はじめに
この記事は「cGAN(conditional GAN)でくずし字MNIST(KMNIST)の生成」の続きです。
cGANを元にACGANをやろうとしてあれこれやってみた際の記録になります。
cGANからの進化という意味では自然な発想かなと思いますが、実装してみるとなかなか...
ACGANとは
cGANについては前回の記事に簡単に紹介したので、ACGANについて簡単に説明します。
ACGANとは、一言だと**「Discriminatorがクラス分類タスクも行うcGAN」**です。
よりバリエーションの多い画像の出力を可能とする手法になっています。
元論文は[こちら](Conditional Image Synthesis With Auxiliary Classifier GANs)
A. Odena, C. Olah, J. Shlens. Conditional Image Synthesis With Auxiliary Classifier GANs. CVPR, 2016
ACGANの論文については、元論文を記事化されている方がいらっしゃいますので、そちらが参考になります。
<参考記事>
AC-GAN(Conditional Image Synthesis with Auxiliary Classifier GANs)の論文解説
ACGANのモデル構造
cGANでは、Discriminatorに本物/偽物画像とラベル情報を入力して、本物or偽物の識別を出力としていました。一方ACGANでは、Discriminatorの入力が画像のみで、本物or偽物の識別だけでなくそれがどのクラスかを当てるクラス判定も出力に加わります。図で書くと以下のような感じです。
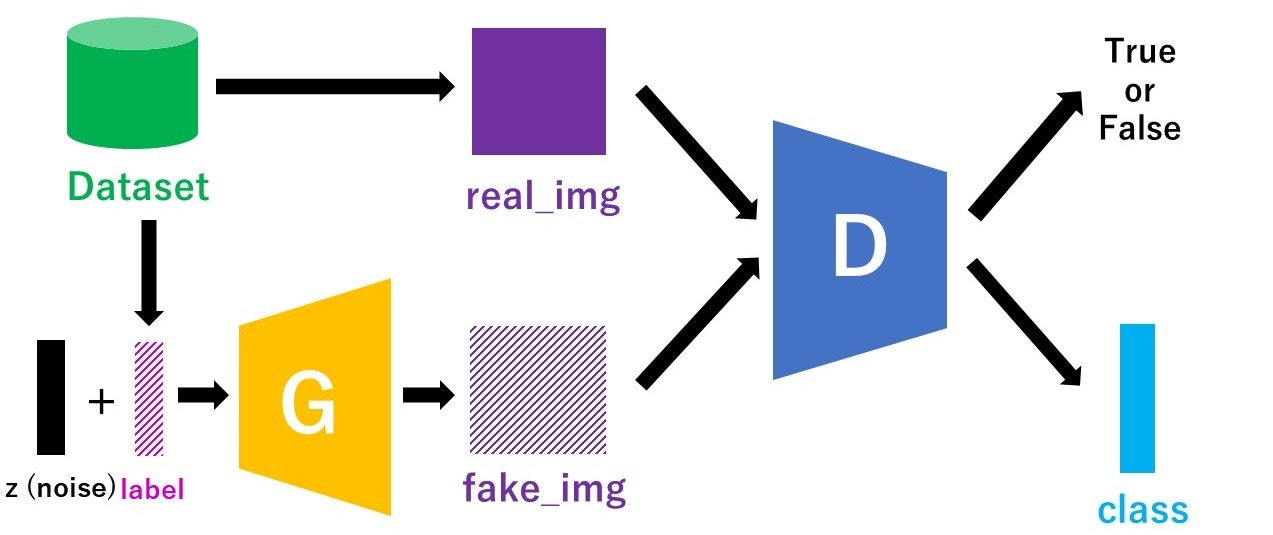
図中のclassの部分が、Discriminatorが予測するクラス分類の出力です。labelと同じく、クラス数次元のベクトルの形をしています。
とりあえず実装
ACGANはGitHubにPyTorch実装があります。
これを参考にしながら、前回の記事で書いたcGANの実装に手を加えてみます。
やることは
- Discriminatorの入力からラベル情報をなくす
- Discriminatorの出力にクラス分類を足す
- 2種類のlossを計算し、伝播させる
がほぼすべてです。そうすると、Discriminatorの構造はこんな感じです。
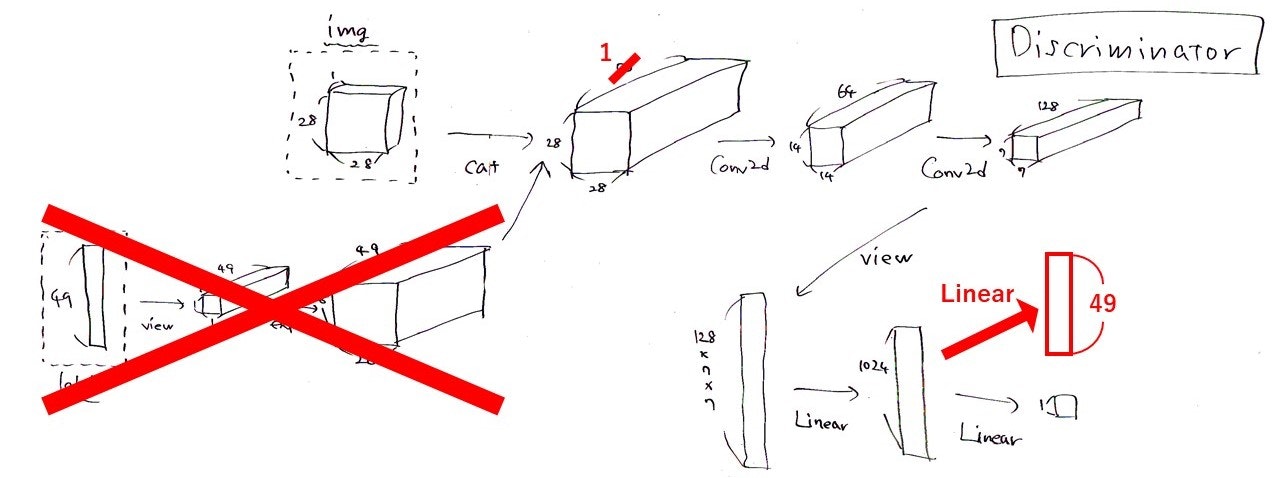
これは前回の記事に載せたcGANのDiscriminatorの構造の図にお絵描きしたものですが、赤で示された部分がACGANでの変更点になります。
Discriminatorの実装です。
class Discriminator(nn.Module):
def __init__(self, num_class):
super(Discriminator, self).__init__()
self.num_class = num_class
self.conv = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=4, stride=2, padding=1), #入力は1チャネル(白黒だから), フィルターの数64, フィルターのサイズ4*4
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.BatchNorm2d(128),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
)
self.fc_TF = nn.Sequential(
nn.Linear(1024, 1),
nn.Sigmoid(),
)
self.fc_class = nn.Sequential(
nn.Linear(1024, num_class),
nn.LogSoftmax(dim=1),
)
self.init_weights()
def init_weights(self):
for module in self.modules():
if isinstance(module, nn.Conv2d):
module.weight.data.normal_(0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.Linear):
module.weight.data.normal_(0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm1d):
module.weight.data.normal_(1.0, 0.02)
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.normal_(1.0, 0.02)
module.bias.data.zero_()
def forward(self, img):
x = self.conv(img)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
x_TF = self.fc_TF(x)
x_class = self.fc_class(x)
return x_TF, x_class
クラス分類の出力をどう加えるかは色々やり方がありそうです。先ほど貼ったリンクのPyTorch実装で最後にLinear層を二股に分岐させていたので、ここでは同じように実装しています。
この変更に合わせると、1エポック当たりの関数はこんな感じ。
def train_func(D_model, G_model, batch_size, z_dim, num_class, TF_criterion, class_criterion,
D_optimizer, G_optimizer, data_loader, device):
#訓練モード
D_model.train()
G_model.train()
#本物のラベルは1
y_real = torch.ones((batch_size, 1)).to(device)
D_y_real = (torch.rand((batch_size, 1))/2 + 0.7).to(device) #Dに入れるノイズラベル
#偽物のラベルは0
y_fake = torch.zeros((batch_size, 1)).to(device)
D_y_fake = (torch.rand((batch_size, 1)) * 0.3).to(device) #Dに入れるノイズラベル
#lossの初期化
D_running_TF_loss = 0
G_running_TF_loss = 0
D_running_class_loss = 0
D_running_real_class_loss = 0
D_running_fake_class_loss = 0
G_running_class_loss = 0
#バッチごとの計算
for batch_idx, (data, labels) in enumerate(data_loader):
#バッチサイズに満たない場合は無視
if data.size()[0] != batch_size:
break
#ノイズ作成
z = torch.normal(mean = 0.5, std = 1, size = (batch_size, z_dim)) #平均0.5の正規分布に従った乱数を生成
real_img, label, z = data.to(device), labels.to(device), z.to(device)
#Discriminatorの更新
D_optimizer.zero_grad()
#Discriminatorに本物画像を入れて順伝播⇒Loss計算
D_real_TF, D_real_class = D_model(real_img)
D_real_TF_loss = TF_criterion(D_real_TF, D_y_real)
CEE_label = torch.max(label, 1)[1].to(device)
D_real_class_loss = class_criterion(D_real_class, CEE_label)
#DiscriminatorにGeneratorにノイズを入れて作った画像を入れて順伝播⇒Loss計算
fake_img = G_model(z, label)
D_fake_TF, D_fake_class = D_model(fake_img.detach()) #fake_imagesで計算したLossをGeneratorに逆伝播させないように止める
D_fake_TF_loss = TF_criterion(D_fake_TF, D_y_fake)
D_fake_class_loss = class_criterion(D_fake_class, CEE_label)
#2つのLossの和を最小化
D_TF_loss = D_real_TF_loss + D_fake_TF_loss
D_class_loss = D_real_class_loss + D_fake_class_loss
D_TF_loss.backward(retain_graph=True)
D_class_loss.backward()
D_optimizer.step()
D_running_TF_loss += D_TF_loss.item()
D_running_class_loss += D_class_loss.item()
D_running_real_class_loss += D_real_class_loss.item()
D_running_fake_class_loss += D_fake_class_loss.item()
#Generatorの更新
G_optimizer.zero_grad()
#Generatorにノイズを入れて作った画像をDiscriminatorに入れて順伝播⇒見破られた分がLossになる
fake_img_2 = G_model(z, label)
D_fake_TF_2, D_fake_class_2 = D_model(fake_img_2)
#Gのloss(max(log D)で最適化)
G_TF_loss = -TF_criterion(D_fake_TF_2, y_fake)
G_class_loss = class_criterion(D_fake_class_2, CEE_label) #Gからすると、Dが本物だと思い込んでかつクラスもあててくれた方がうれしい
G_TF_loss.backward(retain_graph=True)
G_class_loss.backward()
G_optimizer.step()
G_running_TF_loss += G_TF_loss.item()
G_running_class_loss -= G_class_loss.item()
D_running_TF_loss /= len(data_loader)
D_running_class_loss /= len(data_loader)
D_running_real_class_loss /= len(data_loader)
D_running_fake_class_loss /= len(data_loader)
G_running_TF_loss /= len(data_loader)
G_running_class_loss /= len(data_loader)
return D_running_TF_loss, G_running_TF_loss, D_running_class_loss, G_running_class_loss, D_running_real_class_loss, D_running_fake_class_loss
先ほど述べた変更点に加えて、入れるノイズも少し変えました。
前回は30次元・平均0.5・標準偏差0.2の正規分布でしたが、今回は100次元・平均0.5・標準偏差1の正規分布にしています。
クラス分類のlossはtorch.nn.NLLLoss()です。これも先ほどのリンクの実装に合わせました。
結果
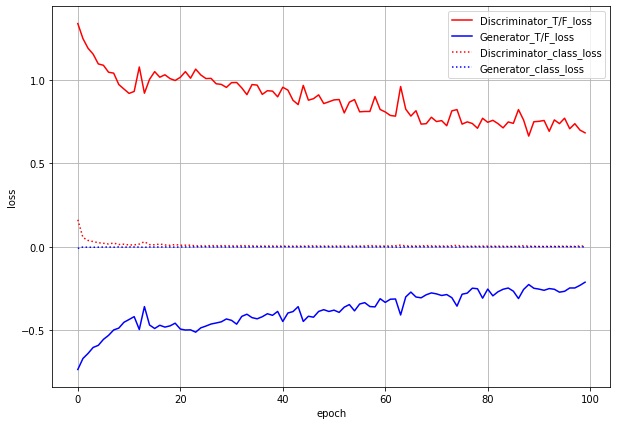
まずはlossのグラフです。
ACGANでは、本物or偽物識別のlossとクラス分類のlossの2つがあり、GeneratorにもDiscriminatorにも両方のlossを伝播させます。グラフでもわけてプロットしています。
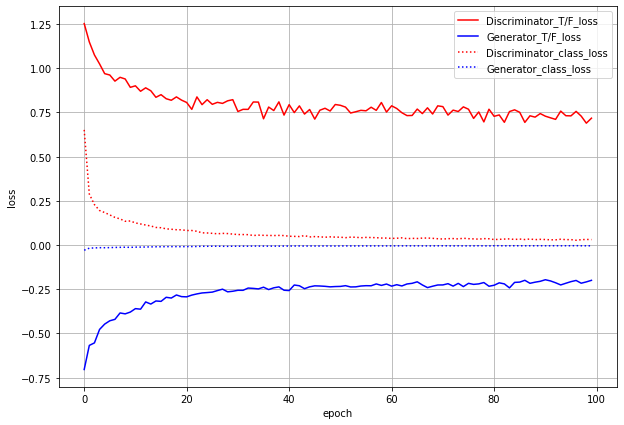
T/F_lossが本物/偽物識別のloss(実線)、class_lossがクラス分類のloss(点線)です。
これだけ見るとうまくいっているように見えます。しかし...
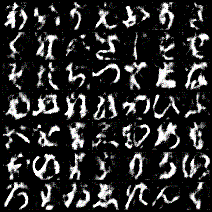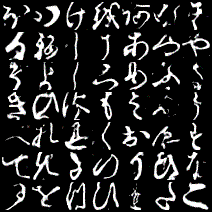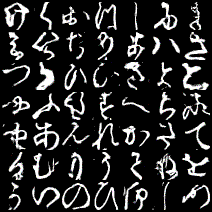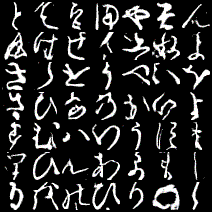
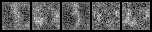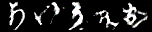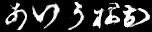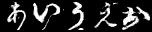
これは1epochごとに各ラベルの画像を1枚ずつ生成したときのgifです。
一番上の行が左から「あ、い、う・・・」と続いて、右下が「・・・を、ん、ゝ」となるようにラベル情報を入力していますが、与えたラベルと生成する画像がほとんど対応していません。でも、全く意味のない画像というよりは「別のラベルの文字」を生成しているように見えます。
cGANと同様に、100epoch訓練後のGeneratorで「あ」~「ゝ」を5枚ずつ生成してみました。

ラベルちゃんと対応してそうなのは「け」くらいじゃないでしょうか。
(というか完全にモード崩壊・・・)
ちなみに、同じ条件で100epoch訓練後のcGANの生成結果がこれです。

明らかにcGANの方がラベルに近い文字が出力されています。
うまくいかない原因・・・?
パッと出力を見た感想ですが、ACGANではGeneratorとDiscriminator双方が、本来とは異なる形の文字をそのラベルの文字だと思い込む(Ex: DiscriminatorとGeneratorが両方とも「い」の形に似ているものを「あ」のラベル扱いしている)のではないか?と思いました。
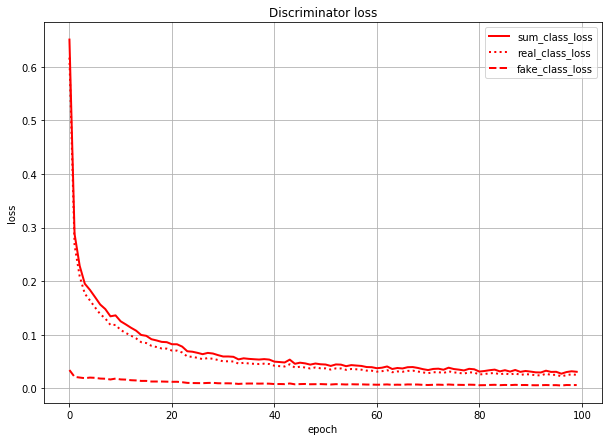
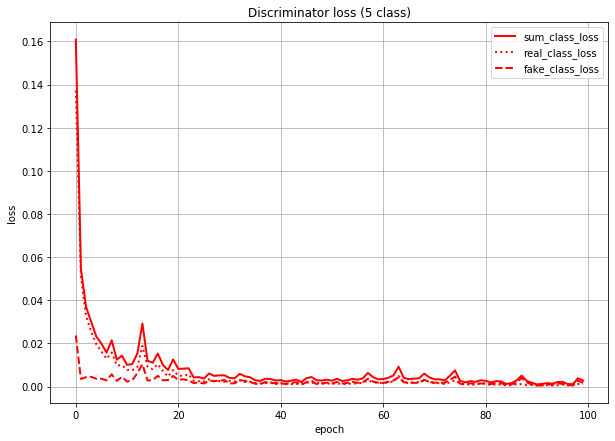
これは、Discriminatorのクラス分類のlossを本物画像由来のlossと偽物画像(=Generatorが作った画像)由来のlossに分けて描いたグラフです。sum_class_lossは合計値(=さっきのグラフの赤点線と同じ)になってます。
このグラフを見ると、Discriminatorは(特に学習序盤で)本物画像の判定を間違え、偽物画像の判定を当てまくっていることになります。
(数値で言うと、real_class_lossはfake_class_lossの序盤で20倍、終盤で5倍くらいの値になっている)
つまり、Generatorが「あ」のラベルで作った画像は、実際の形は「あ」とはだいぶ異なる形になっていても、Discriminatorでも「あ」扱いされている、というようなことが想像できます。
おそらく理想としては、クラス分類のlossは本物画像由来も偽物画像由来も同じくらいの値になってほしいのではと思います。
うまくいってそうなものと比較してみる
ACGANの元論文でも言及されていることですが、クラス数が多すぎると同一ネットワークでは出力画像の質が落ちるらしいです。元論文でもImageNet(1000クラス)を10クラス×100ケースに分けて実験しています。
そこで、こちらも一度5クラスでやってみることにしました。
ネットワーク構造は同じにして、「あ」~「お」の5文字生成をやってみます。
lossのグラフは同じような感じです。T/F_lossの方はまだ下がる余地がありそうではあります。
こちらも若干のムラはありますが、後半はかなり綺麗に出来ています。
続いて、100epoch訓練後のもので5枚ずつ画像を生成してみます。
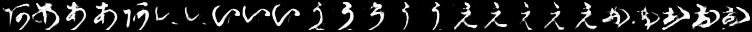
なんとモード崩壊もしてなさそうです。
では、Discriminatorのクラス分類のlossです。
数値ベースで言うと、序盤は10倍くらい差があったのが、終盤ではほぼ同じ値になっているのですが、このグラフだと見づらいので3epoch以降だけ表示してみます。
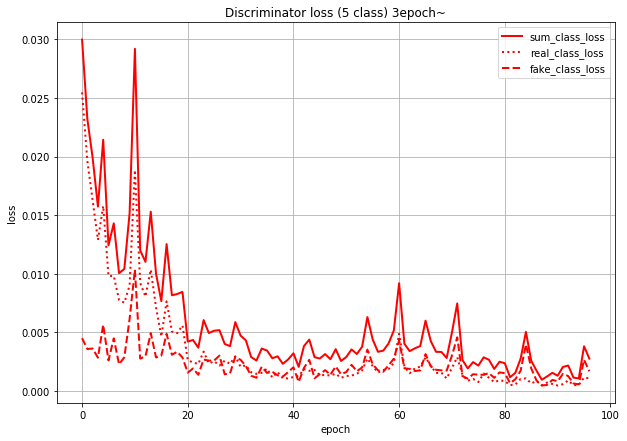
こう見るとreal_class_lossとfake_class_lossがかなり近い値になっていくのがよくわかります。
iterごとのloss
そもそも学習の序盤で1epochめから本物分類と偽物分類で10倍~20倍の差がでるの??と思ったので、iterごと(ミニバッチごと)のlossを表示してみました。
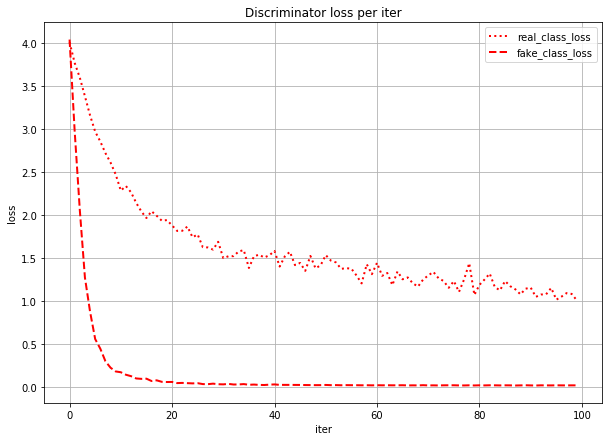
確かに最初はreal_class_lossとfake_class_lossでlossの値は変わりませんが、fake_class_lossの方が急激に下がっているのがわかります。
事前学習を試す
最初の数エポックで本物画像だけを学習させるなどしてみましたが、それでもほぼ意味がなかったので、分類タスクだけを事前学習させてみることにしました。
Discriminatorだけを取ってきて分類タスクだけ解かせます。
分類タスクの結果
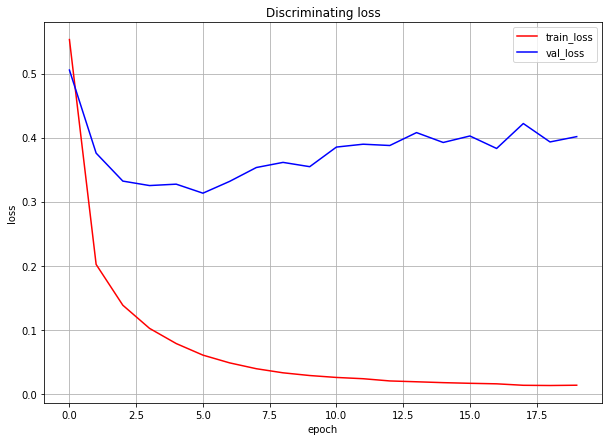
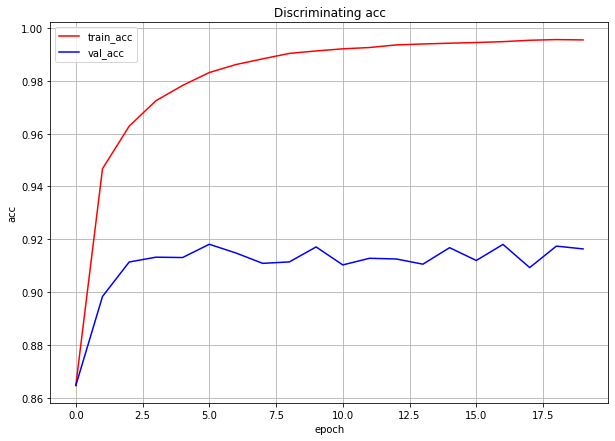
収束がかなり速いので、20epochしかやっていません。
なんか結果的には微妙ですが、とりあえずこの20epoch訓練後のDiscriminatorを使うことにします。
事前学習適用時の結果
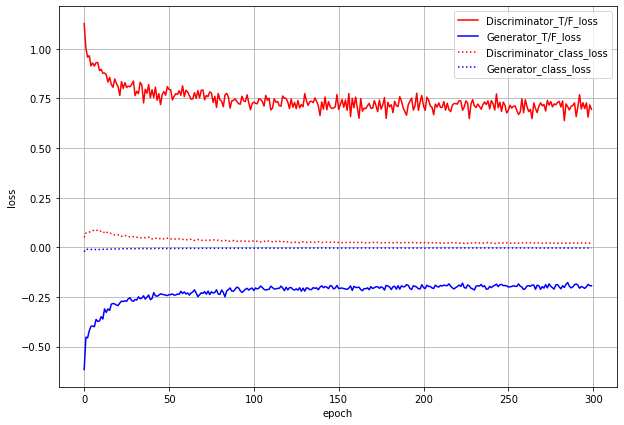
True/Falseのlossは事前学習しないときとほとんど変化がありません。分類のloss
については、序盤からかなり小さくなっています。
では、本物画像由来と偽物画像由来の分類lossを見てみます。
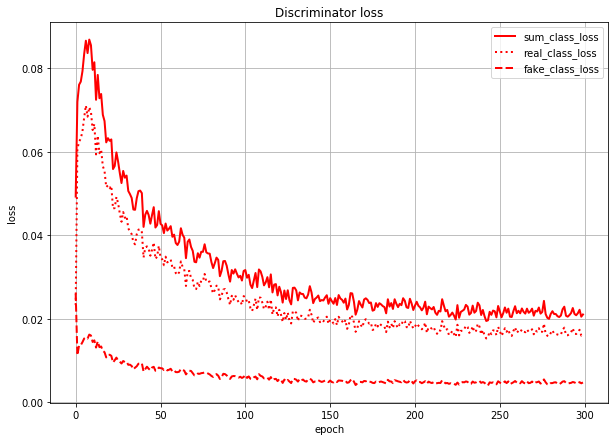
300epochまで学習させてみました。事前学習しないときに比べると、本物画像由来のlossの値もかなり下がってはいます。偽物画像由来のlossと比べても4倍程度に収まっていますが、それでも同じくらいの値にはなっていません。
この300epoch訓練後のACGANによる生成画像を見てみます。

うーん。。
効果が見られません。うまく行った文字が増えたということもなく、モード崩壊も起きています。
感想
くずし字データセットは、1文字当たりのデータ数が多くは6000で300~400程度しかないものも数個あります。1クラス当たりのデータ数が多い方がうまくいくと思うので、CIFAR-10よりもデータ数が多いくずし字ならうまくいく可能性はあると思いましたが、ダメでした。
個人的には、潜在空間での各ラベルの文字どうしの距離が近い(=異なるラベルの文字でも潜在空間内ではかなり近いところにいる)のでは?と思います。
元論文の実験ではCIFAR-10やImageNetを10クラスごとで実験していましたが、くずし字だと10クラスでは半分強しかうまくいく文字がなく、5クラスにして初めてうまくいきました。
いずれにしても、49クラスをACGANで狙って出力させるのはかなり難しそうなのであきらめることにします・・・