著者: 橋本恭佑, 伊藤雅博、株式会社 日立製作所
はじめに
本連載では、画像の前処理と学習処理とが一体となった機械学習システムにおける前処理の短縮効果について議論します。
前回の投稿では、深層学習における前処理の設計において、前処理を実行するライブラリやプロセッサの選択、
チューニングの目標値見積が必要であることを示しました。
今回の投稿では、並列化やプロセッサの変更による前処理の処理時間短縮効果と、
チューニングによる前処理の処理時間短縮効果が総処理時間に与える影響について、実機検証した結果を示します。
さらに、実機検証した結果を踏まえた、用途に応じた前処理システムの設計方針について示します。
投稿一覧:
深層学習向け画像前処理システムの性能比較検証
検証②: プロセッサの種類(CPU/GPU)による前処理の処理時間
前処理の処理時間の測定条件
前処理の処理時間(GPUを活用する場合を含む)を検証するため、下記3種類の前処理プログラムの処理時間の比較結果を示します。
- torchvisionを用いてCPU上で実行する前処理プログラム
- OpenCVを用いてCPU上で実行する前処理のプログラム
- OpenCVを用いてGPU上で実行する前処理のプログラム
なお、処理を並列化した場合のCPUリソースの利用の傾向については、機械学習における画像データ前処理の性能検証(後編)で紹介しています。
torchvisionとOpenCVでCPUを用いる場合は、前処理を実行する際に並列数(プロセス数)を指定します。
今回は物理的なコア数が12コアのCPUを2個搭載する環境を用いており、
予備実験の結果、並列数を12とした場合が並列数が24や48とした場合よりも処理時間が最小となりました。
したがって、torchvisionとOpenCVでCPUを用いる場合は、並列数1と並列数12の場合の処理時間を測定しました。測定条件を表5に示します。
表5 前処理の処理時間の測定条件
| 項番 | ライブラリ | プロセッサ |
|---|---|---|
| 1 | torchvision | CPU(1プロセス) |
| 2 | torchvision | CPU(12プロセス) |
| 3 | OpenCV | CPU(1プロセス) |
| 4 | OpenCV | CPU(12プロセス) |
| 5 | OpenCV | GPU |
また、今回は前処理の処理繰り返し回数(MAX_ITER)を1,000回とします。
1回の前処理で16個の画像をまとめて読み込むため、合計で16,000枚の画像を読み込んで前処理を実行することになります。
前処理の処理時間の測定結果
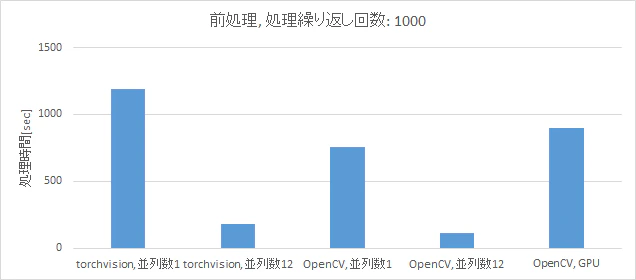
表5の測定条件における測定結果を図2に示します。縦軸は処理時間であり、小さいほど処理が高速であることを示しています。
図2より、今回の環境ではOpenCVでCPUを用いて12並列で処理する場合が最も高速であり、機械学習における画像データ前処理の性能検証(後編)の結果と異なることがわかります。
また、GPUを用いて前処理をした場合の処理時間は、OpenCVでCPUを用いて1並列で処理した場合の処理時間よりも遅いことがわかります。
以上より、前処理の処理時間を短縮する上では、GPUを用いるよりも、CPUを用いて並列化した方が効果的であるといえます。
図2 ライブラリ及びプロセッサ毎の前処理の処理時間比較
検証③: 前処理のチューニングが総処理時間に与える影響の確認
検証②の結果から、前処理にGPUを利用することによる処理時間の短縮効果は小さいこと、
及び今回の検証ワークロードにおいて前処理の処理時間を短縮するためのチューニングとしては、CPUを用いた並列化が最も有効であることがわかりました。
この測定結果は前処理部分のみの結果でしたが、実際の機械学習システムでは前処理と学習処理を合わせた処理時間を短縮することが重要です。
このチューニングが前処理と学習処理とが一体のシステムにおいても有効であるかを確認するため、
前処理の並列数を変化させてチューニングした場合の、前処理と学習処理とを合わせた総処理時間、
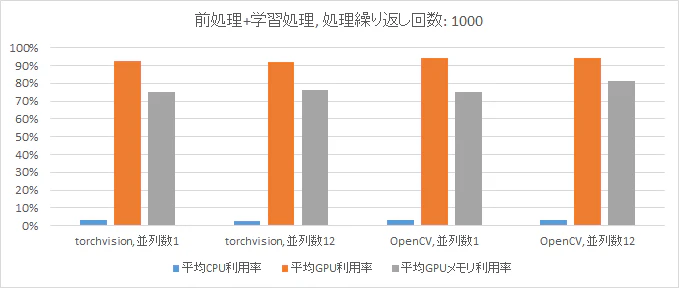
平均GPU利用率および平均CPU利用率の測定結果をそれぞれ図3、図4に示します。
図3より、前処理を並列化しチューニングした後の総処理時間は、OpenCVでは約11%減少した一方で、torchvisionでは6%増加しました。
検証②で検証した前処理の短縮効果が総処理時間の変化に表れないことから、前処理をチューニングすることで総処理時間を短縮する効果は表れにくく、
学習処理の短縮が総処理時間の短縮にはより効果があることを意味します。
図4より、平均GPUメモリ利用率がtorchvisionよりもOpenCVの方が高いことからも、
前処理にOpenCVを用いてチューニングした場合の方がGPUリソースをより多く使うことができており、
学習処理の処理時間が短縮したことで、総処理時間が短縮したことがいえます。
また、図4より総処理時間がライブラリや並列数にかかわらず、平均CPU利用率は3%程度であるのに対して、平均GPU利用率は90%以上あることがわかります。
これは今回のユースケースでは学習処理がGPUに大きく負荷をかけるため、CPUによる前処理のチューニングに工数をかけても、
学習処理がボトルネックとなって総処理時間の短縮効果が薄いことを意味します。
図3 前処理をCPU、学習処理をGPUで処理した場合の総処理時間の比較
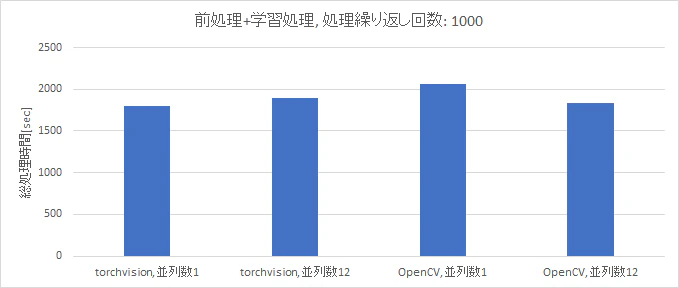
図4 前処理をCPU、学習処理をGPUで処理した場合の平均リソース利用率の比較
前処理チューニング結果の考察と用途に応じた前処理システムの設計方針
PyTorchの様な深層学習向けフレームワークでは、前処理と学習処理とを一体のシステムとして設計します。
モデル作成中に前処理と学習処理とを並行して実行するため、前処理と学習処理を合わせた総処理時間が、各々の処理時間よりも短くなります。
このようなシステムでは、元の画像セットから機械学習モデルを作成するまでの総処理時間を短くできますが、
前処理をチューニングする効果は限定的になることが検証②の結果からわかります。
特に今回のユースケースにおいては、学習処理がボトルネックとなって総処理時間が長くなっていることから、
総処理時間を短くする上では、学習処理を速くするためのチューニングが必要であるといえます。
このような設計はデータが毎回異なる追加学習、差分学習などにおいて有効です。
一方で、前処理と学習処理とを分離したシステムとして設計する方針も考えられます。
この場合、前処理と学習処理とを個別に処理できるため、必要なリソースを減らすことができます。
しかし前処理の処理時間と学習処理の処理時間の和が総処理時間となるため、モデル作成時にボトルネックとなる処理があると、総処理時間が長くなります。
したがって前処理と学習処理の両方をチューニングすることが、総処理時間の短縮に向けて必要といえます。
この様な設計は、前処理済みの同じデータを何度も使用する機械学習モデルのハイパーパラメータチューニングなどにおいて有利と考えられます。
上記の前処理システムの設計方針とその特徴のまとめを表6に示します。
以上の議論を踏まえて、用途に応じた前処理のシステムを設計した上で、前処理のチューニング効果を検討することが重要と考えます。
表6 前処理システムの設計方針とその特徴
| 項番 | 前処理システムの設計方針 | 利点 | 前処理チューニングの必要性 | 適性ある用途 |
|---|---|---|---|---|
| 1 | 前処理と学習処理を分離しない(今回のユースケース) | 総処理時間を短縮可能 | △(チューニング前に前処理と学習処理のいずれがボトルネックかを調査要) | 頻繁に異なるデータを学習処理で用いる用途(追加学習や差分学習など) |
| 2 | 前処理と学習処理を分離する | 処理リソースを削減可能 | ○(前処理および学習処理の処理時間を短縮した分、総処理時間も短縮できる) | 学習処理に用いるデータが同じ用途(パラメータチューニングなど) |
おわりに
画像を対象とした深層学習を行う機械学習システムにおける前処理について、主に性能面での観点からシステム化する際の設計の考え方を、
MLperfのシナリオを用いた実機検証結果を通して紹介しました。
実機検証の結果、GPUを前処理に用いることによる前処理の処理時間の短縮効果は、前処理をCPUで並列化することによる短縮効果よりも小さいことがわかりました。
また、前処理と学習処理を並行して実行するアーキテクチャでは、前処理の処理時間短縮に向けたチューニングの効果が限定的となることがわかりました。
このアーキテクチャは毎回利用するデータが異なる追加学習、差分学習を行うシステムを設計する際に有効です。
一方で、同じデータに対して、異なる設定で学習を繰り返すシステムを設計する上では、1度前処理した結果を出力して、
その結果をそれぞれの設定の学習で読み込むアーキテクチャが、効率よくリソース活用できることも考えられます。
この場合は、前処理と学習処理とを個別のシステムとして設計し、各々の処理をチューニングすることで、総処理時間を短縮する効果が期待できます。
以上の議論を踏まえて、機械学習向けの前処理システムの設計においては、機械学習システムの用途を把握し、
上述の2つの前処理システムの設計方針の利点を把握したうえで、前処理システムのチューニング要否を検討することが重要と考えます。