はじめに
ハンス・ロスリングさんの著書「[FACTFULNESS(ファクトフルネス) 10の思い込みを乗り越え、データを基に世界を正しく見る習慣][1]」に触発されて、データ(書籍出版数)からAI関連キーワードのトレンドを見てみました。
[1]:https://www.amazon.co.jp/gp/product/4822289605
トレンド1
「人工知能」、「機械学習」、「IoT」といったビッグキーワードは2017年をピークに2018年は微減しています。それに対して「深層学習(ディープラーニング含む)」、「Python」といったもう少し技術よりのキーワードは2018年も継続して増加しています。
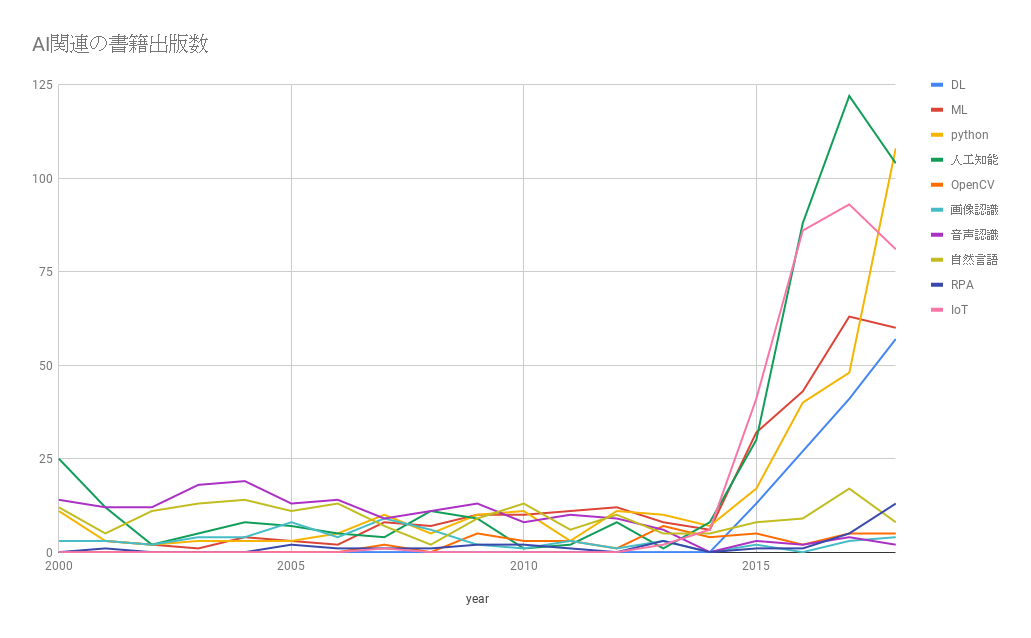
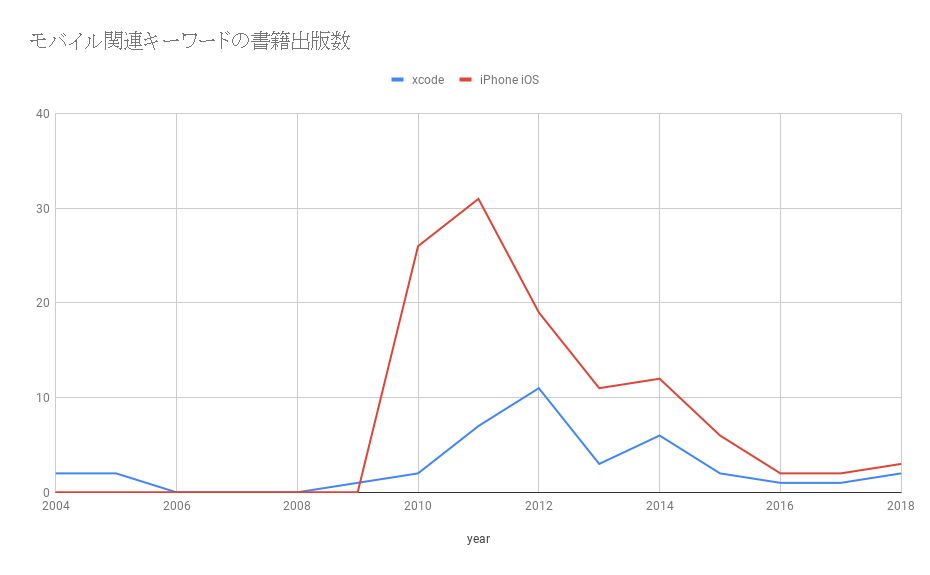
モバイルのトレンドでも、ビッグキーワードに少し遅れて、技術よりのキーワードのピークが来る傾向にありました。世の中で騒がれ始めたタイミングで開発が本格化するため、技術よりの書籍のピークが少しずれているように思います。
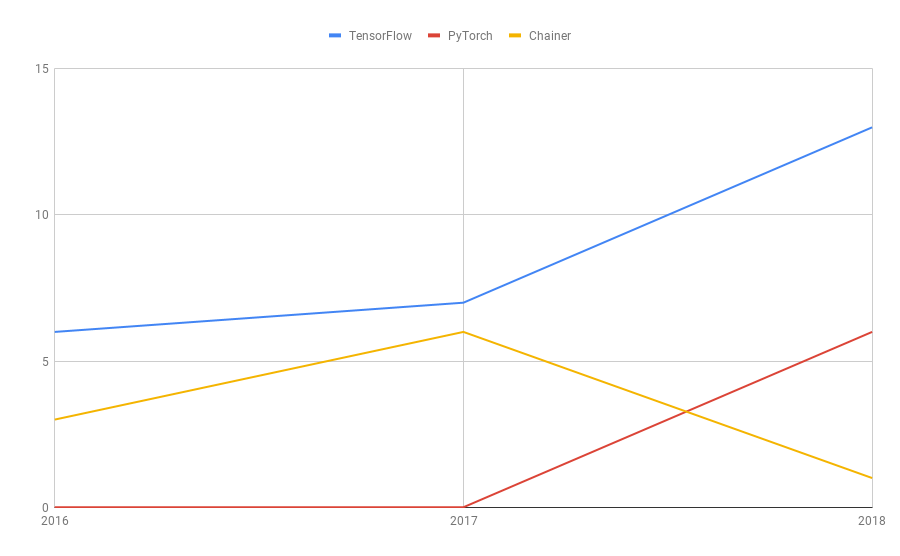
トレンド2
深層学習のフレームワークを比較してみました。2017年には「Chainer」と「TensorFlow」が互角でしたが、2018年はくっきりと明暗が分かれてしまいました。Chainerは国産フレームワークで、ネットで十分情報があるため、書籍のニーズが少なかった可能性が考えられます。PyTorchが2018年に伸びているのが予想外でした。あまり使われている印象が無いので。
書籍情報の取得方法
「国会図書館サーチ API で書籍情報をまとめて取得」を参考にさせていただきました。
一点だけ、注意点としては、出版年月日の「from」パラメータは年だけを指定する必要があります。国会図書館の外部提供インタフェース(API)からダウンロードできる仕様書にこんな記載があります。
なお、 「年月(YYYY-MM)」「年月日(YYYY-MM-DD」の指定時は、指定の粒度未満の出版 年を持つ書誌はヒットしない。(例えば、1999-01~2000-12(YYYY-MM 形式)と指定 した場合、出版年に 1999-12(YYYY-MM 形式)や 2000-01-01(YYYY-MM-DD 形式) を持つ書誌はヒットするが、1999 や 2000(YYYY 形式)の書誌などはヒットしない。)
おわりに
書籍出版数からトレンドを調べてみました。書籍以外にも、論文数や特許出願数などからもトレンドを把握できるかトライしてみたいと思います。