『AIは短歌をどう詠むか』(講談社 (2024/6/20))という、とても面白い本を読んだ。
https://amzn.asia/d/4Uwobm7
私自信も生成AIまわりのことを生業にしていて、しかも短歌を趣味にしているため、まさにドンピシャな内容だった。(さらに著者の方は人文系分野に興味を持ちつつ大学まで応用数学を研究され、社会に出てから技術系に進んだという経歴も私と一致している...。)
この本の著者のプロジェクトでは実際にAIに短歌の定型を満たした詩を詠ませるところまでを実現し、そこから進んで「面白い」歌とは何かというところまで探究している。
この本には感銘を受けたので、私も少し目的を変えつつ、AIに短歌を詠ませることができるかを試してみた。
また、この本での研究についての以下の論文も適宜参照した。
目的
私の作風のような短歌を出力してくれるAIを作ることを大目標にする。(上記の「モーラを考慮したFine-tuningによる口語短歌生成」では、約5,000件の学習データがあれば特定の歌人のような歌を詠んでくれる可能性を示唆している)
また、そのAIを気軽に自分のPCで普段使いできるようにするために、CPUで現実的な時間で返してくれるようにする。
ちなみにChatGPTはすでに短歌を詠む能力を備えている。

しかしこれは自分らしい歌ではない。
OpenAIのAPI経由でOpenAIの高性能なGPTモデルをファインチューニングするという手段もあるが、それだと自分でコントロールできている感が薄いのでやはりローカルで自分のLLMがほしい。
学習データの用意
自分の短歌のデータセットを文字起こししたりするのが大変なので、まずは過去の歌人たちの短歌をデータセットにしてみて、どれくらいの精度が得られるのか検証してみる。
「近代短歌データベース」から死後50年が経過して著作権の切れた短歌を110,460件取得した。
さらに情景に対して短歌を詠むということを想定して、取得した短歌からOpenAIのgpt-4oを使い、110,460件の短歌にそれぞれ情景を付与した。
出来上がったデータセットは以下のようなイメージである。
このデータセットを使って指示チューニングをしていく。
| 情景 | 短歌 |
|---|---|
| 大河の岸辺で、梅雨の雨が降り、風が強く吹いている。 | から梅雨の風吹きわたり大河の波の騒立ち閃けるかも |
| 海岸の小さな港に停泊している小さな漁船が、夕立の雨の中にうかべている。 | 夕映えのひかりうち乱れ潮疾し船子がおらびのいらだたしかも |
| 海岸で潮が満ち満たされて、潮汐が高くなっている。 | 満ち潮のしほのあしはやみ船と船と触れなむとしてまた事もなし |
具体的には
[SEP]
### 指示:
与えられた情景に対して短歌を一つ作成してください。[情景]:「大河の岸辺で、梅雨の雨が降り、風が強く吹いている。」[/SEP]
### 応答:
から梅雨の風吹きわたり大河の波の騒立ち閃けるかも<|endoftext|>
というインプット形式にしてモデルの学習に使う。
ちなみに先述の論文『RLHFを用いた「面白い」短歌の自動生成の試み』では、Wikipediaの記事から偶然に5・7・5・7・7の短歌の定型を満たしているチャンクを抜き出してきてデータセットを構成し、それで短歌が定型を満たすように学習をかけていた。
今回の私が作ったデータセットは本物の短歌だが、字余りや字足らずの破調の歌が混じっているため、少し学習が難しくなった可能性はある。
学習するモデルの選定
色々とLLMモデルを使ってみて使い勝手などを比較してみたが、最終的にはmicrosoft/Phi-3.5-mini-instructを利用することにした。
このモデルを選んだ理由としては、モデルサイズが小さく(3.8B)てサクサク動くにも関わらず、元々の精度もそれなりに良いということである。
後々に私のそこまでスペックのないローカルPCで動かすことを考えると、モデルが軽量であることは非常にありがたい。
それとLLMがデコーダだけから構成されている必要があった。というのも、ローカルPCのCPUで推論してもらう時に使うllama.cppのLlamaクラスはデコーダしかサポートしていないようだったからである。(→https://github.com/ggerganov/llama.cpp/issues/5763)
実際にエンコーダ-デコーダ構成のT5モデルで試してみたらLlamaクラスのインスタンス化の時点で失敗してしまった。
確かに短歌の生成というタスクを考えると、前のトークンをみていって次々にトークンを生成するデコーダが相応しい気もする。
他はelyza/Llama-3-ELYZA-JP-8Bやcyberagent/calm3-22b-chatのような日本語のLLMモデルも試してみた(いずれもデコーダのみの構成)。確かに精度は高そうだったが、やはり重すぎたので今回は使わないことにした。
学習前のモデル(microsoft/Phi-3.5-mini-instruct)の元々の精度
以下の通り、学習前のモデルでは短歌の定型を満たした出力ができておらず、
「暑すぎる夏は情緒がないから早く終わってほしい。」という情景に対して、
「夏の熱さに沈め、情緒の薄さ、
涼しい瞬間求める心、
早く終わり、穏やかな秋の訪れを。」
という出力をしてしまっている。
しかもその後に勝手に指示文を作ってしまってもいる。
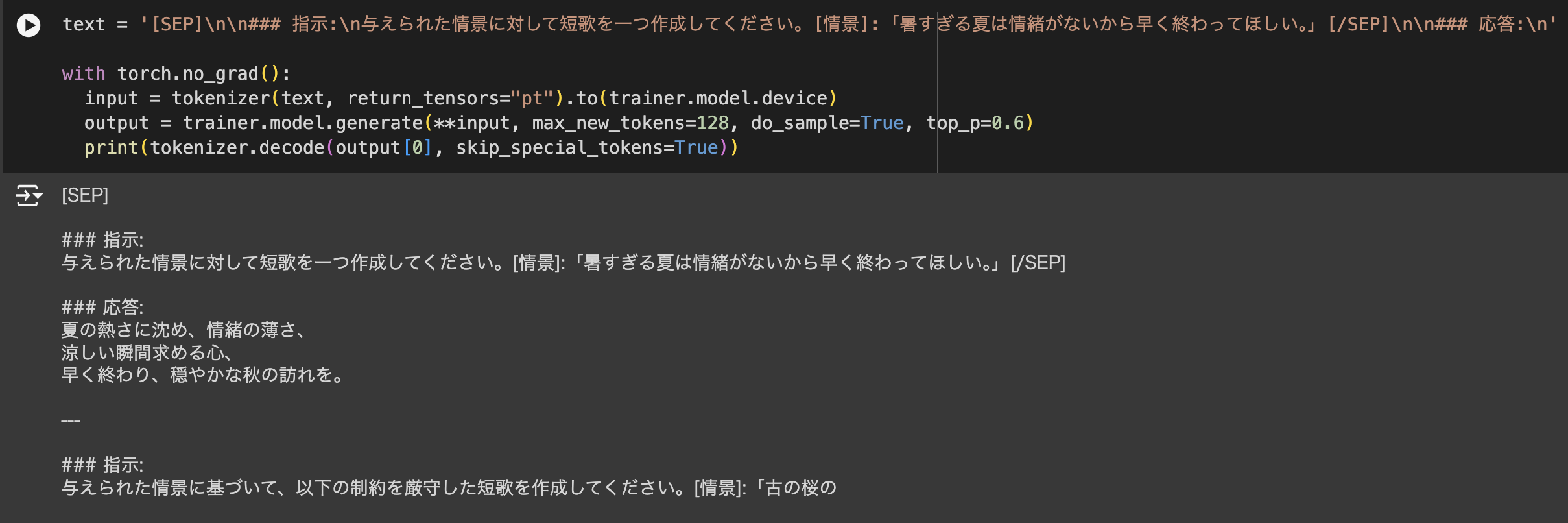
元々のモデルは短歌についての理解がうまくできていないようだ。
モデルの学習
学習はGoogle Colaboratoryで行った。
なお今回はメモリに余裕があったため4bitではなく8bitで量子化して学習した。
余談だが、量子化しなくてもとにかく学習が動いたのは驚いた。すごいな、Phi-3.5。(もっとも、時間がかかりすぎるため使い物にはならないが)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments
from trl import DataCollatorForCompletionOnlyLM, SFTTrainer
from peft import get_peft_model, LoraConfig
# Phi3のデコーダーモデルとトークナイザーをロード
model_name = "microsoft/Phi-3.5-mini-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.model_max_length = 2048
tokenizer.pad_token = tokenizer.unk_token
tokenizer.pad_token_id = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)
tokenizer.padding_side = 'right'
# 量子化パラメータ
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_8bit_quant_type="nf4",
bnb_8bit_compute_dtype=torch.float16,
bnb_8bit_use_double_quant=False,
)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=bnb_config)
model.config.use_cache = False
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"[SEP]\n\n### 指示:\n{example['instruction'][i]}[/SEP]\n\n### 応答:\n{example['output'][i]}<|endoftext|>"
output_texts.append(text)
return output_texts
# 「### 応答:\n」以降の部分だけを損失計算の対象にする。
response_template = "### 応答:\n"
collator = DataCollatorForCompletionOnlyLM(tokenizer.encode(response_template, add_special_tokens = False)[2:], tokenizer=tokenizer)
# Loraを適用するモジュール (モデル構成の線形層)
target_modules = ["o_proj","qkv_proj","gate_up_proj","down_proj","lm_head"]
# LoraConfigの設定
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=target_modules,
task_type="CAUSAL_LM"
args = TrainingArguments(
output_dir=f"/content/gdrive/MyDrive/study/Tanka_models/fine_tuned_phi3.5",
num_train_epochs=3,
gradient_accumulation_steps=8,
per_device_train_batch_size=4,
save_strategy="no",
logging_steps=10,
lr_scheduler_type="constant",
save_total_limit=1,
fp16=True,
)
trainer = SFTTrainer(
model,
args=args,
train_dataset=train_dataset,
formatting_func=formatting_prompts_func,
max_seq_length=1024,
data_collator=collator,
peft_config=peft_config,
)
# 学習の実行
trainer.train()
学習後のモデルの精度
100AのGPUで学習をかけておよそ10時間くらいで学習が完了した。
だいぶそれらしいものが生成されるようになった。
「暑すぎる夏は情緒がないから早く終わってほしい。」という情景に対して、
「この夏は熱いたきにかあらぬからはやも終りてあらん情緖なし」
という(破調だしちょっと意味がわからないが)短歌を詠むことができている。

まあ最もモデルは必ずしも短歌の形式に合った生成をしてくれるとは限らない。
その時はMeCabで生成した結果をパースして7・7・5・7・7の31音になっているかどうかチェックして、31音になるまで生成をやり直させれば良いだろう。
論文の方ではここからさらにRLHFを行い、生成した短歌の面白さを報酬にする強化学習をやっている。
その「面白さ」を私自身で評価してますます自分好みのLLMに仕上げられたら良いなと思ったが、それはまたの機会にする。
LLMをCPUで動かす
ここまでの学習は仕方なくGPUを使っていたが、推論はCPUだけでやっていきたい。
LLMモデルをCPUで動かすのは、先ほども少しだけ触れたLlama.cppを使った。
Llama.cppでLLMモデルをCPUで推論させるのにはggufというフォーマットのファイルが必要である。
学習する前のmicrosoft/Phi-3.5-mini-instructのggufファイルはここで公開されていたのでそれをそのまま使った。
ファインチューニングしたモデルは自分でggufファイルに変換した。
その時も割と苦労したが、それは前の記事で書いた。
デモアプリの作成
ここまでの学習モデルを使って、情景を入力して短歌を生成するアプリをStreamlitで簡単に作成し、Hugging Face Spacesで公開した。
https://huggingface.co/spaces/kyotoman/TankaGhostWriter
とは言ってもまだまだ課題点はたくさんあり、あくまでデモ版といった感じだ。
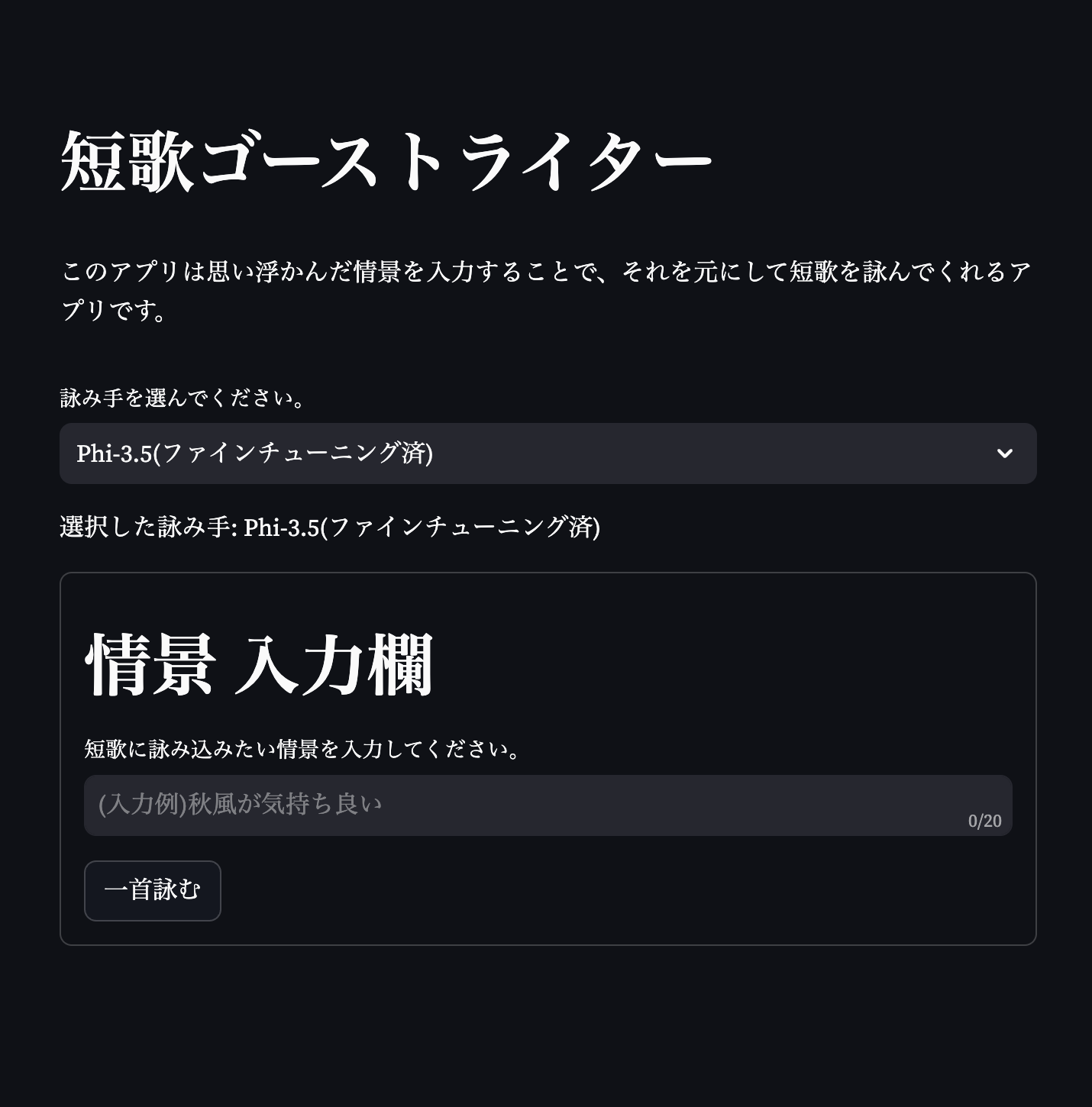
推論速度が遅すぎる!
推論の仕組みとしては、先述したように生成した短歌のモーラ数(音の数と思ってほしい)を数えて、それは30~32音(破調の歌を考慮)でなかったら推論を3回までやり直すようにしている。
ローカルでサーバーを立てて開発していた時にはせいぜい10秒足らずで結果が返ってきたのに、Hugging Face Spacesのサーバーでは1分以上かかっている印象だ。
先ほど、私のローカルPCはそこまでスペックは高くないと申し上げたが、それでもM1 Macである。それに対してHugging Face Spacesの環境は完全無料版のものを使っている。
この環境差が推論速度の差を起こしているか。
大人しくGPUのサーバーを借りれば良いのかもしれないが、1ヶ月で4万円以上する計算になったからそれはちょっと無理そう。
LLMの実行速度を上げるためにまず思い浮かぶのはvLLMだが、よく調べてみるとあれはバッチ推論を効率よく行うためのものだった。今回のような一件のプロンプトとその回答を得るタスクでは意味がなさそう。そもそも何よりGPUが使えないからvLLMも使えない...。
LLMのinputとoutputを短くすることでも推論の速度を上げることができる。
ここでoutputはわずか31音の短歌だけだからこれ以上は短くできない。
inputも指示文を少し削ることができるかな?くらいであって劇的には短くできなさそう。
そうなると考えうるのは、さらにモデルの精度を上げて、モーラ数の制約を違反した場合の再推論を起きないようにするしかない!
短歌の定型についての精度を上げる
論文「モーラを考慮したFine-tuningによる口語短歌生成」で、モーラ数を考慮してファインチューニングを行う手法が示されていたので、それを参考にして実装を行ってみた。
実装は面倒だがアイデアは比較的シンプルである。
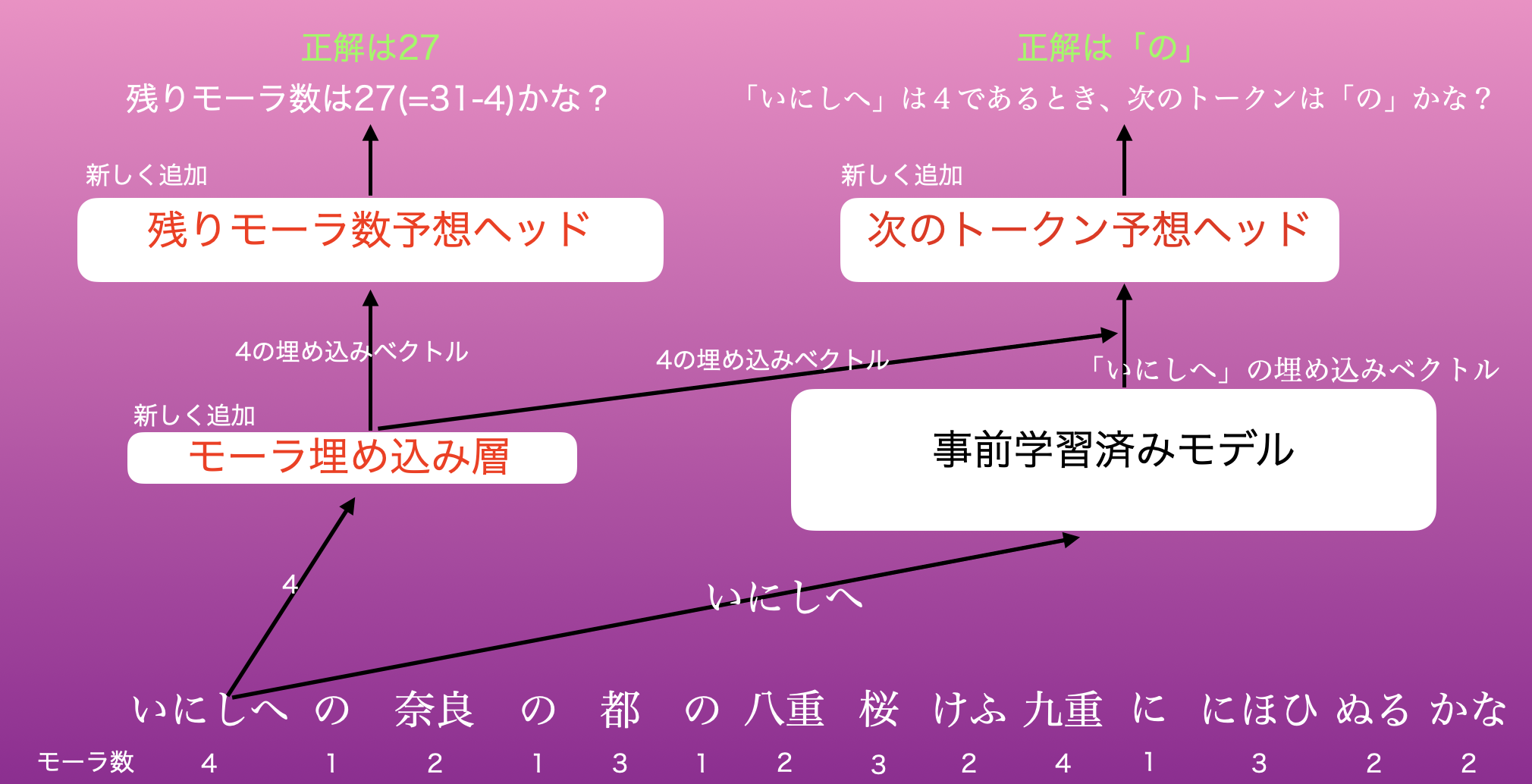
①まず、短歌を構成するトークンのモーラ数に注目する。
繰り返しになるがモーラ数とは、音の数だと思ってほしい。(例えば、「あ」は1モーラで、「ちゃ」も1音、「キー」は2モーラ、「バット」は3モーラである)
②このトークンをLLMモデルに渡すが、ここでLLMモデルを拡張して受け取ったトークンのモーラ数も埋め込むことができるようにモデルを拡張する。
③トークンのモーラ数を埋め込むための新しい層と、トークン自身を埋め込む既存の層の二つからそれぞれ出力された埋め込みベクトルを結合し、それをヘッド(LMHeadと呼ぶ)から出力して損失計算を行う。ここでは次のトークンを正解させることを考え、損失関数はクロスエントロピーロス$CE_{token}$とする。
④トークンのモーラ数を埋め込むための新しい層から得られた埋め込みベクトルを、それ専用のヘッド(MoraHeadと呼ぶ)から出力して損失計算を行う。ここでは残りモーラ数を正解することを考え、損失関数はクロスエントロピーロス$CE_{mora}$とする。
⑤$CE_{token}$と$CE_{mora}$の重み付き平均をモデル全体としての損失関数とする。
モーラ数を明示的に考慮するような拡張モデルのイメージは以下のようになる。
具体的な実装は以下のようになった。
論文には実装方法の詳細は載っていなかったが、大体同じような感じだと思う。
(実装にはかなり苦労しており、FIXMEやNOTEの部分をご覧の通り、まだ直す必要がある)
class MoraEmbeddingLayer(nn.Module):
def __init__(self, mora_dim:int, max_mora:int=50):
super(MoraEmbeddingLayer, self).__init__()
# モーラ数(最大 max_mora)に対応する埋め込み層を作成
self.mora_embedding = nn.Embedding(max_mora, mora_dim)
def forward(self, mora_ids):
# モーラIDをモーラ埋め込みベクトルに変換
mora_embeddings = self.mora_embedding(mora_ids)
return mora_embeddings
class TankaModelWithMora(nn.Module):
def __init__(self,
model_name: str='microsoft/Phi-3.5-mini-instruct',
mora_dim: int=8,
hidden_size: int=768,
mora_embedding_size: int=32,
loss_fn: Callable = None):
super(TankaModelWithMora, self).__init__()
# 事前学習済みモデルの設定の読み込み
self.config = AutoConfig.from_pretrained(model_name)
# 事前学習済みのデコーダーモデル
self.base_model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True, device_map="auto")
# トークナイザの設定
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
# モーラ埋め込み層を追加
self.mora_embedding_layer = MoraEmbeddingLayer(mora_dim)
# モーラ数の埋め込みとデコーダ出力を結合する層(量子化)
self.mora_fc = bnb.nn.Linear8bitLt(
self.base_model.config.hidden_size + mora_dim,
self.base_model.config.hidden_size
)
# デコーダ出力とモーラ埋め込みを結合し、次のトークンを予測するヘッド(LMHead)(量子化)
self.lm_head = bnb.nn.Linear8bitLt(self.base_model.config.hidden_size, self.base_model.config.vocab_size)
# 残りのモーラ数を予測するヘッド(MoraHead)(量子化)
self.mora_head = bnb.nn.Linear8bitLt(mora_dim, 50) # FIXME:0-35モーラの範囲(仮にすべての句で字余りなら35モーラまでいく)
# 損失関数の設定
self.loss_fn = loss_fn
def forward(self,
input_ids:torch.Tensor,
mora_ids:torch.Tensor=None,
input_labels:torch.Tensor=None,
mora_labels:torch.Tensor=None,
attention_mask=None,
**kwargs):
# デコーダの出力を取得
outputs = self.base_model(input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=True)
# hidden_states = outputs.last_hidden_state
hidden_states = outputs.hidden_states[-1]
# モーラ埋め込みを取得し、デコーダ出力と結合
mora_embeddings = self.mora_embedding_layer(mora_ids)
combined = torch.cat([hidden_states, mora_embeddings], dim=-1) # (batch_size, seq_len, hidden_size + mora_dim)
combined = self.mora_fc(combined)
# 次のトークンの予測(LMHead)
lm_logits = self.lm_head(combined) # (batch_size, seq_len, vocab_size)
# 残りのモーラ数の予測(MoraHead)
mora_logits = self.mora_head(mora_embeddings) # (batch_size, seq_len)
loss=None
if self.loss_fn is not None:
loss = self.loss_fn(self.base_model, lm_logits, mora_logits, input_labels, mora_labels, tokenizer)
return loss, (lm_logits, mora_logits)
def prepare_inputs_for_generation(self, input_ids: torch.Tensor, **kwargs):
"""
# NOTE: このメソッドがないとモデルにprepare_inputs_for_generationがないという旨のエラーが出る。
Implement in subclasses of :class:`~transformers.PreTrainedModel` for custom behavior to prepare inputs in the
generate method.
"""
pass
# 損失関数の定義
def compute_loss(base_model:nn.Module,
lm_logits:torch.Tensor,
mora_logits:torch.Tensor,
lm_labels:torch.Tensor,
mora_labels:torch.Tensor,
tokenizer:AutoTokenizer,
lm_weight:float=0.5,
mora_weight:float=0.5):
# LMHeadのクロスエントロピー損失
lm_loss = F.cross_entropy(lm_logits.view(-1, base_model.config.vocab_size), lm_labels.view(-1), ignore_index=tokenizer.pad_token_id)
# MORAHeadのクロスエントロピー損失
mora_loss = F.cross_entropy(mora_logits.view(-1, 50), mora_labels.view(-1), ignore_index=32)
# 両方の損失を重み付きで平均化
total_loss = lm_weight * lm_loss + mora_weight * mora_loss
return total_loss
普段、ファインチューニングをするときはモデルの拡張などはせず、お膳立てされた出来合いのものをそのまま量子化したりしていた。
そのような時は、モデルのインスタンス化のときに量子化の設定クラスを引数に渡すだけでモデルができていたから楽(quantization_config=bnb_configみたいな感じ)だが、今回のような自分で作ったモデルの量子化は少し大変だった。
つまずき
上記の拡張モデルを実装して、短歌データの他に各短歌のモーラ数の情報もあらかじめ計算しておいたデータセットを作って、それで学習をかけることができるところまで確認できた。
データセットのイメージとしては以下のような感じである。
「モーラ」データは、短歌をトークンごとに分解した時のそのトークンのモーラ数を羅列している。
| 短歌 | モーラ |
|---|---|
| から梅雨の風吹きわたり大河の波の騒立ち閃けるかも | [2, 2, 1, 2, 2,...] |
| 夕映えのひかりうち乱れ潮疾し船子がおらびのいらだたしかも | [2, 2, 1, 3, 2...] |
| 満ち潮のしほのあしはやみ船と船と触れなむとしてまた事もなし | [2, 2, 1, 2, 1,...] |
しかしここで問題が起きた。
このモーラ数の算出がMeCabでうまくいかない場合が多すぎたのである。
どういうことかというと、モーラ数が0として処理される場合が多かった。
これはなぜ起きるかというと、MeCabで未だ登録されていないワードやサブワードに直面することがあるからである。
具体例をお見せしよう。

この「濱みちと此處を見なして作りけむ道のそばなる砂雪隱の小屋」は中村憲吉によるものだが、「此處」がモーラ数0になり、あと雪隱(せっちん)もモーラ数0の原因になっていそうである。
つまり、原因は私が作った歌人の歌が古めかしくてMeCabでは対応ができていないということである。
うーんこれはちょっと困った。データセットを作り直すのも大変だが、MeCabを古めかしい表現でアップデートするのも骨が折れそう...。
現状としてはここで作業がストップしている。
なお、参考にした論文の方でもMeCabでモーラ数を算出しているが、特にここら辺の問題は起きていない。
そちらでのデータセットはwebから取ってきた偶然に短歌の形式を満たしているチャンクを使っているとのことだから、古めかしい表現とかは特になかったのだと思われる。
残念ながら現状ではなかなか本や論文ほどの結果は得られていない。
データセットやモデルや学習手法などで色々違いがあるのだろう。
まああとこっちは量子化してCPUで動かそうとしているという制約もある。
とにかく地道に頑張るしかない。
(参考)MeCabでモーラ数を算出する方法
参考までに、短歌をトークンに分解して、そのトークンのモーラ数を算出する方法も紹介しておく。
Google ColaboratoryでMeCabをインストールするのにも少し手間取った。
割と頻繁に仕様が変わるらしく、これは2024年9月現在の方法である。
!pip install mecab-python3
!pip install ipadic
!python -m unidic download
MeCabがインストールできたら以下を使う。
import MeCab
# トークンごとのモーラ数を算出する関数
def count_mora_per_token(text, tokenizer):
# MeCabのTaggerの初期化
CHASEN_ARGS = r' -F "%m\t%f[7]\t%f[6]\t%F-[0,1,2,3]\t%f[4]\t%f[5]\n"'
CHASEN_ARGS += r' -U "%m\t%m\t%m\t%F-[0,1,2,3]\t\t\n"'
tagger = MeCab.Tagger(ipadic.MECAB_ARGS + CHASEN_ARGS)
# 与えられたテキストをトークンIDに分解する。
token_ids = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
moras = []
tokens = []
for token_id in token_ids["input_ids"][0]:
token = tokenizer.decode(token_id)
if token == "<|begin_of_text|>":
continue
# 形態素解析を実行し、結果を取得します
node = tagger.parseToNode(token)
while node:
# # モーラ数をカウントするための変数
mora_count = 0
# ノードの表層形(表記)を取得
surface = node.surface
# ノードの品詞情報を取得
features = node.feature.split(",")
if features[0] == "BOS/EOS":
# 次のノードへ移動
node = node.next
continue
# ノードが読みを持っている場合
if len(features) > 7:
# 読みを取得
reading = features[7]
# 読みの長さをモーラ数として加算
mora_count += len(reading)
break
moras.append(mora_count)
tokens.append(token)
return moras, tokens
mora_infos = {}
for index in range(len(tanka_data)):
tanka = tanka_data.iloc[index]["短歌"]
tanka = tanka.replace(" ", "")
tanka = tanka.replace(" ", "")
tanka = tanka.replace("\n", "")
tanka = tanka.replace("\t", "")
can_continue = False
if can_continue:
continue
# 拡張モデルで使った事前学習済みモデルのトークナイザを使う(今回はPhi-3.5)
moras, _ = count_mora_per_token(tanka, tokenizer)
total_moras = sum(moras)
remaining_moras = []
for mora in moras:
remaining_moras.append(total_moras)
total_moras -= mora
mora_infos[tanka] = [moras, remaining_moras]
(余談)DVCを使ってモデルのバージョン管理を行なった
DVC(Data Version Control)というオーペンソースのライブラリがあることを初めて知った。
これまでLLMやデータセットなどの巨大なサイズのファイルをgitで管理するのが難しくて難儀していたが、DVCがあればこの問題を解決できる。
使い勝手もGitに似ていて扱いやすくオススメ。
ざっくりしたイメージとしては、DVCで管理したいファイルの差分情報をdvcファイルとして管理し、元のファイル自体はローカルなりリモートストレージなりで保管しているといった感じである。
例えばファイルhoge.csvをDVCで管理したいときには、
dvc add hoge.csv
というようにステージングする。
こうすると、hoge.csv.dvcというファイルが出来上がるが、こちらのファイルをGitの追跡対象とする。
git add hoge.csv.dvc
リモートストレージにhoge.csvを登録するのは、
dvc push hoge.csv
でOK。Gitに慣れていればDVCもすぐ使える。
リモートストレージとしては、私はGoogle Driveを使ったが、他にもAWSのS3などメジャーなものはサポートされている印象である。
DVCはもっと早く知りたかったな。