はじめに
前回記事はこちら
前回まではプロジェクトチーム編成的なアサイン最適化について問題を作って解いていましたが、
今回は、プロジェクト内のタスクをメンバーに振り分けるタスクスケジューリングを問題として取り扱ってみます。
数ヶ月間のプロジェクトにて存在するタスクをメンバーの工数や勤務時間等に合わせて、最適化するような問題として想定しました。
問題設定
- メンバー数:5人
- 1人辺りの月工数:14~18人日(平均16人日分)
- タスク数:50件(4~5人日のタスクを設定)
- タスクの合計工数:80人日分(メンバーの工数は70人日 10人日分マージンあり)
- タスクの締め切り:週単位で締め切りを設定
複数メンバーに対し、月上限を超えず、かつ週の稼働も過不足が出にくいように配分し、さらに締切を遵守するスケジューリングを行います。
こちらの問題設定に辺り以下のようなデータの作成をしました。
tasks.csv
このcsvファイルにはタスクの一覧と、それぞれのタスクについての工数(人日)と締切の週が記載されています。(実際のデータは記事の一番下に記載しています。)
| task_id | effort | due_week |
|---|---|---|
| T01 | 4 | 1 |
- task_id:タスクのID
- effort: 工数(人日単位)
- due_week: (締切、数値の週までに終わらせる必要がある)
members.csv
このcsvファイルでは、メンバーの月ごとの工数上限が記載されています。
| member_id | cap_month_m1 | cap_month_m2 | cap_month_m3 |
|---|---|---|---|
| P01 | 18 | 18 | 18 |
| P02 | 17 | 17 | 17 |
- member_id: メンバーのID
- cap_month_m1, cap_month_m2, cap_month_m3: それぞれの月の稼働上限(人日単位)
weeks.csv
このcsvファイルでは、月と週の関係が記載されています。
本来は週ごとの営業日数に差異があると思いますのが、今回は簡単のため全ての週を5日としています。
| week_id | month_idx | weekday_count |
|---|---|---|
| 1 | 1 | 5 |
| 2 | 1 | 5 |
- week_id: 週のID
- month_idx: 該当する月のID
- weekday_count: 週の日数
この記事での記号と定義
集合
- $\mathcal{T}$ :タスク集合(例:$|\mathcal{T}|=50$)
- $\mathcal{P}$ :メンバー集合(例:$|\mathcal{P}|=5$)
- $\mathcal{M}={1,2,3}$ :月インデックス
- $\mathcal{W}$ :週ID集合(
weeks.csvで定義) - $\mathcal{W}(m)={,w\in\mathcal{W}\mid \text{month}(w)=m,}$:月 $m$ に属する週
- $\mathcal{U}_t={1,\dots,E_t}$:タスク $t$ を 1人日ユニットに分割した添字集合
入力パラメータ
- $E_t\in\mathbb{Z}_{\ge1}$:タスク $t$ の総人日(例:4, 5, …)
- $C_{p,m}\in\mathbb{R}_{>0}$:メンバー $p$ の月 $m$ の稼働上限(人日)
- $d_t\in\mathbb{Z}_{\ge1}$:タスク $t$ の締切週ID(
weeks.csvのweek_id) - $\text{month}(w)\in\mathcal{M}$:週 $w$ が属する月
- $\text{wim}(w)\in{1,2,3,4}$:週 $w$ の「月内の第何週」
- $\text{days}(w)\in{3,4,5}$:週 $w$ の稼働日数
- 週キャパ(稼働上限から週あたりで稼働できる時間)
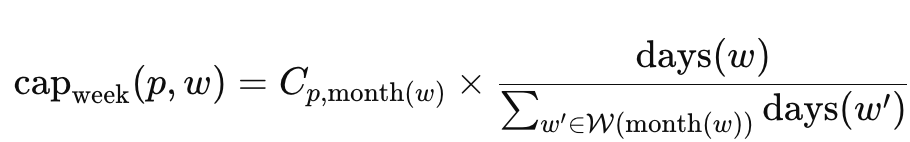
変数(step1:月の最適化)
- $x_{t,p,m}\in{0,1}$ :タスク $t$ をメンバー $p$ の 月 $m$ に丸ごと割り当て
- 月の over-onlyスラック(離散・非負):$s_{\text{month}}(p,m)\in\mathbb{Z}_{\ge0}$
(超過分のみを表現。実装はビット和)
変数(step2:週の最適化)
※ Step1 の解で決まった $\mathcal{R}={(t,p,m)\mid x_{t,p,m}=1}$ を前提に最適化。
- $y_{t,p,m,w,u}\in{0,1}$ :ユニット $u\in\mathcal{U}_t$ を 月 $m$ 内の週 $w$ に置く
- 週の over-only スラック(離散・非負):$s_{\text{week}}(p,w)\in\mathbb{Z}_{\ge0}$
二段最適化のため、週の QUBO には $x$ は登場しません($x$ は確定済み)。
問題を解いてみる
今回の問題ですが、一気にタスクを各メンバーに対して、「全タスクが重複なくメンバーに振られる」かつ「月の稼働を超えない」かつ「週の稼働を超えてない」かつ「締切を遵守」とするとかなりQUBOが長くなり、うまく問題を解くことができませんでした。そのため段階を踏んでタスクの振り分けを行って行きます。
1つ目は以下のように月の工数を超過しないように、各メンバーに対してタスクを振り分けるイメージです。
2つ目に、1つ目で振り分けられた月毎のタスクについて、週の稼働時間を超過しないようにタスクを振り分ける2段階のイメージになります。
締切の部分については、今回設定するバイナリ変数を作る際に、そもそも締切週以降については、タスクを振り当てられないように変数を生成しないようにします。こうすることで締切違反や、単純に変数数が減るため若干ではありますがqubo式を簡単にできると考えています。
step1の制約項
1) タスク一意割当(タスクがどこかの月に1つだけ)
$$
H_{\text{task}}(t) =
A \cdot (\sum_{p \in \mathcal{P}}\sum_{m\in\mathcal{M}_t^{\text{feas}}}x _{t,p,m} - 1 )^2
$$
単純なイメージとして、タスクに対して、
メンバーの集合[P01, P02, P03, P04, P05]に対して、
月の集合[M01, M02, M03]に対して、そのタスクをやるかやらないかを0, 1のバイナリで決定するような感じです。
ということで、15個くらいのバイナリ変数の中でそのタスクが1つだけ1になっている状態(重複なしでタスクが1つ振られている状態)を作ります。
月キャパ(over-only)
$$
H_{\text{month-over}}(p,m) =
B_{\text{month}}\cdot\Bigl(L_{\text{month}}(p,m)-C_{p,m}-s_{\text{month}}(p,m)\Bigr)^2
+\varepsilon_{\text{month}}\cdot s_{\text{month}}(p,m)
$$
月キャパについては、月の稼働日数に対して割り振ったタスクの工数($L_{month}(p, m)$)が超過しないようにするための制約項となります。
超過しないようにということで、月稼働日数に対して数値を合わせるような等式制約の条件ではなく、
月の稼働日数以下の値であればOKのような不等式制約としています。
また、不等式制約のみであると月に振られる工数が1人日とか2人日か小さい稼働でもOKとなり、
月毎の稼働にばらつきが出る可能性があり、それを防ぐために2項目の調整を行っております。
可能な限り稼働上限を超えないように、かつ稼働予定日数から大きく離れないように、
スラック変数で決定された値を用いて調整を行っています。
step1のqubo式
$$
H_{\text{Step1}} =
\sum_{t\in\mathcal{T}} H_{\text{task}}(t)
+
\sum_{p\in\mathcal{P}}\sum_{m\in\mathcal{M}} H_{\text{month-over}}(p,m)
$$
step2の制約項
1) ユニット一意割当
$$
H_{\text{unit}}(t,p,m,u)=
A_{\text{week}}\cdot(\sum_{w\in\mathcal{W}_t^{\text{feas}}(m)} y _{t,p,m,w,u}-1)^2
$$
月の時と同様に、月に振られたタスクを週毎に対して再振り分けをするようなイメージです。
また振ったタスク自体を1人日単位に全て分割してユニットとして取り扱います。
(5人日分のタスクであればユニットを5つに分割して、週のどこかに振り分け、5人日分のユニットが全てどこかの週にちゃんと割り当てられたのかを確認しています。)
2) 週キャパ(over-only)
$$
H_{\text{week-over}}(p,w) = B_{\text{week}}\cdot(L _{\text{week}}(p,w)-\text{cap} _{\text{week}} {(p, w)} -s _{\text{week}}(p,w))^2 +\varepsilon _{\text{week}}\cdot s _{\text{week}}(p,w)
$$
週キャパも月キャパと同じ考えです。
週の稼働上限と割り振られたタスクの工数($L_{week}(p, w)$)を確認して超過させない、かつ週の稼働に大きな差が出ないように調整をする制約項です。
step2のqubo式
$$
H_{\text{Step2}} =
\sum_{(t,p,m)\in\mathcal{R}}\sum_{u=1}^{E_t} H_{\text{unit}}(t,p,m,u)
+
\sum_{p\in\mathcal{P}}\sum_{w\in\mathcal{W}} H_{\text{week-over}}(p,w)
$$
プログラム
PyQUBOとOpenJijのSQAで以下のようにプログラムを作成しました。
今回のプログラムはQUBOが2つ出ることもありdetails内に記載しておりますので開いてご確認ください。
プログラム
import argparse
from math import ceil, log2
import time
import numpy as np
import pandas as pd
from pyqubo import Binary
import openjij as oj
def month_list():
return [1, 2, 3]
def make_weeks_df(weeks_path: str|None):
"""Return weeks dataframe with columns [week_id, month, week_in_month, weekday_count]."""
if weeks_path:
df = pd.read_csv(weeks_path).copy()
if "month" not in df.columns:
if "month_idx" in df.columns:
df = df.rename(columns={"month_idx": "month"})
else:
raise ValueError("weeks.csv must have 'month' or 'month_idx' column.")
if "weekday_count" not in df.columns:
df["weekday_count"] = 5
df = df.sort_values(["month", "week_id"]).copy()
if "week_in_month" not in df.columns:
df["week_in_month"] = df.groupby("month").cumcount() + 1
cols = ["week_id","month","week_in_month","weekday_count"]
return df[cols].astype({"week_id": int, "month": int, "week_in_month": int, "weekday_count": int})
# default 3x4, 5 weekdays each
rows=[]; wid=1
for m in month_list():
for w in range(1,5):
rows.append({"week_id": wid, "month": m, "week_in_month": w, "weekday_count": 5}); wid+=1
return pd.DataFrame(rows)
def build_members(members_df):
mems = []
cap_sum = 0.0
for r in members_df.itertuples(index=False):
caps = {1: float(getattr(r, "cap_month_m1")),
2: float(getattr(r, "cap_month_m2")),
3: float(getattr(r, "cap_month_m3"))}
mems.append({"id": getattr(r, "member_id"), "cap_m": caps})
cap_sum += sum(caps.values())
share = {(me["id"], m): (me["cap_m"][m] / cap_sum if cap_sum>0 else 1.0/(len(mems)*len(month_list())))
for me in mems for m in month_list()}
return mems, share
def due_maps(tasks_df, weeks_df):
"""Return dicts: due_month[t], due_week[t] based on tasks.due_week (global week_id)."""
w2m = weeks_df.set_index("week_id")["month"].to_dict()
due_m = {}
if "due_week" in tasks_df.columns:
for r in tasks_df.itertuples(index=False):
dw = int(getattr(r, "due_week"))
if dw in w2m: due_m[r.task_id] = int(w2m[dw])
due_w = {}
if "due_week" in tasks_df.columns:
for r in tasks_df.itertuples(index=False):
due_w[r.task_id] = int(r.due_week)
return due_m, due_w
SCALE = 10 # fixed scaling to handle fractional caps in integer QUBO
def solve_month_stage(args, tasks_df, members_df, due_month_map):
mems, share = build_members(members_df)
eff = {row.task_id: float(row.effort) for row in tasks_df.itertuples(index=False)}
# decision vars (respect hard deadline by skipping months > due_month)
x = {}
for t in tasks_df["task_id"]:
for me in mems:
pid = me["id"]
for m in month_list():
if t in due_month_map and m > due_month_map[t]:
continue # HARD deadline: don't create variables beyond due month
x[(t,pid,m)] = Binary(f"x_{t}_{pid}_m{m}")
# binary slack bits for "over-only" monthly capacity
def cap_scaled(pid, m):
cap = next(me for me in mems if me["id"]==pid)["cap_m"][m]
return int(round(cap * SCALE))
max_cap_scaled = max(cap_scaled(me["id"], m) for me in mems for m in month_list())
bits_m = max(1, ceil(log2(max_cap_scaled + 1))) if max_cap_scaled>0 else 1
sp = {(me["id"], m, b): Binary(f"sp_{me['id']}_m{m}_b{b}") for me in mems for m in month_list() for b in range(bits_m)}
def slack_over_val(pid, m):
return sum((2**b) * sp[(pid,m,b)] for b in range(bits_m))
def monthly_load_scaled(pid, m):
val = 0
for t in tasks_df["task_id"]:
if (t,pid,m) in x:
val += int(round(eff[t] * SCALE)) * x[(t,pid,m)]
return val
A, Bm, eps = args.A, args.Bm, args.eps
H = 0
# (1) unique assignment per task
for t in tasks_df["task_id"]:
vars_t = [x[(t,pid,m)] for pid in [me["id"] for me in mems] for m in month_list() if (t,pid,m) in x]
# Guard: in case of impossible deadline, allow any month to keep feasibility
if not vars_t:
for me in mems:
pid = me["id"]
for m in month_list():
x[(t,pid,m)] = Binary(f"x_{t}_{pid}_m{m}")
vars_t.append(x[(t,pid,m)])
H += A * (sum(vars_t) - 1) ** 2
# (2) monthly capacity (over-only) L - cap - sp = 0 + eps * sp
for me in mems:
pid = me["id"]
for m in month_list():
H += Bm * (monthly_load_scaled(pid,m) - cap_scaled(pid,m) - slack_over_val(pid,m)) ** 2
for b in range(bits_m):
H += eps * ((2**b) * sp[(pid,m,b)])
# compile & normalize
model = H.compile()
qubo, _ = model.to_qubo()
max_abs = max(abs(v) for v in qubo.values()) if qubo else 1.0
if max_abs > 0:
qubo = {k: v/max_abs for k,v in qubo.items()}
# SQA sampling (Step1)
if args.seed1 is not None:
import random as _rnd
np.random.seed(args.seed1); _rnd.seed(args.seed1)
sampler = oj.SQASampler()
s_vals = np.linspace(0.0, 1.0, args.sweeps1, dtype=float)
schedule = [(float(si), 1) for si in s_vals]
result = sampler.sample_qubo(
qubo, num_reads=args.reads1, num_sweeps=args.sweeps1, seed=args.seed1,
schedule=schedule, trotter=8
)
print("step1 schedule:", result.info.get("schedule"))
best = result.first.sample
# decode (capacity-aware tie-break)
caps = {(me["id"], m): me["cap_m"][m] for me in mems for m in month_list()}
used = {(me["id"], m): 0.0 for me in mems for m in month_list()}
rows = []
for t in tasks_df["task_id"]:
cand = []
for me in mems:
pid = me["id"]
for m in month_list():
if (t,pid,m) not in x:
continue
v = int(best.get(f"x_{t}_{pid}_m{m}", 0))
cand.append((v, pid, m))
if not cand:
for me in mems:
pid=me["id"]
for m in month_list():
cand.append((0,pid,m))
vmax = max(v for v,_,_ in cand)
e_t = float(tasks_df.loc[tasks_df.task_id==t,"effort"].values[0])
if vmax > 0:
ones = [(pid,m) for v,pid,m in cand if v==vmax]
fit = [(pid,m) for (pid,m) in ones if (caps[(pid,m)] - used[(pid,m)]) >= e_t]
if fit:
pid, m = max(fit, key=lambda pm: (caps[pm]-used[pm], -used[pm]))
else:
def overload(pm): return max(0.0, used[pm] + e_t - caps[pm])
pid, m = min(ones, key=lambda pm: (overload(pm), used[pm]))
else:
fit0 = [(pid,m) for _,pid,m in cand if (caps[(pid,m)] - used[(pid,m)]) >= e_t]
if fit0:
pid, m = max(fit0, key=lambda pm: (caps[pm]-used[pm], -used[pm]))
else:
def overload(pm): return max(0.0, used[pm] + e_t - caps[pm])
pid, m = min([(pid,m) for _,pid,m in cand], key=lambda pm: (overload(pm), used[pm]))
rows.append({"task_id": t, "member_id": pid, "month": m, "effort": e_t})
used[(pid,m)] += e_t
assign_df = pd.DataFrame(rows).sort_values(["month","member_id","task_id"])
monthly_usage = build_monthly_usage(assign_df, mems)
return assign_df, monthly_usage, mems
def build_monthly_usage(assign_df, mems):
rows=[]
for me in mems:
pid = me["id"]
for m in month_list():
used = float(assign_df[(assign_df.member_id==pid) & (assign_df.month==m)]["effort"].sum())
rows.append({"member_id": pid, "month": m, "used_days": round(used,2), "cap_days": round(me["cap_m"][m],2)})
return pd.DataFrame(rows).sort_values(["member_id","month"])
# ---------------------- Week stage (hard + over-only) ----------------------
def solve_week_stage(args, month_assign_df, members_df, weeks_df, due_week_map):
mems, _ = build_members(members_df)
# per-month weekday sum
month_weekday_sum = weeks_df.groupby("month")["weekday_count"].sum().to_dict()
week_weekday = {int(r.week_id): int(r.weekday_count) for r in weeks_df.itertuples(index=False)}
# week capacities per (member, week_id): cap_week = cap_month * (weekday_count / month_total)
cap_week = {}
for me in mems:
for wr in weeks_df.itertuples(index=False):
m = int(wr.month)
wk = int(wr.week_id)
cap_week[(me["id"], wk)] = me["cap_m"][m] * (week_weekday[wk] / month_weekday_sum[m])
# Build unit-day variables for each assigned task; apply hard deadline by limiting weeks
y = {}
for r in month_assign_df.itertuples(index=False):
t, pid, m, e = r.task_id, r.member_id, int(r.month), int(round(r.effort))
weeks_m_all = weeks_df[weeks_df["month"]==m]["week_id"].astype(int).tolist()
weeks_m = weeks_m_all
if t in due_week_map:
weeks_m = [w for w in weeks_m_all if w <= int(due_week_map[t])]
if not weeks_m: # if impossible, keep all to stay feasible
weeks_m = weeks_m_all
for u in range(1, e+1):
for w in weeks_m:
y[(t,pid,m,w,u)] = Binary(f"y_{t}_{pid}_m{m}_w{w}_u{u}")
# Slack bits per (pid, week_id) for over-capacity (weekly)
bits_w = 3
spw = {(me["id"], wr.week_id, b): Binary(f"spw_{me['id']}_w{wr.week_id}_b{b}")
for me in mems for wr in weeks_df.itertuples(index=False) for b in range(bits_w)}
def slack_over_week(pid, w):
return sum((2**b) * spw[(pid,w,b)] for b in range(bits_w))
def week_load(pid, w):
val = 0
for r in month_assign_df.itertuples(index=False):
t, p2, m = r.task_id, r.member_id, int(r.month)
if p2 != pid: continue
e = int(round(r.effort))
for u in range(1, e+1):
key = (t,pid,m,w,u)
if key in y:
val += y[key]
return val
Aw, Bw, epsw = args.Aw, args.Bw, args.epsw
H = 0
# (1) each unit-day chooses exactly one feasible week
for r in month_assign_df.itertuples(index=False):
t, pid, m, e = r.task_id, r.member_id, int(r.month), int(round(r.effort))
weeks_m_all = weeks_df[weeks_df["month"]==m]["week_id"].astype(int).tolist()
weeks_m = weeks_m_all
if t in due_week_map:
weeks_m = [w for w in weeks_m_all if w <= int(due_week_map[t])]
if not weeks_m: weeks_m = weeks_m_all
for u in range(1, e+1):
H += Aw * (sum(Binary(f"y_{t}_{pid}_m{m}_w{w}_u{u}") for w in weeks_m) - 1) ** 2
# (2) weekly capacity (over-only)
for me in mems:
pid = me["id"]
for wr in weeks_df.itertuples(index=False):
w = int(wr.week_id)
H += Bw * (week_load(pid, w) - cap_week[(pid,w)] - slack_over_week(pid, w)) ** 2
for b in range(bits_w):
H += epsw * ((2**b) * spw[(pid,w,b)])
model = H.compile()
qubo, _ = model.to_qubo()
max_abs = max(abs(v) for v in qubo.values()) if qubo else 1.0
if max_abs > 0:
qubo = {k: v/max_abs for k,v in qubo.items()}
# SQA sampling (Step2)
if args.seed2 is not None:
import random as _rnd
np.random.seed(args.seed2); _rnd.seed(args.seed2)
sampler = oj.SQASampler()
s_vals = np.linspace(0.0, 1.0, args.sweeps2, dtype=float)
schedule = [(float(si), 1) for si in s_vals]
result = sampler.sample_qubo(
qubo, num_reads=args.reads2, num_sweeps=args.sweeps2, seed=args.seed2,
schedule=schedule, trotter=8
)
print("step2 schedule:", result.info.get("schedule"))
best = result.first.sample
used_week = {(me["id"], wr.week_id): 0.0 for me in mems for wr in weeks_df.itertuples(index=False)}
wrows = []
for r in month_assign_df.itertuples(index=False):
t, pid, m, e = r.task_id, r.member_id, int(r.month), int(round(r.effort))
weeks_m_all = weeks_df[weeks_df["month"]==m]["week_id"].astype(int).tolist()
weeks_m = weeks_m_all
if t in due_week_map:
weeks_m = [w for w in weeks_m_all if w <= int(due_week_map[t])]
if not weeks_m: weeks_m = weeks_m_all
for u in range(1, e+1):
cand = []
for w in weeks_m:
v = int(best.get(f"y_{t}_{pid}_m{m}_w{w}_u{u}", 0))
cand.append((v, w))
vmax = max(v for v,_ in cand) if cand else 0
if vmax > 0:
ones = [w for v,w in cand if v==vmax]
fit = [w for w in ones if (cap_week[(pid,w)] - used_week[(pid,w)]) >= 1.0]
if fit:
w = max(fit, key=lambda ww: (cap_week[(pid,ww)] - used_week[(pid,ww)], -used_week[(pid,ww)]))
else:
def overload(ww): return max(0.0, used_week[(pid,ww)] + 1.0 - cap_week[(pid,ww)])
w = min(ones, key=lambda ww: (overload(ww), used_week[(pid,ww)]))
else:
fit0 = [w for w in weeks_m if (cap_week[(pid,w)] - used_week[(pid,w)]) >= 1.0]
if fit0:
w = max(fit0, key=lambda ww: (cap_week[(pid,ww)] - used_week[(pid,ww)], -used_week[(pid,ww)]))
else:
def overload(ww): return max(0.0, used_week[(pid,ww)] + 1.0 - cap_week[(pid,ww)])
w = min(weeks_m, key=lambda ww: (overload(ww), used_week[(pid,ww)]))
wrows.append({"task_id": t, "member_id": pid, "month": m, "week_id": int(w), "days": 1.0})
used_week[(pid,w)] += 1.0
week_df = pd.DataFrame(wrows).sort_values(["month","week_id","member_id","task_id"])
# Weekly usage
rows=[]
for me in mems:
pid = me["id"]
for wr in weeks_df.itertuples(index=False):
w = int(wr.week_id); m = int(wr.month)
used = float(week_df[(week_df.member_id==pid) & (week_df.week_id==w)]["days"].sum())
rows.append({"member_id": pid, "week_id": w, "month": m, "used_days": used,
"cap_days": round(cap_week[(pid,w)],2)})
weekly_usage = pd.DataFrame(rows).sort_values(["member_id","week_id"])
return week_df, weekly_usage
# ---------------------- CLI ----------------------
def parse_args():
ap = argparse.ArgumentParser(description="Step3 minimal: Month + Week SQA (hard deadlines, over-only slack)")
ap.add_argument("--tasks", default="tasks.csv")
ap.add_argument("--members", default="members.csv")
ap.add_argument("--weeks", default="weeks.csv")
ap.add_argument("--out_prefix", default="sqa_step3")
# Step1 (Month) SQA
ap.add_argument("--reads1", type=int, default=100)
ap.add_argument("--sweeps1", type=int, default=2000)
ap.add_argument("--seed1", type=int, default=48)
ap.add_argument("--beta1", type=float, default=6.0) # unused with custom schedule
ap.add_argument("--gamma1", type=float, default=0.9) # unused with custom schedule
ap.add_argument("--A", type=float, default=100.0, help="unique assignment (month)")
ap.add_argument("--Bm", type=float, default=120.0, help="monthly capacity (over-only)")
ap.add_argument("--eps", type=float, default=0.3, help="slack cost (month)")
# Step2 (Week) SQA
ap.add_argument("--reads2", type=int, default=100)
ap.add_argument("--sweeps2", type=int, default=2000)
ap.add_argument("--seed2", type=int, default=14)
ap.add_argument("--beta2", type=float, default=6.0) # unused with custom schedule
ap.add_argument("--gamma2", type=float, default=0.9) # unused with custom schedule
ap.add_argument("--Aw", type=float, default=8.0, help="unit-day selection (week)")
ap.add_argument("--Bw", type=float, default=90.0, help="weekly capacity (over-only)")
ap.add_argument("--epsw", type=float, default=0.08, help="slack cost (week)")
return ap.parse_args()
def main():
args = parse_args()
# Seeds for reproducibility
if args.seed1 is not None:
import random as _rnd
np.random.seed(args.seed1); _rnd.seed(args.seed1)
# Load data
tasks = pd.read_csv(args.tasks)
members = pd.read_csv(args.members)
weeks_df = make_weeks_df(args.weeks)
# Schema check
for need, df, nm in [
(["task_id","effort","priority"], tasks, "tasks.csv"),
(["member_id","cap_month_m1","cap_month_m2","cap_month_m3","base_alpha"], members, "members.csv"),
]:
miss=[c for c in need if c not in df.columns]
if miss: raise ValueError(f"{nm} missing columns: {miss}")
# Deadlines (hard)
due_month_map, due_week_map = due_maps(tasks, weeks_df)
# ---------- Stage 1: Month (hard + over-only) ----------
month_df, monthly_usage, mems = solve_month_stage(args, tasks, members, due_month_map)
month_df.to_csv(f"{args.out_prefix}_month.csv", index=False)
monthly_usage.to_csv(f"{args.out_prefix}_monthly_usage.csv", index=False)
print("=== Monthly assignment (head) ===")
print(month_df.head(12).to_string(index=False))
print("\n=== Monthly usage ===")
print(monthly_usage.to_string(index=False))
# Enforce no monthly over-capacity in final decode (stop if violated)
for r in monthly_usage.itertuples(index=False):
if r.used_days > r.cap_days + 1e-5:
print(f"[ERROR] Monthly usage exceeded capacity: member_id={r.member_id}, month={r.month}, used_days={r.used_days}, cap_days={r.cap_days}")
return
# Quick check: all tasks assigned uniquely?
uniq_ok = (month_df["task_id"].nunique() == tasks["task_id"].nunique())
print(f"\n[CHECK] All tasks uniquely assigned? -> {uniq_ok} "
f"({month_df['task_id'].nunique()}/{tasks['task_id'].nunique()})")
dup = month_df.groupby("task_id").size()
dups = dup[dup>1]
if len(dups)>0:
print("[WARN] Duplicate assignments found for tasks:", list(dups.index))
# Month-deadline violations (decode check)
viol_month = []
for r in month_df.itertuples(index=False):
t, m = r.task_id, int(r.month)
if t in due_month_map and m > int(due_month_map[t]):
viol_month.append({"task_id": t, "assigned_month": m, "due_month": int(due_month_map[t])})
if len(viol_month)>0:
vmdf = pd.DataFrame(viol_month)
vmdf.to_csv(f"{args.out_prefix}_deadline_month_violations.csv", index=False)
print(f"[DEADLINE] Month violations: {len(vmdf)} -> {args.out_prefix}_deadline_month_violations.csv")
else:
print("[DEADLINE] Month violations: 0")
# ---------- Stage 2: Week (hard + over-only) ----------
# Use separate seed for step2 to avoid unintended coupling
if args.seed2 is not None:
import random as _rnd
np.random.seed(args.seed2); _rnd.seed(args.seed2)
week_df, weekly_usage = solve_week_stage(args, month_df, members, weeks_df, due_week_map)
week_df.to_csv(f"{args.out_prefix}_week.csv", index=False)
weekly_usage.to_csv(f"{args.out_prefix}_weekly_usage.csv", index=False)
print("\n=== Weekly assignment (head) ===")
print(week_df.head(12).to_string(index=False))
print("\n=== Weekly usage ===")
print(weekly_usage.to_string(index=False))
# Week-deadline violations (decode check): any unit placed after due_week
viol_week = []
for r in week_df.itertuples(index=False):
t = r.task_id
if t in due_week_map and int(r.week_id) > int(due_week_map[t]):
viol_week.append({"task_id": t, "week_id": int(r.week_id), "due_week": int(due_week_map[t]),
"member_id": r.member_id, "month": int(r.month)})
if len(viol_week)>0:
vwdf = pd.DataFrame(viol_week)
vwdf.to_csv(f"{args.out_prefix}_deadline_week_violations.csv", index=False)
print(f"[DEADLINE] Week violations: {len(vwdf)} -> {args.out_prefix}_deadline_week_violations.csv")
else:
print("[DEADLINE] Week violations: 0")
if __name__ == "__main__":
t = time.time()
main()
print(f"\n[ALL DONE] Elapsed time: {time.time() - t:.2f} sec")
パラメータは以下の通りとなります。
1つ目のQUBO:月のステップ
| A | 100.0 |
| Bm | 120.0 |
| eps | 0.3 |
| reads | 100 |
| sweeps | 2000 |
| seed | 48 |
2つ目のQUBO:週のステップ
| Aw | 8.0 |
| Bw | 90.0 |
| epsw | 0.08 |
| reads | 100 |
| sweeps | 2000 |
| seed | 14 |
結果
結果は以下のようなものが得られました。
[CHECK] All tasks uniquely assigned? -> True (50/50)
=== Monthly usage ===
member_id month used_days cap_days
P01 1 17.0 18.0
P01 2 12.0 18.0
P01 3 17.0 18.0
P02 1 17.0 17.0
P02 2 14.0 17.0
P02 3 16.0 17.0
P03 1 12.0 16.0
P03 2 12.0 16.0
P03 3 16.0 16.0
P04 1 13.0 15.0
P04 2 13.0 15.0
P04 3 13.0 15.0
P05 1 12.0 14.0
P05 2 13.0 14.0
P05 3 13.0 14.0
=== Weekly usage ===
member_id week_id month used_days cap_days
P01 1 1 4.0 4.50
P01 2 1 5.0 4.50
P01 3 1 5.0 4.50
P01 4 1 3.0 4.50
P01 5 2 4.0 4.50
P01 6 2 2.0 4.50
P01 7 2 3.0 4.50
P01 8 2 3.0 4.50
P01 9 3 4.0 4.50
P01 10 3 5.0 4.50
P01 11 3 4.0 4.50
P01 12 3 4.0 4.50
P02 1 1 5.0 4.25
P02 2 1 5.0 4.25
P02 3 1 3.0 4.25
P02 4 1 4.0 4.25
P02 5 2 4.0 4.25
P02 6 2 5.0 4.25
P02 7 2 3.0 4.25
P02 8 2 2.0 4.25
P02 9 3 4.0 4.25
P02 10 3 4.0 4.25
P02 11 3 4.0 4.25
P02 12 3 4.0 4.25
P03 1 1 4.0 4.00
P03 2 1 3.0 4.00
P03 3 1 3.0 4.00
P03 4 1 2.0 4.00
P03 5 2 3.0 4.00
P03 6 2 4.0 4.00
P03 7 2 2.0 4.00
P03 8 2 3.0 4.00
P03 9 3 4.0 4.00
P03 10 3 4.0 4.00
P03 11 3 4.0 4.00
P03 12 3 4.0 4.00
P04 1 1 3.0 3.75
P04 2 1 4.0 3.75
P04 3 1 4.0 3.75
P04 4 1 2.0 3.75
P04 5 2 4.0 3.75
P04 6 2 3.0 3.75
P04 7 2 3.0 3.75
P04 8 2 3.0 3.75
P04 9 3 2.0 3.75
P04 10 3 4.0 3.75
P04 11 3 4.0 3.75
P04 12 3 3.0 3.75
P05 1 1 4.0 3.50
P05 2 1 4.0 3.50
P05 3 1 2.0 3.50
P05 4 1 2.0 3.50
P05 5 2 3.0 3.50
P05 6 2 4.0 3.50
P05 7 2 2.0 3.50
P05 8 2 4.0 3.50
P05 9 3 4.0 3.50
P05 10 3 3.0 3.50
P05 11 3 3.0 3.50
P05 12 3 3.0 3.50
今回の問題は最適化問題であるものの結果を見れば正解というか近似解であるかどうかが判断できるものとなります。
最適化したい項目として
- 全てのタスクが重複なく全てのメンバーに振られていること
- 月の稼働時間を超過していないこと
- 週の稼働時間から大きく離れていないこと
上記の3項目が押さえられていることを条件としておりました。
出力を見ていると、全てのタスクが重複なく振られており、
月の稼働時間もそれぞれ設定したメンバーの稼働時間を超過することもなく、
また週の稼働時間は各メンバーの月稼働を4で割った数値として扱っていますが、
一般的な考えで週に5人日が上限になるため、5人日以上になるような例は出力されておらず、
こちらの結果で目的を達成するタスクのスケジューリングをすることができました。
おわりに
今回はタスクスケジューリングを例題として、3ヶ月分のタスクをメンバーに割り振るような問題を作ってquboを解きました。
当初問題設定でタスク毎にスキルや難易度、またメンバーに生産性やスキルなどのマッチング的なものも追加しようと問題を複雑にしようとしておりましたが、今回の単純な例であっても組み合わせ数が非常に大きくなり1つのquboでは解くのが難しくなるなど
問題設定では、quboを分割の分割や、タスクを最初に月毎に分けるような抽象化、簡略化はquboを解く上では重要ということが認識できました。
今後も同じように問題を大規模化していく上で、問題の簡略化や抽象化は意識して検討していけるように、
さらに今回はquboのみでやりましたが、quboに拘らず大規模な部分ではquboで、小さくした後に古典アルゴリズムを使うような
ハイブリッドな構成も考えても良さそうだなと感じました。
引き続き問題設定+quboを解くようなトレーニングは続けていければと思います。
付録
今回扱ったデータ
今回の問題を解く上で使用したcsvファイルを添付?します。
tasks.csv
task_id,effort,due_week
T01,4,1
T02,5,2
T03,4,3
T04,5,4
T05,4,1
T06,4,2
T07,4,3
T08,4,4
T09,4,1
T10,4,2
T11,4,3
T12,4,4
T13,5,1
T14,5,2
T15,5,3
T16,5,4
T17,4,5
T18,4,6
T19,4,7
T20,4,8
T21,4,5
T22,4,6
T23,4,7
T24,4,8
T25,4,5
T26,4,6
T27,4,7
T28,4,8
T29,4,5
T30,4,6
T31,5,7
T32,5,8
T33,4,5
T34,4,9
T35,4,10
T36,5,11
T37,4,12
T38,5,9
T39,4,10
T40,4,11
T41,4,12
T42,4,9
T43,4,10
T44,4,11
T45,4,12
T46,4,9
T47,4,10
T48,4,11
T49,4,12
T50,4,9
members.csv
member_id,cap_month_m1,cap_month_m2,cap_month_m3
P01,18,18,18
P02,17,17,17
P03,16,16,16
P04,15,15,15
P05,14,14,14
weeks.csv
week_id,month_idx,weekday_count
1,1,5
2,1,5
3,1,5
4,1,5
5,2,5
6,2,5
7,2,5
8,2,5
9,3,5
10,3,5
11,3,5
12,3,5