はじめに
データ蓄積→加工→BI表示・・・というデータの可視化・分析の一連の流れを実際にトレーニングするため、今回Symbolブロックチェーンのトランザクションデータの分析に取り組みました。
ゴール
- Symbolブロックチェーンのトランザクション数の過去統計レポートを公開する
- 2021年のローンチ以降から現在までのトランザクションの増減傾向を明らかにする。
- レポートは有償ツールやライセンスを持っていない人でも広く参照できるようにする。
全体構成
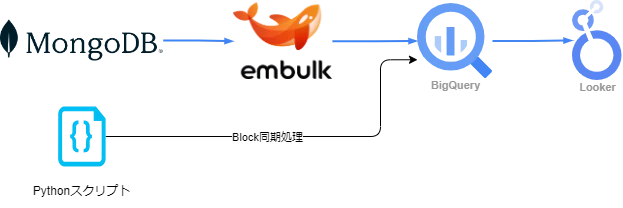
Symbolブロックチェーンのノードから、過去のトランザクションデータ(約240万ブロック分)をEmbulkを用いてBigQueryに抽出。データの可視化や分析レポートの表示はLokkerStudioで行います。また、データ抽出以後もブロックチェーンのトランザクションデータは約30秒ごとに生成されますので、最新データについてはPythonスクリプトによる日次同期処理で取り込みます。
環境
- 外部データソース
- Symbolブロックチェーンノード上のMongoDB
- Embulk実行環境
- Ubuntu 20.04.4 LTS (GNU/Linux 5.4.0-62-generic x86_64)
- Embulk 0.9.25
MongoDB+Embulkによるデータ抽出とBigQueryへの転送
SymbolブロックチェーンノードのMongoDBへの接続
Symbolブロックチェーンのノード内部のデータベースは、通常は外からアクセスすることはできませんが、立ち上げ時の設定を変更することで外部からの接続が可能になります。自身でノードを運用している場合は、下記リンクの手順に従ってノード起動時のデータベース接続許可設定を変更します。
Embulkの環境構築
Javaのインストール
sudo apt install -y openjdk-8-jdk
Embulkのインストール(最新版ではなく、安定版0.9.25を指定)
wget https://github.com/embulk/embulk/releases/download/v0.9.25/embulk-0.9.25.jar -O embulk.jar
sudo mv embulk.jar /usr/local/bin/embulk
sudo chmod +x /usr/local/bin/embulk
パス設定
.bashrcファイルを開き、下記を追加 nano ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH="$JAVA_HOME/bin:$PATH"
export PATH="$HOME/.embulk/bin:$PATH"
変更を反映 source ~/.bashrc
プラグインのインストール
今回インストールするプラグインは下記の3つ
- embulk-input-mongodb
- embulk-filter-expand_json
- embulk-output-bigquery
MongoDBプラグイン
embulk gem install embulk-input-mongodb
Jsonプラグイン
embulk gem install embulk-filter-expand_json
BigQueryプラグイン
embulk 0.9.25環境でBigQueryプラグインをインストールする際に、Rubyのバージョンに起因したインストールエラーが発生する可能性がある。当方の環境ではjwt:2.3.0とpublic_suffix -v 4.0.7を指定することで解消
embulk gem install jwt:2.3.0
embulk gem install public_suffix -v 4.0.7
embulk gem install embulk-output-bigquery
参考リンク
参考リンク
Gemファイルのバージョン違いのエラーが出たとき
Running Embulk version (0.9.25) does not match the installed embulk.gem version (0.11.0).
上記のようなエラーが出たときは、自前のBundleファイルを使ったプラグイン管理を行うか、Bundleを使わない場合はGemファイルを削除すればOK。自分の環境だと、最初にEmbulkの最新Verを入れてから、その後Embulkのバージョンを下げた場合に発生。最新のEmbulkインストール時に最新のGemファイルも一緒にインストールされてしまうことが原因なので、EmbulkのGemファイルを削除することで解消。
sudo rm -r ~/.embulk/lib/gems/gems/embulk-0.11.0-java/
MongoDBとEmbulkの接続(データ読み出し)
読み出しテスト
下記のコンフィグファイルを作成。
in:
type: mongodb
hosts:
- {host: localhost, port: 27017}
database: catapult
collection: blocks
json_column_name: record
limit: 3
filters:
- type: expand_json
json_column_name: record
expanded_columns:
- {name: _id, type: string}
- {name: block, type: json}
out: {type: stdout}
プレビュー確認
embulk preview config.yml
本番実行
embulk run config.yml
EmbulkでのJSONのパース(抽出したいカラムを指定)
MongoDBのコレクションに格納されているJsonデータから、必要なデータを抽出するConfigファイルのサンプルについては下記の通り。embulk-filter-expand_jsonプラグインを使ってJSONをパースし、rename でカラム名を整える。expand_jsonプラグインの設定中では、rootを指定することでそこから目的のカラムを指定することができる。
filters:
- type: expand_json
json_column_name: record
root: "$."
expanded_columns:
- {name: _id, type: string}
- {name: block.timestamp, type: long}
- {name: meta.totalFee, type: long}
- {name: meta.transactionsCount, type: long}
- {name: meta.totalTransactionsCount, type: long}
- {name: block.size, type: long}
- {name: block.height, type: long}
- type: rename
colmuns:
_id: id
block.timestamp: timestamp
meta.totalFee: totalFee
meta.transactionsCount: transactionsCount
meta.totalTransactionsCount: totalTransactionsCount
block.size: size
block.height: height
BigQueryテーブルへの転送
転送先のテーブルを作成
Embulkでロードしたデータを書き込む(転送)する先のテーブルをBigQuery上で作成する。このとき、スキーマの型とEmbulkで読みだしたカラムの仕様がマッチしていないと転送時にエラーになるので注意する。今回のデータ抽出のテーブルスキーマの例は以下の通り。※BigQuery上でのDB、テーブルの作成方法は割愛します。
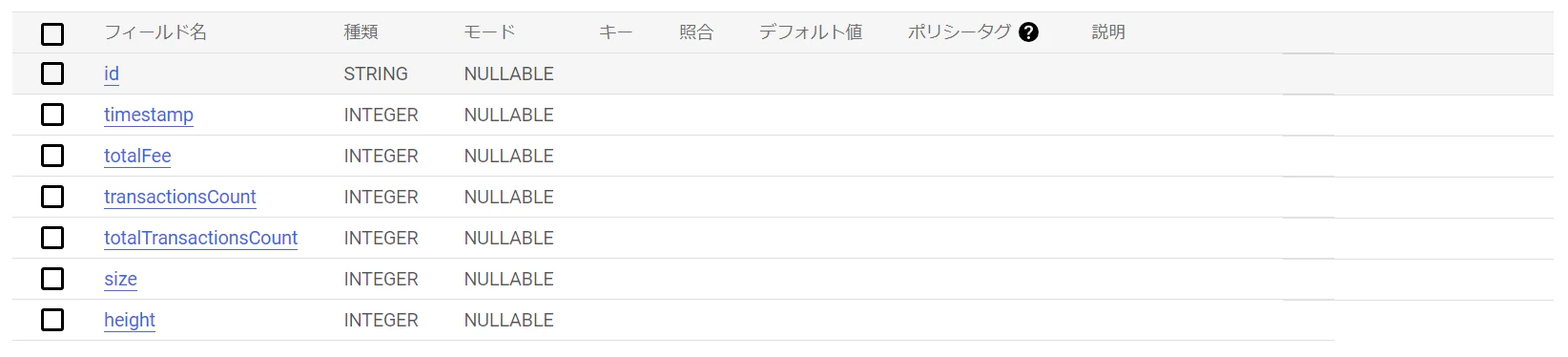
このとき、データの型とモードの指定に注意。特に、MongoDB上でByte列のまま格納されているデータなどを直接BigQueryにロードしようとすると不一致になったり文字化けしたりする。また、BigQuery側で「REQUIRED」に指定していた項目も、なぜかEmbulkからロード時に「NULLABLE」に勝手に変更されるようで、BigQuery側のスキーマ指定を全部「NULLABLE」にするとエラーが消えた事象も確認。※詳しく検証してないので参考までに
テーブルスキーマの指定
データ転送先のテーブルをBigQuery側で作成したら、スキーマ構造をJSON形式でエクスポートして、Embulkの実行環境上に配置。データ抽出のConfigファイルで参照させる。
out:
type: bigquery
auth_method: json_key
json_keyfile: ./bigquery/***.json
project: <プロジェクトID>
dataset: <データセットID>
table: <テーブルID>
auto_create_table: true
schema_file: ./schema.json <- ここでスキーマ定義ファイル参照
location: US
charset: UTF-8
サービスアカウントの有効化
外部からBigQueryのテーブルに書き込むためのサービスアカウントを作成します。作成したサービスアカウントのJSON KeyファイルをEmbulkの実行環境上に配置し、EmbulkのConfigファイル上で参照します(下記)
out:
type: bigquery
auth_method: json_key
json_keyfile: ./bigquery/***.json <- ここにKeyファイルを指定
project: <プロジェクトID>
dataset: <データセットID>
table: <テーブルID>
auto_create_table: true
schema_file: ./schema.json
location: US
charset: UTF-8
BigQueryのテストテーブルの作成、及びサービスアカウントの作成方法についてはこちらの記事が大変詳しく参考になりました。
MongoDBからBigQueryへのデータ転送
これまでの流れをまとめると、config.ymlファイルは大きく以下の3つの構造で設定が記載されることになる。最終的なconfigファイルのサンプルは以下の通り。
in:MongoDBの接続先の指定
filters:JSONのパースとカラム定義
out:BigQueryの接続情報、書込み先テーブルとスキーマ定義
in:
type: mongodb
hosts:
- {host: localhost, port: 27017}
database: catapult
collection: blocks
filters:
- type: expand_json
json_column_name: record
root: "$."
expanded_columns:
- {name: _id, type: string}
- {name: block.timestamp, type: long}
- {name: meta.totalFee, type: long}
- {name: meta.transactionsCount, type: long}
- {name: meta.totalTransactionsCount, type: long}
- {name: block.size, type: long}
- {name: block.height, type: long}
- type: rename
colmuns:
_id: id
block.timestamp: timestamp
meta.totalFee: totalFee
meta.transactionsCount: transactionsCount
meta.totalTransactionsCount: totalTransactionsCount
block.size: size
block.height: height
out:
type: bigquery
auth_method: json_key
json_keyfile: ./bigquery/***.json <- ここにKeyファイルを指定
project: <プロジェクトID>
dataset: <データセットID>
table: <テーブルID>
auto_create_table: true
schema_file: ./schema.json
location: US
charset: UTF-8
上記のconfigファイルをembulk run config.ymlで実行。特に問題なければ、MongoDBからBigQueryのテーブル上へのデータ転送が開始される。ちなみに今回の検証ではSymbolブロックチェーンのトランザクションデータ約240万レコードが、わずか数分(もっと短いかも?)で一発でBigQuery上のテーブルにロードされた。Embulk恐るべし…。
BigQueryでのデータ加工
これはSymbolブロックチェーンの仕様に特有の処理ですのでご参考まで。
SymbolのTimestampをDatetime形式に変換するクエリ
Symbolのブロックに格納されているTimestamp(ブロック生成時刻)は、ネメシスブロック(チェーンの最初のブロック)の生成時刻(UTC)からの経過ミリ秒という仕様になっています。そのままだと時系列での集計などがやりづらいので、Datetime形式に変換します。
INSERT INTO `symbol_db.block_datetime`
SELECT
id AS id,
CAST(FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', TIMESTAMP_SECONDS( 1615853185 + CAST((timestamp /1000) AS INT64)+ 32400000)) AS DATETIME) as datetime
FROM `symbol_db.block_data`
WHERE id IS NOT NULL
日次でのデータ集計
約30秒ごとに生成されたブロックデータを、日単位で集計するクエリの例
SELECT
CAST(datetime AS DATE) day,
SUM(transactionsCount) transactionsCount,
SUM(totalTransactionsCount) totalTransactionsCount
FROM
`symbol_db.joined_block_table`
GROUP BY
day
ORDER BY
day
LookerStudioでのレポート公開
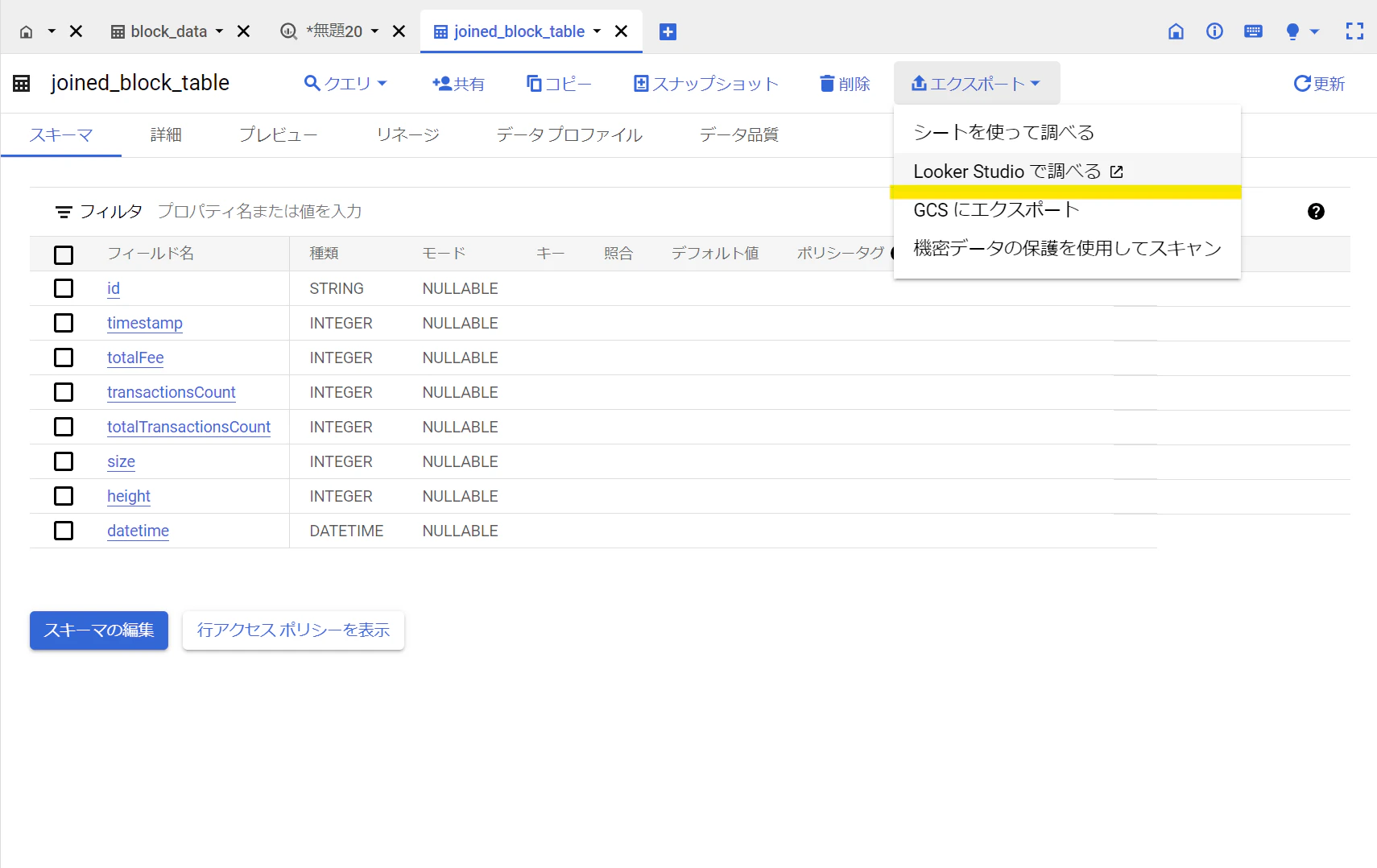
BigQueryのテーブルにまでロードできれば、あとは対象のテーブルをLooker Studioに接続すれば可視化はすぐに行える。対象テーブルを開いて「エクスポート」>「Looker Studioで調べる」ですぐに連携可能。ただ、レポートを外部に公開しようとすると意外とコツが必要。
レポートの外部公開のコツ
一般公開の許可設定
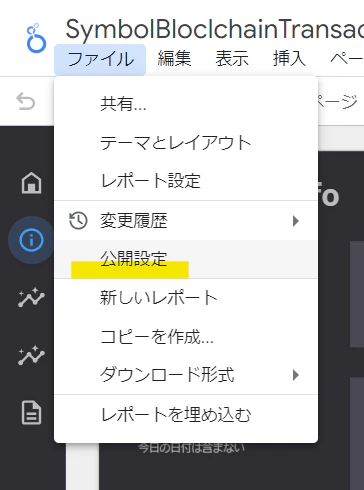
まず一般公開のやり方がわからず。「ファイル」「公開設定」で一般公開を許可する必要があった。それをやらないと、いくら共有リンクを発行してもパブリックには見れない。
BigQuery(データソース側)の公開許可設定
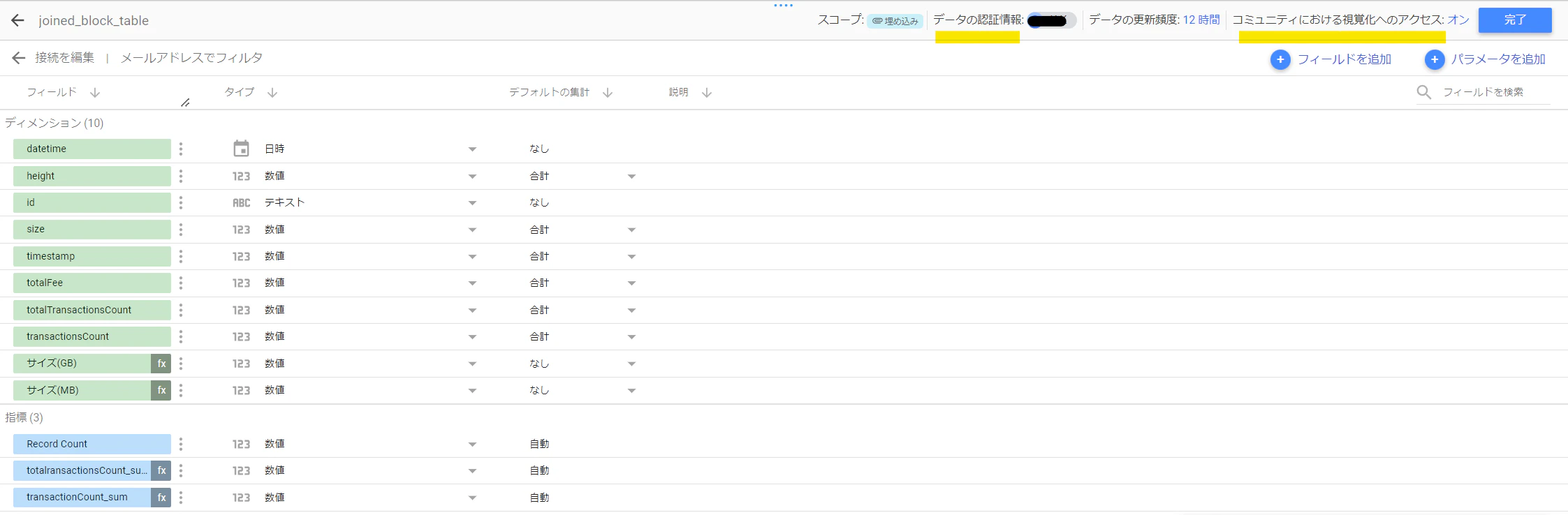
さらに、公開設定をした後も、今度はBigQuery側のデータソースについても設定の追加が必要。「リソース」>「追加済みリソースの管理」から、「データの認証情報」を「閲覧者」ではなく「データオーナー」に変更。あと「コミュニティにおける視覚化へのアクセス」も「オン」に変更。
BigQueryのデータソースも合わせて一般公開
分析レポートだけでなくデータソース側も一般公開する場合は、下記のリンクを参考に、データセットのユーザに「allUsers」を閲覧者として追加する。
Looker Studioでレポート画面を作り込む
ここまでくれば、あとは好きにレポート画面を作り込んで公開するだけです。直感的に操作できるので、シンプルなグラフであればそんなにトレーニングしなくても使えると思います。業務でTableauを触ったことはありましたが、ほぼ同じ感覚で操作できました(むしろブラウザ上でサクサク動いて、大規模データの計算処理もこちらの方が高速でした)
外部に公開するレポートの作成にあたっては、オープンデータを活用したダッシュボードを作成されている事例が非常に参考になりました。
最新ブロックデータの同期処理
ここまでで、約240万ブロック分のデータをBigQuery上で分析・可視化する環境が整いました。これに加えて、今度は30秒ごとに生成されるブロックのデータを日次で同期させる処理を作成します。
本当はEmbulkだけで差分ロードみたいなこともやれるんだと思いますが、今回はPythonでのBigQuery操作も試したかったのであえてPythonでやってみました。
PythonでのBigQuery操作
まず、PythonでBigQueryにアクセスする際の基本操作をまとめたクラスを作成しました。
"""_summary_
BigQuery操作関数をまとめたクラス
"""
from google.cloud import bigquery
# BigQuery操作関数をまとめた自作クラス
class BigQueryController:
# コンストラクタ
def __init__(self, json_path, table_name):
self.client = bigquery.Client.from_service_account_json(json_path)
self.table = self.client.get_table(table_name)
# データを挿入する
def insert_data(self, rows_to_insert):
errors = self.client.insert_rows(self.table, rows_to_insert)
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
# データを取得する
def get_data(self, query):
query_job = self.client.query(query)
return query_job.result()
# データを削除する
def delete_data(self, query):
query_job = self.client.query(query)
return query_job.result()
# データを更新する
def update_data(self, query):
query_job = self.client.query(query)
return query_job.result()
# データを挿入する
def insert_data(self, rows_to_insert):
errors = self.client.insert_rows(self.table, rows_to_insert)
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
このクラスを継承して、今回のBlockデータを格納したテーブルを操作するクラスを実装します。
# bigquery_controllerクラスを継承して、block_table操作用クラスを作成する
from controller.bigquery_controller import BigQueryController
class BlockDataController(BigQueryController):
# コンストラクタ
def __init__(self, json_path, table_name):
super().__init__(json_path, table_name)
# データを挿入する
def insert_data(self, rows_to_insert):
errors = self.client.insert_rows(self.table, rows_to_insert)
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
# 最新ブロックデータを取得する
def get_latest_block_record(self):
table_name = self.table.full_table_id.replace(':', '.')
query = "SELECT * FROM `" + table_name + "` ORDER BY height DESC LIMIT 1"
result = self.get_data(query)
for row in result:
return row
ブロックデータ同期処理の実装
先程のBigQuery操作クラスを使って、テーブルに格納されている最新のブロック高から、ブロックチェーン上の最新のブロック高までの差分データをロードする処理を実装します。
Symbolブロックチェーンは多くのノードがAPIノードとしても機能しているため、チェーン上の最新のブロック高をAPI経由で取得します。
import json
import urllib.request
NODEURL = "https://***:3001"
# Symbolノードから最新のブロック高を取得する関数
def get_latest_height():
try:
req = urllib.request.Request(NODEURL + '/chain/info')
with urllib.request.urlopen(req) as res:
if res.status == 200:
json_data = json.load(res)
return json_data['height']
else:
print(f"HTTPエラー: {res.status}")
return None
except urllib.error.URLError as e:
print(f"通信エラー: {e.reason}")
return None
except Exception as e:
print(f"予期せぬエラーが発生しました: {e}")
return None
あとは、テーブル上の最新のブロック高の次のブロックから、ノードから取得したチェーンの最新ブロックに追いつくまで、ノードのAPIで繰り返しブロックデータを取得していきます。
# heightからブロック情報を取得する関数
def get_blocks( height ):
try:
req = urllib.request.Request(NODEURL + '/blocks/' + str(height))
with urllib.request.urlopen(req) as res:
if res.status == 200:
return json.load(res)
else:
print(f"HTTPエラー: {res.status}")
return None
except urllib.error.URLError as e:
print(f"通信エラー: {e.reason}")
return None
except Exception as e:
print(f"予期せぬエラーが発生しました: {e}")
return None
メイン処理は以下の通り。EmbulkでMongoDBからBigQueryにロードしたときと同様、外部からアクセスするためのサービスユーザの認証Key(JSONファイル)を参照する必要がありますので、予め実行環境に配置しておきます。あとは書込みたいテーブルのIDを指定し、繰り返し書込みを行うだけです。念のため、BigQueryへの書込み回数を軽減するため、1000件データが溜まってから書き込む処理としています。
# メイン処理
if __name__ == "__main__":
# BigQuery操作用クラスのインスタンス生成
json_path = "hoge.json" # BigQueryのサービスユーザ用認証Keyファイルのパス
table_name = "braided-liberty-386707.symbol_db.joined_block_table" # 接続先テーブルID
block_data_controller = bdc.BlockDataController(json_path, table_name) #BigQuery操作用自作クラス
# BigQueryに取り込まれている最新ブロックデータの取得
latest_block_record = block_data_controller.get_latest_block_record()
# 最新ブロックのheightを取得
latest_height = int(latest_block_record[6])
# 最新ブロックの次のブロックのheightを取得
next_height = latest_height + 1
# 以下、最新データに追いつくまで繰り返し実行
stop_height = int(get_latest_height())
if stop_height:
pass
else:
print("ブロックデータの取得に失敗しました。")
exit()
rows_to_insert = []
while True:
print("next_height:" + str(next_height))
# ブロック情報の取得
block_info = get_blocks(next_height)
if block_info:
pass
else:
print("ブロックデータの取得に失敗しました。")
exit()
# 書き込み用ブロックデータの作成
block_data = {
"id": str(block_info["id"]),
"timestamp": int(block_info["block"]["timestamp"]),
"totalFee": int(block_info["meta"]["totalFee"]),
"transactionsCount": int(block_info["meta"]["transactionsCount"]),
"totalTransactionsCount": int(block_info["meta"]["totalTransactionsCount"]),
"size": int(block_info["block"]["size"]),
"height": int(block_info["block"]["height"]),
"datetime": get_datetime(int(block_info["block"]["timestamp"]))
}
rows_to_insert.append(block_data)
# 1000件溜まるか、最新ブロックに追いついたらテーブルに書き込み
if len(rows_to_insert) >= 1000 or next_height >= stop_height:
# BigQueryにデータを書き込む
block_data_controller.insert_data(rows_to_insert)
# リストを空にする
rows_to_insert = []
# 最新データに追いついたら終了
if next_height >= stop_height:
break
# 次のブロックのheightを取得
next_height += 1
上記のサンプルコードでは割愛していますが、実運用上ではエラー発生時または正常処理終了時にLNEで通知を飛ばすように設定しています。PythonでLINE通知を飛ばす関数の例は以下です。
# LINE通知
def send_notify(msg):
#APIのURLとトークン
url = "https://notify-api.line.me/api/notify" #URL
access_token = "***" #取得したトークン
headers = {"Authorization": "Bearer " + access_token}
send_data = {"message": msg}
result = requests.post(url, headers=headers, data=send_data)
print("Send Massage")
print(result)
あとは作成した同期処理のPythonプログラムを、CronやWindowsのタスクスケジューラーで定期実行すれば、日次で最新データを自動同期してくれる処理の完成です。
成果物
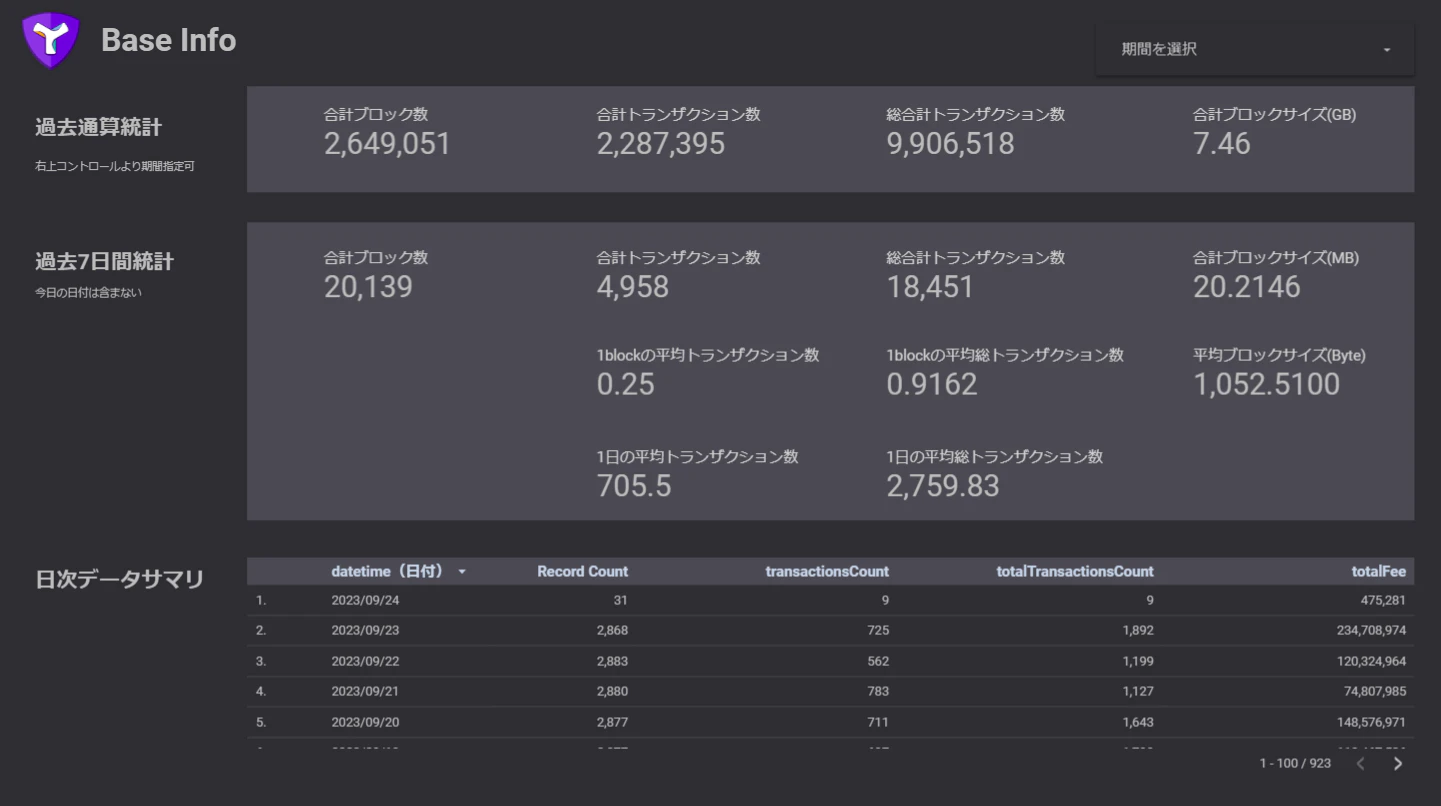
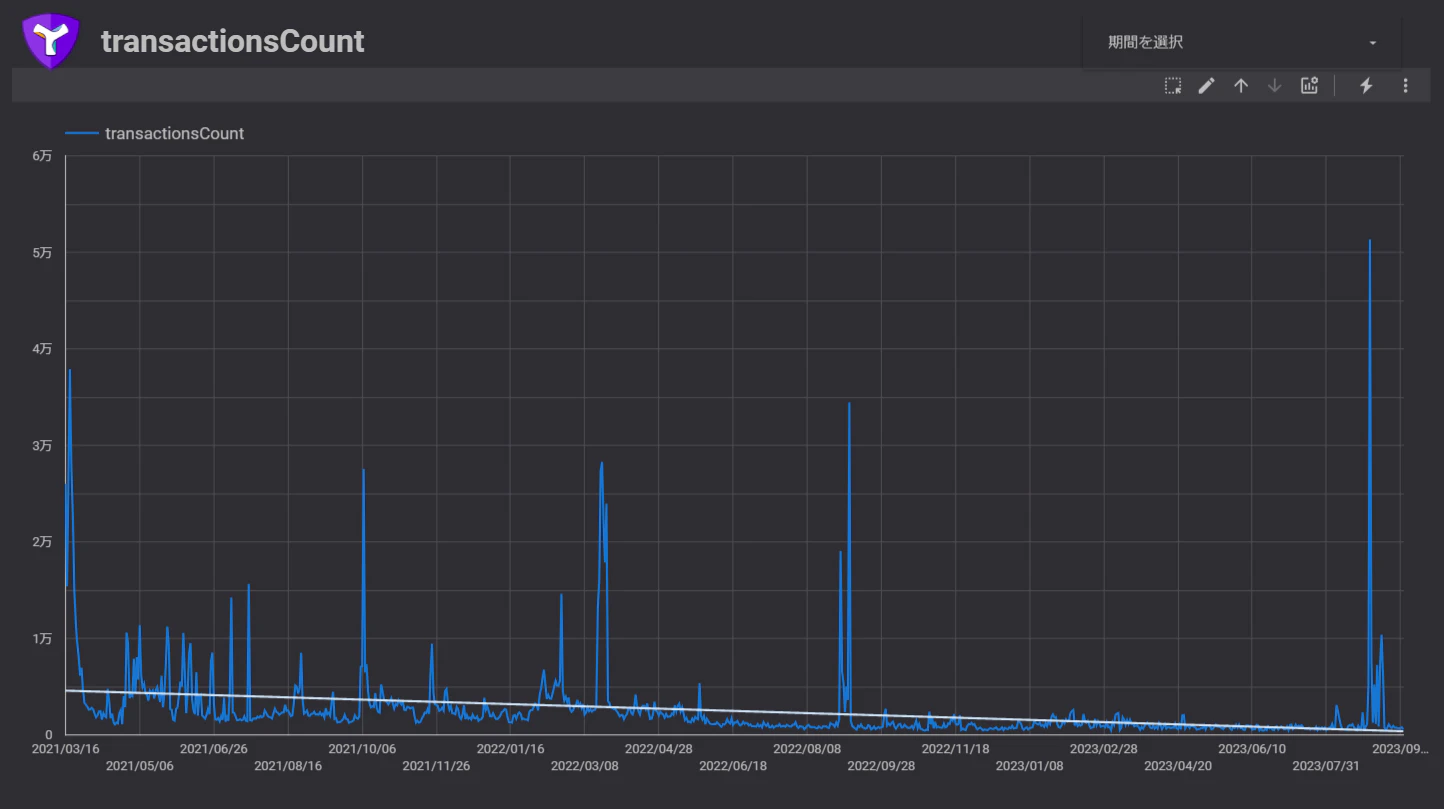
すごく長くなってしまいましたが、以上でSymbolブロックチェーンのトランザクション数を統計分析する環境とレポート画面を完成させることができました。完成したレポートはこちら。一般公開してますのでどなたでも見れます。
まとめ
想像してた以上に手間がかかって大変だった…というのが最初の感想です。まず240万件もあるデータを前に、1件ずつPythonとかで処理してたらとてもじゃないけど終わらないし、効率よく処理するにはどうすればいいか?を調査するところからスタートでした。
実際に調べてやってみることで、ETLツールの必要性やその効果(強力さ)、レポートやデータを公開するときのコツなど、色々と大変勉強になりました。データベース、Linux周りの環境構築、ETLツール、データレイク、Pythonのスクリプト、BIツールまで、一気通貫に様々な領域の技術を勉強することができ、非常に良いトレーニングになりました。
あと、今回この数百万件オーダーのデータ集計・可視化環境を、個人が無償で作成できたことにもすごく驚いています。BigQueryも今回くらいの規模だと余裕で無料枠でいけます。レポートの作成と公開もLookerStudioでスムーズに行なえました。Embulkやそのプラグインなど、素晴らしいソフトウェアを開発してくださっているOSS開発者の皆様や、リッチなコンピューティングリソースを無料で使わせてくれるGoogleさんに深く感謝です。
今回はトランザクションの集計をメインに行いましたが、ハーベスト報酬(いわゆるマイニング報酬)のデータやノードの分散状況など、Symbolブロックチェーンの活用度や状況を測るKPIは他にもいくつかあるので、また次のテーマを設定してトライしてみようと思います。
長文お付き合いいただき、ありがとうございました。個人でデータ分析や可視化の開発にチャレンジしたい方の参考になれば幸いです。また、これを機にSymbolブロックチェーンにもご興味持ってもらえると幸いです。開発しやすく、高性能で非常に興味深い技術です。