著者: 橋本恭佑、伊藤雅博, 株式会社 日立製作所
はじめに
機械学習を活用したシステムでは、生データを整形・加工して機械学習モデルに入力するデータを作成する「データ前処理」が必要です。前編では、torchvisionおよびOpenCVによる画像データ前処理の性能検証結果を紹介しました。
しかし実際の機械学習システムでは、データ前処理の後にモデルの学習処理を行います。後編となる本投稿では、画像データの前処理とモデル学習処理を合わせた性能検証結果を紹介します。
投稿一覧:
データ前処理と学習処理を並列実行
前編の投稿ではデータ前処理の部分だけを検証しましたが、今回はデータ前処理とモデル学習処理を合わせた検証を行いました。この検証では、前処理した結果をキューに書き込み、それを学習側が読み出して処理することで、データ前処理と学習を並列に実行しました。
今回は性能検証が目的のため、実際の学習処理の代わりに、前処理後のデータをキューから読み出してファイルに出力する処理を追加しました。つまり、毎回の処理で16個の画像ファイルを読み出して前処理してキューに格納し、それを非同期で読み出して(学習処理の代わりに)ファイルへ出力しました。
測定条件
測定時に変化させたパラメータを表 7に示します。今回はMAX_ITER=1,000で固定としたので、合計で16,000枚の画像を処理しました。
表 7 MLPerfの測定パラメータ(前処理+ファイル出力(学習処理の代わり))
| パラメータ名 | 測定する値 |
|---|---|
| NUM_WORKERS (プロセス数) | 1, 2, 4, 10, 20 |
| MAX_ITER (処理回数) | 1000 |
この検証で実行したソースコードを以下に示します。
dataset = COCODataset(“filename”)
# データセットから並列に読み出して前処理を行い、結果を順次data_itemとして渡す
for data_item, index in enumerate(DataLoader(dataset), index):
# データをファイルに出力する(学習処理の代わり)
with open(“outputfile-for-%d.pkl”%index,”wb”) as f:
pickle.dump(data_item, f)
測定結果
先ほどの前処理のみの測定結果と、今回の前処理+ファイル出力(学習処理の代わり)の測定結果の比較を、図 6(torchvision)、および図 7(OpenCV)に示します。torchvision、OpenCVともに、プロセス数を増やすことで処理時間は短縮できましたが、その効果は前処理のみの場合と比べて小さくなりました。
図 6 前処理+ファイル出力の処理時間(torchvision)
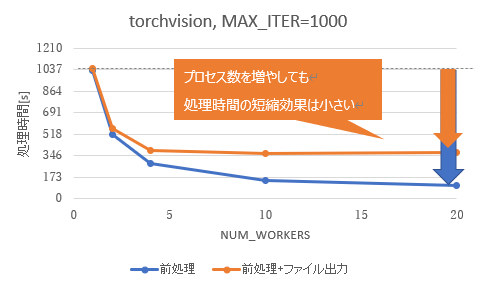
図 7 前処理+ファイル出力の処理時間(OpenCV)
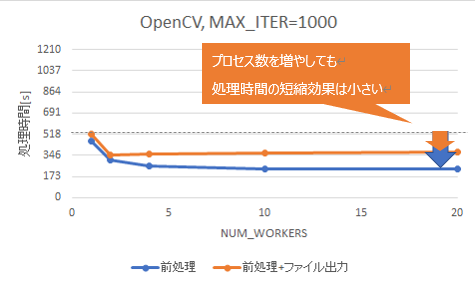
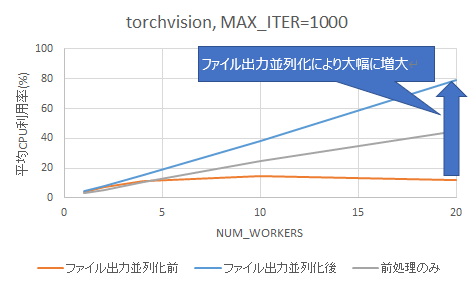
それぞれの平均CPU利用率を図 8に示します。torchvisionとOpenCV共に、プロセス数を増やしても平均CPU利用率は上がりませんでした。いずれの場合も、前処理のみの場合(前編の図 5)と比べて平均CPU利用率は低下しており、CPUを有効活用できていないことがわかりました。
図 8 前処理+ファイル出力の平均CPU利用率
データ前処理と学習処理間のボトルネックを解消して実行
測定条件
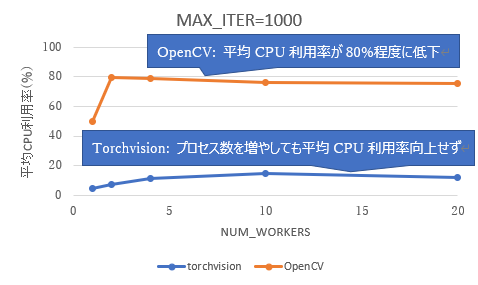
先ほどの前処理+ファイル出力(学習処理の代わり)の検証では、並列処理を増やしても処理時間があまり短縮されませんでした。これは、前処理よりもファイル出力(学習処理の代わり)が遅いため、前処理の実行結果をプールしておくキューが詰まってしまい、前処理側のプロセスがキュー空きを待つ必要があることが原因でした(図 9)。
図 9 前処理と学習処理の間のボトルネック
これを解消するために、前処理済データを出力するキューをプロセス数の数だけ作成し、ファイル出力をプロセス数の数だけ並列処理することで、前処理済データの出力処理がボトルネックとならないようにしました。実行したソースコードを以下に示します。
dataset = COCODataset(“filename”)
# ファイルにデータを書き出す(のちに学習で利用する)処理の実装
def output_file(queue):
while True:
data_item, index = queue.get()
with open(“outputfile-for-%d.pkl”%index,”wb”) as f:
pickle.dump(data_item, f)
# データを出力する処理をマルチプロセス化する
queues = []
processes = []
for i in range(NUM_PROCESSES):
q = Queue()
queues.append(q)
p = Process(output_file, q)
processes.append(p)
for data_item, index in enumerate(DataLoader(dataset), index):
#複数のプロセスにリクエストを投げる
queues[index % len(queues)].put(data_item, index)
測定結果
torchvisionとOpenCVそれぞれについて、プロセス数を変化させた場合の処理時間の比較を、図 10と図 11に示します。いずれの場合においても、プロセス数の増加に応じて処理時間は短くなりました。
図 10 プロセス数を変化させた場合の処理時間の変化 (torchvision)
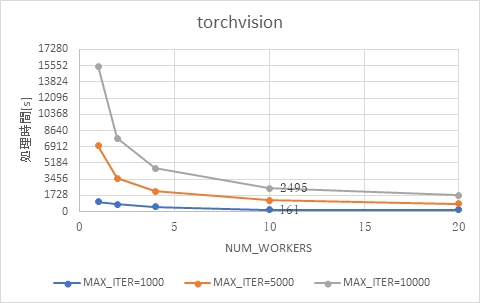
図 11 プロセス数を変化させた場合の処理時間の変化 (OpenCV)
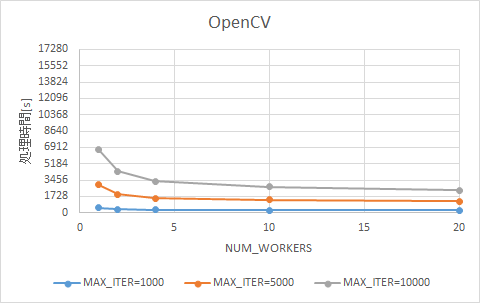
学習処理を並列化する前と後について、10プロセス時の処理時間の比較を図 12に示します。OpenCVとtorchvision共に、並列化によって処理時間を短縮でき、前処理のみの処理時間に近づくことが確認できました。今回のワークロードでは、処理時間の改善効果はOpenCVよりもtorchvisionの方が顕著であり、処理時間そのものもtorchvisionの方が短くなりました。
図 12 学習処理を並列化する前後における処理時間の比較
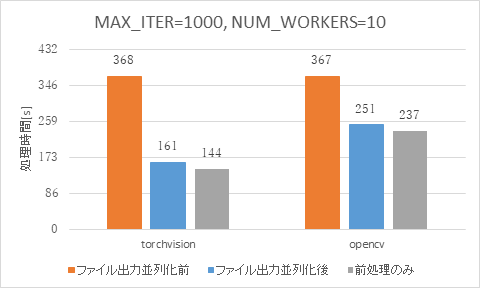
最後に、torchvisionとOpenCVそれぞれについて、平均CPU利用率の比較結果を図 13と図 14に示します。
図 13に示すtorchvisionの結果では、ファイル出力処理を並列化した後の方が、前処理のみの場合よりも平均CPU利用率が高いことがわかります。これは、キューを設けることで前処理済データの出力が詰まらなくなったことで、並列化したファイル出力処理にもCPUが使用されているためと考えられます。
図 13 平均CPU利用率の比較 (torchvision)
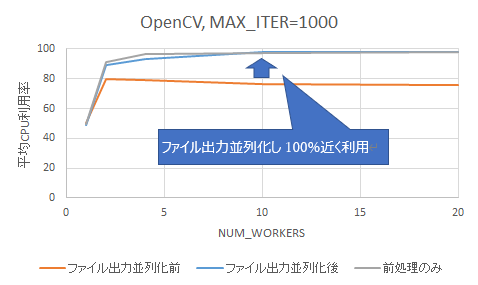
一方で、図 14に示すOpenCVの結果では、前処理のみの場合と同様に平均CPU利用率が100%近くになりました。そのため、ファイル出力がボトルネックとなりCPU使用率が下がる事態は回避できています。
図 14 平均CPU利用率の比較 (OpenCV)
おわりに
本投稿では、torchvisionおよびOpenCVによる画像データの前処理に、モデル学習処理を組み合わせた際の性能検証結果を紹介しました。機械学習を活用したシステムでは、データ前処理の後に機械学習モデル学習を行うため、データ前処理を高速化すると今度はモデル学習処理の方がボトルネックとなります。そのため、機械学習の処理全体を高速化するには、前処理だけではなく学習処理の高速化も重要となります。
今回の検証では、前処理したデータをキューを挟んで非同期的に学習処理へ渡すことで、前処理と学習処理を同時に並列実行でき、CPUリソースの利用効率を高めることが出来ることを確認しました。