AtCoder Heuristic Contest 001 - AtCoder
いわゆるマラソン系コンテスト。普通の数時間程度のコンテストとは異なり、最適解の出ない問題を1週間くらい掛けて点数を上げていくコンテスト。AtCoder社長のchokudaiさんが前々から開催したがっていたらしい。開催おめでとうございます ![]()
私の解答。コミットメッセージにはそのときの10ケースのスコアも載せている。
問題概要
長方形の広告ごとに含まなければいけない座標と目標面積が与えられる。なるべく条件を満たすように敷き詰めろという問題。公式のヴィジュアライザの結果が↓。青は目標面積より小さく、紫がちょうど。目標面積よりも大きくなると赤色になるけど、ムダなのでそういう広告は無し。

貪欲(山登り法)
平均0.892G点。なお、全ての広告で目標面積が達成できると1G(109)点になる。Twitterで皆が話題にしているのはAtCoderの50ケースでの暫定テスト結果なので、これの50倍。以降、章ごとにスコアを書いているけど、説明を端折っているものものあるので、その修正だけでスコアが変化しているわけではない。そもそも10ケースしか試していないから誤差がある。
最初は指定された点を含む1x1の広告を置いて、他の広告とぶつかるまで徐々に広げていく。
貪欲2
平均0.951G点
他の広告を押しのけてでも広げる。このとき、他の広告が含まなければいけない点は覆わないようにする。0点になってしまうので。また、この条件を満たす限り、他の広告を完全に覆うように拡がることはないので、押しのけられた側はいずれかの辺を小さくすれば、衝突を回避できる。
これだけで満点の95%までいくのか。初開催のコンテストだし、点数が高いほうが皆のやる気も出るだろうという配慮のスコア計算方法か?
焼き鈍し
平均0.966G点。
たとえスコアが減ってもときどきは元に戻さずにそのままにする。この「ときどき」の確率は最初は高めに徐々に低くしていく。最初にこのアルゴリズムを知ったときは「そんなので上手くいくの?」と思ったが、とても上手くいく。マラソンマッチの定番アルゴリズム。
拡張するだけではダメなのでは?
平均0.959G点。
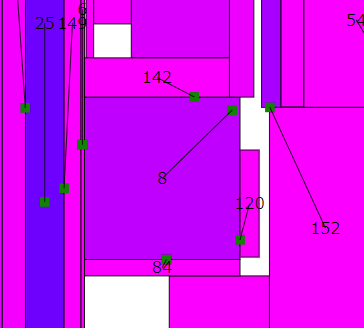
広告を広げるときに、他の広告が含む点は覆わないようにしている。するとこの8番のように他の広告が含む点まで拡がった広告は詰む。幅か高さを縮めて、高さか幅を増やすしかない。ということでときどき縮めるようにしてみた。これはいまいち。後で何とかする。
正方形に近づける
平均0.964G点。
← before after →
放っておくと広告が細長くなる。身動きが取れなさそうなイメージがあるので、正方形に近づけてみた。
伸ばす方向を決めるときに、縦に伸ばす確率:横に伸ばす確率 = 幅:高さ とした。ただ、どうしても横に伸ばさざるをえないときもあるだろうし、一定の確率で従来通り縦横を等確率に。これ、遷移を決めることによるのではなく、スコアに重みを付けたほうが良かったかもしれない。
このときは必要だと思ったのだけど、後述のOptunaの結果を見るに、要らなかったっぽい。
伸縮の上限
平均0.9821G点。
少しずつ広げたほうが良いと思ったけど、無制限にしたらスコアが伸びた。
高速化
平均0.9827G点。
広告を広げるときに覆ってしまってはいけない他の広告が覆うべき点との衝突判定。この点をp[i]とすると、X[p[i].y].push_back(p[i].x), Y[p[i].x].push_back(p[i].y) としておいて、例えば、右端x2をe伸ばすならば、X[x2+1], X[x2+2], ..., X[x2+e-1]をチェックする。先に伸縮の上限を無制限にしたとはいえ、そんなに伸ばすことは少ないはずなので計算量は減る。
この高速化を入れた段階で、他の広告との衝突判定が半分近い時間を使っていた。何とかしたいが、覆うべき点と違って難しい。1点ではなく領域なので。とりあえず、右端の座標を上記と同じように管理して、見るのは自分より右端が左にある広告とするだけで、平均的に計算量は半分になるはずである。とはいえ、そもそも広告を伸縮させるたびに右端を管理するコストだけでも地味に重かった。半分近い計算時間を使っているとはいえ、しょせん高々200回のループだからな……。結局これは最後までどうにもならなかった。
縮小と拡張を同時に
平均0.9826G点。
ある試行で縮小して、次の機会に拡張するというのは、山登りで言うと一度谷に降りるイメージ。谷に降りるのを(ときどき)許すのが焼き鈍し法の特徴……とはいえ、あまり良くないらしい。谷の間に橋を架けるイメージだろうか。
スコア計算を高速化
平均0.9882点。
「え、そこ?」という感じだった。プロファイラーで計測するの重要。まあ、割り算が2回だし。ということで、結果をキャッシュしておくようにした。
あとは、t*(mx-mn)/mx*(mx-mn)/mxよりt*(mx-mn)/(mx*mx)のほうが割り算が1回になって速いだろうけど、tをかなり小さくしないとlong longに入らないのでNG。スコアの精度が落ちてしまう。
パラメタ調整
https://github.com/kusano/ahc001/commit/7ac6ef4d011ad848a15f8ecdb8279b176c11c1a7
https://github.com/kusano/ahc001/commit/24aa56b8e4115672c868398a4b26016c52a7cdae
https://github.com/kusano/ahc001/commit/baf7efc924fe854084396d9cf2ccb48a9ee3a997
平均0.9886点。
名前は聞いたことのあるOptunaを使ってみた。いいなこれ。
import optuna
import os
import pwn
import sys
pwn.context.log_level = "error"
def objective(trial):
temp_start = trial.suggest_float("temp_start", 1e-3, 1., log=True)
temp_end = trial.suggest_float("temp_end", 1e-7, 1e-4, log=True)
square = trial.suggest_int("square", 0, 1024)
shrink = trial.suggest_int("shrink", 0, 1024)
os.system(
f"clang++ -std=c++17 -O2 -DNDEBUG -DLOCAL "+
f"-DPARAM_TEMP_START={temp_start} "+
f"-DPARAM_TEMP_END={temp_end} "+
f"-DPARAM_SQURE={square} "+
f"-DPARAM_SHRINK={shrink} "+
f"./ahc001.cpp")
s = pwn.process(prog)
s.readuntil("sum: ")
score = float(s.recvline().decode()[:-1])/test_num*50
s.close()
return score
study = optuna.create_study(
study_name="ahc001_8",
storage="sqlite:///db.sqlite3",
load_if_exists=True,
direction="maximize")
study.optimize(objective, n_trials=100)
使い方はこんな感じ。trialを受け取る関数の中で、trial.suggest_floatやtrial.suggest_intでパラメタを取得し、そのパラメタでスコアを計算して返す。pwntoolsは本来はCTFでリモートのサーバーを攻撃するために使うライブラリだけど、ローカルのプログラムを起動して入出力するにも便利なので使っている。パラメタに対してスコアさえ返せば、実装は何でもOK。後はOptunaがパラメタを良い感じに探索してくれる。
storageとload_if_existsの設定は無くても良いのだけど、設定しておけば途中で止めて再開しても良くなるし、同じスクリプトを複数動かせばそれだけで並列化できて便利。複数動かすときはコンパイル結果が衝突すると困るのでプログラム名を変えたほうが良いかも。
$ pip install optuna-dashboard
$ optuna-dashboard sqlite:///db.sqlite3
でブラウザから様子を確認できる。
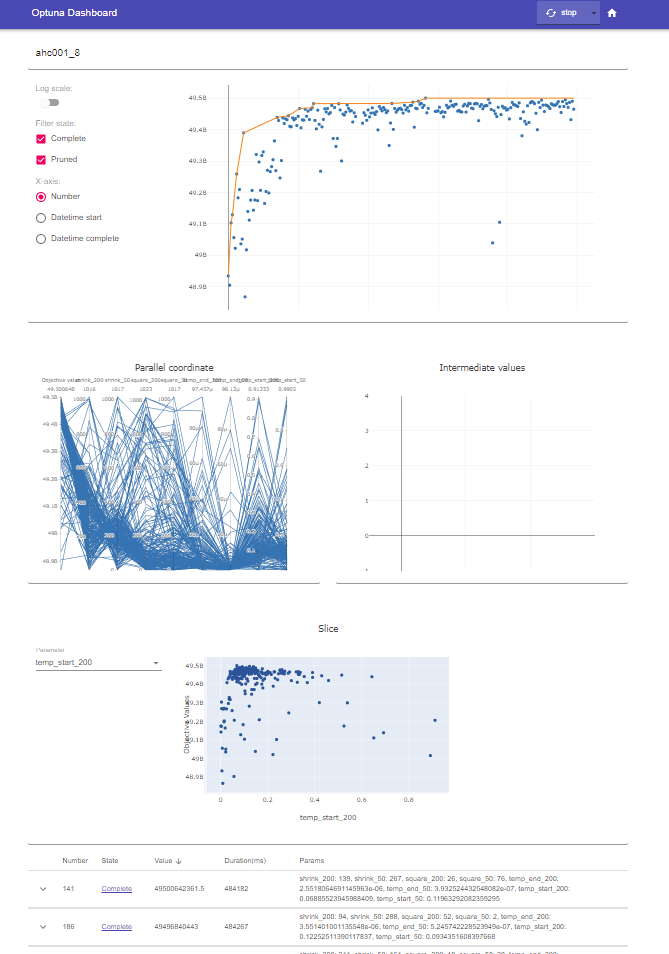
ただ……スコアの計算に誤差があることを考慮してくれていない(と思う)のが問題。本来の用途は機械学習のハイパーパラメタを探索するためのもので、機械学習だとハイパーパラメタに対して収束の様子はそんなにブレないのかもしれない。グラフの上側の包絡線を見て「temp_start_200の値は0.1くらいが良いかな」と思うけど、これ、たまたま良い結果が出てその周辺が多く探索されているだけの可能性もあるんじゃないだろうか。
1回の試行あたり1ケースを試すようにしたら、必要な回数を自動的に試行してほしい。PFN頼む~🙏
— kusanoさん@がんばらない (@kusano_k) March 14, 2021
そういうのを解決してくれるマラソンマッチ用パラメタ探索ツールを誰か作ってほしい ![]()
変更Xを追加したときに、各遷移でXを適用する確率をパラメタにして、パラメタの探索結果が0に近づいたら「この変更は要らないね」という使い方もできるのではないかと思う。
一方で、上の焼き鈍しの開始温度はわりと差が出ているパラメタだけど、それでも0.2%ほど。最後に一晩回すくらいの使い方でも良いかもしれない。
両側を同時に縮める(ボツ)
対して結果が変わらなかったのでボツ。
パラメタをnによって変える
平均0.9896G点。
結果の見た目もだいぶ違うのに、n=50とn=200で同じパラメタというのは無理があるよね。Optunaの探索の結果、焼き鈍しの温度はわりと差が大きかったので、指数的に、その他は線形で変化。そもそも理屈が良く分かっていないから、線形が良いのか、二乗に比例が良いのかとか分からん。もう、これもOptuna先生に訊けば良かったか。
広告を消す(ボツ)
平均0.9897点。
消すというか、指定された点を覆うのを諦めて、最後に1x1にしてどこか空いているところに置く。
だいたい満点の99%近いところで戦っているわけである。ある広告が0点になると、n=50ならば2%、n=200でも0.5%のマイナス。これは無いよなぁと思う。とはいえ、もう他に思いつくことも無いし試しにやってみた。
意外と結果が悪くない。消した広告が最後に残ることはほとんどないのに。行き詰まったときに一旦消すと何かがリセットされて上手く行くのかもしれない。
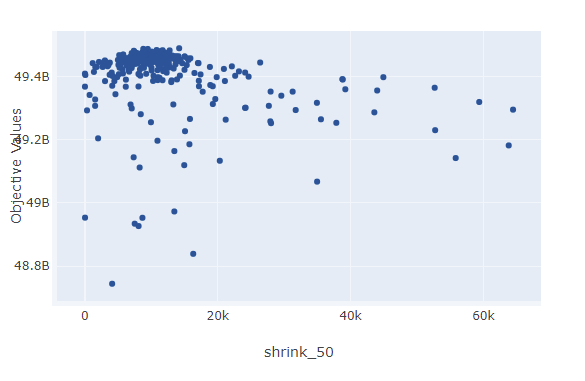
Optunaも、広告の伸縮の代わりに消す確率は1/6くらいが良いのでは?と言っている。とはいえ、明確に良くなるわけでもない。この確率が0に近づくわけでもないのに点数が上がりはしないのは、消すことに伴う処理の追加が重いせいだろうか。
結果がほとんど変わらないなら、処理は単純なほうが良いだろうということでボツ。公式のビジュアライザは、広告が指定された点を覆っていないと警告を出してくるんだよね。消すのが作問者の想定なら、いちいちメッセージを出してはこないだろう、というメタ読みもある。
rectangle 1 does not contain point 1
やり残したこと
ずっと広告同士は絶対に重ならないようにするという前提だった。重なっても良いけどスコアはマイナス、とすると良い感じになったかもしれない。でも重なると何かと処理が面倒になるし、問題のスコア計算とは別のスコアをどう扱って良いのか分からなかった。