🚀 情報に溺れるエンジニアへ:Cursor × Obsidian で “勝手に育つ第二の脳” を作ってみた
はじめに:あれ? 今日もまた、全部忘れてない?
こんにちは。くわっちです。
生成AIの進化の激流に半分飲み込まれつつ、今日も料理と読書とゲームとほんの少しの仕事をしています。
さて今日はこんなお話です。
最近はエンジニアも何かとアウトプットを求められる時代です。生成AIの登場で、一からアウトプットする機会は少なくなっているかもしれませんが、プロンプトをいくら工夫してアウトプットを求めても、ありきたりな薄っぺらいテキストが濫造されるばかりだと思ったことはありませんか。
結局は自分自身で専門書や技術サイトを読み、知識のバックボーンを構築しないと、いい文章というのは生み出せません。かといって――
- 技術記事を読みまくる
- ニュースも追う
- ChatGPTやGeminiに相談もする
- メモアプリも使っている
――結構インプットしているはずなのに、いざアウトプットしようとすると何も出てこない。
- 「あの記事どこだっけ?」
- 「前に調べたはずなのにまたググってる」
- 「ノートは溜まるのに“知識”になってる手応えがない」
そんなことはないでしょうか。
今日はそんなあなたのために書きました。ほんとは内緒にしておいて、自分だけはるかな高みに登り詰めようともほんの一瞬だけ思ったのですが、今日は特別にさらけ出してしまいます。
最近は「Obsidian」や「Zettelkasten(ツェッテルカステン)」がよく話題に上がります。
「第二の脳」 という言葉も、よく見かけるようになりました。
でも正直、最初はこう思っていました。
コンセプトはわかるけど、
これ、本当に第二の脳になるの?
Evernote/Notionで日記やブログの下書き、業務メモをずっと書きためてきた身からすると、
- 「Obsidianって何がそんなに違うの?」
- 「リンクが貼りやすいのはわかるけど、それがどこにつながるの?」
という感覚の方が強かったです。
結論から言うと、人間だけで“第二の脳”を作ろうとするのは大変すぎるということです。
人間だけで、全部やろうとしているからうまくいかない。
もちろん、時間をかければ満足のいく”第二の脳"を構築することはできます。フォルダ構造をどうするか、タグ管理をどうするか、ナリッジベースの体系は?
納得いくまでチューニングして、これが自分の"第二の脳"だと思えるまでには相当な時間がかかってしまうように感じていました。
なら発想を変えればいい。
「人間が“頑張るノート術”はやめて、
“AIと一緒に勝手に育つ第二の脳”を作ればよくない?」
そうしてたどり着いたのが、
Cursor × Obsidian で構築した “勝手に育つ第二の脳” です。
この記事では、その全体像と実際の運用、具体的な成果まで、できる限りあけっぴろげにさらけ出します。
ちょっとだけ自己紹介すると:
- 元々は技術畑 → 約20年前に囲碁・将棋のイベント運営部署に異動
- Pythonの「パ」の字も知らないまま年月が過ぎる(囲碁と将棋とイラストはちょっとだけうまくなりました)
- 2025年4月、技術系部門に異動
- Cursor を触り始めてから Python と Obsidian にどっぷりハマり、完全に覚醒
自分で言うのもなんですが、「あ、これはもう前とは完全に別人やな」と思うレベルで仕事のやり方が変わりました。
この記事でわかること
- なぜ従来の知識管理(Zettelkasten/ノートアプリ/タグ地獄)は挫折するのか
- Cursor × Obsidian で構築した「勝手に育つ第二の脳」の全体像
- ジャーナル/思考/Clippings/ナレッジベース/ワークフロー/AIジャーナルの 6層構造
- Cursor と Obsidian を どう連携させているか(具体的なフォルダ構成と開き方)
- 実はこの仕組みが RAG(Retrieval-Augmented Generation)とほぼ同じ構造 になっている話
- Python+Cursor で自動化しているワークフローの考え方
- どう始めればいいか(最初の一歩と段階的な導入ステップ)
なぜ「ノート術」は続かないのか?(問題の整理)
まず、従来の知識管理がなぜうまくいかないのかを整理します。
❌ Zettelkasten:理念は最高、運用が地獄
Zettelkastenの基本は:
- 1ノート1アイデア
- ノート同士をリンクで接続
- 積み重ねるほど「第二の脳」ができる
考え方としては理にかなっています。
Obsidianでもよく紹介される「1ノート1アイデア」「リンクでつなぐ」思想ですね。
ただ、現実の仕事と並行して運用するには、正直かなりキツい。
- 1ノート1アイデアに分割する手間
- 毎回、どこにリンクを張るか考える負荷
- フォルダ構造を捨ててタグ&リンクだけで管理するストレス
「ノートをフォルダ管理しないでいい」と言われても、
ファイルが一つの箱に雑然と置かれていくのは、
少なくとも自分の感覚では生理的に無理でした。
日記や業務メモは話題があちこちに飛ぶのが普通です。
それを全部1ノート1アイデアに分解しようとすると、逆に「いつどこで思いついたか」が失われてしまう気もします。
❌ ノートアプリ:書くだけで終わる「ゴミ箱化問題」
- Notion/メモアプリ/テキストファイル…
- とりあえず書けば安心するが、二度と開かない
“安心感だけくれて記憶から消えていくノート” が増えていくだけで、
蓄積しても「使える知識」にはなりません。
Notion時代の自分はまさにこれでした。
- 記録保管庫にはなっている
- でも、知識の保管庫にはなっていない
- 整理されていない or 整理されすぎていて辿りたくない
- 関連ノートの内容が微妙に重複していて、鮮度もバラバラ
フォルダを切りすぎると、今度はフォルダ同士が完全にサイロ化してしまう問題もあります。
❌ タグ付け:タグが増えすぎて詰む
- 最初はよくても、数ヶ月で破綻
- 「このタグで付けたっけ?」と迷い始める
- 類似タグが乱立してカオス
- 「業務」なのか「業務メモ」なのか
- 「アイデア」と「アイディア」が混在
どのみち、増えたタグの管理も人間がやるので、結局しんどくなります。
解決策:AIとObsidianに「知識管理の面倒くさい部分」を丸投げする
そこで選んだのが、この組み合わせです。
-
Obsidian
→ Markdownベースで超高速な「知識のグラフ」 -
Cursor
→ AIを活用してコードと文章を自動生成する「開発用IDE」 -
Python+ワークフロー
→ Clippingsやニュース、ジャーナルを自動処理する仕組み
この3つを組み合わせて、
「人間は雑に情報を投げるだけ」
「AIが構造化・整理・リンク張り・要約・ナレッジ更新をやる」
という状態を目指しました。
結果として出来上がったのが、
“勝手に育つ第二の脳” です。
Cursor × Obsidian をどう連携させているか
ここがよく聞かれるポイントなので、先に具体的に書きます。
🔗 連携の基本アイデア
ObsidianのVaultフォルダ = CursorのWorkspace
にしてしまう。
これだけです。やっていることはシンプル。
手順
-
ObsidianでVault(ルートフォルダ)を作る
例:~/SecondBrainみたいなフォルダを1つ作る。 -
同じフォルダをCursorで「Open Folder」として開く
- Cursorの「Open Folder」から、さっきのVaultフォルダを指定
- これで、そのフォルダ配下のMarkdownファイルを全部Cursorから操作可能になる
-
以降はこうなる
- Obsidianでノートを作る/編集する
- Cursorでは、同じフォルダをWorkspaceとして、
- Markdownを読ませる
- Pythonスクリプトで一括更新する
- Agentに「このフォルダ以下をスキャンして○○して」と指示する
つまり、
- Obsidian:人間が読む・書く・眺めるためのUI
- Cursor:AIと一緒に「ファイル群そのものを編集・生成」するためのUI
として、同じファイル群を両側から触っている構成です。
「Obsidianだけ」「Cursorだけ」で完結させようとすると途端に難易度が跳ね上がるので、
Vaultフォルダを“インフラ”にして、
その上にObsidianとCursorを並べる
イメージで設計しています。
全体像:6つの層で動く「第二の脳アーキテクチャ」
この知識管理システムは、以下の 6層構造 でできています。
- ジャーナル層:日々の記録を時系列でためる
- 思考層:1ファイル1テーマで思考を深掘り
- Clippings層:Web記事・ニュースの一時保管
- ナレッジベース層:人物・用語・トピックの体系化
- ワークフロー層:AIが動くための手順書
- AIジャーナル層:AIが自分の作業ログを残す
ここからは各層をざっと紹介します。
1. ジャーナル層:ゆるく全部受け止める“入り口”
役割:
日記/業務メモ/議事録/週報/読書メモなど、なんでも放り込む箱。
- 形式・ジャンルは問わない
- 年・月ごとにフォルダ分けしてもいいし、単一フォルダでもいい
- 命名規則も「自分がわかればOK」
ポイントは一つ。
「あとでAIが読む前提なので、雑でOK」
- 1ファイル1テーマにはこだわらない
- とにかく“ここに書けば残る”という安心感を作る
これまでNotionでやっていたこととまるで変わりません。というか、Notionからごっそり持ってきました。
2. 思考層:1ファイル1テーマで“深く考える”場所
役割:
1テーマについてとことん考えたログ を残す層。
- 「1ファイル1テーマ」を徹底
- 構造化しようとしない(生の思考でOK)
- アイデア、疑問、プロット、壁打ちログ、生成AIとの対話などを丸ごと保存
ここを Cursor / Gemini / ChatGPT に読ませることで、
- 体系的な整理
- ブログネタの抽出
- 書籍/長文記事の構成案
- 業務ソリューションのためのアイデア創出
など、“思考からアウトプットへの橋渡し” が自動化されます。
日別管理にしないのは、1つのテーマを何日もかけて考えたり、しばらく寝かせてまた深掘りしたりするから。
中長期的なテーマや、腰を据えて考えたいアイデアを置く場所です。
3. Clippings層:Web記事の一時保管&自動処理
役割:
Webの記事やニュースを一時的にぶち込む場所。
- ニュース記事/技術ブログ/解説記事などを保存
- 保存した時点では「雑に放り込むだけ」でOK
- 処理が終わった記事から順次削除 or アーカイブ
ここにファイルを置き、Cursor+Pythonのワークフローを発動させます。
Pythonを使わず、CursorのAgentに自然言語ワークフローを読ませるだけでもある程度回せます。
Clippingsの処理フロー(例)
- 記事を Clippings フォルダに保存
- Cursor が記事を読み込み、ジャンル分類
- 優先度に沿って処理(例:用語 > マーケティング > インバウンドマーケティング)
- 人物・用語・トピックを抽出し、
ナレッジベース層の各ノートに反映
処理フロー自体は Markdown で自然言語で書いておき、
それを「この手順で処理して」とAgentに投げています。
(もちろん、その処理フローのMarkdownを書くのもCursorに手伝わせます)
Clippingsで処理が終わったファイルは、もう「整理済み情報」なので、
捨てるなりアーカイブするなりお好みでOKです。
4. ナレッジベース層:知識を“使える形”にする中心部
ここが、このシステムの 心臓部 です。
役割:
Clippings やジャーナルなどを元に、人物/用語/トピック/ニュース を構造化。
実際に育ったナレッジ(現時点)
- 🔹 人物ノート:約 330 個
- 政治家、スポーツ選手、国際関係の主要人物、作家など
- 🔹 用語ノート:約 170 個
- 技術用語、ビジネス概念、国際・経済用語、作品など
- 🔹 トピックスファイル:約 40 個
- 継続して追っているテーマ(例:「存立危機事態」「ガザ地区の戦闘と停戦合意」など)
- 🔹 HowToカテゴリー:約 10 個
- 「Windowsのショートカット」「Macの便利機能」など、頻度は低いが役に立つ系
- 🔹 ニュースノート
- 日付別に整理された時事問題ノート
ニュースノートの自動生成
- 日付ごとにノートを分ける
- 「政治・国内」「政治・外交」「国際」「経済」「社会」「スポーツ」「テクノロジー」などセクションに分類
- 同じトピックのニュースは統合し、包括的なタイトルに調整
- 関連人物ノートへのリンクを自動設置
人物ノートの自動更新
- 約200人分の人物ノートを管理
- インデックスを自動作成し、重複チェック機能で同一人物の別ノートを防止
トピックスファイル
- 特定テーマ(例:「第一次高市早苗内閣発足」など)を時系列で整理
- 関連ニュースノートと双方向リンク
- 「そのテーマの全体像」を一発で把握できるように設計
5. ワークフロー層:AIエージェントの「取扱説明書」
役割:
Cursor に「どう動いてほしいか」を明示するための 定例作業マニュアル集。
たとえば:
- ニュース処理ワークフロー
- 人物ノート作成ワークフロー
- 用語ノート作成ワークフロー
- 週報作成ワークフロー
- レコメンド機能ワークフロー
これらを Obsidian 上の Markdown で管理し、
「このワークフローに沿って Clippings を処理して」
と Cursor に指示します。
すると AI が 人間の代わりに淡々と作業してくれる ようになります。
週報作成の自動化の例
以前は:
- チームメンバーの週報を集める
- 過去の週報やBacklog、Slackのやり取りを遡る
- 進捗を確認し、タスクをクローズ/新規追加
- 週次ミーティングの議事録を踏まえて修正
……という作業に半日くらいかかっていました。
今は:
- 週次ミーティングの議事録
- 業務メモ(Obsidianに全部残している)
- チーム員の週報
を同じVault内に置いておき、
「週報作成ワークフロー」を実行するだけで、たたき台の週報が自動生成されます。
- 完璧ではないので最終チェックは必要
- それでも、半日かかっていた作業が1時間程度に
というところまで来ました。
もちろん、Agentの過信は禁物です。
分類ミスや変なPythonスクリプトを勝手に書いて迷走することもあるので、必ず人間がレビューしています。
6. AIジャーナル層:AIに「自分の作業ログ」を書かせる
役割:
その日の作業内容を、AI自身に自動で書かせるジャーナル。
- 何をやったか
- 何を学んだか
- どこで詰まったか
- 明日やるべきこと
といった内容を、AIにウォークスルーとして書かせています。
ここが効くポイント
- 新しいチャットを開くとき、過去10日分のAIジャーナルを読み込ませる
- これにより、AIエージェントが
- 何をしてきたか
- どこまで進んでいるか
- どこで失敗して、どうリカバリーしたか
- どのワークフローが更新されているか
を理解した状態でスタートできる
つまり、作業の「続き」がすぐに再開できるようになります。
これだけで Agent への信頼度がかなり上がります。
……が、それでもやっぱり失敗はするので、繰り返しになりますが過信は禁物です。
この「第二の脳」、実はそのまま RAG になっている
ここまで読むと、勘のいい方はお気づきかもしれません。
これって要するに、
自前のRAG(Retrieval-Augmented Generation)を作ってるのでは?
RAG を超ざっくり言うと:
- 手元に「知識ベース(ドキュメント群)」がある
- ユーザーの質問に応じて、関連ドキュメントを**検索(Retrieval)**する
- その内容をLLMに渡して、**答えを生成(Generation)**する
という仕組みです。
この「第二の脳システム」を RAG 目線で見直すと、こうなります。
-
知識ベース
→ ObsidianのVaultに溜まった- 人物ノート
- 用語ノート
- トピックスファイル
- ニュースノート
- ジャーナル/思考ノート
-
Retrieval(検索)
→ Cursor に- 「このテーマに関するノートを全部読んで」
- 「この人物についての情報をまとめて」
などと指示し、
Obsidian配下のMarkdownを検索・抽出させる部分
Obsidianプラグイン(2Hop Links Plus など)によるリンク可視化も、
「どのノートが関連しているか」を見せるという意味で Retrieval の一部と捉えられます。 -
Augmentation(文脈付与)
→ Cursorに- 関連ノートの中身を読み込ませる
- YAMLフロントマターやリンク構造からコンテキストを組み立てさせる
-
Generation(生成)
→ その文脈をもとに、Cursorが- 記事ドラフト
- 週報
- 企画書のたたき台
- 新しいトピックノート
などを生成してくる部分
つまり、
ObsidianのVault = ベクトルDB的な「知識コーパス」
CursorのAgent = LLMとRAGのオーケストレーター
という構図になっています。
「社内向けにRAGシステムを作ろう」と思うと途端にハードルが上がりますが、
実はこの第二の脳システム自体が、個人用のローカルRAGとして機能しているんですよね。
非エンジニアでも、自分用のRAGにかなり近いものを構築できる時代になっています。
使わないのは、さすがにもったいないです。
発想への転換:知識管理から「ネタ生成装置」へ
ここまでで作ったものは、単なる情報整理ではありません。
「ブログ・記事・企画・プロットのネタを量産する装置」 でもあります。
ジャーナル&思考ノートから記事ネタを掘り起こす
- ジャーナル:
→ 日々見ているニュースや出来事から「書くべきテーマ」が見つかる - 思考層:
→ 既に深掘りしたテーマが、そのまま記事やエッセイの種になる
具体例:
-
ジャーナルに書いた
「福間香奈女流六冠の11連覇と棋士編入試験」
から、
→ 「“最後の挑戦”から3年後に再挑戦を決めた理由を掘る記事」
を自動生成
→ ちょっと手直ししてブログ(個人のnote)で公開 -
思考ノートに書いた
「Obsidian×Cursorで思考するための方法論」
から、
→ 今読んでいるこのブログ記事のような構成案が生まれる
業務データと組み合わせれば、
- 社内に蓄積されたデータ(一部でも可)
- ナレッジベースに蓄積された分析ノート
を組み合わせて、データ分析の新しい試行のネタ出しにも使えます。
(業務に関わるのでここでは詳細は書きませんが、
やろうと思えばかなり面白いことができます)
ノート同士のリンクから“連想ゲーム”でネタが増える
Obsidian の双方向リンク+AIの補助により、
- 人物ノート × トピックノート
- 用語ノート × 思考ノート
- ニュースノート × ジャーナル
の組み合わせから、新しい記事案がどんどん出てきます。
「この人物、あのトピックにも関わってない?」
「この用語、前に考えてたアイデアと繋がるのでは?」
といった “発想のショートカット” が頻発します。
さらに、コミュニティプラグインも活躍します。
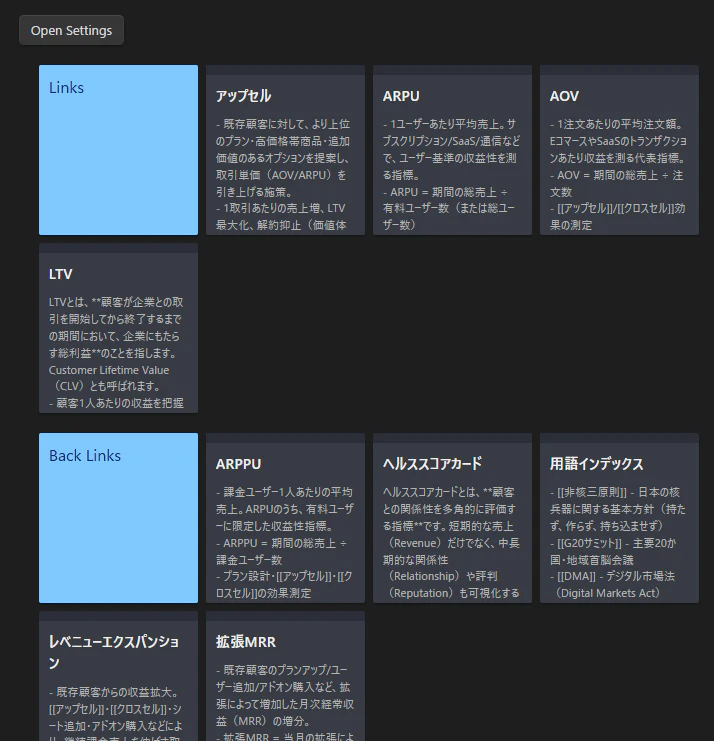
-
2Hop Links Plus
→ ノートにリンク(2ホップ先までというのがミソ!)&バックリンクの記事を表示し、関係性を可視化
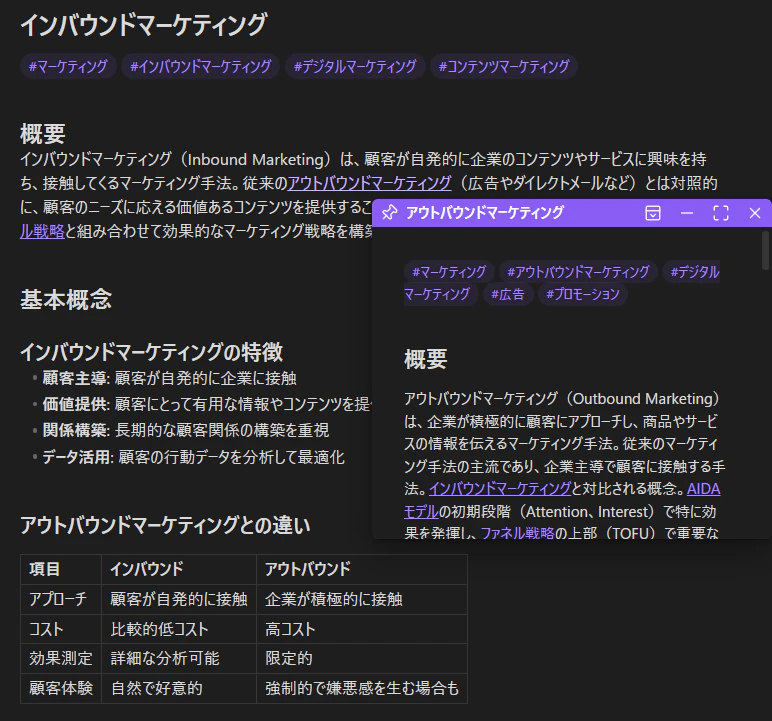
-
Hover Editor
→ リンクにカーソルを合わせるだけで別ウィンドウでノートをプレビュー
この2つが、連想にツバサを与えてくれる感じがして、とても気に入っています。
レコメンド機能ワークフロー:
“お前、これ書いたらバズりそうだよ” とAIが教えてくれる
ナレッジベースから記事のネタを自動レコメンドするワークフローも作っています。
- Phase 1:興味分析
- 人物インデックス/用語インデックス/AIジャーナル/ニュースノート/トピックファイルを解析
- Phase 2:記事候補マッチング
- ユーザーの興味に合いそうな記事案をAIが提案
- Phase 3:記事案の具体化
- 選んだネタに対して、3パターンの構成案を自動生成
- Phase 4:ドラフト作成
- ブログ原案を自動生成
ここまで来ると、
「何を書こうかな…」という悩みそのものが消えます。
技術的な実装のざっくり概要
詳細なコードは長くなるので割愛しますが、実装の柱はこんな感じです。
🔧 Pythonスクリプト
- Clippingsフォルダからニュース記事を読み込み
- カテゴリー分類(政治/国際/経済/社会/スポーツ/テクノロジー etc.)
- 人物・用語の抽出
- 既存ノートとの重複チェック
- Markdownファイル(Obsidian用)の自動生成・更新
🤖 Cursorとの連携
- ObsidianのVaultフォルダをCursorのWorkspaceとして開く
- 「このワークフローでClippingsを処理して」と自然言語で指示
- Pythonやシェルスクリプトの生成・修正
- ワークフローの継続的な改善(プロンプトのチューニング含む)
🧾 YAMLフロントマター
- 人物ノート:
-
aliasesで別名管理
-
- トピックスノート:
-
created/updated/tagsで履歴管理
-
- 共通フォーマットを決めておくことで、AIからも扱いやすくする
どう始める?(ミニマムスタートガイド)
全部いきなり真似する必要はありません。
おすすめは次の3ステップです。
Step 1:Obsidianを導入して「ジャーナル層」だけ作る
- 日付フォルダ or 週ごとのフォルダを作る
- 日記/業務メモ/議事録を全部ここに突っ込む
- 雑でいいです。「綺麗に書こう」と思わないことが重要
Step 2:Clippings用フォルダを作る
- 「あとでちゃんと読みたい記事」をここに保存
- 最初は手動で整理してもOK(カテゴリ分けくらいから始める)
Step 3:Cursorで1つだけワークフローを自動化する
- 例:
「Clippingsフォルダ内のニュースを、日付別のニュースノートに追記するスクリプトを書いて」
とCursorに依頼 - うまく動いたら、徐々に
- 人物ノート生成(人物でなくてもいいです。自分にとって重要な単位なら何でもOK)
- 用語ノート生成
- トピックファイル更新
に手を伸ばす
この3ステップだけでも、「情報が勝手に整理されていく感覚」が味わえるはずです。
まとめ:“ノート術”から、“勝手に育つ第二の脳”へ
- 人間だけで知識管理をやる時代は、そろそろ限界が見え始めている
- Cursor × Obsidian を組み合わせることで、
- 情報は勝手に整理され
- 知識は勝手に育ち
- アウトプットのネタは勝手に増える
そんな環境を、個人レベルでも作れるようになりました。
もし今あなたが、
- 情報に追いつけていない感覚がある
- ノートアプリに疲れている
- Zettelkastenは無理ゲーだと思っている
のであれば、
この「勝手に育つ第二の脳」を一度試してみてほしいです。
情報を管理するために生きるのではなく、
情報があなたのために働く世界へ。
その最初の一歩は、
Obsidianで1つフォルダを作り、それをCursorで開くところから。