この投稿はNTTコミュニケーションズ Advent Calendar 2017の22日目です。
執筆はNTTレゾナントの @ktooriyama です。
NTTレゾナントはNTTコミュニケーションズのグループ企業です。個人のお客様にポータルサイトのgooやNTT-Xストア、gooSimsellerなどのサービスを展開し、法人のお客様にはWeb関連のICTソリューションをご提案しています。他にも、開発者向けにRemote TestKitを提供しています。
誰に向けた記事か
- クラウド環境の監視に興味がある方
- ZabbixやPrometheusに興味がある方
- ZabbixやNagiosを使っていてPrometheusがどう違うのか(何となく)知りたい方
- ZabbixのGUIがアレすぎてアレな感じになっている方
TL;DR
監視について説明する機会があまりなかったので、思うままに書いていたら長文になりました。書き直すのが面倒なのでそのまま投稿します。
- NTTレゾナントではOpenStackとCloud Foundryを使ったプライベートクラウドを運用しているよ
- プライベートクラウド上で稼働するVMとサービスの監視に、ZabbixとPrometheusを利用しているよ
- Zabbixをうまく使うと出たり消えたりするOpenStack上のVMを自動監視できるよ
- Prometheus+Grafanaを使うともっと変動しまくりなPaaS環境でも監視しやすいよ(けど課題もあるよ)
- (おまけ)ZabbixとGrafanaを組み合わせると既存環境をステキに見える化できるよ
はじめに
NTTレゾナントでは、OpenStackとCloud Foundryを利用してプライベートIaaS&PaaSを構築・運用しています。現在のOpenStackの規模はコンピュートノード 約400台、総VM数 3,300台です。Cloud Foundryは2017年7月からサービスインし、いまトピを始めとしたgooサービスの基盤として利用されています。
私が所属するチームはこうしたプライベートクラウド自体の開発・運用を担当していますが、あわせて IaaS上で稼働しているVMやPaaS上のサービスの監視も社内向けに提供しています。社内版のMonitoring as a Serviceのようなイメージで捉えていただければ結構です。1
本稿では、社内向けに監視をどのように提供してきたのかを簡単に解説しながら、ZabbixとPrometheusの特徴やpros/consについて書いていきます。
※本稿はNTT Tech Conference #2で発表した内容を下敷きに監視の側面をクローズアップしたものですが、内容は独立しています。
ZabbixでOpenstack上のVMを自動監視する
OpenStack上のVM監視にはZabbixを利用しており、Zabbixが備える監視自動化の仕組みを活用しています。
OpenStack上の3,300台のVMは、gooサービスなどを担当する多種多様なチームが構築したもので、私たちクラウド側のチームで直接構築したものではありません。勝手にVMを設定変更することはできませんから、各サービスの担当者には、zabbix-agentを決められた設定でインストールするように依頼しています。2
OpenStack上のVMは、サービス側の都合で増えたり減ったりします。VMの役割によって監視して欲しいミドルウェアの種類は異なります。開発機と商用機でアラート通知の深刻度を変更したいという要望も発生します。
このように多様かつ変動する3,000台オーバーのVMの監視設定を手作業で行ったりしたら、人件費がかさんで大赤字になるだけでなく、作業者の目が死んだ魚みたいになるでしょう。自動化は必須要件です。
実際にZabbixで自動監視する
Zabbixに求められる機能は以下の通りです。
- OpenStack VMの自動発見と自動登録
- 各VMに、サービス側が要求する監視を自動設定
それぞれ、以下の方法で実装しています。
- Zabbixのネットワークディスカバリ機能により、定期的にOpenStackの全テナントをIPアドレスレンジで走査してVMを探索
- サービス開発者が各VM上の既定ディレクトリに監視設定内容を記載したファイルを配置すると、Zabbixがそのファイルを読んで必要な監視テンプレートを適用する
- たとえば、Apache httpdの商用レベルの監視設定が必要なら、
apache_productionとファイル内に書いておくと、Zabbix上で対応する監視テンプレートがそのVMに適用されます
- たとえば、Apache httpdの商用レベルの監視設定が必要なら、
図解するとこのようになります。
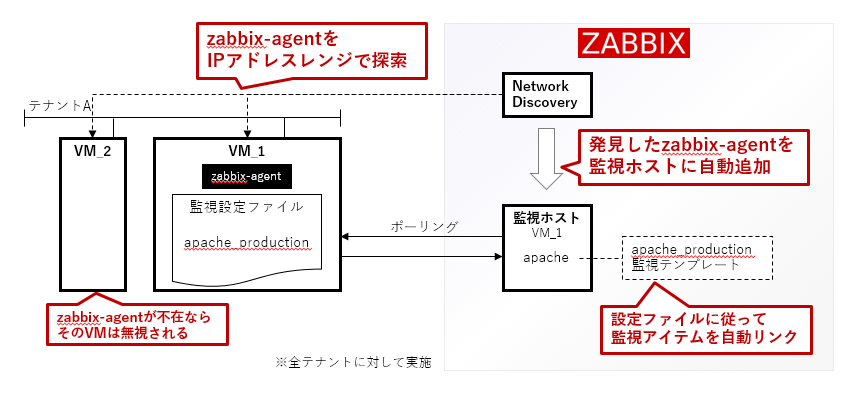
他にも工夫をしていますが、この方法をベースとして3,300台のVM監視を自動制御しています。
Zabbixはイケてる?
イケてると思っています。
- とにかく手堅く監視でき、安定稼働している
- 自動化をサポートするしくみが整っている
- 特定のホストだけアラート閾値を上書き変更する、といった柔軟な対応もできる
- 自身が実行した処理のログを残しているので、何があったのか追いかけやすい
当たり前ですが、使っていてしんどいところもあります。
- Web GUIのデザインが独特すぎて、必ず文句を言われる(俺が見たいグラフはどこにあるんだよぉぉぉ!)3
- 利用者に現在の監視設定をGUIで見せようとすると、監視設定を変更できる権限を渡さなければならない(手動で誤った設定変更をされると全体が破綻しかねないのでリスク有り)
- 複数セットを運用すると、それらの情報をまとめて監視・設定するための簡便な方法がない4
- Zabbix自体が高負荷に陥るほど使い込んでいくと、安定させるための工夫が数多く必要になる5
使っているからこそ多少の文句もあるのですが、それでもサーバホストを手堅く監視するならZabbixは現在でも有力な選択肢だと考えています。
PrometheusでCloud Foundry上のWebサービスを自動監視する
Cloud FoundryはPaaSです。その上に展開されるサービスの監視は従来のVM監視とは根本的に異なります。Zabbixは手堅さと柔軟性を兼ね備えた素晴らしいOSSですが、果たして適用できるでしょうか。
結論から書くと、ZabbixでCloud Foundry上のサービスを監視することは現実的ではないと判断してPrometheusを採用しました。
PaaS上のサービスの監視情報源はAPIとログ
Cloud Foundry上に展開されるサービスは、実際にはアプリケーションコードを含んだコンテナとして稼働します。Cloud Foundry自体がコンテナオーケストレータの役割を担っており、利用者が定義したコンテナの台数を担保するように動作します。何のURLをどのコンテナにマッピングするかも、利用者が簡単に設定できるようになっています。
Cloud Foundryの動作概要を図式化すると、以下のようになります。
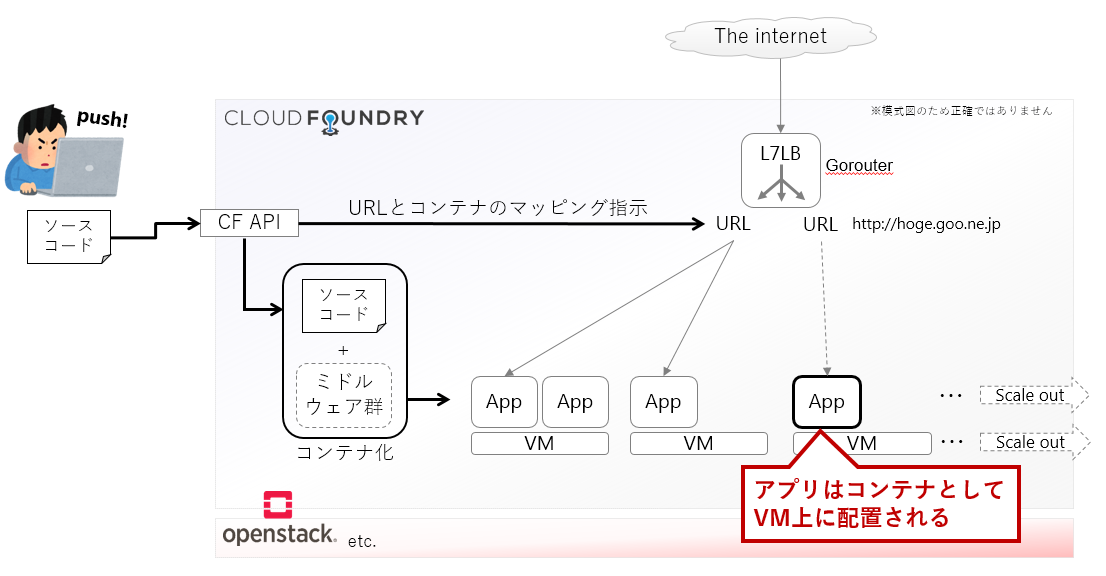
監視対象のメトリクスとしては、これらコンテナのCPU, メモリの状態を気にすることになります。CPUやメモリのメトリクスは、Cloud Foundry APIと、Cloud Foundryが搭載するFirehose6というログ出力モジュール7の両方から取得することが可能です。
一方、サービスの死活や健全性は、サービスのURL宛のHTTPリクエスト/レスポンスの状況を何らかの手段で把握する必要があります。各サービスのURLへの外部からのトラフィックは、Cloud Foundryが内包するソフトウェアロードバランサ"Gorouter"がURLベースのL7ルーティングを提供して処理します。こうしたHTTPリクエスト/レスポンスの履歴も、Firehoseから大量のログとして得ることができます。
ざっと図解するとこのようなイメージです。
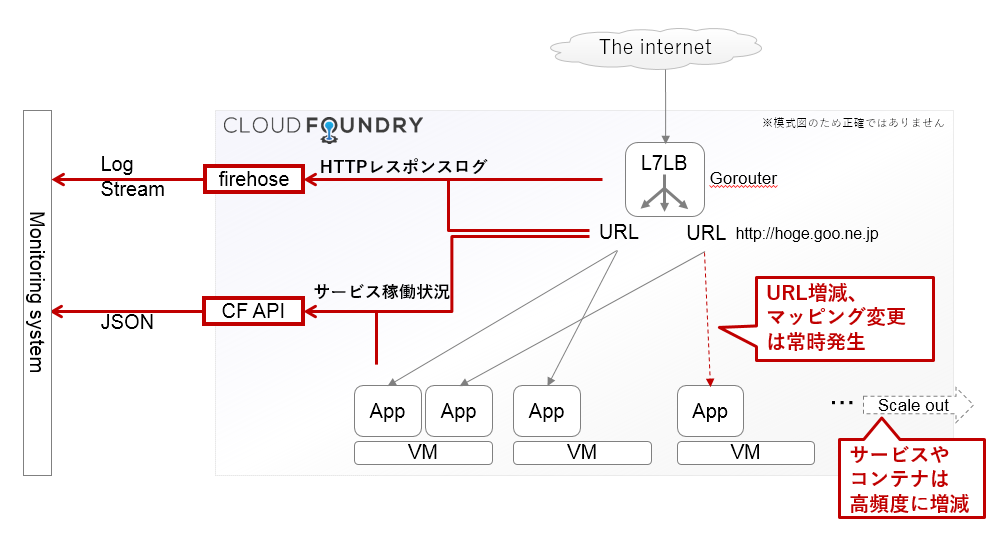
たとえば、APIやfirehoseからは以下のような情報を得ることができます。
Cloud Foundry API (公式ドキュメントより)
サービスの定義やステータスを取得するのに便利です
{
"total_results": 3,
"total_pages": 1,
"prev_url": null,
"next_url": null,
"resources": [
{
"metadata": {
"guid": "6064d98a-95e6-400b-bc03-be65e6d59622",
"url": "/v2/apps/6064d98a-95e6-400b-bc03-be65e6d59622",
"created_at": "2016-06-08T16:41:45Z",
"updated_at": "2016-06-08T16:41:45Z"
},
"entity": {
"name": "name-2443",
"production": false,
"space_guid": "9c5c8a91-a728-4608-9f5e-6c8026c3a2ac",
"stack_guid": "f6c960cc-98ba-4fd1-b197-ecbf39108aa2",
"buildpack": null,
"detected_buildpack": null,
"detected_buildpack_guid": null,
"environment_json": null,
"memory": 1024,
"instances": 1,
"disk_quota": 1024,
"state": "STOPPED",
"version": "f5696e0f-087d-49b0-9ad7-4756c49a6ba6",
"command": null,
"console": false,
"debug": null,
"staging_task_id": null,
"package_state": "PENDING",
"health_check_http_endpoint": "",
"health_check_type": "port",
"health_check_timeout": null,
"staging_failed_reason": null,
"staging_failed_description": null,
"diego": false,
"docker_image": null,
"docker_credentials": {
"username": null,
"password": null
},
"package_updated_at": "2016-06-08T16:41:45Z",
"detected_start_command": "",
"enable_ssh": true,
"ports": null,
"space_url": "/v2/spaces/9c5c8a91-a728-4608-9f5e-6c8026c3a2ac",
"stack_url": "/v2/stacks/f6c960cc-98ba-4fd1-b197-ecbf39108aa2",
"routes_url": "/v2/apps/6064d98a-95e6-400b-bc03-be65e6d59622/routes",
"events_url": "/v2/apps/6064d98a-95e6-400b-bc03-be65e6d59622/events",
"service_bindings_url": "/v2/apps/6064d98a-95e6-400b-bc03-be65e6d59622/service_bindings",
"route_mappings_url": "/v2/apps/6064d98a-95e6-400b-bc03-be65e6d59622/route_mappings"
}
},
...(snip)...
]
}
Cloud Foundry Firehose Gorouter log (HttpStartStop)
HTTPレスポンスコードやレスポンスタイムを取得することができます
origin:"gorouter" eventType:HttpStartStop timestamp:1490342338243712080 deployment:"cf" job:"router" index:"da47a061-5a18-4903-8478-38127fdec412" ip:"172.x.z.32" httpStartStop:<startTimestamp:1490342338182399930 stopTimestamp:1490342338243675973 requestId:<low:14213839074033669409 high:10169310528741837688 > peerType:Server method:GET uri:"http://www.example.com/" remoteAddress:"172.x.y.107:53698" userAgent:"curl/7.35.0" statusCode:200 contentLength:13941 applicationId:<low:13783871512652741491 high:10240381973283636141 > instanceId:"b9a20c63-b5f8-427b-7440-fcc71febabfd" forwarded:"172.x.y.107" >
ZabbixでPaaS上のサービスを監視…できませんでした
このようにAPIとログから得られた監視データを使って、ZabbixでCloud Foundry上のサービスを監視することができるでしょうか。
Zabbixは「監視ホスト」という単位で監視対象を設定する思想です。監視されるホストはIPアドレスを1つ以上保有していてzabbix-agentが稼働している前提で、メトリクスやアラートは「監視ホスト」に対して記録・判定されるようになっています。つまり、APIやログのデータを元にしてZabbixで監視を行うには、Zabbix上で扱える「監視ホスト」や「監視ホストのメトリクス」の形式に変換する必要がありそうです。
また、サービスとURLのマッピングや、コンテナの台数などは刻々と変動します。その変化はOpenStack上のVMよりも急激なものになります。APIやログを利用して、その変動にも追従しなければなりません。
これらは、Zabbixのローレベルディスカバリ(LLD)という機能を利用すれば原理上は実現できるでしょう。LLDはJSONで表現された情報から、自動的に監視アイテムや監視ホストさえも登録できてしまう機能です。わかりやすい解説はこちらの記事などが参考になります。8
LLDを応用すると、APIやログのパース結果をもとに自動的に監視ホストを追加したり、監視アイテムやアラートの設定を行うことができてしまいます。たとえばコンテナのメトリクスについては以下のような流れが考えられます。
- APIとログを適切にパースして、Cloud Foundry上の1コンテナを「監視ホスト」としてZabbixが解釈できるようにJSONとして出力するスクリプトを用意する。
- そのスクリプトをZabbixのLLDで定期的に実行する。
- スクリプトが実行されると各コンテナが(仮想的な)「監視ホスト」として追加される。(コンテナ上でzabbix-agentが稼働していない上に、コンテナから直接メトリクスを吸い出さないので仮想的な監視ホストと表現)
- このとき登録される「監視ホスト」の監視アイテムとして、APIとログをパースして自コンテナのCPU, メモリの値を取得するスクリプトを設定しておく。
- 「監視ホスト」の「アプリケーション」欄にコンテナが所属するCloud Foundry上のサービス名を記載することで、どのサービスにどの「監視ホスト(=コンテナ)」が所属しているかわかるようにする。
- ……など??
なに言ってんだコイツ。
一応、図解してみましょう。
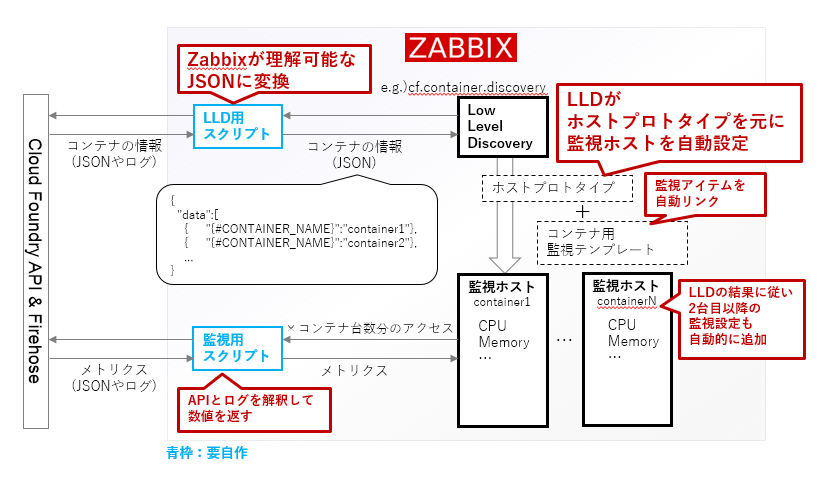
やっぱりなに言ってんだコイツ。
気合いを入れれば実装できるかもしれませんが、つらいです。
たとえば、Cloud Foundry側の負荷を考えると、メトリクスを取得するためだけに大量に稼働しているコンテナの数だけAPIにアクセスするのは悪手でしょうから、APIレスポンスをできるだけまとめて取得してキャッシュしてそこから読み出す、といった工夫の必要がありそうです。
他にも……
- Cloud Foundryにおけるそれぞれの要素(Org, Spaceなど)を、Zabbix上の何の要素に対応するように監視を設定すれば良いでしょうか。
- Firehoseのログを適切にパースする…って簡単に書いていますが、そもそもどうするのがよいでしょうか。FirehoseからのログをfluentdでカウントしてZabbixに送信する、ELKで溜め込んでから検索してメトリクス化する……方法はいくつかありそうです。
- URLとコンテナのマッピング情報は、どうやってZabbixの画面上に反映させればわかりやすいでしょうか。
考えるとキリがありません。どうやらLLDだと厳しそうです。なるほど完璧な作戦っスねーっ 不可能だという点に目をつぶればよぉ~
では、Zabbix APIを使えばどうでしょう。API経由なら、監視ホストの追加や削除などのあらゆる操作を思うままに制御することができます。……ただ、目的を達成するための開発コストは安くないでしょう。運用にのせたあとのメンテナンスも面倒が多そうです。これも上手い方法だとは思えません。
Zabbixは「監視対象は1つのホストとして安定的に存在する」という考え方に則っているため、そうではないものを監視するときには不都合が生じます。
選ばれたのは、Prometheusでした
Zabbixでは太刀打ちできないとわかりました。では、クラウドネイティブ環境の監視OSSとして注目されているPrometheusならどうでしょうか。
PrometheusはZabbixとはずいぶんノリが異なります。たとえば、公式サイトの解説にInstant vectorやらRange vectorなどという単語が書かれています。待って、帰らないで。「ベクトル」とかいきなり出てくるとヤバい香りがしますが、理解すればそれほど恐ろしいものではありません。…たぶん。
Prometheusの監視
PrometheusサーバはExporterと呼ばれる監視エージェントから値をPullして溜め込みます。zabbix-agentを連想させますが、**Exporterは監視対象ごとに実装が異なる点がZabbixと違います。**Exporterは自作も可能です。
Cloud Foundryの場合は、APIの実行結果をPrometheus用に変換して返してくれるCloud Foundry Prometheus Exporter(cf_exporter)、Firehoseからのログを同様に変換して返してくれるCloud Foundry Firehose Exporter(firehose_exporter)、Firehose-to-syslog(firehose-to-syslog)+grok_exporterなどを利用できます。
各Exporterのメトリクスは、多次元ベクトルのような形式でPrometheusに渡されます。たとえばCloud Foundry Firehose Exporterから、各コンテナのCPU利用率を取得すると、次のような1コンテナ1行のメトリクスが返ってきます。
| Element | Value |
|---|---|
| firehose_container_metric_cpu_percentage{ application_id="92bbd8f8-35ad-4228-8478-561ce123459a", bosh_job_ip="172.x.y.128", bosh_job_name="cell", instance="firehose_exporter:9186", instance_index="5", job="firehose"} |
0.6165940472169581 |
| firehose_container_metric_cpu_percentage{ application_id="92bbd8f8-35ad-4228-8478-561ce123459a", bosh_job_ip="172.x.y.129", bosh_job_name="cell", instance="firehose_exporter:9186", instance_index="6", job="firehose"} |
20.408200363712947 |
| firehose_container_metric_cpu_percentage{ application_id="92bbd8f8-35ad-4228-8478-561ce123459a", bosh_job_ip="172.x.y.130", bosh_job_name="cell", instance="firehose_exporter:9186", instance_index="7", job="firehose"} |
0.4638560322248198 |
ここでのappplication_idはコンテナが所属するサービスを、instance_indexはスケールアウトされた何台目のコンテナであるかを、bosh_job_ipはコンテナが動作するVMのIPアドレスを示しています。これらを_label_と_labelvalue_と呼びます。右列の_Value_はそのままメトリクスの値です。
読み解くと、これら3つのコンテナはすべて同一の92bbd8f8-35ad-4228-8478-561ce123459aというサービスのコンテナで、それぞれのCPU利用率が0.6%, 20.4%, 0.5%程度であることがわかります。コンテナが増えれば instance_index="8"と書かれたメトリクスが1行増えて、自動的に取得されるようになります。サービスが増えたときはapplication_idが異なるメトリクスが出現します。
つまり、_label_と_labelvalue_で多次元ベクトル的にメトリクスを表現することで、「このメトリクスが何を表現しているか」を端的に、わかりやすく表現しているのです。**すべてのメトリクスはlabelとlabelvalueが異なるだけでフラットかつスキーマレスに保存されているので、「監視ホスト」がどーだとか悩む必要がありません。**ZabbixのLLDよりも見通しよく環境変動に追従できそうです。
PrometheusのGUI上で、溜め込んだメトリクスを確認することができます。例として、instance_index="5"のコンテナのCPU利用率は、以下のように取り出せます。
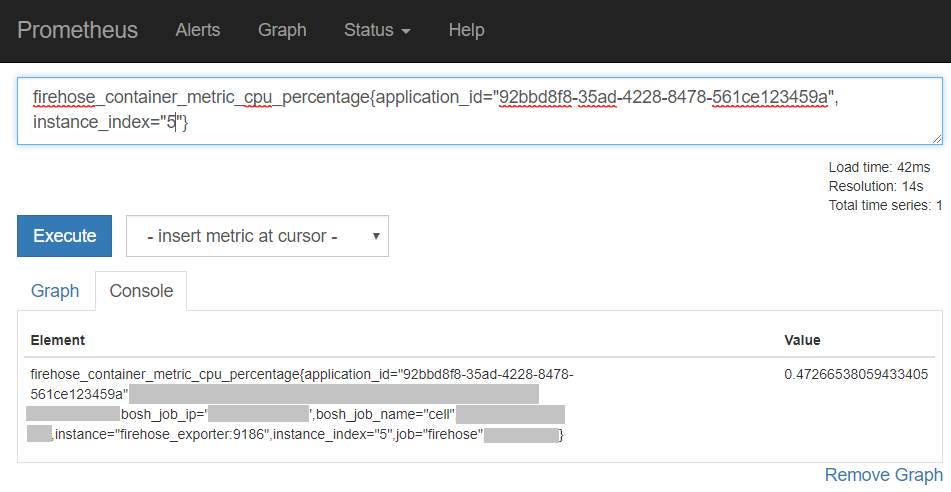
こうしたメトリクスに対するクエリはPromQLと呼ばれます。_labelvalue_やメトリクス名に対して正規表現で検索することもできますし、最初に「多次元ベクトルのような」と表現した通り、メトリクス同士をベクトルのように足したり掛け合わせたりして、新しいメトリクスを作成することも可能です。この機能こそがPrometheusにおける肝となります。
たとえば、「HTMLレスポンスコードが400番台のアクセスの割合が3分間で10%を超えている」を表現しようとすると、こんなPromQLになります。
(sum(rate(cf_application_response_time_sec_bucket{host_domain=“hoge.goo.ne.jp",http_status=~"^4..$",le="+Inf"}[3m])) by (organization_name, space_name, host_domain) / sum(rate(cf_application_response_time_sec_bucket{host_domain=“hoge.goo.ne.jp",le="+Inf"}[3m])) by (organization_name, space_name, host_domain) ) * 100 > 10
待って、帰らないで。
……PromQLを覚えるところだけは避けようがないので、ここは頑張ってください。**要するに慣れです。**GUI上でクエリを試行錯誤すればコツがつかめます。
Prometheusのメトリクスをグラフ化する場合、Grafanaを使うことがデファクトスタンダードです。Prometheusをデータソースとして指定すれば美しくグラフを描画することができます。もちろん、PromQLを正しく理解し、Grafanaのしくみも把握する必要はありますが。9
このように、Prometheusでは監視対象にあわせたExporterが必要になりますが、Exporter側でよしなにメトリクスを出力することで、環境変動が発生してもシンプルにメトリクスを収集することが可能なのです。
実際にPrometheusで自動監視する
というわけで、Cloud Foundry上のサービス監視にはPrometheusを利用することとします。グラフの描画にはGrafanaを利用しました。
実現したいことは下記の通りです。
- HTTPレスポンスの状況と、URLにマッピングされたコンテナの状況をまとめて表示
- URLとコンテナのマッピングや、コンテナのスケールアウト、サービスの追加・削除が発生したら自動反映
実現方法は下記の通りです。
- Prometheusでcf_exporter, firehose_exporter, firehose-to-syslog+grok_exporterからメトリクスを収集する(各ExporterはCloud Foundryに適切に接続する前提)
- 収集した値をGrafana上でゴニョゴニョして描画する
- Cloud Foundry側で設定が変更された場合は対応するメトリクスの_labelvalue_が変動するので、チョチョイと画面に反映する
説明する気あるのかお前。
……実現方法を細かく書いていくとこの投稿がさらに長くなるので割愛しましたが、具体的にはPromQLやGrafanaのTemplatingを活用します。ともかく、Zabbixで実現するよりはシンプルに解決できそうだということが何となくご理解いただけると幸いです。できるんだよ。わかったね?
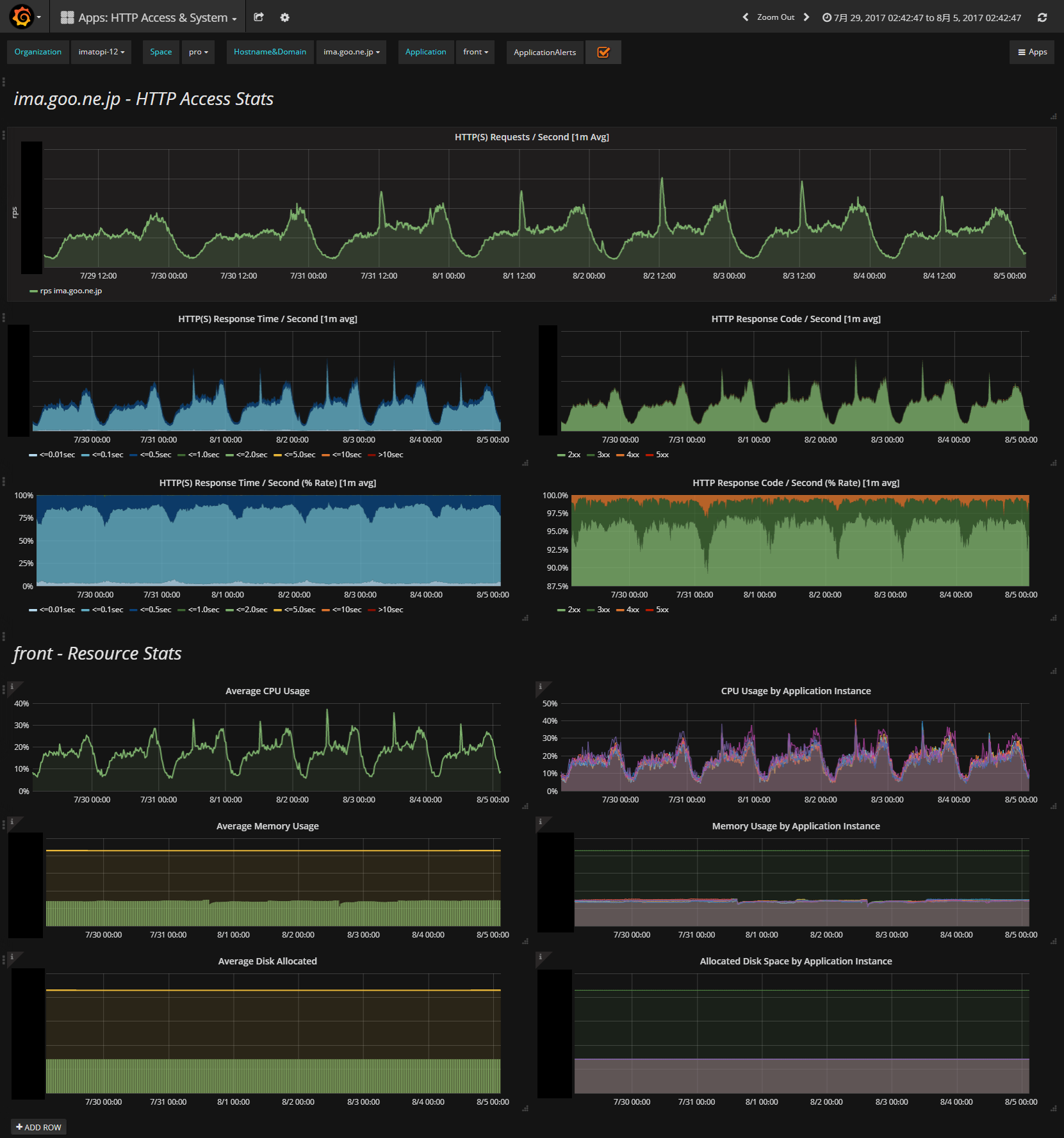
結果としてこうなりました。上半分はサービスのURLに対するHTTPレスポンスの統計、下半分はURLにマッピングされているコンテナのCPU/メモリ/ディスクの統計です。サービスとリソースの稼働状況を1画面で確認できるので、状況を俯瞰しやすくなっています。Zabbixでこのような画面を作ろうとするとスクリーン機能を使うことになりますが、Grafanaほど簡単ではないでしょう。
PrometheusでVMを監視する場合はどうなる?
「ZabbixよりPrometheusの方が柔軟そうに見えるけど、それってAPIやログを監視した場合の話でしょ? 同じ土俵で、たとえばOpenStack上のVM監視で勝負をしたらどうなるのさ?」
こんな疑問が生じる方もいそうなので、Prometheusで大量のVMを監視するとどうなるのか書いておきます。やったことないけど。
VMや物理サーバを監視する場合、Node exporterを利用するのが常道です。Node exporterは監視対象のサーバ上で動作させる必要があり、Prometheusは各Node exporterから値を取得する必要があります。この辺りはzabbix-agentとまったく同じです。
Zabbixの場合はVMの探索にネットワークディスカバリを利用しました。10Prometheusでは、Service Discoveryという機能を利用できます。
Service Discoveryは、「このIPアドレスとポート番号で●●●●というExporter(Target)が動作しているぞ」という情報をPrometheusが検知するしくみです。Kubernetes、Consul、DNS、AWS EC2に正式対応しており、コンフィグを書くだけでTargetがどこにあるのかPrometheusが把握できるようになります。OpenStack Nova APIなどもベータ扱いで対応しています。具体例は公式サイトを参照してください。
未対応の場合でも、YAMLかJSONファイルを書いてPrometheusに読ませるとService Discoveryが利用できます。**ファイルを更新した瞬間にTargetが追加・削除されるため、環境変動への追従は高速です。**YAMLかJSONを吐き出し続けるスクリプトを自作すれば、簡単にTargetの自動更新が可能になります。
そういうわけで、大量のVMをPrometheusで監視する場合でも、セットアップに途方もない労力がかかることはありません。Kubernetesなどの対応している環境であれば、Zabbixよりも簡単でしょう。
Zabbixでもやり方によっては同じくらい高速にVM追加・削除に追従できそうですが、手間暇がかかったり、見通しが悪くなったりしそうです。11
Prometheusはイケてる?
イケてると感じます。
正確には、Grafanaと組み合わせてグラフィカルに「見える化」できるところまでを含めるとイケてます。Prometheus単体だとグラフがまともに描画できませんから、使い物になりません。
目的に適った既存のExporterが存在しない場合は自作する必要がありますが、原理はそれほど難しくないので、監視スクリプトの延長で少し頑張れば対応できるでしょう。
全体的に素晴らしいOSSです。しかし、「OpenStack VMの監視をすべてPrometheusで置き換えたいか?」と問われると、今すぐ置き換えようとまでは思っていません。その理由については、次のセクションで述べます。
ZabbixとPrometheusを商用で使ってみて
Zabbixを数年、Prometheusを半年ほど運用に使ってみてどう感じているかをまとめます。
手堅さと安心感
全般にZabbixの方が手堅くて安心できると感じています。さすがにエンタープライズ分野でも使われてきたOSSです。ただ、自チームの担当範囲を監視するだけならPrometheus+Grafanaの方が柔軟に対応できそうなので、今の私なら小規模な監視にはPrometheusを使うでしょう。
Zabbixはzabbix-agentが1種類なので、agent側の不都合に振り回されることがまずありません。PrometheusはExporterが監視対象ごとによしなに対応することで楽をさせてくれますが、それはExporterの実装がまちまちであることと表裏一体です。大規模な環境で運用するなら自前で検証する必要が生じるでしょう。
Exporterがおかしな挙動をするとデバッグは面倒です。Exporterやその周囲に異常が生じたとき、Exporterが自ら適切にExitするなりエラーを出力してくれるなら対処のしようがありますが、そうとも限りません。Cloud Foundryの監視系を構築しているときは、Exporterは生きているのにメトリクス値だけが更新されなくなるケースに遭遇しました。他にも、定期的に再起動しないと不要なメトリクスを保持し続けてしまうExporterもありました。Exporterごとにクセがあることを認識しておくべきです。
また、Prometheusのアラート通知機構であるAlertManagerはいまいち動作がつかみづらいところがあります。Zabbixは自身が実行したアクションを記録していますが、AlertManagerは仔細には教えてくれません。障害を検知したあとアラート通知されたのかされていないのかが把握しづらいです。12監視静観時の挙動も少しばかり怪しいときがありました。安心して使うにはまだちょっと怖いところがあります。
Prometheusで第三者に監視を提供する場合はこのような観点が気になるので、「安心安全か?」と問われると首を縦に振りづらいです。今すぐにOpenStack VMの監視をZabbixからPrometheusに移行しようとは考えていません。
DB冗長化やデータバックアップの容易さ
ZabbixはMySQLにデータが溜まっているので、MySQLの使い方を把握している人ならバックアップ方法に困ることはないでしょう。監視ログデータの保存が不要であれば、監視設定のテーブルだけをバックアップすれば所要時間とデータ量を低減することもできます。DBの冗長を組むときにも悩むことはないでしょう。
Prometheusの場合、コンフィグはすべてテキストファイル上にあるのでリポジトリ管理すればよいだけです。しかし、時系列データをバックアップするのは容易ではありません。少なくとも1.x系は。バックアップ方法を含めて、監視を冗長化するためにいろいろと考えなければなりませんでした。
2.x系から時系列データの保存方法に改良が加えられて、超高速バックアップが可能になりました。まだ試せていませんが、いまから使うなら間違いなく2.x系でしょう。
なおPrometheusにはそもそもDBの冗長化という概念がないので、単一障害に耐えるにはAct/Actで複数台を動作させるか、Kubernetesのようなオーケストレータに載せて自動復旧させる、といった対策が必要です。通知を司るAlertManagerのHAがまだ開発段階なのが困ったところです。
環境変動への追従性
Zabbixも相当に頑張れますが、Prometheusの追従性を見てしまうとさすがに分が悪いでしょう。
PrometheusのTargetを瞬時に追加・削除できる点は非常に優秀です。対象が増減してもメトリクスが増えたり減ったりするだけで、複雑なことを考える必要がないことも評価できます。
ただ、PrometheusはExporterができないことは基本的にできません。Exporterがどういうメトリクスを出力するかにかかっています。それぞれのExporterのメトリクスを理解することが重要です。逆に「Exporterを自作してしまえばかなり何でもできる」とも言えます。また、使ったことはありませんがscript-exporterのようなものもあるので、懐は広いです。
複数セット構築したときの運用
Zabbixを複数セット構築すると、それぞれのダッシュボードを見てオペレーションすることになります。Hatoholのように複数セットの情報をまとめて表示してくれるソリューションもありますが、その学習コストと運用コストは支払わなければなりません。そこまでしてやりたいかどうか、という話になります。
まだ試していないのですが、PrometheusはFederationを使うことで複数セットの情報を1セットにまとめることができます。たとえば、OpenStackのテナント毎にPrometheusを1セットずつ提供し、全テナントの情報を1箇所のPrometheusに集めて、全環境の監視状況をひとまとめに俯瞰する…といったことも実現できそうです。Federationしようとすると多少設定が複雑化しますが、ネイティブサポートされている点は大きいですよね。
すべてを包括的に確認できる監視系統をシンプルに構築できるなら、それは素晴らしいことです。
GUIのわかりやすさ・使いやすさ
お察し下さい。
(おまけ)Zabbix plugin for Grafana
「Zabbixが持っている既存データをわかりやすくグラフ化したいけれど、その方法がなくて困っている」
そんなあなたに朗報です。Zabbix plugin for Grafana(grafana-zabbix)とGrafanaを利用することで、Zabbix DB上のメトリクス値を超絶美しいグラフに仕立てることができます。
特筆すべき点は、Direct DB Connectionを使うことでGrafanaからZabbix DBに直接接続することができ、グラフ描画が非常にスムーズであることです。また、古いバージョンであるZabbix 2.2でもグラフ化ができてしまいました。13
試しに、OpenStack上の全VMの中から、Disk read access/secのTop10 VMだけを描画してみるとこのようになります。このグラフ、めちゃくちゃ簡単に描けます。
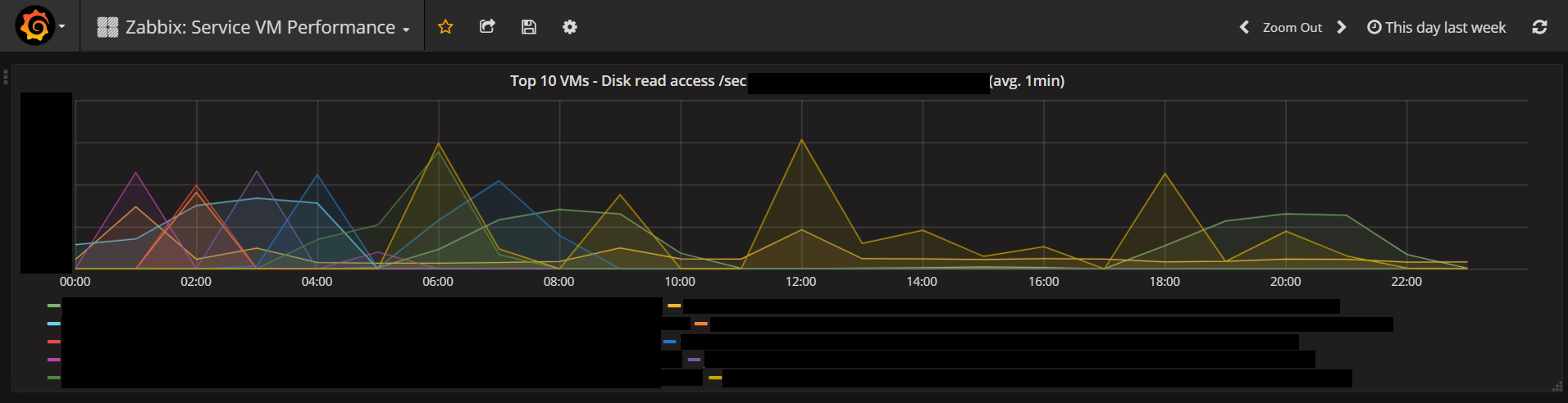
他に、以下のようなケースにも問題無く対応できます。便利すぎて鼻血が出そうですね!
- あるホストグループに所属するホストの特定のグラフだけを重ねて描画したい
- ホスト名や監視アイテムを正規表現でマッチさせて描画したい などなど
ただ、本番系のZabbixにgrafana-zabbixを無邪気に接続することは避けた方が良いです。Zabbix GUIから通常のオペレーションをしているときとは比べものにならないくらい重いSQLクエリがZabbixに飛ぶ可能性があります。バックアップデータを使うとか、待機系のDBを参照するとか、何かしら工夫した方がベターです。
最後に
Prometheusは使い初めて日が浅いですが、その潜在能力の高さには驚くばかりです。まだ不安要素も見え隠れしていますが、開発が進んで安定感が増してきているので、次のOpenStack環境をつくるときはPrometheusを使えないか検討したいと思っています。
Zabbixは従来の監視スコープであれば手堅い選択肢です。クラウドネイティブなサービスのように変動が激しい対象を監視する場合は、どこまで対応できるのか検討する必要があるでしょう。「監視ホスト」という概念が当てはまらないケースには要注意です。
ZabbixもPrometheusも素晴らしい監視OSSです。得手不得手を理解して使っていきましょう。
-
各サービスでばらばらに監視システムと業務フローを構築するよりは、集約して監視業務フローを統一した方がコスト面で有利かつ内部統制が利く、という考え方がベースにあります。 ↩
-
ただzabbix-agentをインストールしてくれと言ってもうまくいかないので、Puppetを使えば簡単にインストールできるようにしくみ化されています。 ↩
-
慣れだよ慣れ。 ↩
-
Hatoholのようなものを使う手はあります。ただ、関係者全員の学習コストに見合うのか?という話になります。 ↩
-
高負荷対策の苦労は色々ありました。どの監視OSSも大規模に使うには工夫が必要だと思いますが…。 ↩
-
TwitterのFirehoseやAmazon Kinesis Firehoseなどと同様、消火用ホースの連想から付けられたのではなかろうか。 ↩
-
ログとしてメトリクスを取得するのはどうも違和感があるけども、そういうもの。 ↩
-
LLDはZabbixの自動化の仕組みにおいて最終兵器と呼んでも差し支えないほど強力な機能だと思いますが、禍々しいオーラを放つ諸刃の魔剣でもあると思います。自由度が高すぎて、考え無しに派手に使うと後任者がメンテナンスできなくなること請け合いです。GUI上でネットワークディスカバリと混同しがちなのも初学者泣かせです。 ↩
-
GrafanaにもTemplatingとかダッシュボードの管理方法とか、いろいろハマりそうなポイントがあります。慣れだよ慣れ。 ↩
-
自動登録という機能もあります。この場合はzabbix-serverがzabbix-agentを探査するのではなく、zabbix-agentがzabbix-serverに自らの存在を通知します。一部の挙動が我々の要件に適合しなかったので採用しませんでした。 ↩
-
Zabbixの自動登録のしくみでzabbix-agentから高速追加はできるにしろ、agent側にserverの所在を教える設定が必要です。削除のタイミングをどうするかも悩ましいでしょう。Zabbix APIから追加・削除をスクリプトで制御する方が良さそうな気がします。……そこまでしたいならね。 ↩
-
Alertmanagerのすべてのアラート通知をwebhookで記録用のシステムに並行して飛ばす、とかやれば通知ログ的なものを溜めることはできると思いますが、ネイティブに対応していないのは少々辛いです。 ↩
-
Zabbix APIにtrends(メトリクスの過去データ)をGETする機能が実装されたのはZabbix 2.4以降です。この機能は、API経由で外部システムにメトリクスを提供する場合は事実上必須です。Zabbix 2.2の場合はパッチをあてると利用できるようになります。が、Zabbix plugin for Grafanaの場合はMySQLに直接接続するので、そもそもAPIからtrendsを取得する必要がありません。スバラシイ。 ↩