はじめに
AAAI19で北京大学、アリババ、テンプル大学の合同チームにより発表された物体検出技術M2Detについての解説です。
- Qijie Zhao et al., M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network.
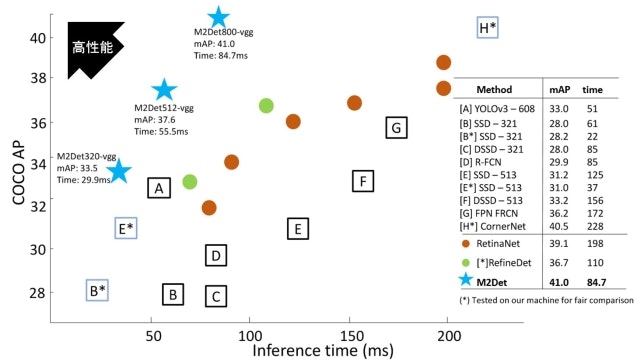
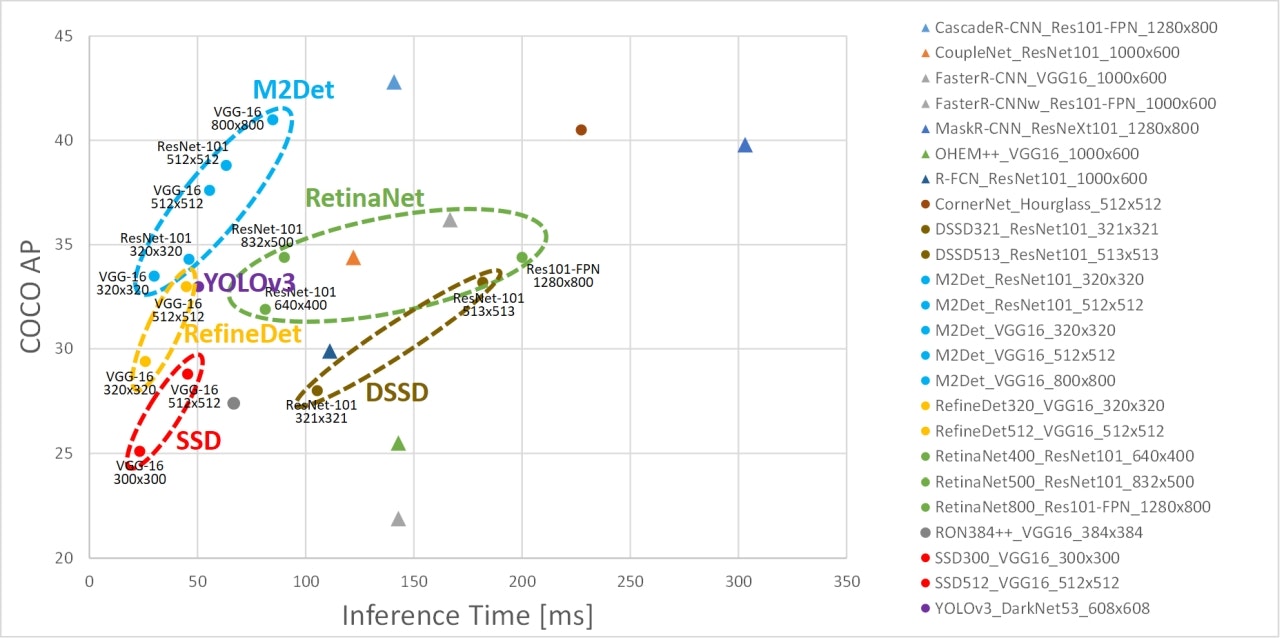
下記は論文から引用した他手法との性能比較図ですが、水色の★がM2Detです。横軸が処理時間、縦軸が検出精度なので、左上にいくほど性能が高い(高速かつ高精度)ことになりますが、M2DetはRetinaNetやRefineDet、SSDやYOLOなどの有名な既存手法を凌駕していることがわかります。
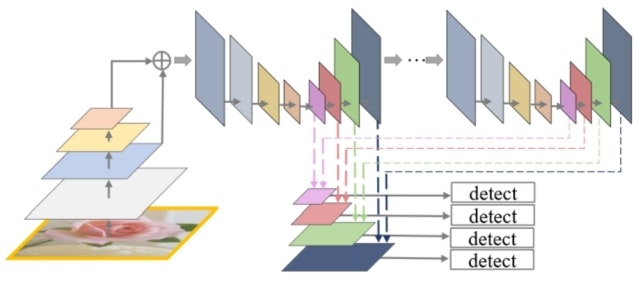
ざっくりとしたアーキテクチャは以下のように図示されていますが、これだけではよくわからないので細かく中身を見ていきたいと思います。
アーキテクチャ概要
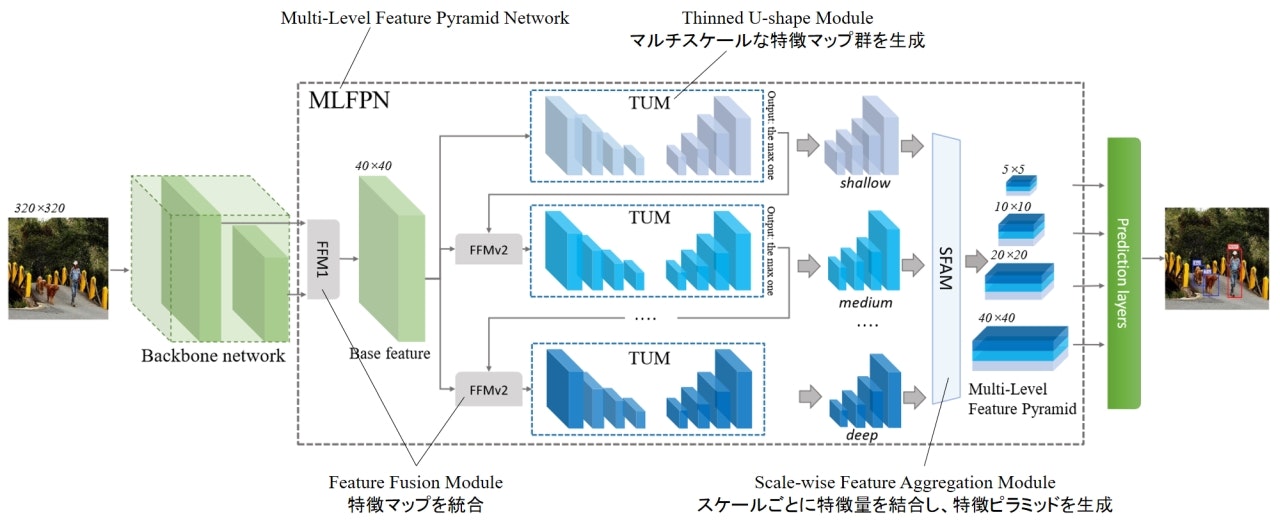
M2Detのアーキテクチャの概要は上図のようになります。大きく分けてBackbone networkとMulti-Level Feature Pyramid Network (MLFPN)、Prediction layersから成ります。それぞれの詳細について以下で見ていきます。
Backbone network
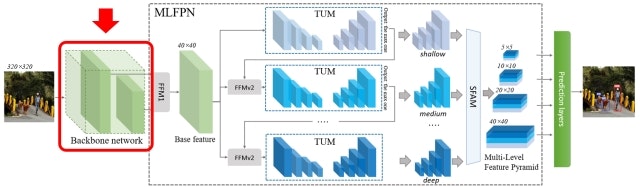
ここは単なる特徴抽出器なので、画像分類向けの任意のアーキテクチャが利用できます。論文ではVGG-16とResNet-101が用いられています。
Multi-Level Feature Pyramid Network (MLFPN)
MLFPNは以下3つのモジュールで構成されます。
- Feature Fusion Module (FFM)
- Thinned U-shape Module (TUM)
- Scale-wise Feature Aggregation Module (SFAM)
Feature Fusion Module v1 (FFMv1)
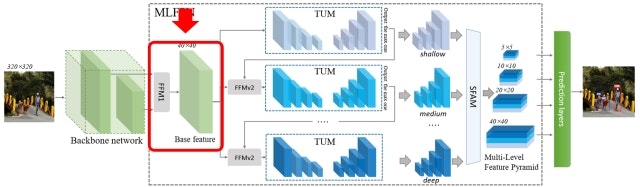
FFMは複数回登場しますが、まず最初のFFM(これをFFMv1と呼びます)は、Backbone networkで得られる特徴ピラミッドのうち異なる解像度の特徴マップをフュージョンすることでBase featureと呼ぶ特徴マップを生成します。以下はBackboneにVGG-16を利用し、conv4_3とconv5_3の特徴マップをFFMv1がフュージョンする様子を示しています。最初のConv層でチャネル方向を圧縮し、かつ解像度が小さい特徴マップについてはアップサンプルして解像度をそろえたうえでConcatすることでフュージョンを実現します。
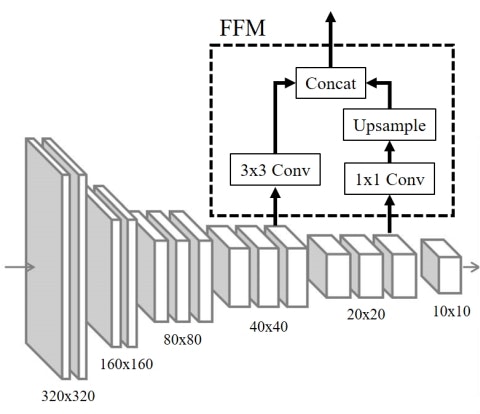
Thinned U-shape Module
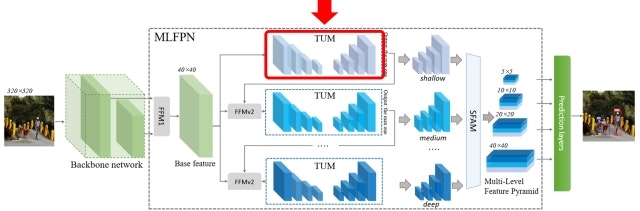
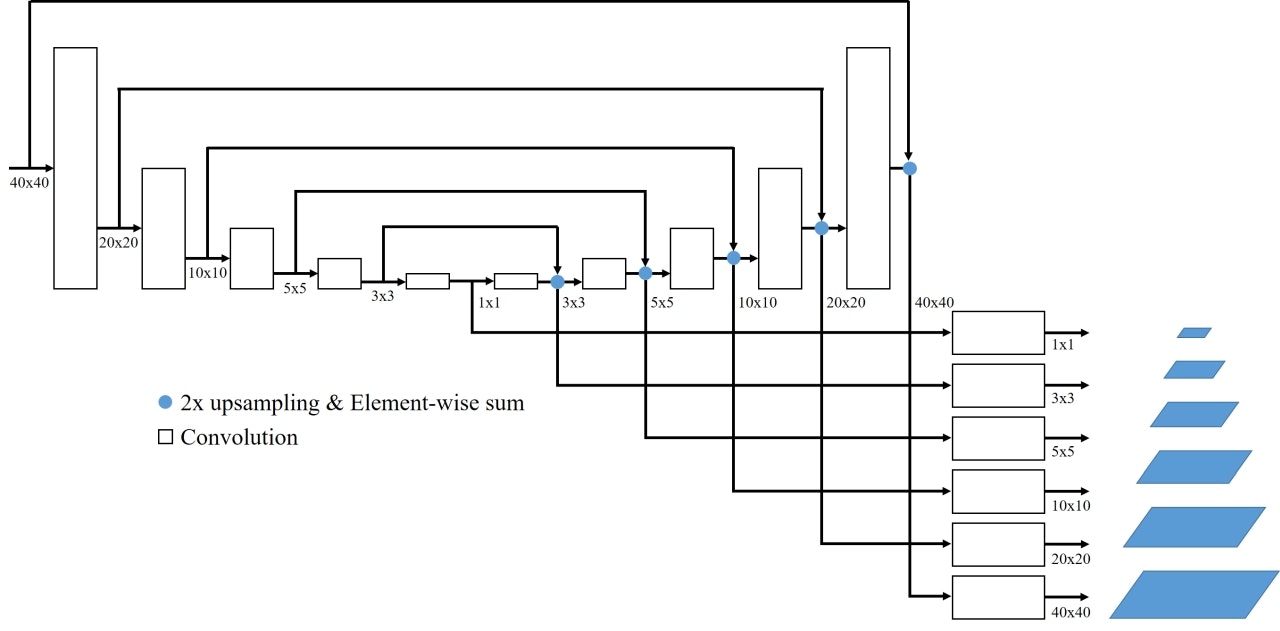
TUMはエンコーダ-デコーダ構成となっており、FFMからの出力を受け取って再度マルチスケールな特徴ピラミッドを生成します。デコーダの各レイヤからの出力をアップサンプルしたうえでエンコーダの対応するレイヤ出力と足し合わせ、さらに1x1 Convを適用してから出力します。
Feature Fusion Module v2 (FFMv2)
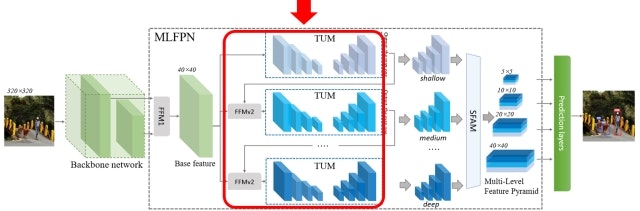
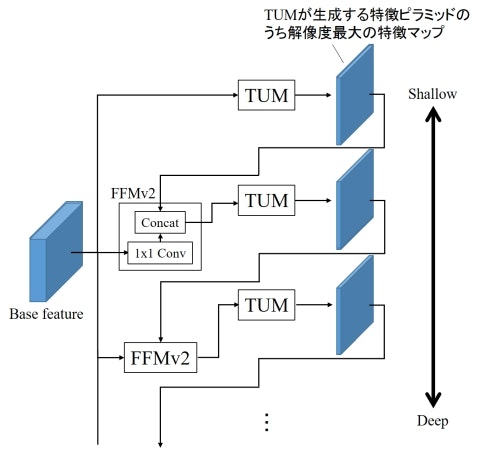
TUMは多段に接続され、その間にFFMが再び挿入されます(これをFFMv2と呼びます)。このとき、TUMが生成する特徴ピラミッドのうち、最大解像度の特徴マップだけが次のTUMの入力として利用されます。FFMv2は、このTUM出力とBase featureに1x1 Convを適用したものをConcatすることでフュージョンし、次のTUMの入力とします。スタックされたTUMのうち、初期のTUMはShallowな特徴を抽出しますが、後段に行くにつれDeepな特徴を抽出できるようになります。
Scale-wise Feature Aggregation Module (SFAM)
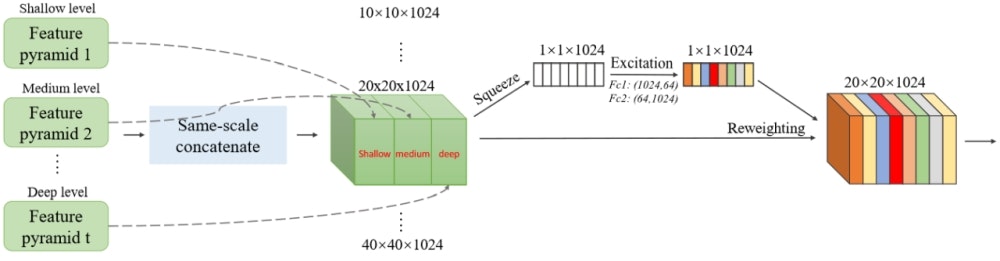
多段に接続した各TUMから得られる特徴ピラミッドを最後に統合するのがSFAMです。SFAMでは、それぞれの特徴ピラミッドから同じ解像度の特徴マップを取り出してチャネル方向にConcatし、さらにSqueeze-and-Excitation Netsで用いられているアテンション機構を導入しています。まず、各チャネルに対してGlobal average poolingを適用して各チャネルの情報を圧縮し(Squeeze)、それを2つの全結合層に通すことで各チャネルに対する重み係数に変換します(Excitation)。これを各チャネルにかけることで最終的な出力とします。
Prediction layers
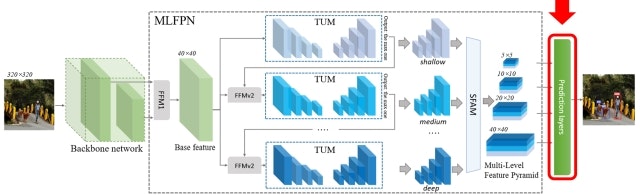
SFAMから得られる最終的な特徴ピラミッドに対し、SSD等と同様にConv層をくっつけて物体クラスの予測と物体位置の回帰を行います。特徴マップの各点に対して6種類のアンカーボックスを3種類のアスペクト比で適用し、信頼度が0.05以上となるものだけを残します。そしてSoft-NMSを適用してさらに精度を高めます。
性能評価実験
論文中ではMS COCOにおけるSOTAとの比較が示されています。以下はその結果の一部をプロットしたものです(冒頭の図と凡例が違っています、すいません)。▲印がFaster R-CNNに代表されるtwo-stage手法、●印がM2Detを含むone-stage手法です。M2Detは精度と速度の両面で他のone-stage手法を上回っており、場合によってはtwo-stage手法よりも高い精度を示しています。詳細な数値については論文中のTable 1を参照いただければと思います。
論文中では各モジュールの有無や個数でどのように性能が変わるかといったAblation studyも細かく報告されておりますので、興味がある方はそちらを参照ください。
考察
著者らが述べているM2Detにおける性能向上要因は大きく以下の2つです。
- 既存のone-stage手法ではBackboneで生成される特徴ピラミッドをそのまま使うか、あるいは数層程度のレイヤを追加しているだけに過ぎない。M2DetではFFMでBase featureを生成した後、それをさらに多段のTUMに入力することで結果的にBackboneよりも大幅にDeepかつ物体検出に適した特徴表現を獲得できる。
- SFAMで生成されるマルチレベルな特徴ピラミッドの各レベルは、複数レベルのTUMの出力を統合したものであり、これにより物体ごとの見た目の複雑さの多様性をうまく扱うことができている。
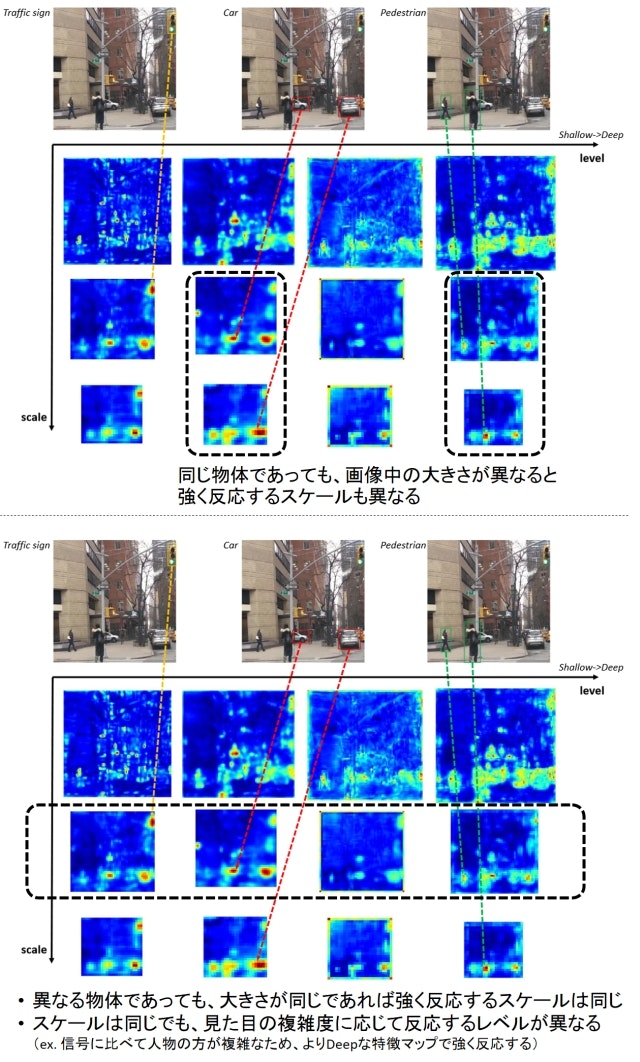
つまり、MLFPNによって物体のサイズ変化に対応するためのマルチスケールな特徴、かつ見た目の複雑さの変化に対応するためのマルチレベル(Shallow → Deep)な特徴が獲得できるということがポイントです。下図はこの様子を確認するためにM2DetのClassification Conv層のアクティベーションをスケールとレベルごとに可視化したものです。入力画像には大きさの異なる複数の人物、車が写っていますが、同じ物体でもその大きさに応じて異なるスケールで強く反応が出ています(下図上段)。一方、信号や車、人物など異なる物体であっても、その大きさがほぼ同じであれば反応するスケールは同じです(下図下段)。ただし、スケールは同じですが見た目が単純な信号機はShallowなレベルで反応が強く出ているのに対し、見た目が複雑な人物はよりDeepなレベルで強く反応しています。
まとめ
SSDやYOLOに代わる物体検出技術として有望そうなM2Detについて解説しました。論文を見る限りは精度、速度共に申し分なく、ぜひ使ってみたい技術ではあります。ただ、アーキテクチャがかなり複雑なので、なぜこれでそんなに早くなるのかはよくわかりません。実装にはPyTorchが使われているようですが、残念ながらコードはまだ公開されていません。ただ著者のGitHubページを見ると3/1にコード公開予定とのことなので、近いうちに試してみることができそうです。