はじめに
【 ニューロ型データベースモデリング Ver.1 】とは
「脳を構成する神経細胞(neuron)が繋がり合って情報を司る」
という仕組み(ネイチャーテクノロジー)に着目し
私が独自で研究・開発 してきた「データベースモデリング」です。
使用する静的テーブルは「2個(2種類)だけ」なのでシンプルな構造となり結果的に基本メンテナンスフリー の 汎用データベースモデリング が出来上がりました。
詳しくは【 開発の歴史:2016-03-04~05 総務省「異能vation」協力・協賛企業マッチングイベントに「ニューロ型データベースモデリング」が選定される 】をご覧下さい。
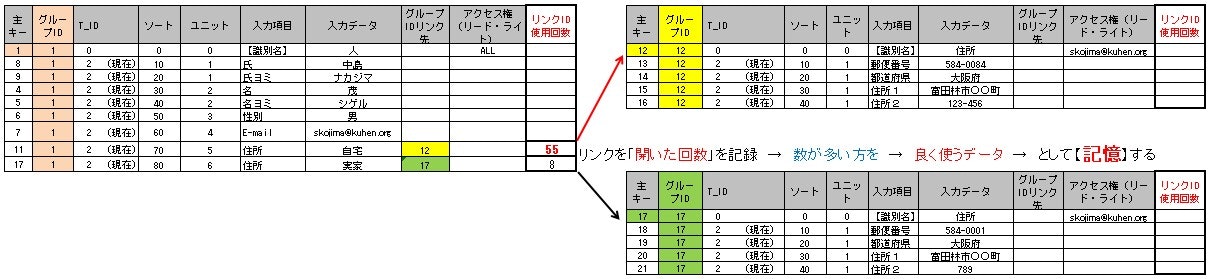
【学習】機能を考える(一般的にも良くやる処理ですが)
「脳」の「神経細胞」同士が繋がりあっている画像を見ると繋がり合っているその線が太ければ太いほど【よく使う】ということではないのか?
それをデータベースの静的テーブルに実装するには
「太さ」=「数値の大小」
だと考えた。
そこで新たに【リンクID使用回数】という「列」を追加し
識別名(ひな型名)【住所】で登録されている「自宅」と「実家」を開く度に
この「リンクID使用回数」をカウント(数値の追加)をしていけば
【よく使う】住所として以下の図だと「自宅」が【記憶される】。
例えば: 【勤務先】 情報が過去を含め 「3社」 あるとする
現在は**「C社」**で勤務しているとする。
やはり「過去」の会社の「リンクID使用回数」の方が数値としては大きい。
**【現在】**の学習状態
| 入力項目 | 入力データ | リンクID使用回数(降順) |
|---|---|---|
| 勤務先 | B社(1982年-2000年) | 883 |
| 勤務先 | A社(-1982年) | 48 |
| 勤務先 | C社(2000年-) | 30 |
新たに【C社】を これから【よく使う】「勤務先」
として**【学習させる】** → 数値を 【 10000 】 加算する
**【最新】**の学習状態
| 入力項目 | 入力データ | リンクID使用回数(降順) |
|---|---|---|
| 勤務先 | C社(2000年-) | 10030 |
| 勤務先 | B社(1982年-2000年) | 883 |
| 勤務先 | A社(-1982年) | 48 |
【応用編】テーブルを【複数】繋げて「辞書学習」処理を考えてみた
例: お父さん
5個のテーブルをリンクして行き「お父さん」にたどり着く
お → と → う → さ → ん
| 入力項目 | 入力データ | リンクID使用回数(降順) |
|---|---|---|
| 辞書「お」 → | と | xxxxxx |
↓
| 入力項目 | 入力データ | リンクID使用回数(降順) |
|---|---|---|
| 辞書「おと」 | う | xxxxxx |
↓
「おとうさん」と「おとうふ」の優先順位
| 入力項目 | 入力データ | リンクID使用回数(降順) |
|---|---|---|
| 辞書「おとう」 | さ | 50000 |
| 辞書「おとう」 | ふ | 3000 |
↓
| 入力項目 | 入力データ | リンクID使用回数(降順) |
|---|---|---|
| 辞書「おとうさ」 | ん | xxxxxx |
↓
| 入力項目 | 入力データ | リンクID使用回数(降順) |
|---|---|---|
| 辞書「おとうさん」 | お父さん |
まとめ
【学習】方法として「リンクID使用回数(降順)」を利用してみました。
このモデリングは1種類の静的テーブルを沢山(無限に)リンクして処理が出来ることを今回の記事で知っていただければと思います。
「多くなりすぎたテーブル(正規化後)」は → 「上下に連結(非正規化)」にしてしまえば良いと思います。
関連投稿記事
前回 第01回 独自開発した「ニューロ型データベースモデリング Ver.1」で個人情報保護の簡単実装を考えてみた
次回 第03回 独自開発した「ニューロ型データベースモデリング Ver.1」 縦連結したデータの表示順(ソート順)を【 サブグループ 】で管理する