概要
文字情報の音声読み上げファイルをワークフローで作成します。
今回はワークフローツールとしてn8n、読み上げのAPIとしてOpenAI Text to Speech(TTS) を使用しています。
n8nから提供されているノードだけで完結しており、HTTP Requestノードでの API 直リクエストは一切使っていません。
GUI 上でノードを数個つなぐだけで「テキスト → 音声(MP3)」のフローを構築でき、とても簡単!
構成
- ワークフローツール:n8n(Version 1.118)
- 読み上げ:OpenAI TTS
使用ノード
OpenAI(Message a model)→ OpenAI(Generate Audio)
構成図
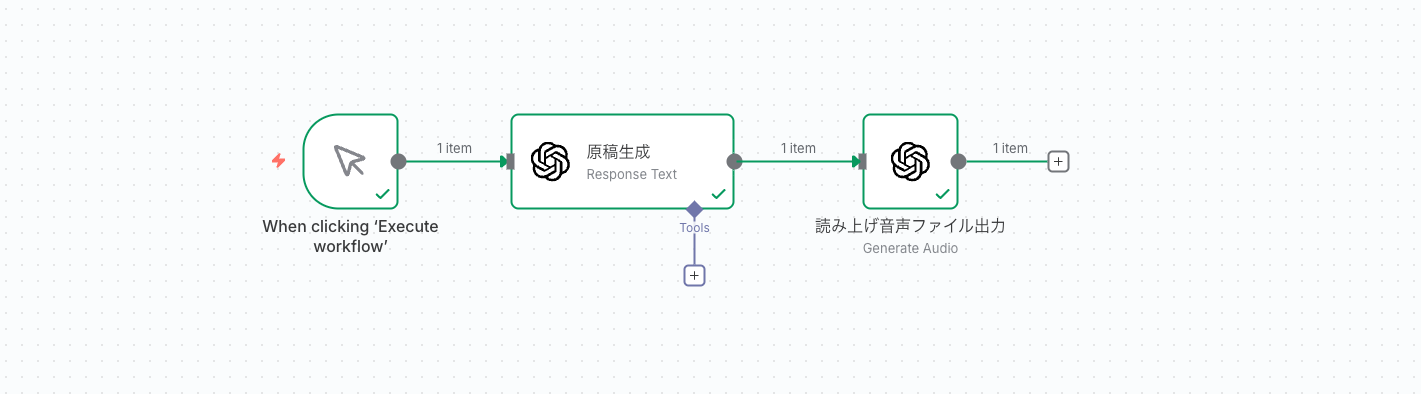
出来た出力
下記のような入力から読み上げファイルを出力
▼ Input
あなたはラジオDJです
ピラミッドについて解説してください
ラジオ原稿となる部分だけ返却してください
▼ Output
mp3形式で読み上げファイルを生成
Node Generate Audioについて
n8nのOpenAIノードにはAudio operationsが用意されており、その中のひとつが"Generate Audio"です。 
このノードは、OpenAIのAudio API(Text to Speech)をラップしたもので、テキストを渡すだけで音声ファイルを生成してくれます。
▼ TTSについて
主な設定項目は次のとおりです。
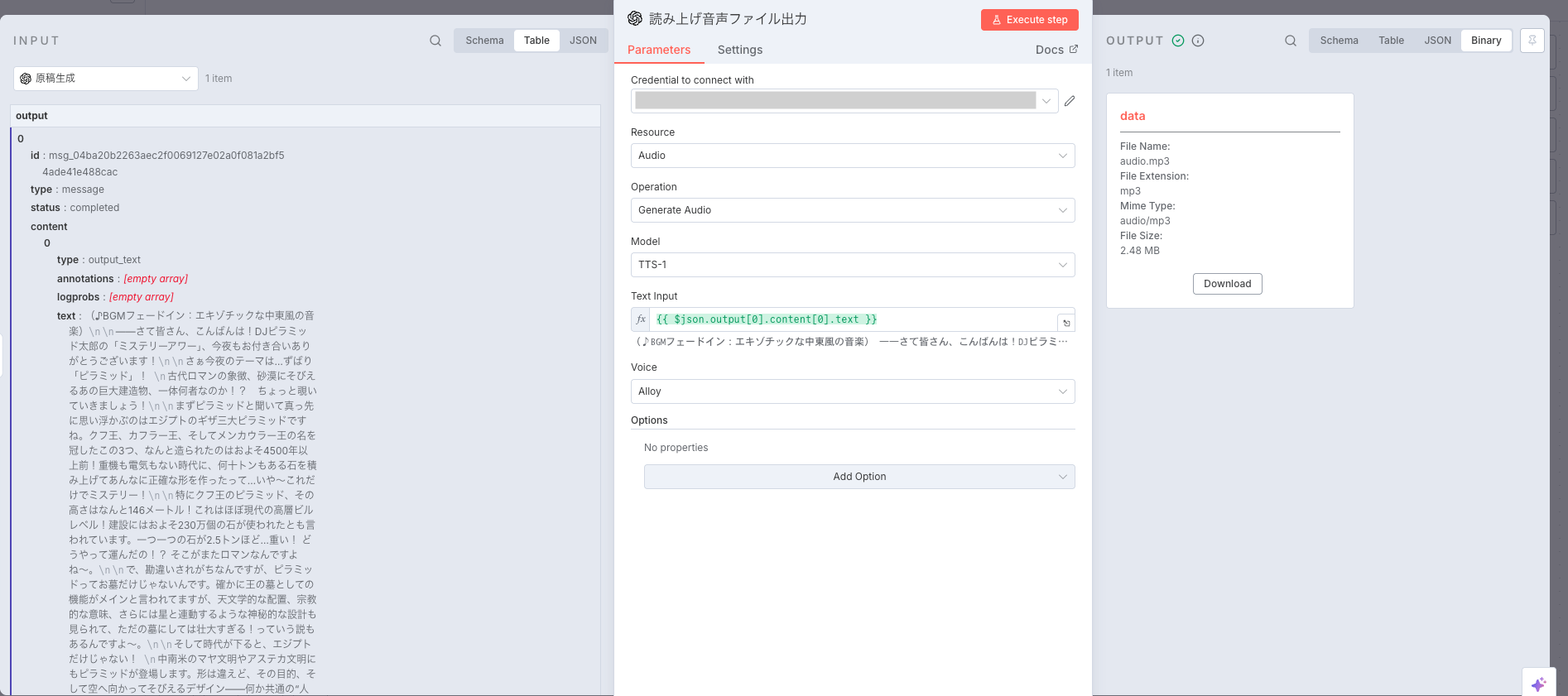
Modelについて
n8nモデル欄に各モデル名を指定するだけで利用できます。
OpenAI TTSで利用できるモデルは次のとおりです。 
- tts-1
- リアルタイム用途向けに最適化されたベースモデル。速度を重視したユースケース向き
- tts-1-hd
- 高品質な音声生成向けのモデル。自然さやイントネーションを重視したい場合に適する
感想
出力された文章に対しての整形処理を簡単に行うことでき、定性情報の取り扱い方のハードルが格段に楽になったと実感します。
今後は日々の日常に応じた形で文言の情報を整形し、ワークフローに組み込んでいきたいです。