One Class SVM とは
SVM : クラス分類、教師あり学習
One Class SVM :外れ値検出、教師なし学習
異常検知:異常検知とは簡単にいえば、「他に比べて変なデータを見つけ出す」タスク
(ソース: https://research.preferred.jp/2013/01/outlier/)
統数研の丸山副所長がよくおっしゃる「ビッグデータ周辺の問題の多くはサンプリングとExcelで解ける」という話が、異常検知タスクではあまり成り立たない
(ソース: https://research.preferred.jp/2013/01/outlier/)
クラス分類問題に用いられるサポートベクターマシンは教師あり学習ですが、1クラスサポートベクターマシンは教師なし学習です。したがって、外れ値検出のための教師データは不要です。
(ソース: http://sudillap.hatenablog.com/entry/2013/03/25/211257 より引用)
2 クラス判別手法である ν-SVM において全訓練パターンがクラス 1 に属し,原点を唯一の
クラス 2 に属するデータとみなして学習することと同じ
(ソース: https://www.sk.tsukuba.ac.jp/SSE/degree/2007/thesis/200620812.pdf)
SVM
"SVMはパーセプトロンに「カーネル関数」と「マージン最大化」を加えたもの"
ソース: http://d.hatena.ne.jp/echizen_tm/20110627/1309188711
パーセプトロン
パーセプトロン=線形識別器の基礎
ソース:http://www.slideshare.net/takashijozaki1/simple-perceptron-by-tjo
パーセプトロン perceptron とはローゼンブラット (Rosenblatt, 1958) に よって提案された図 1 のような 3 層の階層型ネットワークモデルである。パーセプトロンはマッカロック・ピッツの形式ニューロンを用いて学習則にヘッブ 則を使ったモデルで、単純な認識能力を獲得することができる。
ソース:http://www.cis.twcu.ac.jp/~asakawa/waseda2002/perceptron.pdf
カーネル関数
機械学習で用いられる手法で、入力空間のベクトルをいい感じの特徴空間のベクトルに変換してくれます。
ソース: http://qiita.com/sergeant-wizard/items/c5f79adefe5016f4740e
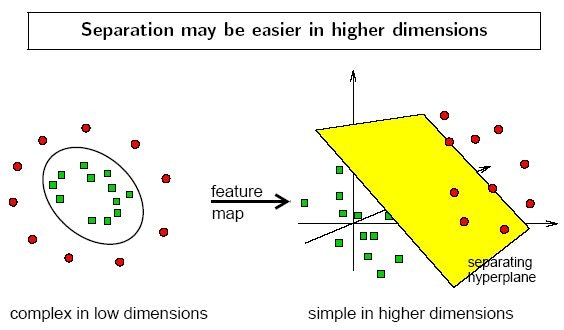
ソース: https://www.dtreg.com/solution/view/20
カーネル関数の選択は?
もちろんデータセットに応じて最適なカーネル関数は異なると思いますが、ガウシアンカーネルを用いればまず間違いありません。事前に決めなければならないパラメータの数も一つと少ない方ですし、変数間の非線形性も考慮できます。
ソース:http://univprof.com/archives/16-06-03-3678374.html
マージン最大化
SVMでは,学習データの中で最も他クラスと近い位置にいるもの(これをサポートベクトルと呼ぶ)を基準として,そのユークリッド距離が最も大きくなるような位置に識別境界を設定する.つまり,クラスの最端から他クラスまでのマージンを最大にするようにするのだ.これがマージン最大化と呼ばれるものである.
ソース:http://www.neuro.sfc.keio.ac.jp/~masato/study/SVM/SVM_1.htm
One Class SVM
パラメータ (1)
SVM を利用した外れ値検知手法。カーネルを使って特徴空間に写像、元空間上で孤立した点は、特徴空間では原点付近に分布。Kernelはデフォルトのrbfで、異常データの割合を決めるnu(0~1の範囲、def.= 0.5)を変更してみる。
ソース: http://qiita.com/SE96UoC5AfUt7uY/items/88006646179adf68cb95
パラメータ (2)
ところで、1クラスサポートベクターマシンには次に述べる2つのパラメータがあり、それらをユーザーが指定する必要があります。
σ : カーネルにRBF(radial basis function)を用いているため。
ν : 1クラスサポートベクターマシンはνサポートベクターマシンにもとづいています。νによりデータに占める外れ値の割合の上限を指定できます。
ソース:http://sudillap.hatenablog.com/entry/2013/03/25/211257
実装
Python (Scikit-learn) を使った場合
outliers_fraction = 0.05 # 全標本数のうち、異常データの割合
...
clf = svm.OneClassSVM(nu=nu, kernel="rbf", gamma='auto') # 異常データの割合を決めるnu(0~1の範囲、def.= 0.5)
clf.fit(X)
y_pred = clf.decision_function(X).ravel() # 各データの超平面との距離、ravel()で配列を1D化
threshold = stats.scoreatpercentile(y_pred, 100 * outliers_fraction) # パーセンタイルで異常判定の閾値設定
ソース:http://qiita.com/SE96UoC5AfUt7uY/items/88006646179adf68cb95
参照、参考、Special Thanks
One Class SVM
https://research.preferred.jp/2013/01/outlier/
http://sudillap.hatenablog.com/entry/2013/03/25/211257
http://qiita.com/SE96UoC5AfUt7uY/items/88006646179adf68cb95
https://www.sk.tsukuba.ac.jp/SSE/degree/2007/thesis/200620812.pdf
http://www.outlier-analytics.org/odd13kdd/papers/slides_amer,goldstein,abdennadher.pdf
http://univprof.com/archives/16-06-03-3678374.html
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.39.9421&rep=rep1&type=pdf
(これがOCSVMを最初に提案した論文のようです)
SVM
http://www.slideshare.net/ShinyaShimizu/ss-11623505
http://www.neuro.sfc.keio.ac.jp/~masato/study/SVM/SVM_3_2.htm
http://d.hatena.ne.jp/echizen_tm/20110627/1309188711
http://www.neuro.sfc.keio.ac.jp/~masato/study/SVM/SVM_1.htm
機械学習以外も含めた外れ値検出の概要
その他
http://www.slideshare.net/takashijozaki1/simple-perceptron-by-tjo
http://www.cis.twcu.ac.jp/~asakawa/waseda2002/perceptron.pdf