Deep Learningは大量のデータを学習する学習フェーズと、学習した結果を用いて推論するフェーズに分かれます。
その中でも学習にかかるコスト、要するに学習時間が非常にかかりハイグレードのGPUを用いても数日から数週間かかることもまれではありません。Deep Neural Networkは文字通りNeural Networkが多層連なったもので、そのうちのConvolution Layerが計算量の多い行列の乗算を行うため色々と工夫されています。
行列A(M x K)と行列B(K x N)の乗算ではM x N x K回の積和演算を行います。高速な物体認識を行うYOLOでも以下のような回数の積和演算(MAC: Multiply Accumlate)が必要となるのです。
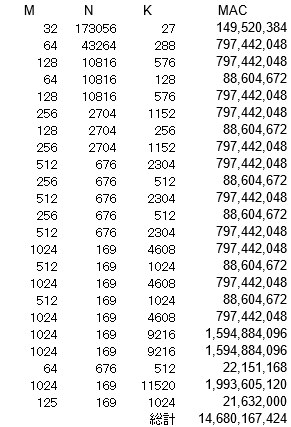
WinogradとFFT
Convolution LayerでWinogrdやFFTで別の空間に投影(変換)すると乗算の回数を減らすことができ、特にFFTでは行列の要素数が大きくなるほど絶大な効果を発揮します。NVIDIAが提供しているcuDNNでもこのWinogrdやFFTを用いるモードが実装されています。
ただ、この別空間に投影した場合、元に戻す処理が発生します。もし、この投影と逆投影を最初と最後だけにできればその恩恵にあずかることができるのでは、と提案されたのがFourier Convolutional Neural Network(FCNN)です。
ただ、比較的Network構成が簡単なAlexNetやVGGであっても、ReLUやMax Poolongをはさんでおり、この部分を変換されたFourie空間で行う方法が必要になります。
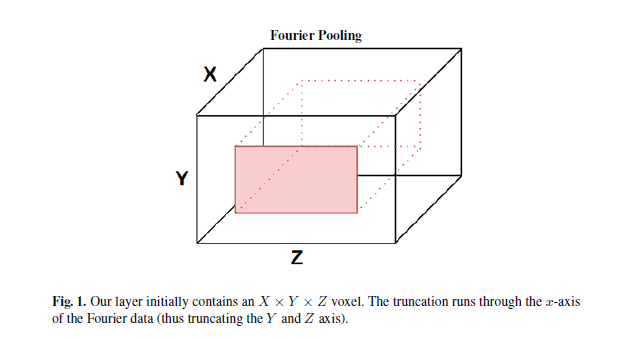
この図でのピンク部分を取り出す操作はローパスフィルターで、この論文ではFourier Poolingと呼んでおり、演算自体が必要なくなります。
提案されたFCNNではAlexNetにおいてMax Poolongの代わりにFourie Poolingを使用し、エポックあたりの処理時間が通常のConvolutionの2435秒から65秒(画像サイズ:512の場合)に高速化されています。
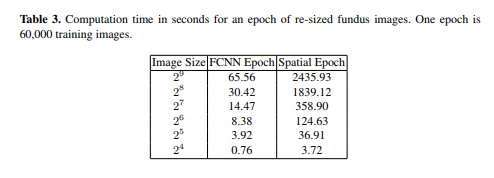
にわかには信じがたい高速化なんですが、もう一つ同様の論文があります。
Reducing Deep Network Complexity with Fourier Transform Methods
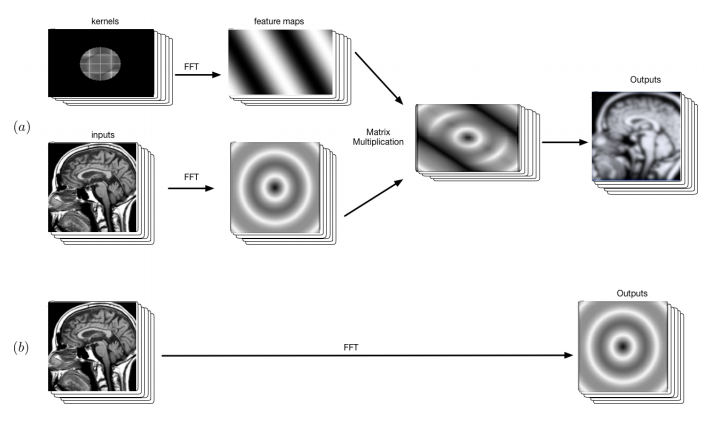
図の(a)はcuDNNに実装されているFFTモードを使用した場合のConvolution Layerの処理を示しており、入力側でFFT,出力側でIFFT(FFTの逆変換)になります。畳み込み演算自体は早くなりますが、入力および出力時の変換処理がオーバーヘッドとなります。
図の(b)が入力時にFFTを行い、周波数空間のまま次のレイヤーに処理を渡し、全てのDeep Neural Networkを周波数空間の演算としています。論文によれば推論側でもこの周波数空間のまま保存したNeural Networkを使用しているとのことです。
気になるMax PoolongをFourier Poolingに置き換えた場合の誤差も問題ないようです(というか減少してる)。

githubにもソースコードがリンクされているのですが、なぜか現在削除されており、追試するための情報が不足しています。
Very Efficient Training of Convolutional Neural Networks using Fast Fourier Transform and Overlap-and-Add
実際にFFTとその拡張版OaAを使用した場合の性能があったので紹介。
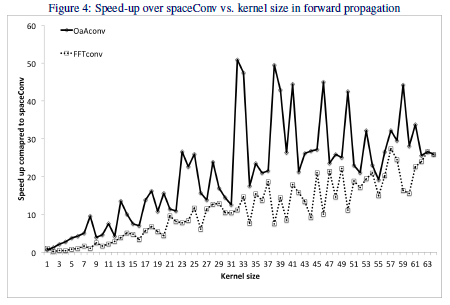
この図の縦軸は通常の畳み込みを行った場合との高速化倍率、横軸はカーネルサイズで、カーネルサイズが大きくなるほどFFTとその拡張版のOaAによる畳込みの効果が大きくなっている。ただし、VGGなどのよく用いられているモデルでのカーネルサイズは3なので、そのサイズの場合はそれほどご利益はない。