概要
- このサイト
より、インフルエンザの県別の報告数が見ることができます。 - でも、いちいちPDFを開いて見るのは面倒くさい…
- 去年と比べてどのぐらい減ったのか見たいけど、いちいちコピペしてグラフにするの怠い……
- Pythonで全て実行できないか試してみました。
実行結果
-
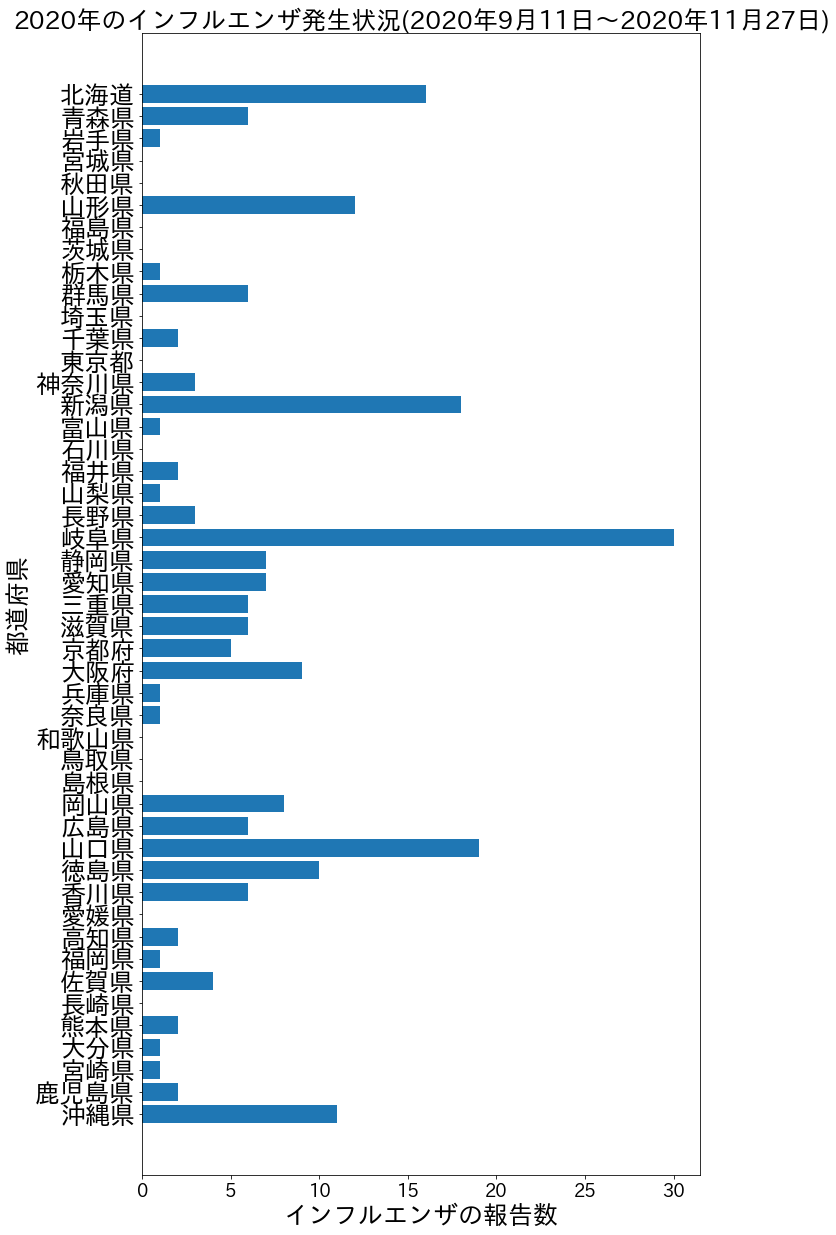
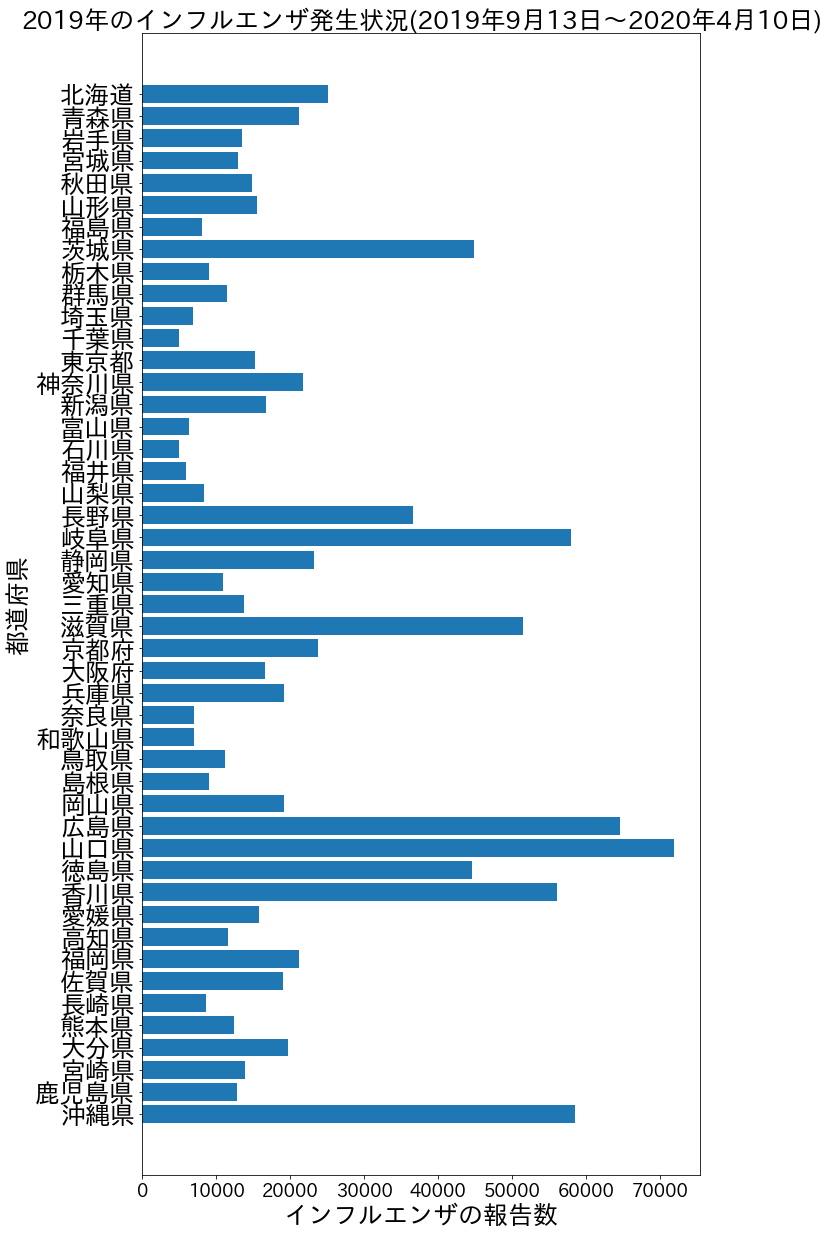
2020年と2019年のグラフの報告数に圧倒的な差がある…。
-
2020年のグラフ
-
2019年のグラフ
コード
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import urllib.request as req
import os
import time
import tabula
import pandas as pd
import requests
import sys
# 入力したurlのBeautifulSoupを返す
def get_bs(url):
res = req.urlopen(url)
bs = BeautifulSoup(res, "html.parser")
return bs
# 入力した年数yearのURLが返す関数
def get_url(year):
url_front = "https://www.mhlw.go.jp"
# インフルエンザに関する報道発表資料 |厚生労働省
url = 'https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/kenkou_iryou/kenkou/kekkaku-kansenshou01/houdou.html'
bs = get_bs(url)
for i in bs.select('div.m-grid__col1'):
for j in i.select("a") :
html_name = j.get_text()
if ("シーズン" in html_name) and (year == html_name.split("/")[0]):
return_url = url_front + j.get("href")
break
return return_url
# 入力した年数yearの年度のPDFのURLがリストで返す関数
def get_year_pdf(year):
url_front = "https://www.mhlw.go.jp"
bs = get_bs(get_url(year))
pdf_list = [[ url_front + j.get("href") , j.get_text().split(" ")[0] ]
for i in bs.select("div.m-grid__col1")
for j in i.select("a")
if "インフルエンザの発生状況について" in j.get_text()]
return pdf_list
# pdfをダウンロードする関数
def download_pdf(pdf_list):
folder_name = pdf_list[-1][1].split("年")[0] + "_data"
if os.path.exists(folder_name) == False:
os.mkdir(folder_name)
for download_url in pdf_list:
time.sleep(1) # 一秒スリープ
file_name = download_url[0].split("/")[-1]
r = requests.get(download_url[0])
# 正常の場合
if r.status_code == 200:
with open(os.path.join(folder_name, file_name), "wb") as f:
f.write(r.content)
pdf_date_list = [[i[0].split("/")[-1],i[1]] for i in pdf_list]
return pdf_date_list
# 指定した内容contentのDataFrameを返す関数
def return_df(pdf,date,content):
dfs = tabula.read_pdf(pdf, lattice=True, pages = 'all')
for i in range(len(dfs)):
if "インフルエンザ" in dfs[i]:
df = dfs[i]
df = df.fillna("県名")
# 「総数」と「昨年同期(総数)」は削除
df = df.drop(df.index[(df.iloc[:,0] == '総数')])
df = df.drop(df.index[(df.iloc[:,0] == '総 数')])
df = df.drop(df.index[(df.iloc[:,0] == '昨年同期(総数)')])
# indexを揃えなおす
df = df.reset_index(drop=True)
# 県名のみを返す
if content == "prefecture":
df = df.iloc[:,:-2]
df = df.dropna(how='any')
df = df.replace(" ","", regex = True)
df = df.replace(" ","", regex = True)
# 報告数のみを返す
elif content == "report":
df = df.iloc[:,:-1]
df = df.dropna(how='any')
df = df.iloc[:,1:]
df = df.replace("報告数",date.split("年")[1])
return df
# PDFをCSV形式に整える関数
def convert_pdf_to_csv(pdf_list):
pdf_date_list = download_pdf(pdf_list)
year_name = pdf_date_list[-1][1].split("年")[0]
folder_name = "\\" + year_name + "_data"
dir_name = os.getcwd() + folder_name +"\\"
df = return_df(dir_name + pdf_date_list[0][0],pdf_date_list[0][1],"prefecture")
for i in pdf_date_list:
df = pd.concat([df, return_df(dir_name + i[0],i[1],"report") ],axis=1)
save_path = os.getcwd() + folder_name +"\\"+"output_data.csv"
df.to_csv(save_path,index=None,header=None,encoding="cp932")
return save_path
# 入力した年数yearのインフルエンザ報告数と都道府県の棒グラフが表示される関数,yearの入力範囲は2010~2020
def make_graph(year):
pdf_date_list = download_pdf(get_year_pdf(year))
save_path = convert_pdf_to_csv(get_year_pdf(year))
df = pd.read_csv(save_path,encoding="cp932")
graph_list = []
for i in df.itertuples():
temp = i[2:]
report_cnt = 0
for j in temp:
if not j in ("-","..."):
j = str(j)
j = j.replace(",","")
report_cnt+=float(j)
graph_list.append([i[1],report_cnt])
first_date = pdf_date_list[-1][1] # 最初の日付
last_date = pdf_date_list[0][1] # 最後の日付
report_num = [i[1] for i in graph_list]
prefecture = [i[0] for i in graph_list]
prefecture.reverse()
fig = plt.figure(figsize=(10,21))
ax = fig.add_subplot(1,1,1)
ax.barh(prefecture,report_num)
plt.title(year + "年のインフルエンザ発生状況" + "(" + first_date + "~" + last_date + ")", fontsize=25)
plt.yticks(fontsize=25)
plt.xticks(fontsize=18)
plt.ylabel('都道府県', fontsize=25)
plt.xlabel('インフルエンザの報告数', fontsize=25)
plt.show()
def main():
year = input("何年のグラフを見ますか?(2010~2020の範囲を入力):") # 2011~2020の範囲
if year.isdecimal() == False:
print("数値以外を入力したため終了します。")
sys.exit() # プログラム終了
if not 2011 <= int(year) <= 2020:
print("範囲外を入力したため終了します。")
sys.exit() # プログラム終了
make_graph(str(year))
if __name__ == '__main__':
main()
まとめ
- コロナの影響でマスク・手洗いする人が増えたから、インフルエンザの数がめちゃくちゃ減ってる!!!