はじめに
Cloud FirestoreはFirebase Realtime Databaseの後継であると同時に、Cloud Datastoreの後継でもあるNoSQLのデータベースです。
それらのDBの利用に適していたサービスは、今後Cloud Firestoreの利用を検討していくことになると思います。
現在ベータではありますが、先日のFirebase Summitでアジアリージョンで間もなく利用可能になるというアナウンスもありました。
近いうちにGAになることも期待できるのではないでしょうか。
目的
Firestoreはクエリ機能もありますが、RDBSほど複雑なクエリが実行できないため、
分析のためBigqueryを利用したいケースも多いと思います。
この記事では定期的にFirestoreの内容をBigqueryにロードする方法を紹介します。
全体の流れ
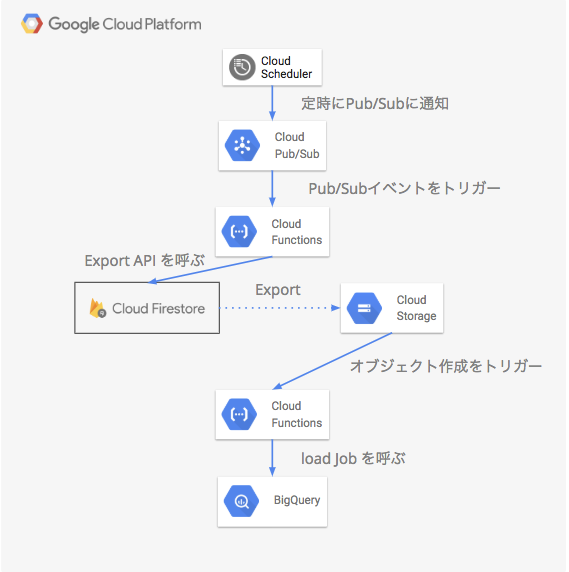
Cloud Schdulerで定期的にPub/Subのトピックに通知するジョブを設定
quick start を参考に設定します。
設定例
- 頻度(Frequency):
"5 0 * * *"(毎日0時5分) - ターゲット(Target):
Pub/Sub - トピック(Topic):
firestore_export - ペイロード(Payload):
{}
Pub/Subのトピックの作成
今回は firestore_export という名前で作成します。
手動で作成してもいいですが、次のCloud Functionsをdeployすると自動で作られます。
Pub/Sub をトリガーにFirestoreのExport APIを呼ぶCloud Functionsの作成
TypeScript のコード例になります。
import { firestore_v1beta2, google } from 'googleapis'
import Schema$GoogleFirestoreAdminV1beta2ExportDocumentsRequest = firestore_v1beta2.Schema$GoogleFirestoreAdminV1beta2ExportDocumentsRequest
import Params$Resource$Projects$Databases$Exportdocuments = firestore_v1beta2.Params$Resource$Projects$Databases$Exportdocuments
import Firestore = firestore_v1beta2.Firestore
import * as dotenv from 'dotenv'
dotenv.config()
const projectId = process.env.GCP_PROJECT_ID
const exportBucket = `gs://${projectId}-firestore` // export先のGCSバケット
const exportCollections = ['users', 'groups'] // export対象のcollection_id
export const ExportFirestore = async () => {
try {
// Cloud Functions のデフォルトのCredentialを利用する
// See Also: https://cloud.google.com/functions/docs/concepts/services#using_services_with_cloud_functions
const auth = await google.auth.getClient({
projectId,
scopes: [
'https://www.googleapis.com/auth/datastore',
'https://www.googleapis.com/auth/cloud-platform'
]
})
const request: Schema$GoogleFirestoreAdminV1beta2ExportDocumentsRequest = {
collectionIds: exportCollections,
outputUriPrefix: exportBucket
}
const params: Params$Resource$Projects$Databases$Exportdocuments = {
auth,
name: `projects/${projectId}/databases/(default)`,
requestBody: request
}
const firestore = new Firestore({})
const result = await firestore.projects.databases.exportDocuments(params)
console.log(result)
return Promise.resolve('success')
} catch (error) {
console.error(error)
return Promise.reject(error)
}
}
※簡略化のため、exportするcollection idをハードコーディングしていますが、
Pub/Subのメッセージで送るか、設定ファイルに切り出してもいいと思います。
必要な設定
上記のコードではデフォルトのサービスアカウントを利用するため、
Cloud IAM から<PROJECT_ID>@appspot.gserviceaccount.com のサービスアカウントに
Cloud Datastore インポート / エクスポート管理者 の役割を付与する必要があります。
また、事前にGoogle Cloud Storageのバケット(今回の場合はプロジェクトIDに-firestoreを付与したもの)を作成します。
deployコマンド
- deploy時にトピック
firestore_exportを指定します - 環境変数を
.env.yamlに記述して、--env-vars-fileで指定します
(google-cloud sdk v227で gcloud beta が不要になりました)
gcloud functions deploy ExportFirestore \
--env-vars-file=./.env.yaml \
--runtime nodejs8 \
--trigger-event google.pubsub.topic.publish \
--trigger-resource firestore_export
Cloud Storageへのバックアップの保存をトリガーにBigqueryにロードするCloud Functionsの作成
import { BigQuery } from '@google-cloud/bigquery'
import { bigquery_v2 } from 'googleapis'
import Schema$JobConfigurationLoad = bigquery_v2.Schema$JobConfigurationLoad
import * as dotenv from 'dotenv'
dotenv.config()
export const LoadFirestoreBackup = async (event: any) => {
try {
const object = event.data || event
const objectName: string = object.name
// メタデータファイルなども生成されるため、対象のファイル以外は早期リターン
// See Also: https://cloud.google.com/bigquery/docs/loading-data-cloud-firestore#loading_cloud_firestore_export_service_data
const matched = objectName.match(/_kind_(.*?).export_metadata$/)
if (!matched) {
console.log(`not a target object: ${objectName}`)
return Promise.resolve('not a target object')
}
const collectionName = matched[1]
console.log(`collection_name: ${collectionName}`)
const bigquery = new BigQuery()
const configuration: Schema$JobConfigurationLoad = {
destinationTable: {
datasetId: `${process.env.DATASET_ID}`,
projectId: `${process.env.GCP_PROJECT_ID}`,
tableId: `${collectionName}`
},
sourceFormat: 'DATASTORE_BACKUP',
sourceUris: [`gs://${object.bucket}/${objectName}`],
writeDisposition: 'WRITE_TRUNCATE'
}
await bigquery.createJob({
configuration: { load: configuration }
})
return Promise.resolve('success')
} catch (error) {
console.error(error)
return Promise.reject(error)
}
}
必要な設定
環境変数でした名前と同名のデータセットを事前に作成しておきます。
テーブル作成は不要です。
deployコマンド
- こちらもdeploy時に対象のバケットを指定します
gcloud functions deploy LoadFirestoreBackup \
--env-vars-file=./.env.yaml \
--runtime nodejs8 \
--trigger-bucket ${PROJECT_ID}-firestore
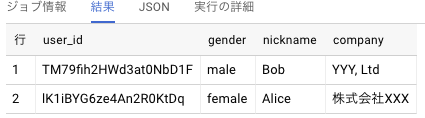
結果
下記のようなユーザーデータがFirestoreに入っている場合、
"users": [
{
profile: {
gender: "female",
nickname: "Alice"
},
company: "株式会社XXX"
},
{
profile: {
gender: "male",
nickname: "Bob"
},
company: "YYY, Ltd."
}
]
Bigqueryにこのようなクエリを打つことで
SELECT
__key__.name AS user_id,
profile.gender,
profile.nickname,
company
FROM
`<PROJECT_ID>.firestore.users`
LIMIT
10
下記の結果が得られるようになります。
今回のコード
https://github.com/kurikei/firestore_to_bq
にアップロードしてあります。