何を書いた記事か
こんにちは。
みなさん、自分たちのシステムで使ってる製品・サービスの寿命(EOL)管理してますか?
大抵の場合気づいたころにはEOL迎えてたものが大量にあって何から手をつけたら・・という状態になっているのではないかと思います。
僕もそうだったので、今回大量の寿命切れに直面したときにどのように対応していくか、自分なりに考えたことをまとめていきます。
なぜEOL対応するのか
そもそもEOLとは
そのそも、EOLって何でしょうか。
EOLとは「End of Life」のことで、読んで字の如く、「寿命切れ」です。
(似た言葉にEOSやEOSLがありますが、ここではだいたい同じ意味として、代表的なEOLに記載を統一します。)
じゃあなんの寿命切れか、と言われたら、__いろいろ__です。
システムを構成するのに、全て自分たちで1からフルスクラッチで作ることは現代においてありえなくて、何かしらのOSSや製品を組み合わせてシステムを組み上げているはずです。
そこで登場する、インフラ基盤・OS・MW・言語・Framework・Library・Plugin・SW、、、、の全てに寿命があります。
EOL対応の目的
では寿命を超えたものを使い続けるとどんなリスクがあるのでしょうか。
寿命を超えた、と言っても、いわゆる命が無くなったものと違って、基本的にはそのまま使い続けることができます。
サポート終了したWindows7だって、きっとどこかで現役で働いているものがたくさんあると思います。
じゃあ別にEOL超えても別にいいじゃん、と言えるかと言うと、そうでもありません。
一般的に大きなリスクとして下記が考えられます。
- セキュリティリスク
- 古いバージョンのソフトウェアなどを利用し続けると、そのバージョンに脆弱性が発覚した際にセキュリティパッチが提供されず、攻撃の対象となるリスクがあります
- 障害リスク
- 何かしらの重大なバグを踏んでしまった時に復旧させることができず、システムの長期停止を引き起こしてしまうリスクがあります
他にも、新しいライブラリを使えず開発生産性が上がらないとか、パフォーマンス改善できないとか、寿命切れの製品・サービスを使い続けることはいろんな問題が起こりえます。
どうやってEOL対応するのか
何も考えずに片っ端から対応はお勧めしない
じゃあEOL迎えたものは片っ端から対応していけばいいのか!というと、そう言うわけにも行きません。
現実の開発現場はEOL対応のために人や予算を潤沢に抱えている訳ではなく、ビジネスにプラスの付加価値をもたらさないEOL対応は往々にして投資対象となりづらいものです。
なので、__ほんとうに必要なものに対して、最小限の工数で対応__しにいくことが求められます。
また、バージョンは相互依存するものです。
例えばFrameworkのバージョンは言語のバージョンと切り離して考えることはできないし、MWのバージョンはOSのバージョンに依存して選択できる幅が決まります。
どことどこに依存関係があって、どういう順番で対応していくのか、全体像を描いてからでないと、効率的に対応していくことはできません。
そこで、僕なりに考えたEOL対応のフレームワーク・考え方について紹介しようと思います。
戦略的対応フレームワーク
現状の把握
まず最初に何よりも必要なのは、今プロダクトが使っている製品・サービスのバージョンを一覧化して、それぞれのEOL時期を確認することです。
構成管理の中で常に管理されていることが理想ですが、現実的にはそうもいかないと思います。
なので、数人で集中して、今プロダクトが使っている製品・サービスをリストアップし、バージョンを調べ、それぞれのEOL時期を調査してリスト化していくのが最初に必要な作業となります。
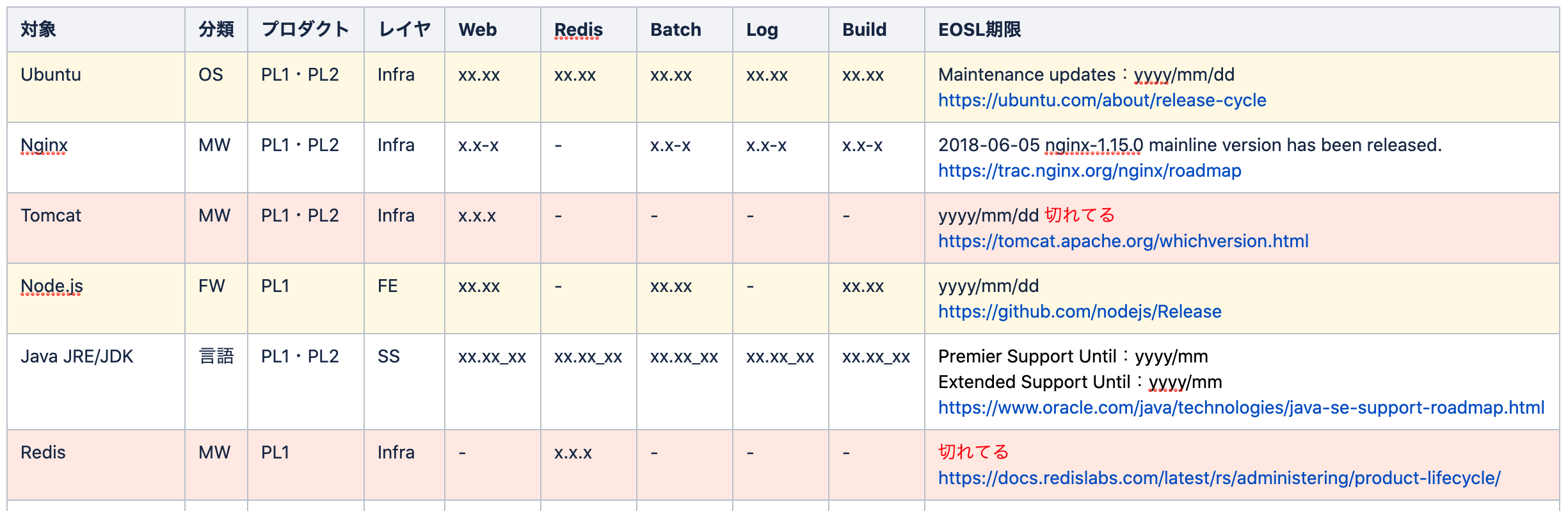
(内容は適当)
EOLの時期を調べるのには下記のページを参考にしました。
https://qiita.com/witchcraze/items/af8ac5da5948ff6a609e
2軸整理・3軸整理
つぎにやるのが、リスト化した製品・サービスの中で、すでにEOLを迎えている、あるいは1年以内にEOLを迎えるものを抽出することです。
この時点で片手で数えるほどしか残らなかったあなたはラッキーです。考えることが少ないので。
20~30残ってしまうと、かたっぱしから全て対応というわけにもいかないと思うので、何かしらクラスタリングして整理する必要があります。
そこで、対象の製品・サービスを下記の3軸でランク付けして整理してみましょう。
- 対応負荷
- セキュリティ影響
- 障害影響
(2と3をまとめてシステム影響としてもいいと思います)

(内容は適当)
具体的には、
__対応負荷__は、その製品・サービスをアップデート対応するのにかかるざっくり工数です。
例えば、プラグイン一つのバージョンをあげるのであれば大した負荷はかからないですが、インフラ基盤丸ごとリプレイスとなると、大事です。
そう言った対応に対する大変さを、1〜5段階で評価します。
__セキュリティ影響__は、その製品・サービスが攻撃された時のセキュリティ上の影響度合いを指します。
例えば、完全にバックエンドに存在するデータベースやログ基盤などは、表から攻撃されるリスクは低いですが、一番手前でリクエストを処理するNginxなどは攻撃対象となるリスクはそれなりにあります。
システム導線においてフロントからどれくらいの距離にあるか、などで同様に1〜5段階で評価します。
__障害影響__は、その製品・サービスが停止したときにシステム全体に与える影響度合いを指します。
例えば、データベースは止まったらシステムは即死に等しいですが、ログ基盤やサブシステムなどは止まってもシステム全体にはそこまでの影響を与えません。
コア機能からの距離などを同様に1〜5段階で評価します。
これで各製品・サービスについて大枠の評価ができたので、この数値をもとに、下記のような図にプロットしていきます。
(僕はセキュリティ影響と障害影響に関しては平均を取ってシステム影響としています。これは担当するプロダクトによってどう評価すべきか議論するのがいいと思います。)

(内容は適当)
Zone毎の対応方針検討
それぞれのZoneに分かれることで、なんとなく、どういう対応をすればいいのかが見えてきたと思います。
さらにもう一歩踏み込んで、各Zoneごとにどう対応するべきかについて検討していきましょう。
これは一例ですが、僕は次のように評価し、合意を取りました。

特筆すべきはZone2でしょうか。
対応負荷が高いのに影響がほとんどないようなものは、思い切って対応しない選択肢も取れると思います。
個別の対応方針検討
ここまできて、ようやく個別の製品・サービスに対して具体的にどのバージョンにあげるか、などの検討をしていきます。
対応優先度が高いものから順番に、最新バージョンにするのか、Stableで実績のあるバージョンを選択するのか、検討していきます。
このバージョン選定は個別だけで考えるのではなく、そのバージョンにおけるシステム要件を確認してください。
例えば、Ubuntu18.04以降しか対応していないようなMWのバージョンを選択する場合は、OSのバージョンがUbuntu18.04以降である必要があります。
すこしパズルが必要ですが、選択するバージョンと依存関係のあるシステム要件に齟齬が生まれないように丁寧にバージョン検討していきましょう。
ただ、あまりにも塩漬けされていたシステムでもない限り、バージョン依存によって対応すべき対象が芋づる式に増えるようなことは基本的にないと思います…
対応実施
ようやく全体の対応方針が決まったので、あとは計画を立てて対応していくのみです。
実際にはポイントポイントで決裁が必要だったり、他チームの手を借りるための調整が必要だったりします。
調整ごとは面倒に感じますが、ここまでEOL対応に対してブレイクダウンして、目的ベースで整理できていたらそこまで難航することはないと思います。(自分に言い聞かせている)
まとめ
EOL対応における僕なりの戦略の立て方を、フレームワークという形でまとめてみました。
本当に大変なのは、この戦略を立てた後の対応実行部分です。
少しでも効率的にEOL対応を実行できるための計画作りの一助になれば嬉しいなと思って寄稿しました。誰かの参考になることを願っています。