はじめに
【 ニューロ型データベースモデリング Ver.1 】とは
「脳を構成する神経細胞(neuron)が繋がり合って情報を司る」
という仕組み(ネイチャーテクノロジー)に着目し
私が独自で研究・開発 してきた**「データベースモデリング」です。
使用する静的テーブルは「2個(2種類)だけ」なのでシンプルな構造となり結果的に基本メンテナンスフリー** の 汎用データベースモデリング が出来上がりました。
詳しくは【 開発の歴史:2016-03-04~05 総務省「異能vation」協力・協賛企業マッチングイベントに「ニューロ型データベースモデリング」が選定される 】をご覧下さい。
個人情報保護に対応するには【閲覧専用のデータベース】を簡単に構築出来れば良い
稼働中のデータベースに登録されている個人情報を誰もが簡単に検索させる環境だと個人情報保護法違反になる昨今それなら稼働中の個人情報を【閲覧専用のデータベース】へエクスポート(構築)すれば「凌げる」のではないだろうか。
今から簡単に閲覧専用のデータベース構築のヒントを書いて行きたいと思います。
開発のきっかけ
2000年04月に36歳で(独身に戻って)事務SEとして現在所属している大阪の某法律事務所に転職し稼働中の「ネットワーク管理」を敏腕IT弁護士(2カ月後には海外留学で渡米)から引き継ぐことになった。
私はAccess2000で2個のテーブルを主キーでリレーションをする位しか経験は無かったがUNIXでCshやsedを使ってバッチ処理をしたりN88BASICで短大の教務システムや図書システムを開発していたので何とかなると簡単に考えていた。
説明を受けたのはSQLサーバを使いリアルタイムで事務処理をする「総合システム」を1から自前で開発することだった。完璧な「要件定義書」を受け取った時は「不安半分」「武者震い半分」であった。
そもそも「理想のデータベース」とは?
渡された「要件定義書」の中身を簡単に言うなら「海外も視野に入れて何にでも対応できるデータベースを構築せよ」というものだった。
今では【AI】という言葉が社会にあふれているが当時データベース開発を始めた2000年はパソコンの処理スピードも遅くスマートフォンなどまだ無い時代だった。
今から開発したい「何でも処理できる理想のデータベースとは?」を色々考えてみたところそれは【人間の脳】ではないか?【人工知能】なんて開発出来ないここで無理だとあきらめた。
そして数日後【人工知能】が無理でも【脳が処理する方法を真似出来ないか?】と気が付きこの日からデータベースで使用する静的テーブル構造の研究・開発が始まった。
今までのデータベース「テーブル構造」
Excelシートでは上から下に向けて個人の氏名があり各氏名の真右に向かい関連データが繋がっていくのは一覧表の基本だがこの方法だと新しい「列」を追加したり削除したりする度に管理権限者に依頼しなければならないし操作対象テーブル内の全データをロックしないといけないかもしれない。
■ 一般的なデータ構造

それでは「ニューロ型データベースモデリング」の「テーブル構造」をご紹介する
◆◆説明の便宜上使用テーブルは1個バージョンでおこないます◆◆
■ まず最初に作成する テーブルの「種類」を【識別名】 「人」 として登録

■ 【入力項】と【入力データ】を 縦長に下方向へ繋いでいく
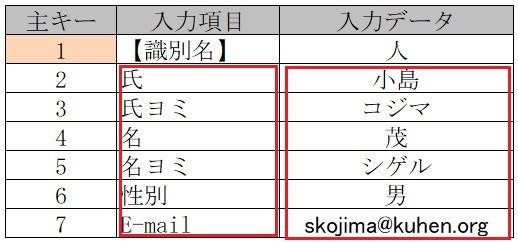
■ 【ソート】を追加 この列でデータの表示順を自由に変更できる
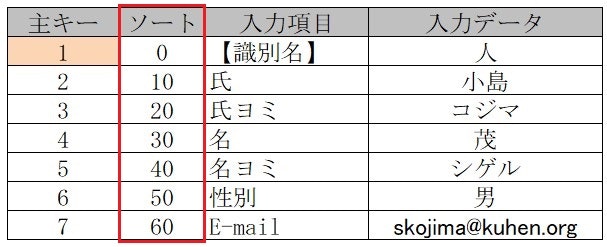
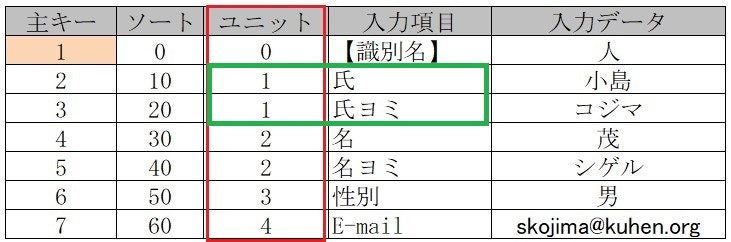
■ 【ユニット】を追加 この列で**「入力項目」のグループ化**を実現
**「氏」「氏ヨミ」を同じ【1】**にすることによりどちらかのデータ修正時に
同じ「ユニット番号」も修正対象にする
過去データを【コンボボックス】として抽出する時も便利
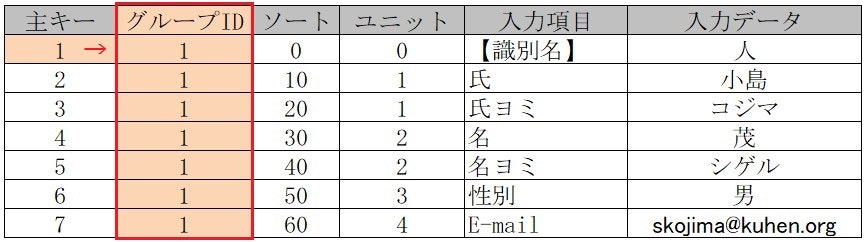
■ 縦長データをユニークな1個の番号で**【グループ化】**(最初の主キーを使用)
縦長に繋がったデータを1種類の動的テーブルとして処理
■ 「現在」「過去」「未来」を管理する「T_ID」列を追加
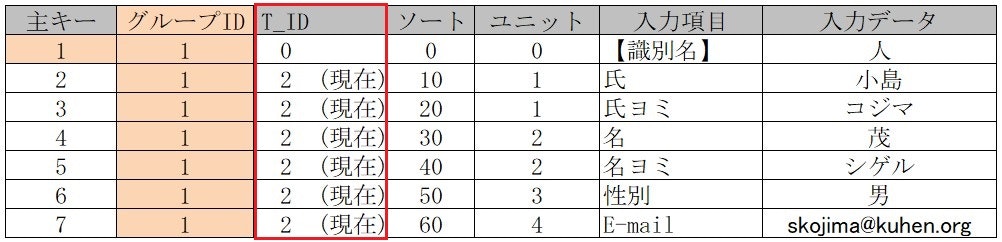
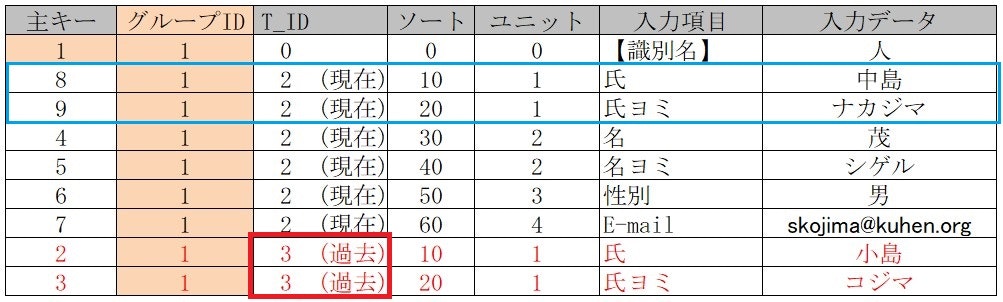
■ データ修正時(青色枠)旧データ(赤色枠)の【履歴化】を実装
「T_ID」を「 3(過去)」に変更し過去データの検索対象とする
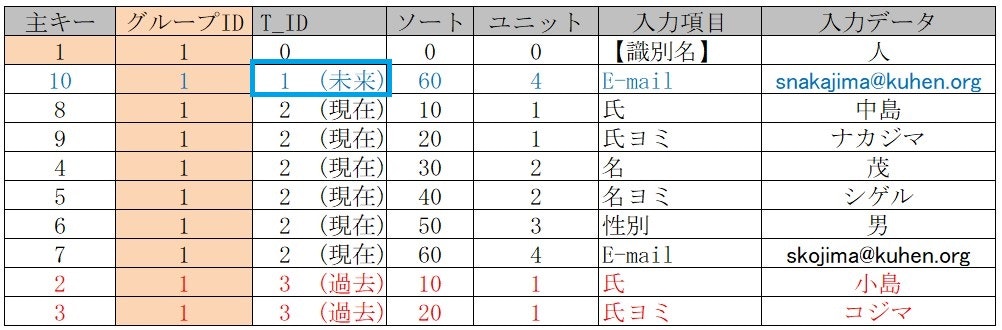
「 1(未来)」として予約登録を実装する(例:取得予定E-mailアドレス)
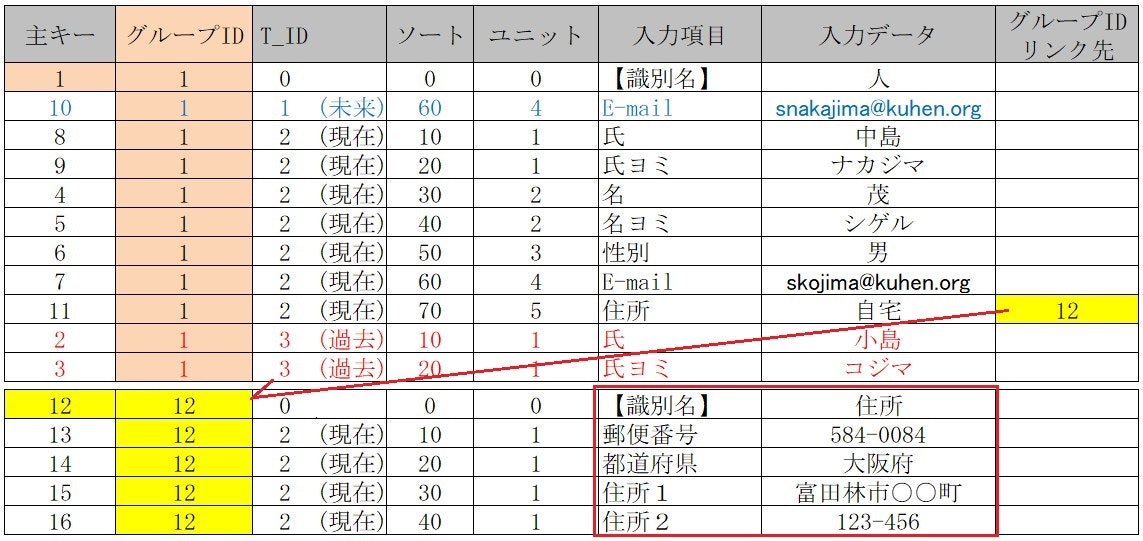
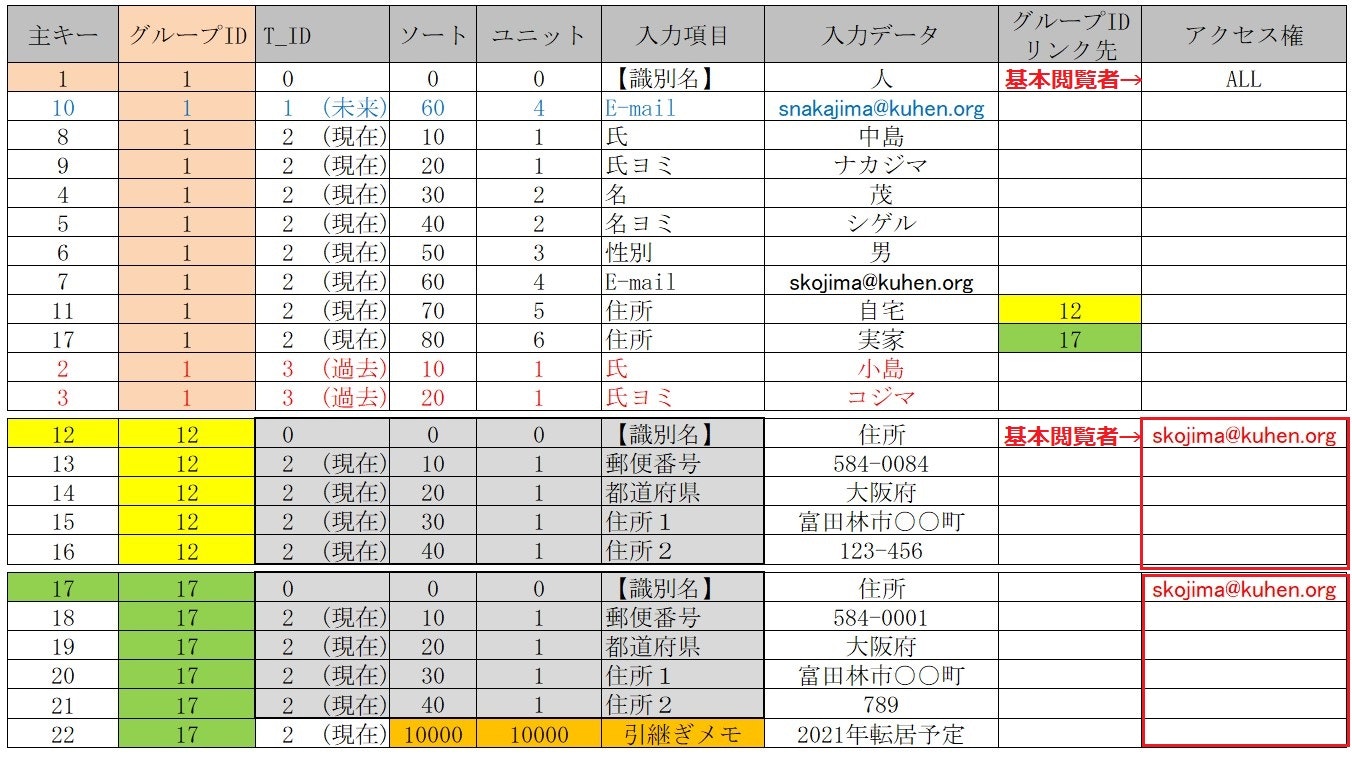
■ 【グループIDリンク先】列を追加
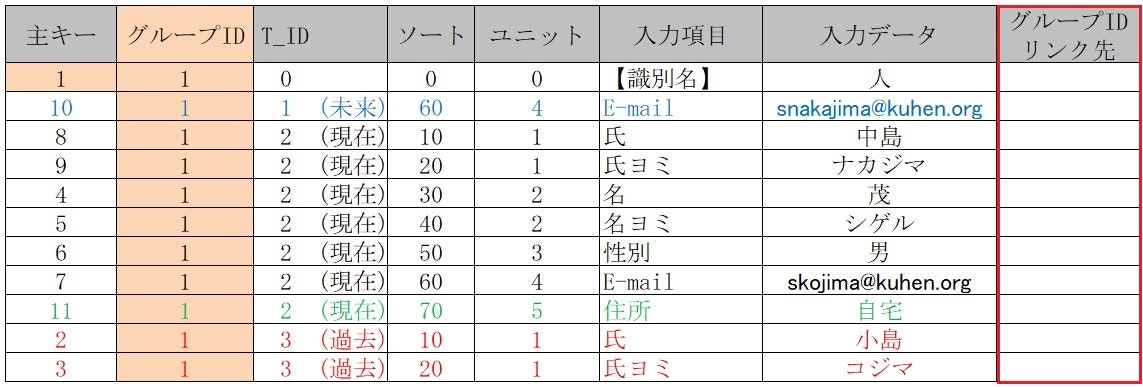
1.「グループID」を【12】として 【識別名】 住所 を新規作成 を
2.【グループIDリンク先】列に【12】を登録する
【 動的テーブル 】間の**【 リレーション 】を【番号】だけで実現**
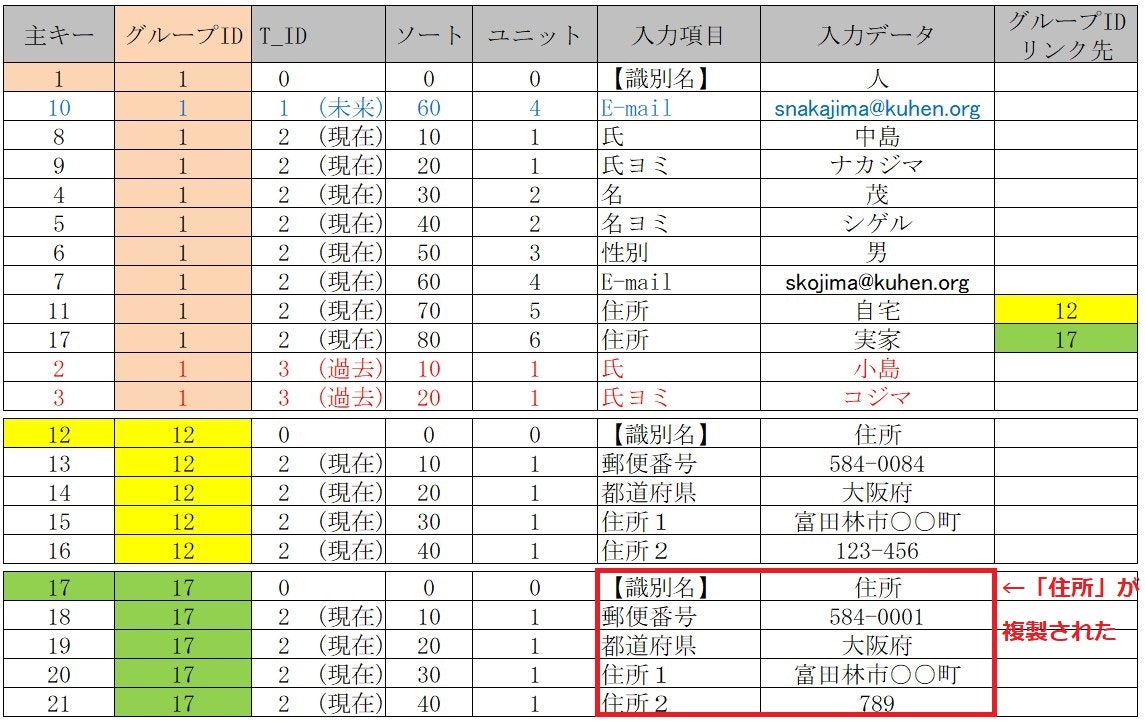
■ 既存「自宅」【識別名】住所 を 複製後 「実家」として登録する
既存【識別名】住所 を継承(複製)し 同じ「項目名」を持つテーブルだが
【入力データ】で「自宅」「実家」など複数の【属性】を実現している
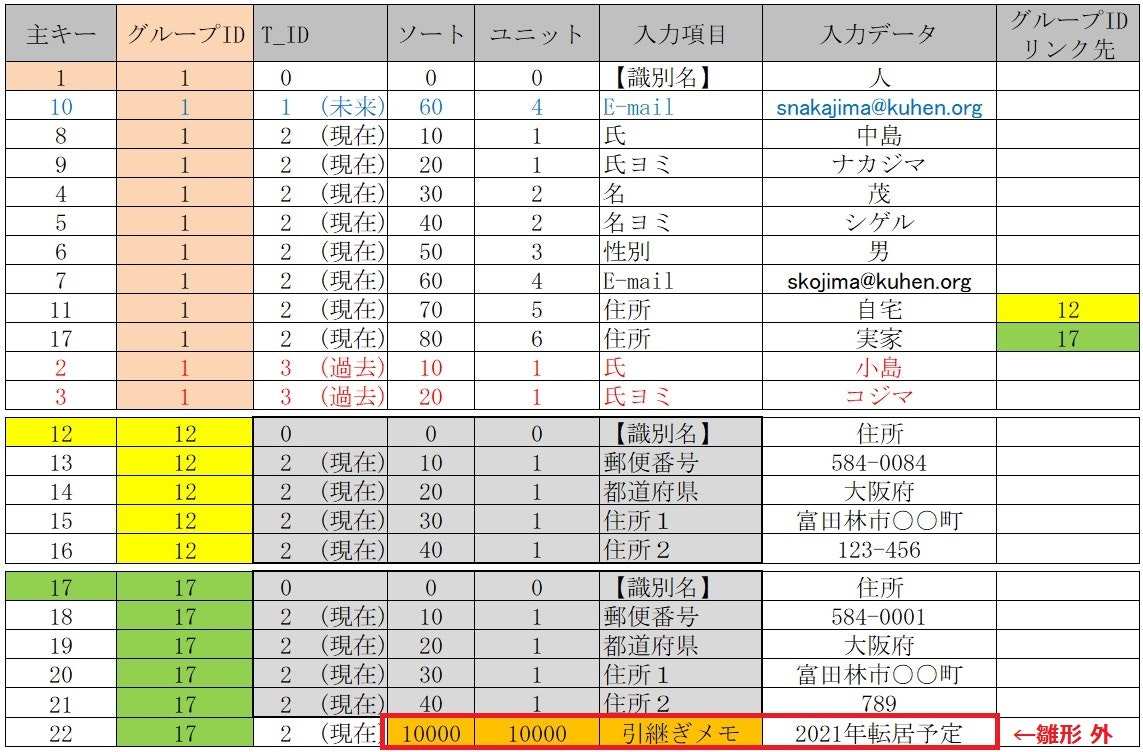
■ 【識別名】住所 の基本【入力項目(共通雛形)】以外の「入力項目」を
「ソート」と「ユニット」の数値が【10000】以上なら
◆管理外◆の「入力項目」として処理する
例:「入力項目」の「E-mail」を「メールアドレス」と変更する時は全データ対象
「入力項目」の「引継ぎメモ」が他のデータにあっても他データは変更しない
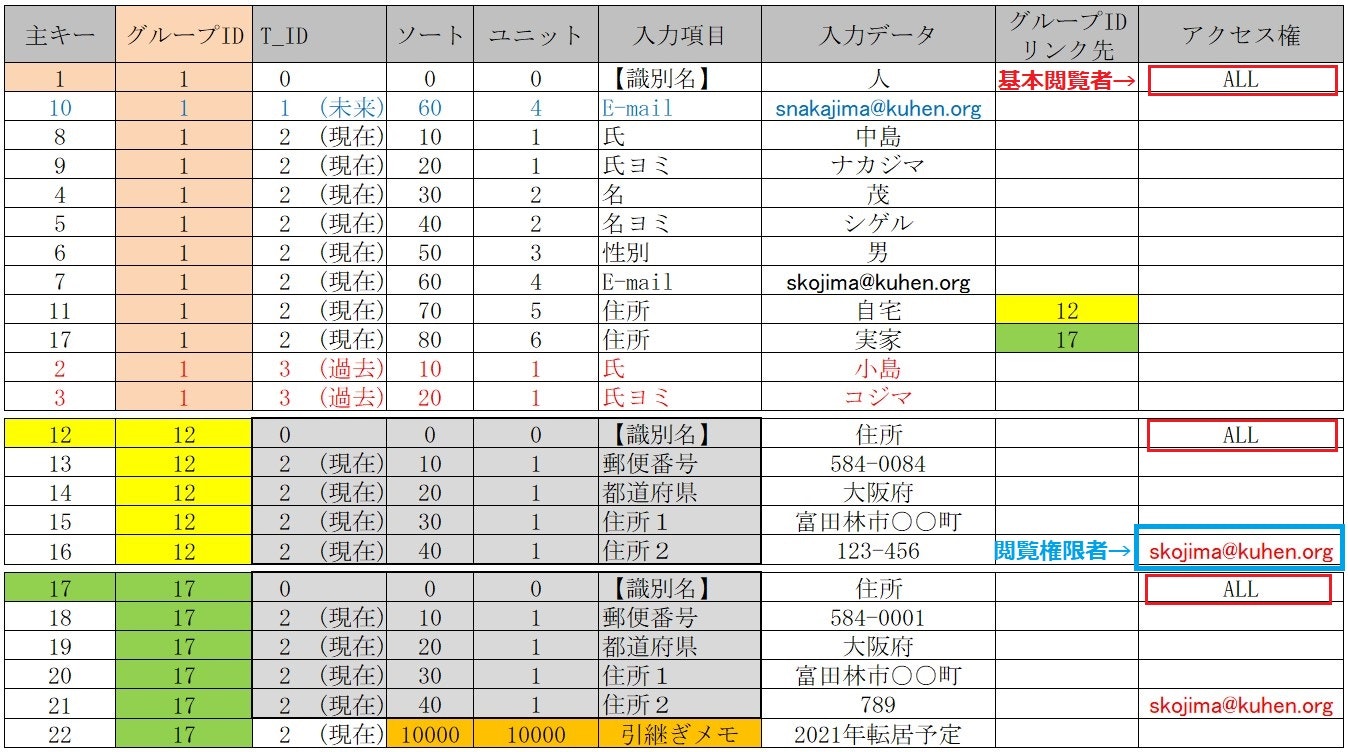
■ 個人情報保護用に 「アクセス権」列 を追加する
データ1個(1行)毎にアクセス権が設定可能で
例:skojima@kuhen.org , 総務
という権限者を列記してもよい
【方法1】
1.各【識別名】レコードの右端に【ALL】を入力
2.全員(ALL)がこのテーブルを検索対象とする
3.ただし「skojima@kuhen.org」がある行(データ)は検索対象外とする
【方法2】
1.【識別名】レコードの右端に【ALL】または「skojima@kuhen.org」を入力
2.「skojima@kuhen.org」のテーブルは全テーブルデータは最初から検索対象外
■ 【応用】 分散していた情報を1つの【グループ】にまとてみる
今までの【アクセス権】は 【読取り権】と【書込み権】に分けた
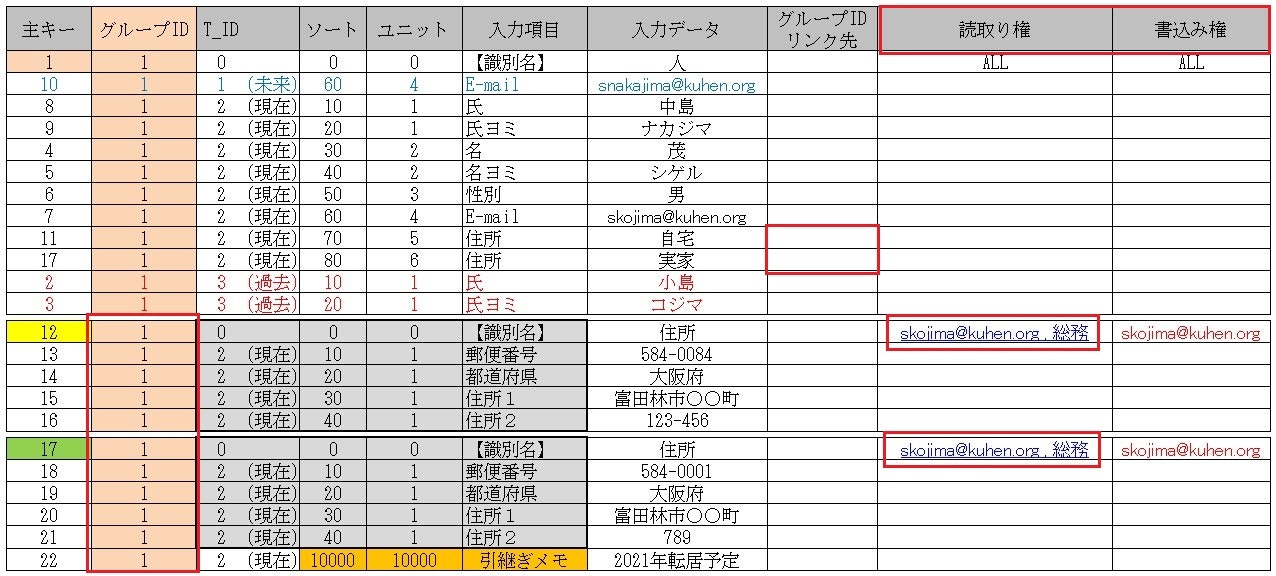
以上が「ニューロ型データベースモデリング Ver.1」の構造(特徴)です。
【主キー】と【グループID】はINTにしてそれ以外は全部文字列をおすすめします。
1個(1種類)の「テーブル」だけを使うのでシンプル構造になり「入力項目」を簡単に「追加」「変更」「削除(履歴化)」したり「テーブル」同士での「項目」移動、「テーブル」同士の「結合」や「分離」が簡単。
検索プログラムも1回作ってしまえば基本「メンテナンスフリー」になります。
最後に
20年かけてこの「ニューロ型データベースモデリング」の研究と開発をしてきました。
この「シンプルな構造」に特化した「日本発祥のデータベース」を開発・提供するのが最終目標ですがもう56歳になり一人では限界を感じています。
非公開のVer.2を手弁当(ボランティア)でAPIや検索プログラムのストアドなど(SQL用には既に2個作成済)ご協力してくれる方がおられましたら【 skojima@kuhen.org 】へご連絡ください。
kuhen.orgの有料GitHubは契約しましたが使い方が良くわかりません。