この記事は 株式会社カオナビ Advent Calendar 2025 シリーズ3の17日目です。
前回のおさらい
株式会社カオナビ Advent Calendar 2025 シリーズ1 13日目 の記事で MySQL Shell の簡単な使い方を説明しました。
今回は MySQL Shell の用途として一番多そうなダンプ/リストアのやり方を説明します。
今回の環境
今回は以下のような環境を準備しました。

- WSL2 Ubuntu 上で 以下の2つのコンテナを docker-compose で起動
- MySQL 8.0.44 を Port 3306 で起動。こちらがダンプ元になります
- MySQL 8.0.44 を Port 3307 で起動。こちらがリストア先になります
- 上記の2つのMySQLに WSL2 Ubuntu 上の MySQL Shell から接続します
3つのダンプ方法
ダンプには MySQL Shell ユーティリティ の以下の3つを利用します。
- インスタンスダンプユーティリティ
- スキーマダンプユーティリティ
- テーブルダンプユーティリティ
それぞれの使い方を見ていきましょう。
(注意) 今回はSQLモードとJavaScriptモードを使います。SQLモートとJavaScriptモードってなんだ?というかたは前回の記事に書いてますのでそちらを先に目を通しておいてください。
インスタンスダンプユーティリティ
まずは、インスタンスダンプユーティリティから説明します。これは特に取得するDB/テーブルを指定するのではなく、まるっとインスタンスごとダンプするものとなります。
ダンプインスタンスユーティリティは以下のよう関数となります。
Undefined dumpInstance(
String outputUrl,
Dictionary options
)
引数は以下の通り。
- 第1引数は出力先のパス(ディレクトリの指定になります)
- 第2引数には出力時のオプション
具体的には以下のような形になります。
util.dumpInstance('/home/kunit/mysql-shell-test/dump-files/dump-instance', {
threads: 4,
dryRun: false
})
(注意) それぞれのユーティリティの細かいオプションが知りたい場合は、以下のページを確認してください。
では、実際に実行してみましょう。
ダンプ元のDBの状態を確認
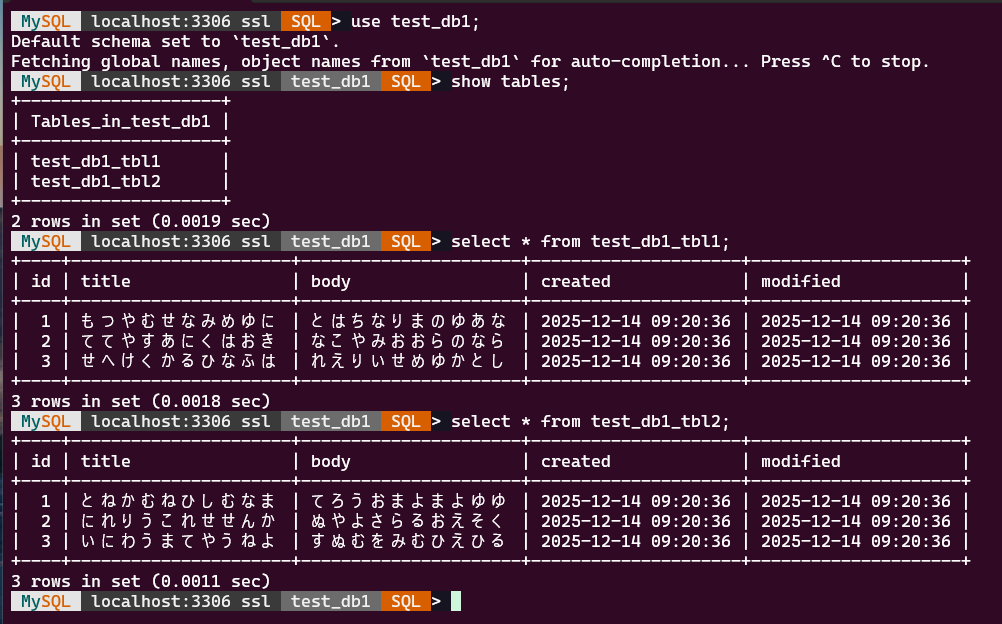
ダンプ元は以下の状態になってます。
-
test_db1とtest_db2の2つのデータベースが存在

-
test_db1にはtest_db1_tbl1とtest_db1_tbl2いう2つのテーブルがある-
test_db1_tbl1には3つのレコードがある -
test_db1_tbl2には3つのレコードがある
-
-
test_db2にはtest_db2_tbl1とtest_db2_tbl2いう2つのテーブルがある-
test_db2_tbl1には3つのレコードがある -
test_db2_tbl2には3つのレコードがある
-

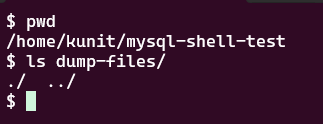
ファイルがないことを確認
出力先の /home/kunit/mysql-shell-test/dump-files/ 以下には何もない状態です。
ダンプ実行
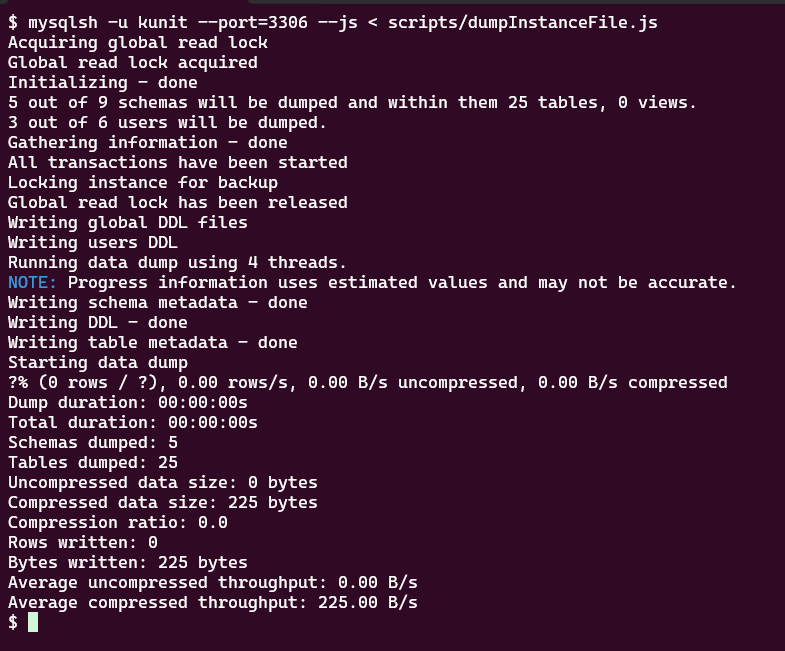
では、MySQL Shell を使ってダンプします。
ダンプされたかを確認
無事、2つのデータベースとそれぞれのテーブルがダンプされました。

スキーマダンプユーティリティ
ダンプされたものをリストアしたくなりますが、引き続きダンプの方法の説明を進めます。
スキーマダンプユーティリティは取得する一つ以上のデータベースを指定してダンプを行います。
スキーマダンプユーティリティは以下のような関数となります。
Undefined dumpSchemasf(
List schemas,
String outputUrl,
Dictionary options
)
引数は以下の通り。
- 第1引数は出力するデータベースのリスト(1つでも配列指定になります)
- 第2引数は出力先のパス(ディレクトリの指定になります)
- 第3引数には出力時のオプション
具体的には以下のような形になります。
util.dumpSchemas(['test_db2'], '/home/kunit/mysql-shell-test/dump-files/dump-schemas', {
threads: 4,
dryRun: false
})
では、実際に実行してみましょう。
ダンプ元のDBの状態を確認
ここはインスタンスダンプユーティリティの時と同じ状態なので割愛します。
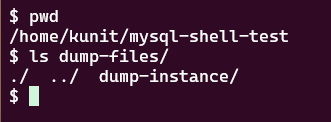
ファイルがないことを確認
出力先の /home/kunit/mysql-shell-test/dump-files/ 以下には dump-schemas がない状態です。
ダンプ実行
では、MySQL Shell を使ってダンプします。

ダンプされたかを確認
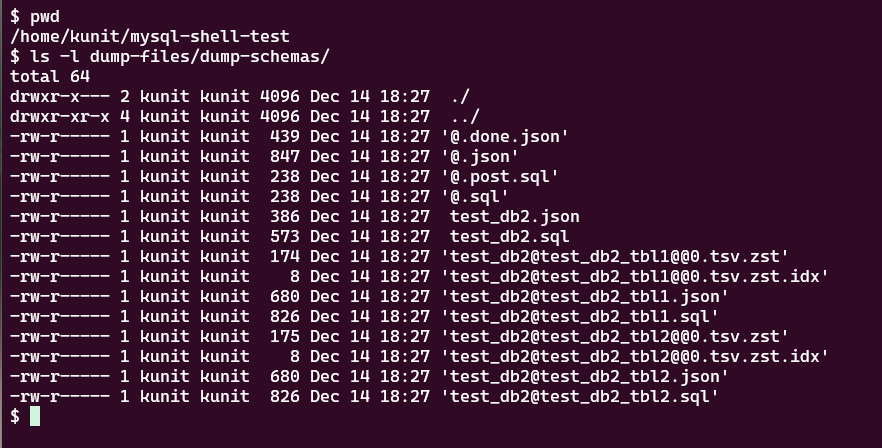
今回は、test_db2 のテーブルだけがダンプされました。
テーブルダンプユーティリティ
最後にテーブルダンプユーティリティの説明をします。
テーブルダンプユーティリティは取得する一つ以上のテーブルを指定してダンプを行います。
テーブルダンプユーティリティは以下のような関数となります。
Undefined dumpTables(
String schema,
List tables,
String outputUrl,
Dictionary options
)
- 第1引数は出力するデータベース
- 第2引数は出力するテーブルのリスト(1つでも配列指定になります)
- 第3引数は出力先のパス(ディレクトリの指定になります)
- 第4引数には出力時のオプション
util.dumpTables('test_Db1' ['test_db1_tbl2'], '/home/kunit/mysql-shell-test/dump-files/dump-tables', {
threads: 4,
dryRun: false
})
では、実際に実行してみましょう。
ダンプ元のDBの状態を確認
ここはインスタンスダンプユーティリティの時と同じ状態なので割愛します。
ファイルがないことを確認
出力先の /home/kunit/mysql-shell-test/dump-files/ 以下には dump-tables がない状態です。

ダンプ実行
では、MySQL Shell を使ってダンプします。

ダンプされたかを確認
今回は、test_db1 の test_db1_tbl2 だけがダンプされました。

リストアしてみよう
ここまで3つのダンプ方法を見てきましたが、それをつかってリストアしてみましょう。
ダンプ方法は3つありましたが、リストアの方法は1つで、ダンプロードユーティリティを利用します。
(注意事項) ダンプロードユーティリティを使うにあたって以下のような注意事項があります。
- ダンプロードユーティリティでは LOAD DATA LOCAL INFILE ステートメントが使用されるため、インポート中は、ターゲット MySQL インスタンスの local_infile システム変数のグローバル設定を ON にする必要があります。
今回のDocker環境では 3307 で起動しているものだけ local_infile を ON にしています。
ダンプロードユーティリティは以下のような関数となります。
Undefined loadDump(
String url,
Dictionary options
)
引数は以下の通り。
- 第1数はダンプされたファイル群のパス(ディレクトリの指定になります)
- 第2引数にはロード時のオプション
具体的には以下のような形になります。
今回はインスタンスダンプユーティリティで取得したダンプを使ってリストアします。
util.loadDump('/home/kunit/mysql-shell-test/dump-files/dump-instance', {
threads: 4,
analyzeTables: 'on',
dryRun: false
})
では、実際に実行してみましょう。
リストア先のDBの状態を確認
リストア先にはシステム関連以外のデータベースはありません。

リストア実行
では、MySQL Shell を使ってリストアを実施します。
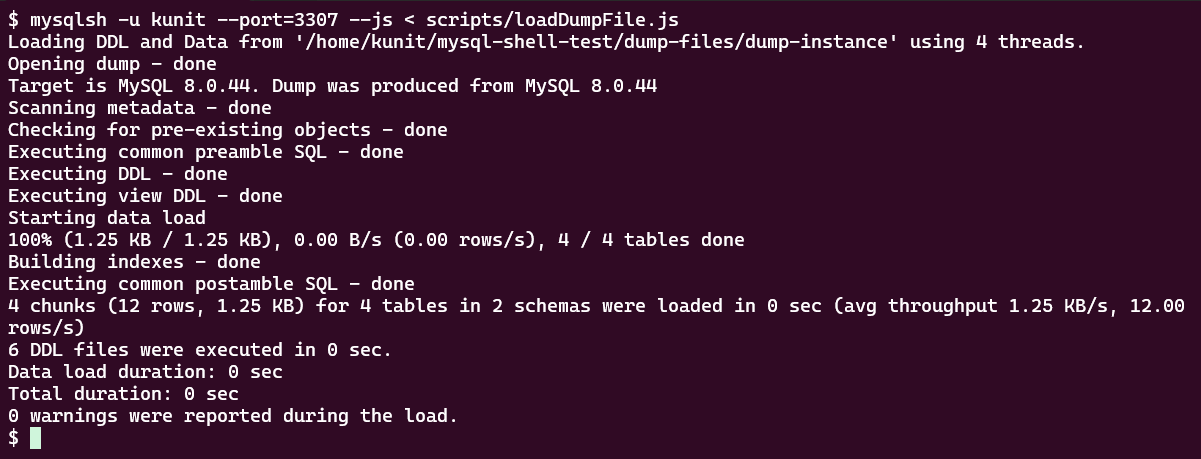
リストアされたかを確認
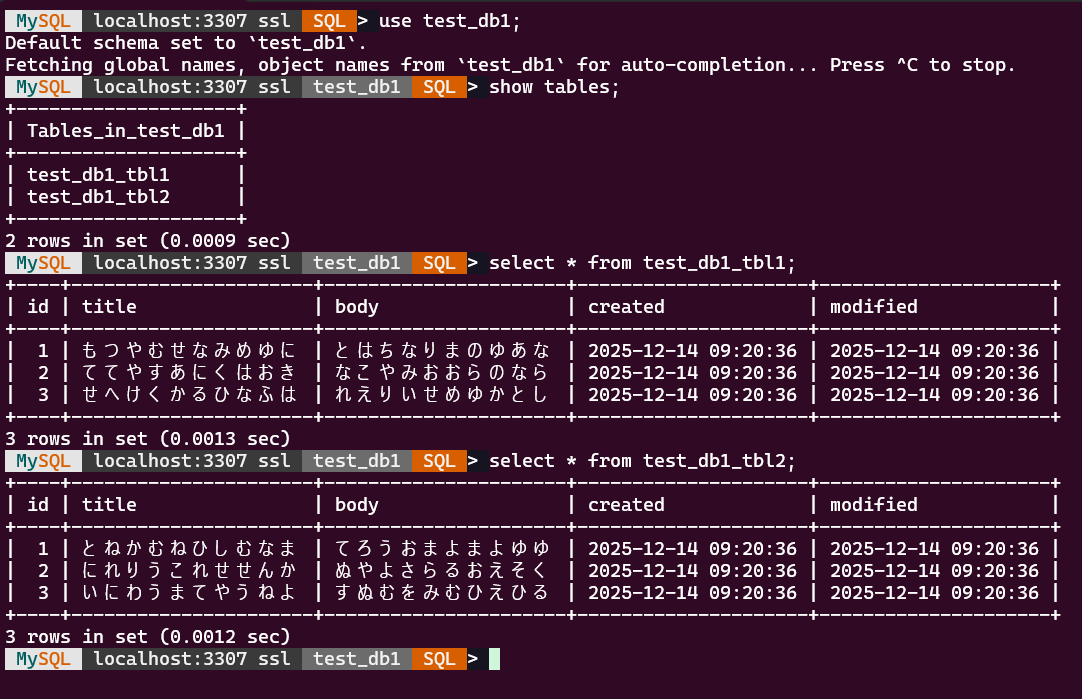
リストア先に test_db1 と test_db2 ができました。

test_db1 に test_db1_tbl1 と test_db1_tbl2 ができました。
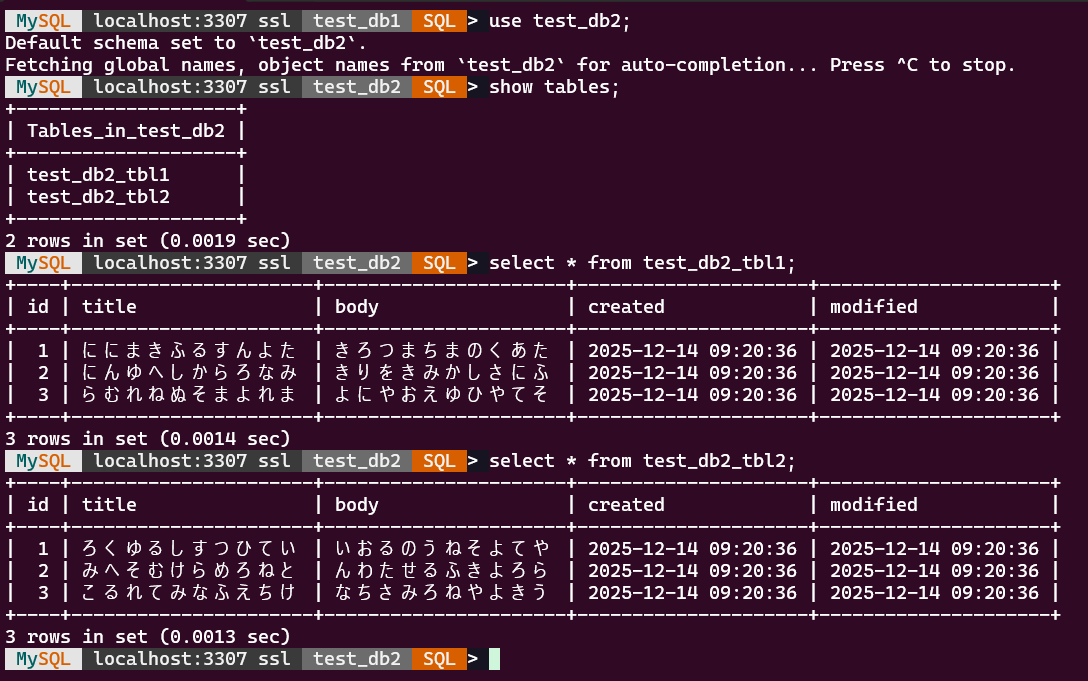
test_db2 に test_db2_tbl1 と test_db2_tbl2 ができました。
このように3つのダンプユーティリティとダンプロードユーティリティを組み合わせることによって、ダンプ/リストアを並列に実行することができました。
S3 を出力先にする
ここまでは従来の mysqldump 同様にローカルのストレージにファイル出力をする方法を説明しましたが、MySQL Shell にはさらに便利な使い方があります。
AWS の S3 を出力先にしてダンプしたり、S3にダンプされたものを元にリストすることができます。
利用するユーティリティは同じですが、引数の使い方が変わります。
今回はインスタンスダンプユーティリティとダンプロードユーティリティにS3を利用するように指定して、ダンプ/リストアを行ってみましょう。
環境の拡張
先程まで使っていた環境を以下のように拡張しました。

- WSL2 Ubuntu 上で 以下の3つのコンテナを docker-compose で起動
- MySQL 8.0.44 を Port 3306 で起動。こちらがダンプ元になります
- MySQL 8.0.44 を Port 3307 で起動。こちらがリストア先になります
- localstack を Port 4566 で起動。ここで S3 をエミュレートします
- 上記の3つのMySQLに WSL2 Ubuntu 上の MySQL Shell から接続します
(注意事項) 今回は locakstack の細かい使い方は本筋ではないので割愛します。
ダンプ元のDBの状態を確認
ここはインスタンスダンプユーティリティの時と同じ状態なので割愛します。
ダンプ先のS3バケットになにもないことを確認
ダンプ先のS3バケット mysql-shell-test 以下には何もない状態です。あわせてファイルとしてダンプも出力されていません。

ダンプするスクリプトを準備
S3 を出力先とするようなJSファイルを準備します。
第1引数にはバケットに作るフォルダ名、第2引数にはオプションとしてS3関連の設定を指定します。
util.dumpInstance('dump-instance', {
s3EndpointOverride: 'http://localhost:4566',
s3Profile: 'localstack',
s3BucketName: 'mysql-shell-test',
s3Region: 'ap-northeast-1',
threads: 8,
dryRun: false
})
ダンプ実行
では、MySQL Shell を使ってダンプします。
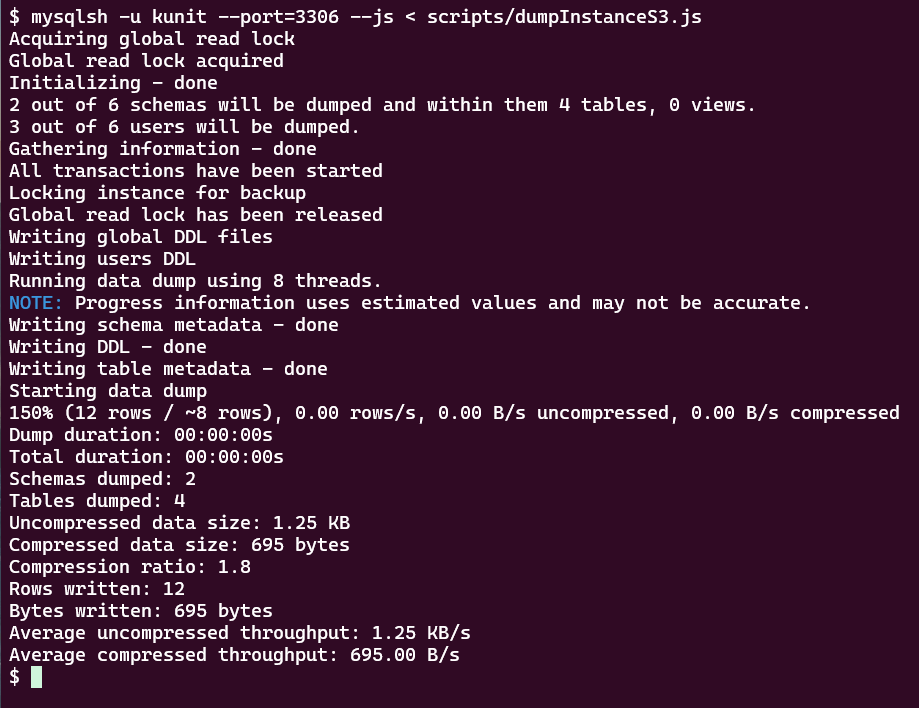
ダンプされたかを確認
無事、2つのデータベースとそれぞれのテーブルがS3バケットにダンプされました。
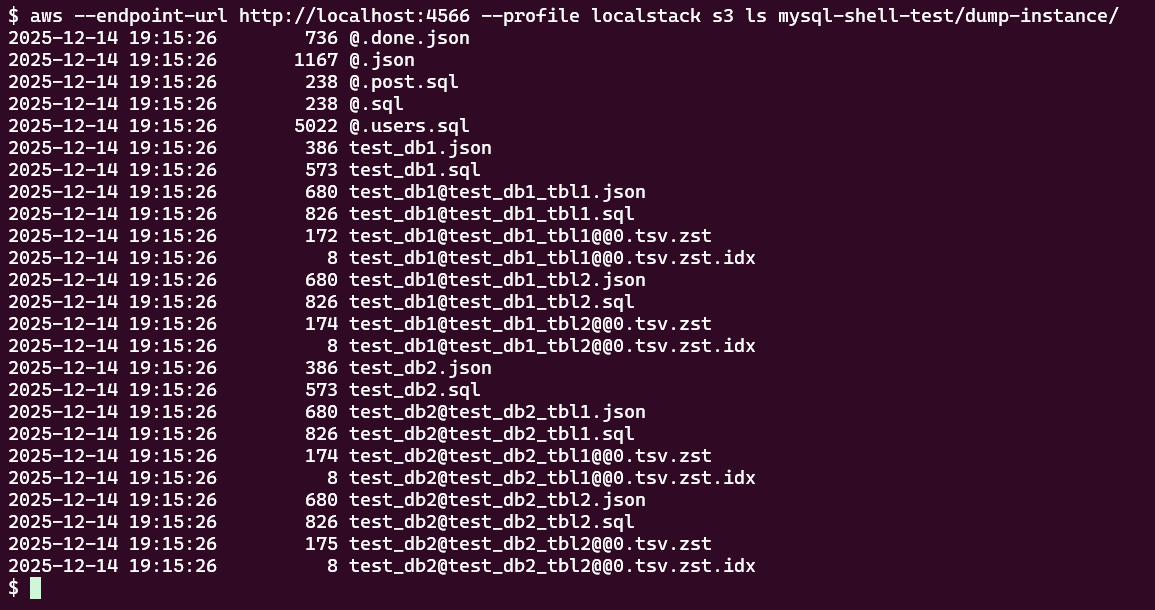
リストア先のDBの状態を確認
リストア先のDBはシステム関連以外のデータベースがない状態に戻しました。

リストアするスクリプトを準備
S3 を利用するようなJSファイルを準備します。
第1引数にはダンプしたファイル群が入っているS3のフォルダ、第2引数にはオプションとしてS3関連の設定を指定します。
util.loadDump('dump-instance', {
s3EndpointOverride: 'http://localhost:4566',
s3Profile: 'localstack',
s3BucketName: 'mysql-shell-test',
s3Region: 'ap-northeast-1',
threads: 8,
dryRun: false
})
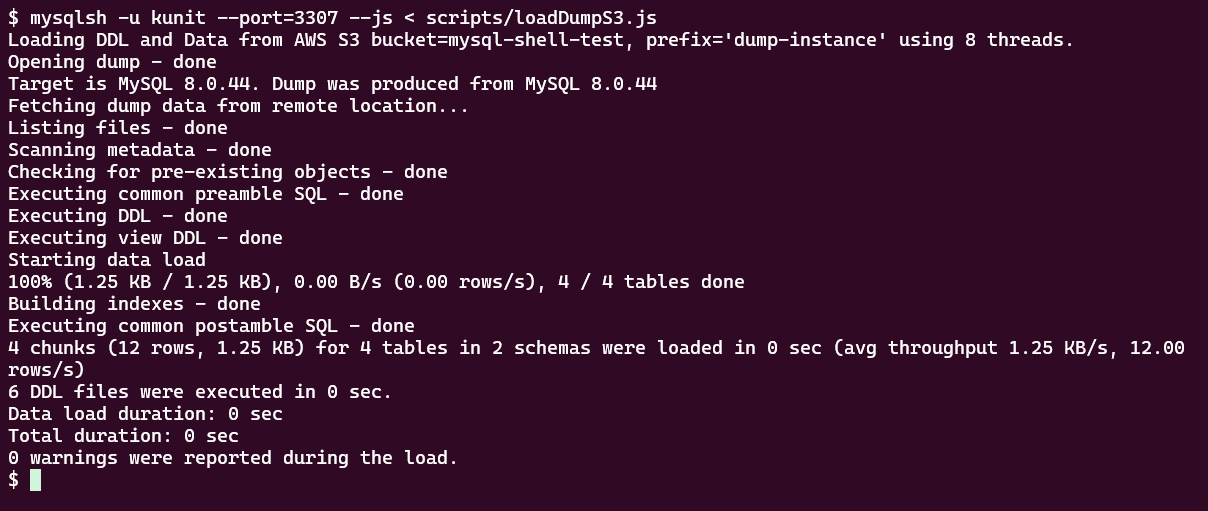
リストア実行
では、MySQL Shell を使ってリストアを実施します。
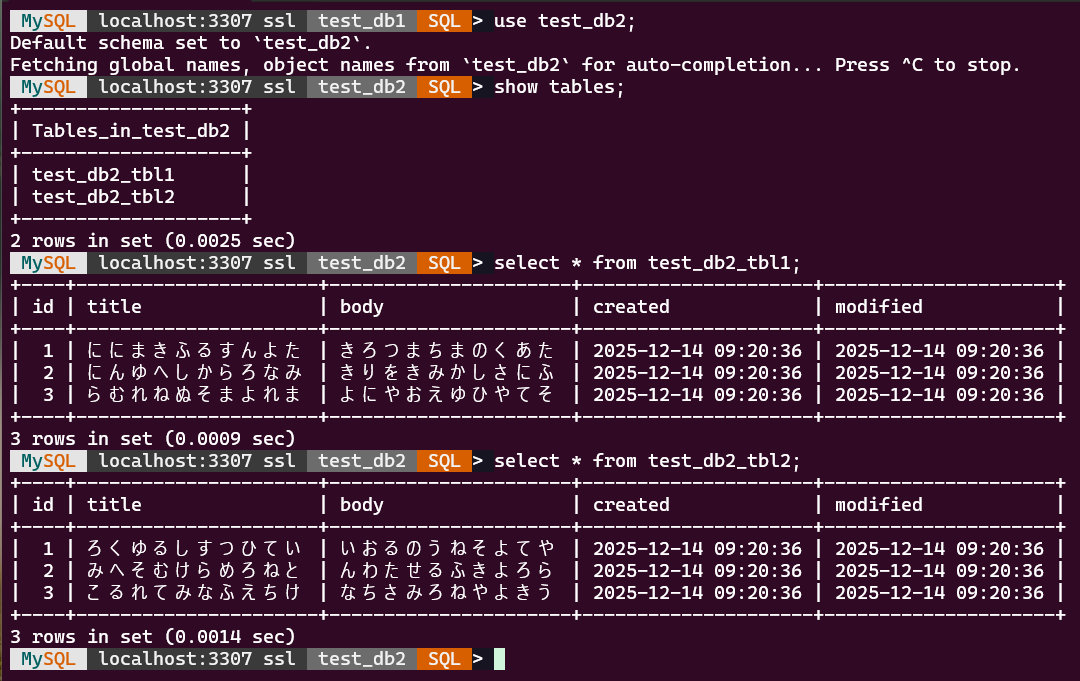
リストアされたかを確認
リストア先に test_db1 と test_db2 ができました。

test_db1 に test_db1_tbl1 と test_db1_tbl2 ができました。

test_db2 に test_db2_tbl1 と test_db2_tbl2 ができました。
S3を経由することにより、ローカルにファイルをつくることなくダンプ/リストアができるようになります。普段 AWS上で RDS/Aurora を使っている場合は S3 を経由するほうがより実践的な使い方になるかもしれません。
ダンプ/リストアをまとめて行う
ここまではローカルストレージのファイルを使うものとS3を経由するものの2つの方法を説明しましたが、両方ともダンプして、リストアするという2ステップが必要でした。
MySQL Shell 8.4 からはこれを1ステップで行うコピーユーティリティというのが追加されました。(前回、MySQL Shell のバージョンを 8.0 ではなく 8.4 にしたのはこれが理由です)
コピーユーティリティはダンプと同様、インスタンス、スキーマ、テーブルの3段階の関数が準備されています。
Undefined copyInstance(
ConnectionData connectionData,
Dictionary options
)
Undefined copySchemas(
List schemas,
ConnectionData connectionData,
Dictionary options
)
Undefined copyTables(
String schema,
List tables,
ConnectionData connectionData,
Dictionary options
)
今回はインスタンス事コピーする形でやってみましょう。
第1引数にリストア先のDBの情報を、第2引数のオプションでユーザー情報はコピーしない設定にしました。
util.copyInstance('kunit@localhost:3307', {
threads: 4,
analyzeTables: 'on',
users: false,
dryRun: false
})
では、実際に実行してみましょう。
ダンプ元のDBの状態を確認
ここはインスタンスダンプユーティリティの時と同じ状態なので割愛します。
リストア先のDBの状態を確認
リストア先のDBはシステム関連以外のデータベースがない状態に戻しました。

コピー実行
では、MySQL Shell を使ってコピーを実施します。


リストアされたかを確認
リストア先に test_db1 と test_db2 ができました。

test_db1 に test_db1_tbl1 と test_db1_tbl2 ができました。

test_db2 に test_db2_tbl1 と test_db2_tbl2 ができました。

ローカルにファイルを出力せずにコピーが可能となりました。この方法にはいくつかの制約があるので、使用する場合は、マニュアルを確認するようにしてください。
最後に
前回の記事では MySQL Shell の説明をしましたが、その説明だけでは複雑なだけで、なにが便利なんだろうという感じだったと思います。
今回の説明したように並列数を指定したり、S3を経由したりすることによって、従来の mysqldump ではできなかったことが可能となっていることがわかっていただけたと思います。
また、MySQL Shell 8.4 からはダンプ/リストアを1ステップでできるようになり、更に便利になりました。
少しクセのあるツールではありますが、かなりの時間短縮や使用リソースの削減につながると思うので上手につかっていきたいなと思いました。
今回使い方はわかったので、実際にどれくらいの時間短縮になるのかを次回ベンチマークを取ろうと思います。
株式会社カオナビでは一緒に働く仲間を募集しています。カジュアル面談も行っていますので、ご興味がある方は気軽にお声がけください。