はじめに
当記事はkaggleのLearnのIntro to Machine LearningのCategorical Variablesを翻訳して備忘としたものです。
拙い英語力なので間違い等あればご指摘いただけたらと思います。
まとめ:【kaggle】翻訳記事まとめ【備忘翻訳】
前:【kaggle】中級機械学習 - 欠損値【備忘翻訳】
次:【kaggle】中級機械学習 - パイプライン【備忘翻訳】
当記事に含まれるコードはkaggle内のnotebook内で正常に動作します。動作を試したい場合はkaggleのnotebookで試してください。
カテゴリ変数
世の中には数値以外のデータがたくさんあります。ここでは、それを機械学習に使用する方法を説明します。
このチュートリアルでは、カテゴリ変数とは何か、またこのタイプのデータを処理するための3つのアプローチについて学習します。
イントロ
カテゴリ変数は数値のみに限られます。
- 朝食を食べる頻度を尋ね、「全く食べない」、「めったに食べない」、「ほとんど毎日食べる」、「毎日食べる」という4つの選択肢を提供したアンケートを考えてみましょう。この場合、回答は固定された一連のカテゴリに分類されるため、データはカテゴリ別になります。
- 所有している車について調査した結果、その回答は「ホンダ」や、「トヨタ」、「フォード」などのようなカテゴリとして落とし込めます。この場合も、カテゴリとして分類できます。
これらの変数を事前に処理せずにpythonの機械学習モデルで処理しようとすると、ほとんどの場合エラーが発生するでしょう。このチュートリアルではカテゴリデータを準備するための3つのアプローチを比較します。
3つのアプローチ
1) カテゴリ変数の削除
最も簡単なアプローチは単純にデータセットからカテゴリ変数を削除することです。このアプローチはその列に有用な情報が含まれない場合にのみ有効です。
2) Ordinal(序列)エンコーディング
Ordinal(序列) エンコーディングでは各一意の値がそれぞれ異なる整数に割り当てられます。
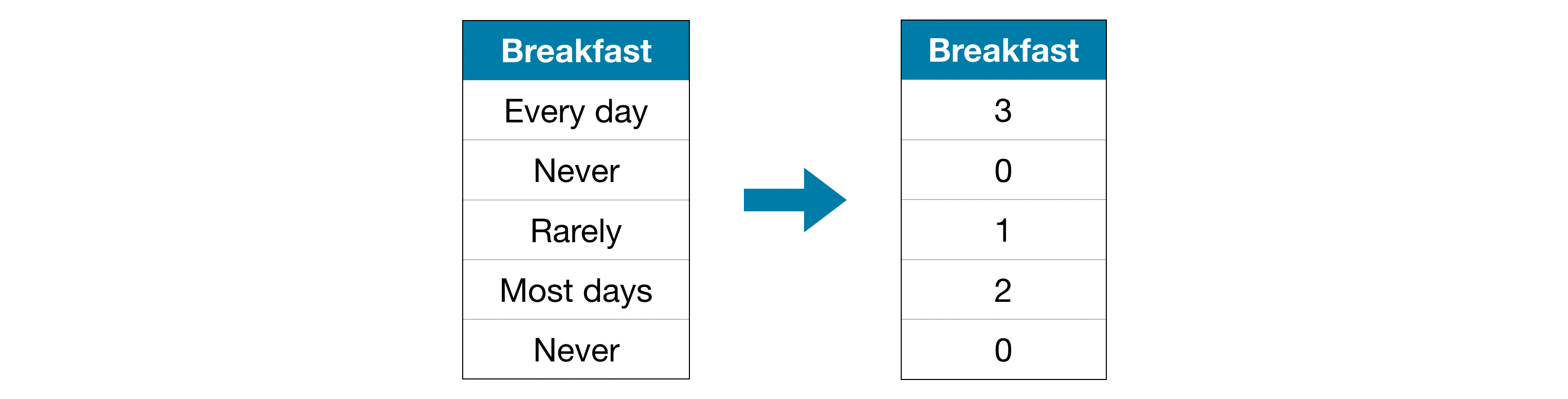
このアプローチは、カテゴリーの順位付けを前提としています。: 「全くない」(0) < 「めったにない」(1) < 「ほとんど」(2) < 「毎日」(3)
この例ではカテゴリに議論の余地のない順位付けがあるため、この過程は意味をなします。すべてのカテゴリ変数に値の明確な序列があるわけではありませんが、そのような変数を序列変数と呼びます。ツリーベースのモデル(決定木やランダムフォレストなど)の場合、序列変数ではordinalエンコーディングが適切に機能することが期待できます。
3) One-Hot エンコーディング
One-hotエンコーディングでは元のデータに含まれる可能性のある各値の存在(または不在)を示す新しい列を作成します。分かりやすいように例を見てみましょう。
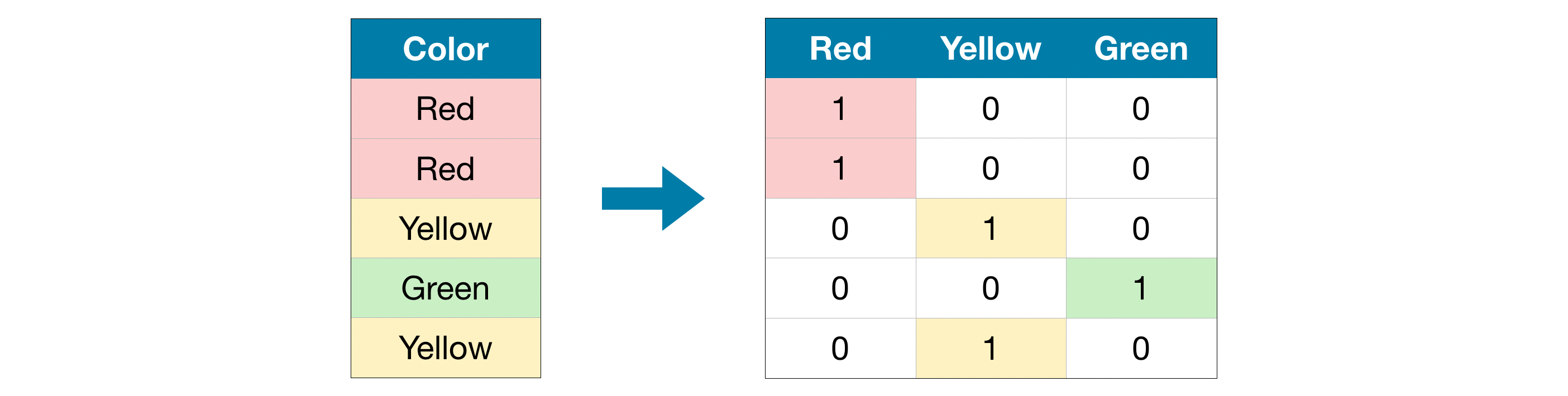
元のデータセットでは「色」は「赤」、「黄」、「緑」の3つのカテゴリを持つカテゴリ変数です。対応するone-hotエンコーディングでは、可能性のある各値に対する新たに追加された1列に、元のデータセットの各行が対応しています。元の値が「赤」だった場合は、「赤」列に1を入れます。元の値が「黄色」の場合は、「黄色」に1を入力します。
ordinal(序列)エンコーディングと対照的に、one-hotエンコーディングではカテゴリの順位付けは想定されません。したがって、カテゴリデータに明確な序列がない場合(例えば「赤」は「黄色」よりも多くも少なくもない)は、このアプローチが特に上手く機能すると予想できます。
通常、カテゴリ変数が多数の値を取る場合、one-hotエンコーディングは適切に機能しません(おおよそ、15を超える異なる値を取る変数には使用されません)。
例
前回のチュートリアルと同様に、メルボルンの住宅データセットを使用します。
データの取り込み手順については特に触れません。X_train、X_valid、y_train、y_validにデータが取り込まれている段階にあると考えてください。
データの取り込み
import pandas as pd
from sklearn.model_selection import train_test_split
# Read the data
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Separate target from predictors
y = data.Price
X = data.drop(['Price'], axis=1)
# Divide data into training and validation subsets
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)
# Drop columns with missing values (simplest approach)
cols_with_missing = [col for col in X_train_full.columns if X_train_full[col].isnull().any()]
X_train_full.drop(cols_with_missing, axis=1, inplace=True)
X_valid_full.drop(cols_with_missing, axis=1, inplace=True)
# "Cardinality" means the number of unique values in a column
# Select categorical columns with relatively low cardinality (convenient but arbitrary)
low_cardinality_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and
X_train_full[cname].dtype == "object"]
# Select numerical columns
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
# Keep selected columns only
my_cols = low_cardinality_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
head()メソッドで、トレーニングデータを見てみましょう。
X_train.head()
| Type | Method | Regionname | Rooms | Distance | Postcode | Bedroom2 | Bathroom | Landsize | Lattitude | Longtitude | Propertycount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 12167 | u | S | Southern Metropolitan | 1 | 5.0 | 3182.0 | 1.0 | 1.0 | 0.0 | -37.85984 | 144.9867 | 13240.0 |
| 6524 | h | SA | Western Metropolitan | 2 | 8.0 | 3016.0 | 2.0 | 2.0 | 193.0 | -37.85800 | 144.9005 | 6380.0 |
| 8413 | h | S | Western Metropolitan | 3 | 12.6 | 3020.0 | 3.0 | 1.0 | 555.0 | -37.79880 | 144.8220 | 3755.0 |
| 2919 | u | SP | Northern Metropolitan | 3 | 13.0 | 3046.0 | 3.0 | 1.0 | 265.0 | -37.70830 | 144.9158 | 8870.0 |
| 6043 | h | S | Western Metropolitan | 3 | 13.3 | 3020.0 | 3.0 | 1.0 | 673.0 | -37.76230 | 144.8272 | 4217.0 |
次に、トレーニングデータ内の全てのカテゴリ変数のリストを取得します。
これは各列で、データの型(またはdtype)をチェックすることで可能です。objectdtypeはその列がテキストを含むかを示します。このデータセットでは、テキストのある列はカテゴリ変数として示します。
# Get list of categorical variables
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
Categorical variables:
['Type', 'Method', 'Regionname']
各アプローチの品質を測定する関数を定義する
カテゴリ変数を扱う3つの異なるアプローチを比較するために、score_dataset()関数を定義します。この関数はランダムフォレストモデルからの平均絶対誤差(MAE)を返却します。
score_dataset()
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# Function for comparing different approaches
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)
アプローチ1のスコア(カテゴリ変数の削除)
select_dtypes()メソッドを使用してobject列を削除します。
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
MAE from Approach 1 (Drop categorical variables):
175703.48185157913
アプローチ2のスコア(ordinal(序列)エンコーディング)
scikit-learnはordinalエンコーディングを提供するクラスのOrdinalEncoderを提供しています。カテゴリ変数をループし、各列にOrdinalEncoderを個別に適用します。
from sklearn.preprocessing import OrdinalEncoder
# Make copy to avoid changing original data
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()
# Apply ordinal encoder to each column with categorical data
ordinal_encoder = OrdinalEncoder()
label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols])
label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
MAE from Approach 2 (Ordinal Encoding):
165936.40548390493
上記のコードでは、各列ごとに、イチイの値をそれぞれ異なる整数をランダムに割り当てます。これはカスタムラベルを提供するよりも簡単な一般的なアプローチです。ただし、すべての序列変数に対してより情報に基づいたラベルを提供すると、パフォーマンスのさらなる向上が期待できます。
アプローチ3のスコア(One-Hotエンコーディング)
scikit-learnからone-hotエンコーディングを使うにはOneHotEncorderクラスを用います。動作をカスタマイズするために使用できるパラメータがいくつかあります。
- トレーニングデータに含まれていない列が検証データにあった場合にエラーを回避する
handle_unknown='ignore' -
sparse=Falseに設定すると、エンコーディングされた列がnumpy配列として返却されるようになります
エンコーダーを使用するには、one-hotエンコードするカテゴリ変数列のみを指定します。例えば、トレーニングデータをエンコードするには、X_train[object_cols]を指定します。(以下のコードのobject_colsはカテゴリデータを含む列名のリストであるため、X_train[object_cols]にはトレーニングセット内の全てのカテゴリデータが含まれます。)
from sklearn.preprocessing import OneHotEncoder
# Apply one-hot encoder to each column with categorical data
OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
# One-hot encoding removed index; put it back
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index
# Remove categorical columns (will replace with one-hot encoding)
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)
# Add one-hot encoded columns to numerical features
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
# Ensure all columns have string type
OH_X_train.columns = OH_X_train.columns.astype(str)
OH_X_valid.columns = OH_X_valid.columns.astype(str)
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))
MAE from Approach 3 (One-Hot Encoding):
166089.4893009678
どのアプローチがベスト?
今回のケースではカテゴリ列を消したアプローチ(アプローチ1)が最もパフォーマンスが悪く、MAEスコアが最も高くなりました。一方他の2つのアプローチは、MAEスコアの値は非常に近く、どちらかが他方よりも優位なパフォーマンスを持つようには見えません。
一般的にone-hotエンコーディング(アプローチ3)はパフォーマンスが最もよく、カテゴリ列を削除すると(アプローチ1)パフォーマンスが最も悪くなりますが、ケースによって異なります。
まとめ
世界はカテゴリデータで溢れています。この一般的なデータタイプの使い方を知っていれば、より効果的なデータサイエンティストになれるでしょう。