], Y[val_idx]
dtrain = xgb.DMatrix(X_tr, label=y_tr, enable_categorical=True)
dval = xgb.DMatrix(X_val, label=y_val, enable_categorical=True)
evals = [(dval, 'eval')]
model = xgb.train(
params,
dtrain,
num_boost_round=3000,
evals=evals,
early_stopping_rounds=100,
verbose_eval=False
)
preds = model.predict(dval, iteration_range=(0, model.best_iteration + 1))
rmse = np.sqrt(mean_squared_error(np.exp(y_val), np.exp(preds))) #対数から戻して評価
rmse_scores.append(rmse)
return -np.mean(rmse_scores)
# Optuna でチューニング
study = optuna.create_study(direction='maximize', sampler=optuna.samplers.TPESampler(seed=42))
study.optimize(bayes_objective, n_trials=100)
print(f"成功した試行数: {len([t for t in study.trials if t.state.name == 'COMPLETE'])}")
# 最適パラメータ
best_params = study.best_trial.params
best_score = study.best_trial.value
print(f"最適パラメータ: {best_params}\nスコア: {best_score}")
from optuna.importance import get_param_importances
importances = get_param_importances(study)
print(importances)
# 本番用パラメータ(n_estimators などを追加)
final_params = {
**best_params,
'n_estimators': 10000,
'random_state': 42,
'tree_method': 'gpu_hist',
'verbosity': 0
}
# KFold で最終予測(テストデータ)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
test_pred_log_submit = np.zeros(len(test_X))
oof_preds = np.zeros(len(X))
for fold, (train_idx, val_idx) in enumerate(kf.split(X)):
print(f"Fold {fold + 1}")
X_tr, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_tr, y_val = Y[train_idx], Y[val_idx]
# callbacksをコンストラクタで渡す(推奨)
model = XGBRegressor(
**final_params,
callbacks=[EarlyStopping(rounds=100, save_best=True)],
enable_categorical=True
)
model.fit(
X_tr, y_tr,
eval_set=[(X_val, y_val)],
verbose=False
)
best_iteration = model.get_booster().best_iteration
test_pred_log_submit += model.predict(test_X, iteration_range=(0, best_iteration)) / kf.get_n_splits()
oof_preds[val_idx] = model.predict(X_val, iteration_range=(0, best_iteration))
# logスケール戻し&マイナス予測の対処
test_pred_submit = np.exp(test_pred_log_submit)
test_pred_submit = np.where(test_pred_submit < 0, 0, test_pred_submit)
# 提出ファイル
submission = pd.DataFrame({
"id": test_df["id"],
"sales": test_pred_submit
})
submission.to_csv("パス名", index=False)
# 評価指標
rmse = mean_squared_error(np.exp(Y), np.exp(oof_preds), squared=False)
r2 = r2_score(Y, oof_preds)
print(f"✅ KFoldによるCVスコア\nRMSE: {rmse:.4f}\nR² : {r2:.4f}")
rmse = mean_squared_error(Y, oof_preds, squared=False)
r2 = r2_score(Y, oof_preds)
print(f"✅ KFoldによるCVスコア\nRMSE: {rmse:.4f}\nR² : {r2:.4f}")
# 可視化
plt.figure(figsize=(8, 6))
plt.scatter(np.expm1(Y), np.expm1(oof_preds), alpha=0.5)
plt.plot([0, max(np.expm1(Y))], [0, max(np.expm1(Y))], color="red", linestyle="--", label="完全一致ライン")
plt.xlabel("実際の値(正解)", fontsize=12)
plt.ylabel("予測値", fontsize=12)
plt.title("KFold予測値 vs 実測値(XGBoost)", fontsize=14)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
5.結果・考察
LightGBM
n_trails = 100
RMSE: 0.6036
R² : 0.9498
n_trails = 30
RMSE: 0.6033
R² : 0.9499
わずかながら30回の方が良いスコアとなった。試行回数を増やしたことで過学習気味になった可能性がある。
考察: LightGBMは高速かつ精度が高いが、過学習を防ぐためには早期停止が重要と考える。
Catboost
n_trails = 100
RMSE: 0.6770
R² : 0.9369
n_trails = 30
RMSE: 0.6782
R² : 0.9367
試行回数を増やすことで僅かに改善。過学習の兆候は見られなかった。
考察: カテゴリ変数の処理に強みを持つCatBoostだが、本データセットではLightGBMやXGBoostに比べて劣後。
特徴量の性質に応じたモデル選択の重要性を学んだ。
XGBoost
n_trails = 100
RMSE: 0.5503
R² : 0.9583
n_trails = 30
RMSE: 0.5504
R² : 0.9583
試行回数の回数による結果への差異はほとんど見られない。
考察: XGBoostは安定性が高く、本ケースでは最も良いスコアを達成した。
6.まとめ
今回のタスクでは XGBoost > LightGBM > CatBoost の順で精度が高かった。
Optunaを活用したハイパーパラメータ探索により、探索回数の違いがモデルごとに与える影響を比較できた。
特にLightGBMは試行回数が多いと過学習リスクがある一方、XGBoostは安定した精度を発揮した。
今回の分析では get_param_importances を用いてパラメータの重要度を確認し、設定に反映させた。今後はパラメータチューニングに関する理解をさらに深め、より最適なモデル構築を目指したい。
習得スキル
SQL / Pythonの基礎構文とデータ前処理
EDA(探索的データ分析)
可視化
SHAP値による特徴量の解釈
Optunaを用いたハイパーパラメータ最適化
モデル実装(LightGBM / CatBoost / XGBoost)