著者: 橋本恭佑、伊藤雅博, 株式会社 日立製作所
はじめに
機械学習のシステム化に際して、データの前処理に要する時間やリソースを考慮し、設計に活かすノウハウが求められています。この投稿では、画像データを対象としたデータ前処理のノウハウと、torchvisionおよびOpenCVによるデータ前処理の性能比較結果を紹介します。
投稿一覧:
機械学習システムにおける画像データの前処理
画像データの前処理とは
機械学習におけるデータ前処理では、生データを整形・加工して機械学習モデルに入力するデータを作成します。機械学習を活用した画像処理の主な用途には、画像に何が映っているかを分類する「イメージ分類」と、画像に映る特定の物体を検出する「物体検出」の2種類があります。画像データ前処理の目的は、画像から意味のある特徴量を取り出すことです。画像に対する主な前処理の内容を表 1に示します。
表 1 画像データの主な前処理1
| 分類 | 前処理の具体例 |
|---|---|
| 意味のある特徴量を際立たせる | グレースケール変換、2値化、正規化 |
| 意味のない特徴量(ノイズ)を除去する | モルフォロジー変換 、ヒストグラム、次元圧縮(主成分分析、t-SNA)、リサイズ |
| 特徴量を増やす | 画像水増し(反転、平滑化、明度変更)、アノテーション |
画像データの前処理における課題
画像処理の分野ではPythonのライブラリが普及しており、前処理もこれらのライブラリで実装されることが増えてきました。しかし、こうしたライブラリはPythonの制約上、単一のCPUで処理が実行されることが多く、そのまま使うと膨大な量の画像を処理するには時間がかかる傾向があります。
本投稿では、画像データの前処理を並列化して最適化することで、処理時間を短縮する方法を示します。
画像データ前処理の検証シナリオ
検証シナリオ
今回は、機械学習向けのベンチマークプログラムの1つであるMLPerfに含まれる、物体検出のベンチマークを検証の題材として選定しました。MLPerfは、機械学習システム向けの業界標準ベンチマークであり、Google, Intel, NVIDIAおよび数十の企業によって支援されています。
MLPerfには、イメージ分類、物体検出、推薦、強化学習、翻訳、テキスト分析、スピーチ認識といったベンチマークが含まれています。今回は画像処理の中で応用例が特に多い「物体検出」を検証の題材として選定しました。
MLPerfの物体検出における前処理の流れ
MLPerfの物体検出における前処理の概要を図 1に示します。
図 1 MLPerfの物体検出における前処理
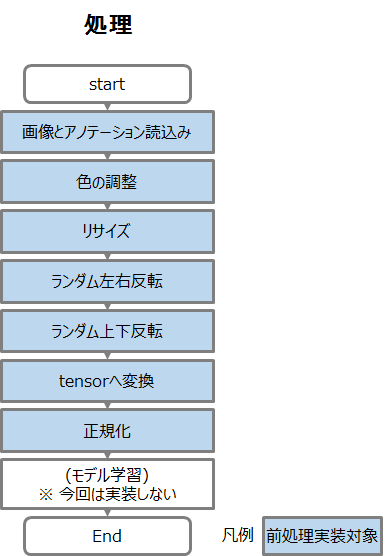
この前処理は以下の5つのフェーズで構成されています。MLPerfの物体検出の前処理は、表 1に示した画像処理分野の前処理が含まれる典型的な例と言えます。
(1)画像とアノテーション読み込み
画像とアノテーションを読み込んで関連付けます。画像はPIL.imageオブジェクトとして読み込み、アノテーションはJSON形式のファイルを読み込みます。そしてJSON内に記載された各画像のファイル名と画像の情報と関連付けます。
(2)色の調整
画像の色を、実行時に指定した明るさ、コントラスト、彩度、色相に変えます。
(3)リサイズ
画像の長辺(または短辺)の大きさが、実行時に指定した値より大きい(あるいは小さい)場合に、指定した値に収まる様に長辺(あるいは短辺) の大きさを変えます。
(4)ランダム左右反転
実行時に指定した確率で入力画像の左右を反転します。
(5)ランダム上下反転
実行時に指定した確率で入力画像の上下を反転します。
(6)tensorへ変換
(5)までPIL.image形式で処理されていた画像をtensor形式へ変換します。
(7)正規化
学習向けにtensorの各値が0から255の範囲に収まる様に変換します。
検証用データセット
画像データの前処理にかかる時間は、基本的に処理する画像数に比例します。物体検出では、認識するオブジェクトのカテゴリごとに約300枚の画像が必要と一般的に言われています。今回は、500種類のオブジェクトを検出するために、16万枚の画像を処理することを想定して評価を行いました。
MLPerfの物体検出では、MS Cocoという画像データセットを使用します。MS Cocoは物体検出の研究促進を目的としてMicrosoft社が発表したデータセットです。MS Cocoには、物体検出、画像認識のために必要な教師データ(画像の認識、セグメンテーション、キャプショニング)が付加されています。2020年5月現在までに2014年、2015年、2017年の3回リリースされています。
MLPerfの物体検出では2014年のデータセットを対象としているため、今回は2014年のデータセットに沿ったサンプルコードを実行します。表2にMS Coco 2014のデータセットのデータ量を示します。
表 2 MS Coco 2014のデータセットのデータ量
| データセットの名称 | データ個数 | 容量 |
|---|---|---|
| 2014 Train images | 82783 | 13GB |
| 2014 Val images | 40504 | 6GB |
| 2014 Test images | 40775 | 6GB |
| 2014 Train/Val annotations | 1(jsonファイル) | 241MB |
| 2014 Testing image info | 1(jsonファイル) | 2MB |
検証で使用した前処理用ライブラリ
画像処理の分野ではOpenCVが幅広い用途で利用されてきた実績のあるライブラリであり、CPU/GPUなどに対する処理の最適化がなされています。
一方で、MLPerfは機械学習エンジンにPyTorch、データの前処理にはtorchvisionを使用しています。PyTorchは使い勝手の良さから学術分野で多数採用されている機械学習エンジンであり、torchvisionはPyTorch向けの画像処理ライブラリです。
そのため、今回はtorchvision とOpenCV による画像データの前処理性能を比較検証しました。torchvision とOpenCVの比較を表 3に示します。
表 3 機械学習エンジンに対応する画像向け前処理ライブラリ一覧
| 前処理ライブラリ | 機械学習エンジン | 説明 |
|---|---|---|
| torchvision | PyTorchのみ | PyTorchと組み合わせることを前提とした画像処理ライブラリ。 |
| OpenCV | 制限なし | 画像処理分野における主要な画像処理ライブラリ。 |
検証内容
画像データの前処理は画像ごとに独立した加工を行うため、複数のCPUで並列処理が可能です。また、前処理の後に行うモデル学習はGPUを利用することが多いため、前処理をCPUで実行しつつ、同時にその結果を使ってGPUで学習処理を実行することで、リソースの利用効率を高めることが出来ます。今回はtorchvisionおよびOpenCVで前処理を並列実行した際の性能を比較しました。
今回の検証で使用するMLPerfの物体検出ベンチマーク(object_detection)は、前処理がtorchvisionで実装されています。そこでOpenCVの検証は、torchvisionの処理内容をOpenCVへ書き換えて実施しました。
torchvisionでは、一定数の入力データを読み出して前処理を行うDataLoaderというプログラムが、単一スレッドで動作します。そして、torchvisionには複数のDataLoaderを並列実行できる仕組みがあり、並列実行数(≒CPUコア数)を指定するだけで、データ前処理を簡単に並列化できます。
OpenCVでは、1つの画像を処理する際に、自動的に領域を分割するなどして処理を自動的に並列化します。そのため、OpenCVのプロセスを並列に呼び出すと、逆にプロセス間のオーバーヘッドが増加してしまい、性能が低下する場合があります。
そのため今回の検証では、まず少数の画像に対して性能測定のテストを実行して、CPUなどのリソースがどの程度利用されているかを確認し、並列処理のボトルネックを発見・解消していきました。画像データの前処理でボトルネックとなりやすい箇所を図2に示します。
図2 画像の前処理の性能測定における確認ポイント
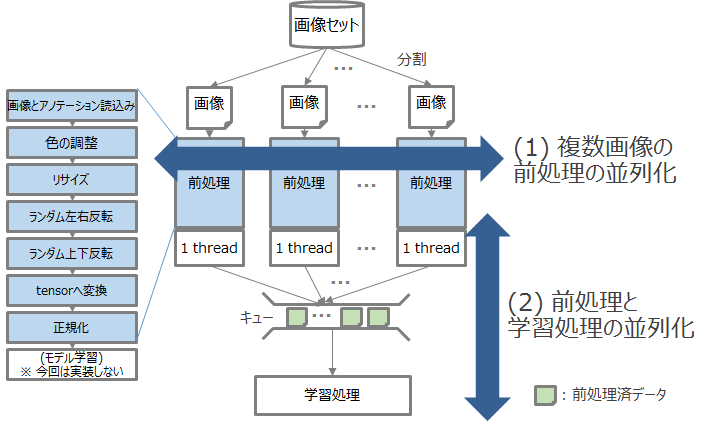
図2に示した2か所のボトルネックの詳細を以下で説明します。
(1)複数画像を並列で処理できているか?
画像データの前処理は画像ごとに独立した加工を行うため、複数のCPUで並列処理が可能です。そのため、マルチコアのCPUを持つ環境で全コアを効率よく使う(使用率が100%近い)ことが重要です。
(2)前処理と学習処理を並列で処理できているか?
一般的に、データの前処理はCPUで行いますが、深層学習によるモデルの学習処理にはGPUを使うことが多いです。そのため、前処理と学習処理の間にキューを挟んで非同期化することで、前処理と学習処理を同時に実行できるため、CPUとGPUを効率よく使用できます。
検証環境
画像データの機械学習では、前処理にCPU、深層学習にGPUを使うため、CPUとGPUの両方を搭載したマシンを使用することが一般的です。しかし今回の検証はデータ前処理が主体のため、CPUのみを搭載したマシンを使用しました。検証環境のハードウェアスペックを表 4に示します。
表 4 検証環境のハードウェアスペック
| 型名 | HA8000 TS20/AN |
|---|---|
| OS | CentOS 7.6.1810 64bit |
| CPU(コア数) | 20 |
| Memory(GB) | 384 |
| HDD(GB) | 12,000 (= 1,200GB * 10台でRAID5) |
検証で利用した主なソフトウェアのバージョンを表 5に示します。
表 5 検証環境のソフトウェアバージョン
| ソフトウェア | バージョン |
|---|---|
| Python | 3.6.9 |
| Numpy | 1.16.4 |
| OpenCV | 3.4.2 |
| PyTorch | 1.3.1 |
| torchvision | 0.4.2 |
| cudatoolkit | 10.0.130 |
画像データ前処理の性能検証結果
この検証では、MLPerfの物体検出シナリオに沿って作成した、torchvisionおよびOpenCVによる画像データの前処理プログラムを実行しました。ここでは、以下の順に検証した結果を紹介します。
- データ前処理のみを実行
- データ前処理と学習処理を並列実行
-
- データ前処理と学習処理間のボトルネックを解消して実行
今回の投稿では、「1. データ前処理のみを実行」の検証結果を紹介し、「2. データ前処理と学習処理を並列実行」、「3. データ前処理と学習処理間のボトルネックを解消して実行」については後編で紹介します。
データ前処理のみを実行
まずは画像データの前処理のみをマルチコアで実行した場合の処理性能を比較しました。PyTorch/torchvisionでは、前処理を実行する際のプロセス数をあらかじめ指定できます。OpenCVについては、torchvisionと同等の処理をOpenCVで実装し、torchvisionと同様にプロセス数を増加させて性能を比較しました。
測定条件
測定時に変化させたパラメータを表 6に示します。検証用マシンのCPUコア数は20コアのため、NUM_WORKERS (プロセス数)は20まで増やして検証を行いました。MAX_ITERは画像を読み込んで前処理を実行する回数です。なお、1回の処理で16個の画像をまとめて読み込み、前処理を行います。例えばMAX_ITER=10,000の場合、合計で160,000枚の画像を読み込んで前処理を実行します。
表 6 MLPerfの測定パラメータ(前処理のみ実行時)
| パラメータ名 | 測定する値 |
|---|---|
| NUM_WORKERS (プロセス数) | 1, 2, 4, 10, 20 |
| MAX_ITER (処理回数) | 1000, 5000, 10000 |
検証に使用したソースコードを以下に示します。この測定ではDataLoader関数における前処理のみを実行し、学習処理は実施しません。
dataset = COCODataset(“filename”)
# データセットから並列に読み出して前処理を行い、結果を順次data_itemとして渡す
for data_item in DataLoader(dataset):
# 本来ここで学習処理を実行するが何もしない
pass;
測定結果
torchvisionの処理時間を図 3、OpenCVの処理時間を図 4に示します。
図 3 データ前処理のみの処理時間(torchvision)
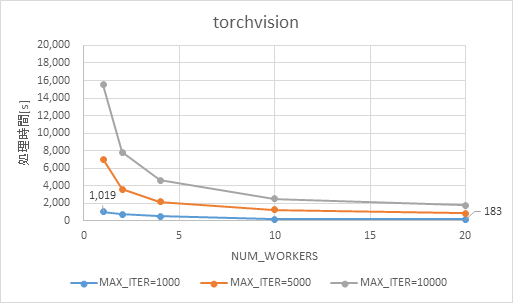
図 4 データ前処理のみの処理時間(OpenCV)
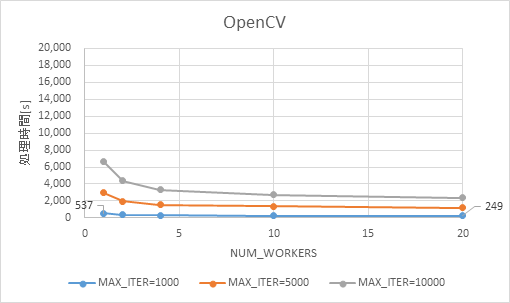
torchvision(図 3)、OpenCV(図 4)ともに、処理回数(MAX_ITER)に比例して処理時間が増加しました。一方、プロセス数(NUM_WORKERS)を増加させた際の処理時間の変化には違いがありました。
処理回数=1,000の場合、プロセス数を1から20に増やしたところ、OpenCVでは処理時間が55%程度短縮されたのに対し、torchvisionの場合は80%以上短縮されました。
処理回数=1,000における、平均CPU利用率を図 5に示します。
図 5 前処理実行時の平均CPU利用率(前処理のみ)
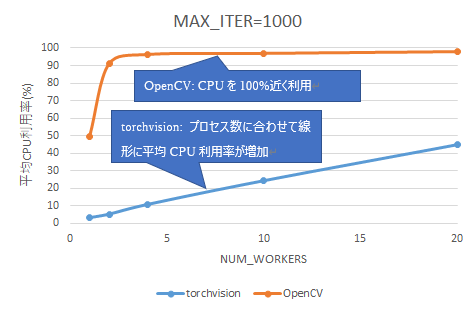
torchvision はプロセス数に比例して線形にCPU利用率が上昇しました。一方、OpenCVではプロセス数が4の時点で既にCPUを100%近く利用していました。
なお、性能測定に利用したマシンは物理コアが20コアですが、Hyper-threading機能が有効になっているため、実際には40スレッドを使用できます。torchvisionは20プロセスでCPU利用率50%のため、約20スレッドを使用していると推測できます。一方、OpenCVはCPU 利用率100%なので40スレッドをほぼ100%使い切っています。
以上の結果から、今回の検証ワークロードに対してはtorchvisionの方が前処理を並列化する効果が大きかったといえます。
おわりに
機械学習を活用したシステムでは、生データを整形・加工して機械学習モデルに入力するデータを作成する「データ前処理」が必要です。本投稿では、torchvisionおよびOpenCVによる画像データ前処理の性能検証結果を紹介しました。今回の検証では、機械学習向けのベンチマークプログラムであるMLPerfに含まれる物体検出ベンチマークから、データ前処理部分のプログラムを抽出し、torchvisionの実装とOpenCVの実装とで性能を比較しました。
画像データの前処理は画像ごとに独立した加工を行うため、複数のCPUを活用した並列処理が可能です。性能検証の結果、torchvisionとOpenCVではCPU利用率の特性が異なることを確認しました。torchvisionは1プロセス1スレッドで動作するため、マシンのCPUコア数に合わせて明示的に並列実行数を指定することで、処理を高速化できました。一方、OpenCVは1プロセスが自動的に複数のCPUコアを使用するため、並列数のチューニングをしなくてもある程度の性能を出せました。
今回の検証ワークロードに対しては、多数のCPUコアを使用して並列化した際の効果はtorchvisionの方が高いといえます。
実際の機械学習システムでは、データ前処理の後にモデルの学習処理を行います。後編では、画像データの前処理とモデル学習処理を合わせた性能検証結果を紹介します。
-
足立悠著, 機械学習のための「前処理」入門, リックテレコム, 2019. ↩