Max Mind社が提供しているIP GeoLocationデータ(IPアドレスと地理情報のマッピング)であるGeoLite2を使って、Databricks上でIPアドレスから地理情報をマッピングする方法について見ていきます。
- 本記事のサンプルNotebook - (記事内で紹介するCodeを含む)
IPアドレスから地理情報が取得できれば、ログ解析やウェブマーケティグなどで幅広く活用できる情報源になります。一方で、IPアドレスは非常にカーディナリティ(値の種類)が高く、照合(Lookup)する際のコストが高くなります。DatabricksのDelta LakeおよびRange Joinを使うことで非常に高速・高効率にIPから地理情報の照合が実現できます。リアルタイムな地理情報が必要なアプリケーションなどでも使用できます。
GeoLite2を使用することで、IPアドレスから以下の情報をLookupすることができます。
|-- ipaddr: string
|-- asn_network: string
|-- autonomous_system_number: integer
|-- autonomous_system_organization: string
|-- city_network: string
|-- registered_country_geoname_id: integer
|-- represented_country_geoname_id: integer
|-- is_anonymous_proxy: integer
|-- is_satellite_provider: integer
|-- postal_code: string
|-- latitude: double
|-- longitude: double
|-- accuracy_radius: integer
|-- locale_code: string
|-- continent_code: string
|-- continent_name: string
|-- country_iso_code: string
|-- country_name: string
|-- subdivision_1_iso_code: string
|-- subdivision_1_name: string
|-- subdivision_2_iso_code: string
|-- subdivision_2_name: string
|-- city_name: string
|-- metro_code: integer
|-- time_zone: string
|-- is_in_european_union: integer
Max Mind - GeoLite2について
GeoLite2は、有償サービスであるGeoIPに比べて精度が低いものの、無償で利用できるIPアドレス-地理情報のデータベースになります。利用規約にあるとおり、商用で利用する場合にはアトリビューションの提示が必要になりますので、利用の際にはご確認ください。
GeoLite2はWeb上でIPから地理情報を取得できるWebサービスもありますが、データベースがCSVファイルでも提供されています。Databricks上で使用する際は、このCSVファイルからDelta Lakeを作成し、SQLのテーブルとして利用します。
GeoLite2のウェブサイトからユーザー登録をすると、ダウンロードのためのライセンスキーが発行できますので、そちらを用意します。
環境準備
以下の2点を事前準備しておきます。
- GeoLite2のライセンスキー
- データブリックスからアクセス可能(Read/Write)なオブジェクトストレージ
今回の例では、オブジェクトストレージとしてAWS S3を使用します。Azure Blog StorageやGoogle Cloud Storageでも同様に可能です。
GeoLite2のCSVのダウンロード・S3への配置
まずは、GeoLite2のCSVデータをダウンロードしてオブジェクトストレージ上に配置します。
GeoLite2はアップデートがあった場合でも機械的にファイルをダウンロードできるように静的なURL(Permalink)でCSVデータがダウンロードできるようになっています。
Databricksクラスタのドライバノード上にCSVファイルをダウンロードして、boto3を使ってS3にアップロードしています。
params={}
params['geolite2']={}
params['geolite2']['s3_bucket'] = S3_BUCKET_NAME
params['geolite2']['license_key'] = GEOLITE2_LICENSE_KEY
params['geolite2']['asn_csv_url'] = f"https://download.maxmind.com/app/geoip_download?edition_id=GeoLite2-ASN-CSV&license_key={params['geolite2']['license_key']}&suffix=zip"
params['geolite2']['city_csv_url'] =f"https://download.maxmind.com/app/geoip_download?edition_id=GeoLite2-City-CSV&license_key={params['geolite2']['license_key']}&suffix=zip"
params['geolite2']['country_csv_url'] = f"https://download.maxmind.com/app/geoip_download?edition_id=GeoLite2-Country-CSV&license_key={params['geolite2']['license_key']}&suffix=zip"
params['geolite2']['s3_base_dir'] = S3_DIRECTORY
params['geolite2']['asn_dirname']='ASN'
params['geolite2']['country_dirname']='Country'
params['geolite2']['city_dirname']='City'
def upload_to_s3(local_filepath, bucket, upload_path):
import boto3
from botocore.exceptions import ClientError
client = boto3.client('s3')
try:
ret=client.upload_file(local_filepath, bucket, upload_path)
except ClientError as e:
print(e)
return False
return True
def downlaod_file(url, local_filepath):
import subprocess
try:
ret=subprocess.Popen(args=['curl', '-o', local_filepath, url],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE )
print( ret.communicate() )
except Exception as e:
print(f'error=>{e}')
def get_and_upload_csv_to_s3(url, tagname, s3_bucket, upload_dir, tmpdir='/tmp'):
'''
url: geolite2 permalink
tagname: fike name for temp use
upload_dir: s3 directory name the file is uploded to
'''
import zipfile
import os.path
# get the files
local_filepath = os.path.join(tmpdir, tagname)
print(f'local_filepath => {local_filepath}')
downlaod_file(url, local_filepath)
# unzip
z = zipfile.ZipFile(local_filepath)
files = z.namelist()
with z as f:
f.extractall(tmpdir)
# uploading to s3
for n in files:
if n.lower().endswith('.csv'):
local=os.path.join(tmpdir, n)
base=os.path.basename(n)
s3_path=os.path.join(upload_dir, tagname, base)
print(f'''uploading files to s3: {local} => s3://{params['geolite2']['s3_bucket']}/{s3_path}''')
upload_to_s3(local, s3_bucket, s3_path)
# ASN
get_and_upload_csv_to_s3(
params['geolite2']['asn_csv_url'],
params['geolite2']['asn_dirname'],
params['geolite2']['s3_bucket'],
params['geolite2']['s3_base_dir']
)
# Country
get_and_upload_csv_to_s3(
params['geolite2']['country_csv_url'],
params['geolite2']['country_dirname'],
params['geolite2']['s3_bucket'],
params['geolite2']['s3_base_dir']
)
# City
get_and_upload_csv_to_s3(
params['geolite2']['city_csv_url'],
params['geolite2']['city_dirname'],
params['geolite2']['s3_bucket'],
params['geolite2']['s3_base_dir']
)
CSVからDeltaテーブルを作成
CSVをSparkのデータフレームとしてロードして、そのままDeltaフォーマットで書き出します。
その後、SQLからも参照できるように、テーブルを作成します(CREATE TABLE)。
# CSVからDeltaテーブルを作成
def createTableDelta(csv_path, table_name, dbname='db_geolite2'):
delta_path = csv_path + '.delta'
(
spark
.read
.format('csv')
.option('Header', True)
.option('inferSchema', True)
.load(csv_path)
.write
.format('delta')
.mode('overwrite')
.save(delta_path)
)
sql(f'''
CREATE DATABASE IF NOT EXISTS {dbname}
''')
sql(f'''
CREATE TABLE IF NOT EXISTS {dbname}.{table_name}
USING delta
LOCATION '{delta_path}'
''')
s3_base = f'''s3a://{params['geolite2']['s3_bucket']}/{params['geolite2']['s3_base_dir']}'''
# ASN
createTableDelta(f'{s3_base}/ASN/GeoLite2-ASN-Blocks-IPv4.csv', 'geolite2_asn_blocks_ipv4_delta', DELTA_DATABASE_NAME)
createTableDelta(f'{s3_base}/ASN/GeoLite2-ASN-Blocks-IPv6.csv', 'geolite2_asn_blocks_ipv6_delta', DELTA_DATABASE_NAME)
# country
createTableDelta(f'{s3_base}/Country/GeoLite2-Country-Blocks-IPv4.csv', 'geolite2_country_blocks_ipv4_delta', DELTA_DATABASE_NAME)
createTableDelta(f'{s3_base}/Country/GeoLite2-Country-Blocks-IPv6.csv', 'geolite2_country_blocks_ipv6_delta', DELTA_DATABASE_NAME)
createTableDelta(f'{s3_base}/Country/GeoLite2-Country-Locations-en.csv', 'geolite2_country_locations_en_delta', DELTA_DATABASE_NAME)
# city
createTableDelta(f'{s3_base}/City/GeoLite2-City-Blocks-IPv4.csv', 'geolite2_city_blocks_ipv4_delta', DELTA_DATABASE_NAME)
createTableDelta(f'{s3_base}/City/GeoLite2-City-Blocks-IPv6.csv', 'geolite2_city_blocks_ipv6_delta', DELTA_DATABASE_NAME)
createTableDelta(f'{s3_base}/City/GeoLite2-City-Locations-en.csv', 'geolite2_city_locations_en_delta', DELTA_DATABASE_NAME)
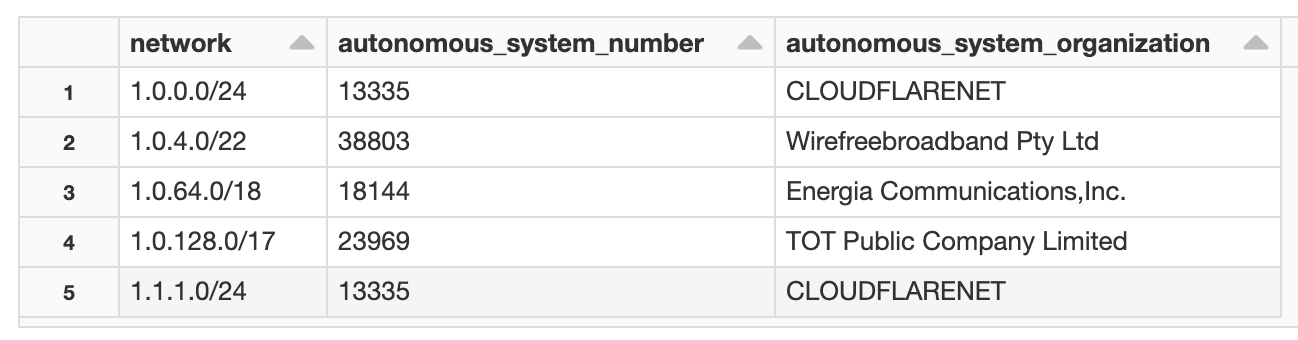
(Optional) データ確認
Deltaテーブル化されたGeoLite2データをいくつか確認してみます。
%sql
SELECT * FROM geolite2_asn_blocks_ipv4_delta LIMIT 5
%sql
SELECT * FROM geolite2_country_locations_en_delta LIMIT 5

IPアドレスから地理情報を調べる(Lookup)
IPアドレスは文字列になっている一方で、GeoLite2のロケーションはCIDRブロックで与えられています。そのため、IPアドレスとCIDRブロックのマッピングで使う関数を定義します(UDF)。
# IP addressとCIDRブロックのマッピングで使うUDF
import pandas as pd
from pyspark.sql.functions import pandas_udf, col
@pandas_udf('long')
def to_network_address(cidr: pd.Series) -> pd.DataFrame:
import ipaddress as ip
return cidr.apply(lambda x: int(ip.IPv4Network(x).network_address) )
spark.udf.register('to_network_address', to_network_address)
@pandas_udf('long')
def to_broadcast_address(cidr: pd.Series) -> pd.DataFrame:
import ipaddress as ip
return cidr.apply(lambda x: int(ip.IPv4Network(x).broadcast_address) )
spark.udf.register('to_broadcast_address', to_broadcast_address)
@pandas_udf('long')
def to_address_int(cidr: pd.Series) -> pd.DataFrame:
import ipaddress as ip
return cidr.apply(lambda x: int(ip.IPv4Address(x)) )
spark.udf.register('to_address_int', to_address_int)
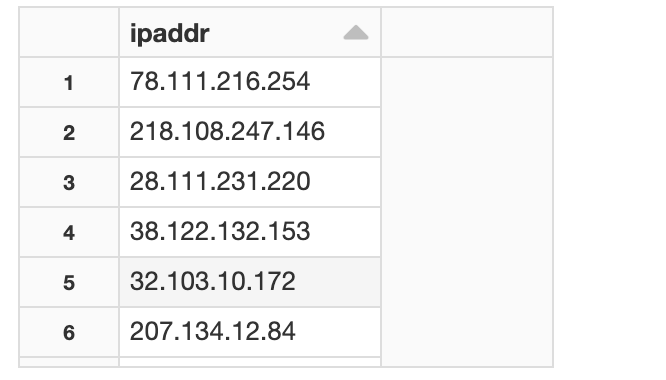
準備ができましたので、ランダムなIPアドレスを使って、その地理情報を調べてみましょう。
# テスト用のランダムIPのDataFrameを準備
ips='''
78.111.216.254
218.108.247.146
28.111.231.220
38.122.132.153
32.103.10.172
207.134.12.84
61.167.199.90
57.131.76.227
31.87.240.21
159.215.114.209
111.5.31.50
98.48.65.209
168.157.24.255
42.161.173.238
23.213.73.177
233.23.214.180
102.100.40.45
246.60.187.154
71.209.81.8
115.250.101.47
'''
ipaddr = ips.splitlines()[1:]
df_ipaddr = spark.createDataFrame([{'ipaddr':ip} for ip in ipaddr])
df_ipaddr.createOrReplaceTempView('ipaddr_list')
display(sql(' select * from ipaddr_list'))
IPアドレスとCIDRのマッピングはRange Joinになるため、range joinの最適化(binSize指定)を実施するとクエリが速くなります(必須ではない)。
%sql
-- [Optional]
-- range joinのため、bin=65536に設定しておく
SET spark.databricks.optimizer.rangeJoin.binSize=65536
1) AS NumberのLook-up
まず初めにAS番号からLookupしてみます。
%sql
SELECT *
FROM ipaddr_list ip
LEFT JOIN geolite2_asn_blocks_ipv4_delta asn
ON to_address_int(ip.ipaddr) BETWEEN to_network_address(asn.network) AND to_broadcast_address(asn.network)
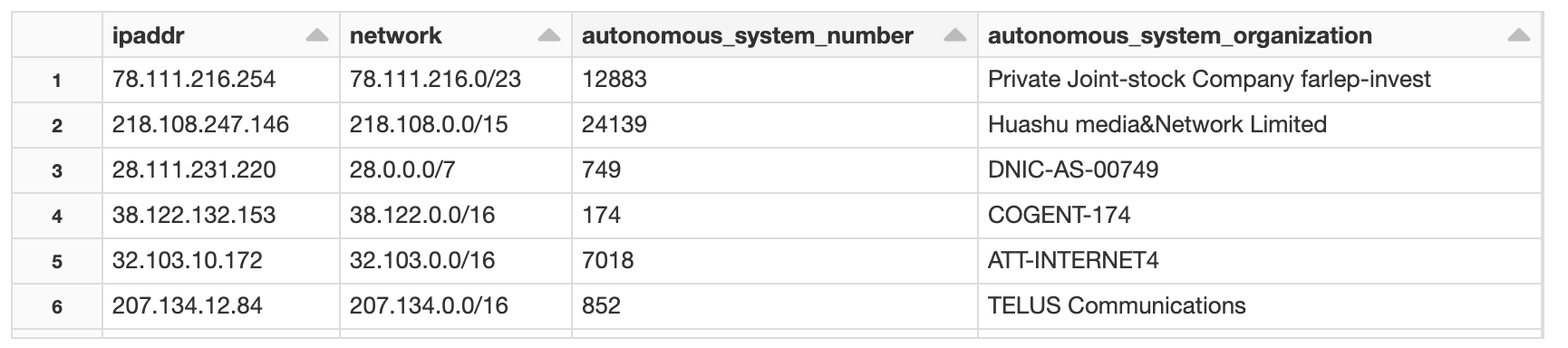
スキーマ
|-- ipaddr: string
|-- network: string
|-- autonomous_system_number: integer
|-- autonomous_system_organization: string
どのネットワーク(ISPなどのAS単位)からのアクセスかが分かります。
例えば、CloudTrailのログ解析などの場合には、そのアクセスがAWS内からだったのか、AWS外部からだったのかなどの判定でも使用できます。
2) CountryのLook-up
国レベルのLookupの例です。国コードなどもありますので、国レベルの地図のマップも可能です。
%sql
SELECT
*
FROM (
SELECT *
FROM ipaddr_list ip
LEFT JOIN geolite2_country_blocks_ipv4_delta c
ON to_address_int(ip.ipaddr) BETWEEN to_network_address(c.network) AND to_broadcast_address(c.network) ) fact
LEFT JOIN geolite2_country_locations_en_delta loc
ON fact.geoname_id = loc.geoname_id

スキーマ
|-- ipaddr: string
|-- network: string
|-- geoname_id: integer
|-- registered_country_geoname_id: integer
|-- represented_country_geoname_id: integer
|-- is_anonymous_proxy: integer
|-- is_satellite_provider: integer
|-- geoname_id: integer
|-- locale_code: string
|-- continent_code: string
|-- continent_name: string
|-- country_iso_code: string
|-- country_name: string
|-- is_in_european_union: integer
is_in_european_unionによって、EUの国の判定などもできます。
3) CityのLook-up
CityレベルのLookupです。一番細かいレベルです。緯度経度情報も載ってきますので、このテーブルを使用して地図へのマップなども可能です。
%sql
SELECT
*
FROM (
SELECT *
FROM ipaddr_list ip
LEFT JOIN geolite2_city_blocks_ipv4_delta c
ON to_address_int(ip.ipaddr) BETWEEN to_network_address(c.network) AND to_broadcast_address(c.network) ) fact
LEFT JOIN geolite2_city_locations_en_delta loc
ON fact.geoname_id = loc.geoname_id

スキーマ
|-- ipaddr: string
|-- network: string
|-- geoname_id: integer
|-- registered_country_geoname_id: integer
|-- represented_country_geoname_id: integer
|-- is_anonymous_proxy: integer
|-- is_satellite_provider: integer
|-- postal_code: string
|-- latitude: double
|-- longitude: double
|-- accuracy_radius: integer
|-- geoname_id: integer
|-- locale_code: string
|-- continent_code: string
|-- continent_name: string
|-- country_iso_code: string
|-- country_name: string
|-- subdivision_1_iso_code: string
|-- subdivision_1_name: string
|-- subdivision_2_iso_code: string
|-- subdivision_2_name: string
|-- city_name: string
|-- metro_code: integer
|-- time_zone: string
|-- is_in_european_union: integer
4) 全部入り (AS Number, Country, CityのLook-up)
IPアドレスから全ての地理データをLookupします。
%sql
-- (CityテーブルがCountryテーブルを内包している)
SELECT
ret_asn.ipaddr,
ret_asn.network as asn_network,
ret_asn.autonomous_system_number,
ret_asn.autonomous_system_organization,
ret_city.network as city_network,
--ret_city.geoname_id,
ret_city.registered_country_geoname_id,
ret_city.represented_country_geoname_id,
ret_city.is_anonymous_proxy,
ret_city.is_satellite_provider,
ret_city.postal_code,
ret_city.latitude,
ret_city.longitude,
ret_city.accuracy_radius,
ret_city.locale_code,
ret_city.continent_code,
ret_city.continent_name,
ret_city.country_iso_code,
ret_city.country_name,
ret_city.subdivision_1_iso_code,
ret_city.subdivision_1_name,
ret_city.subdivision_2_iso_code,
ret_city.subdivision_2_name,
ret_city.city_name,
ret_city.metro_code,
ret_city.time_zone,
ret_city.is_in_european_union
FROM
(
SELECT
*
FROM
ipaddr_list ip
LEFT JOIN geolite2_asn_blocks_ipv4_delta asn ON to_address_int(ip.ipaddr) BETWEEN to_network_address(asn.network)
AND to_broadcast_address(asn.network)
) AS ret_asn
LEFT JOIN (
SELECT
*
FROM
(
SELECT
*
FROM
ipaddr_list ip
LEFT JOIN geolite2_city_blocks_ipv4_delta c ON to_address_int(ip.ipaddr) BETWEEN to_network_address(c.network)
AND to_broadcast_address(c.network)
) fact
LEFT JOIN geolite2_city_locations_en_delta loc ON fact.geoname_id = loc.geoname_id
) AS ret_city ON ret_asn.ipaddr = ret_city.ipaddr

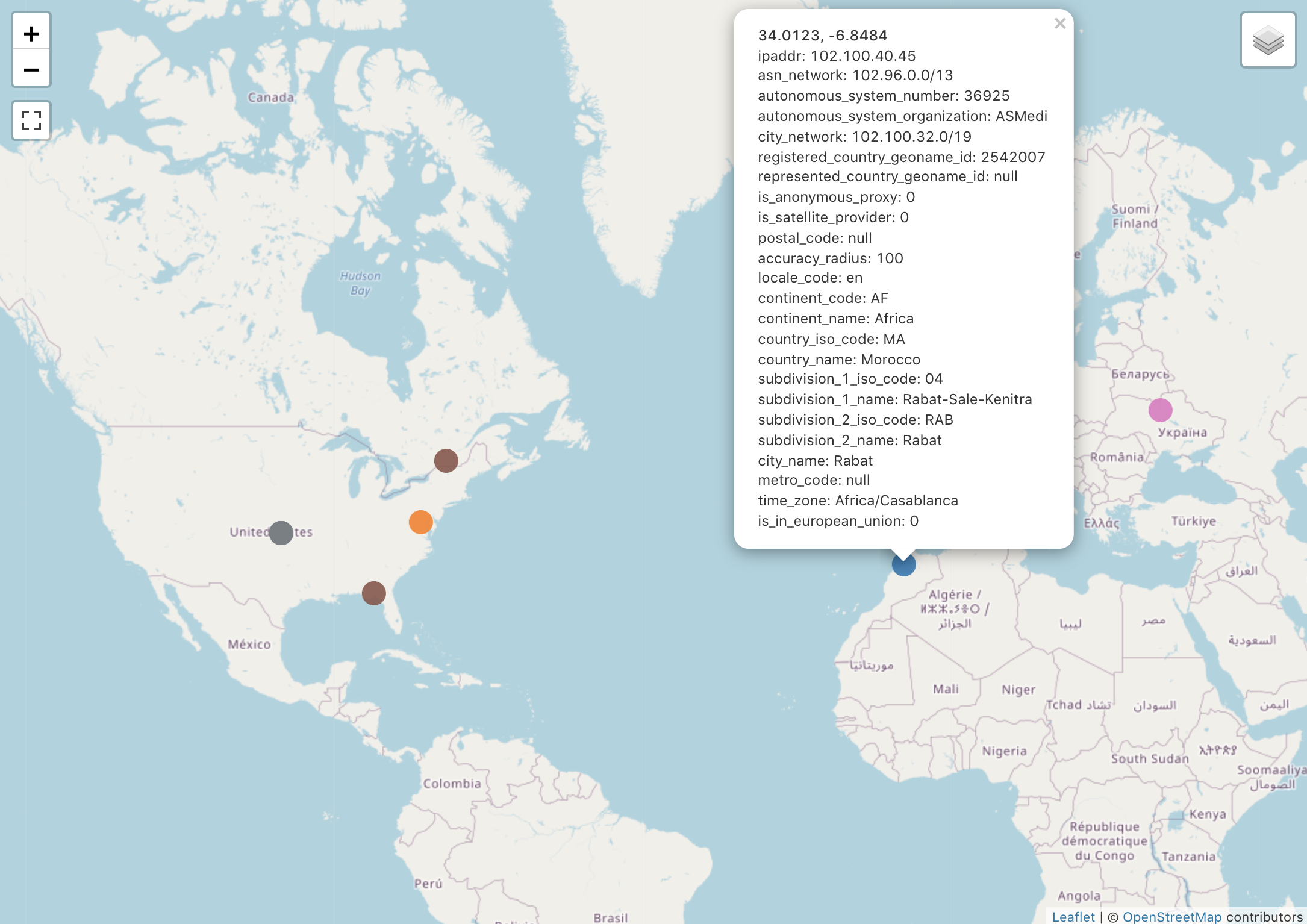
Databricks SQL(Redash)で地図上にマップしてみる
Lookupした情報からRedashの世界地図上にプロットする例です。
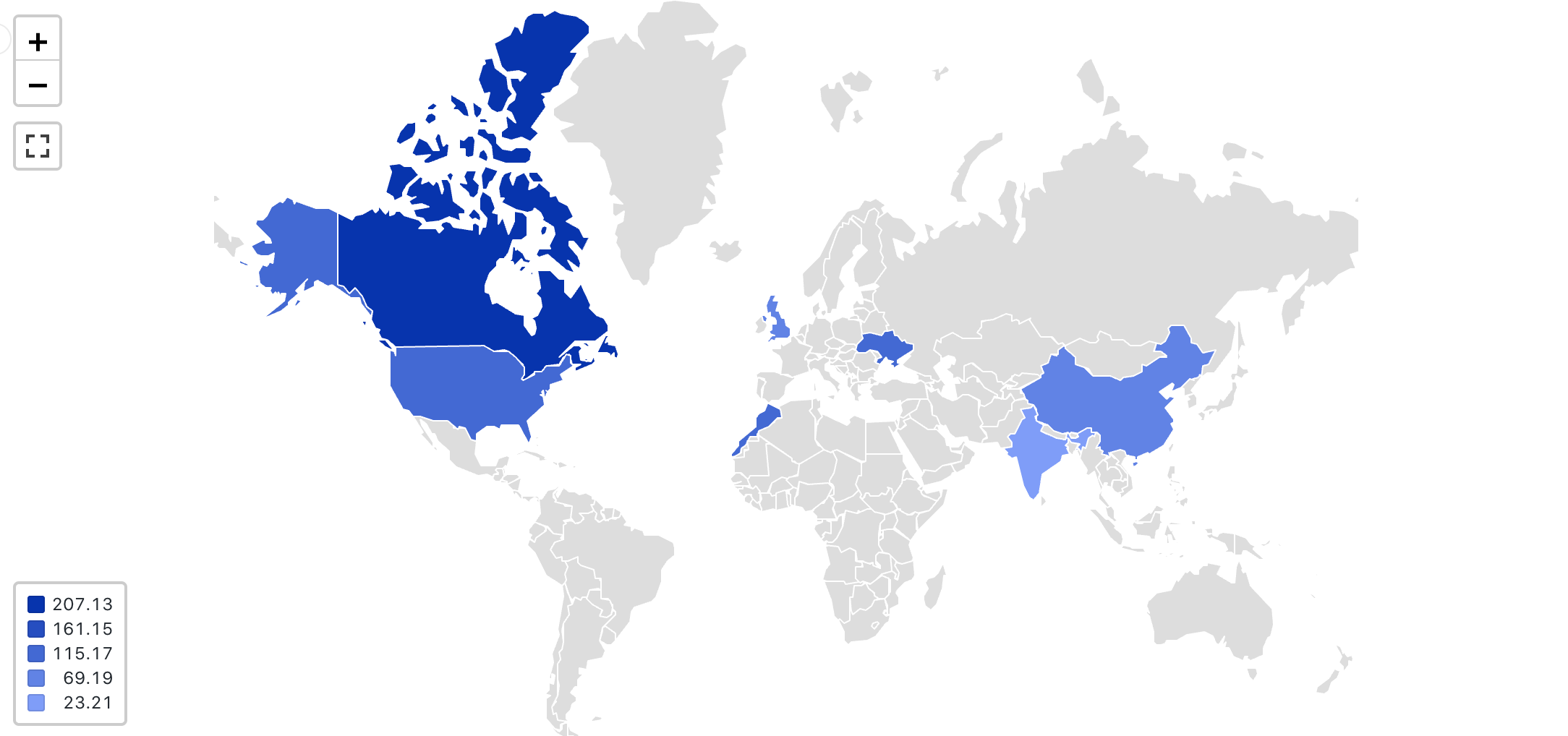
国コード別にプロット
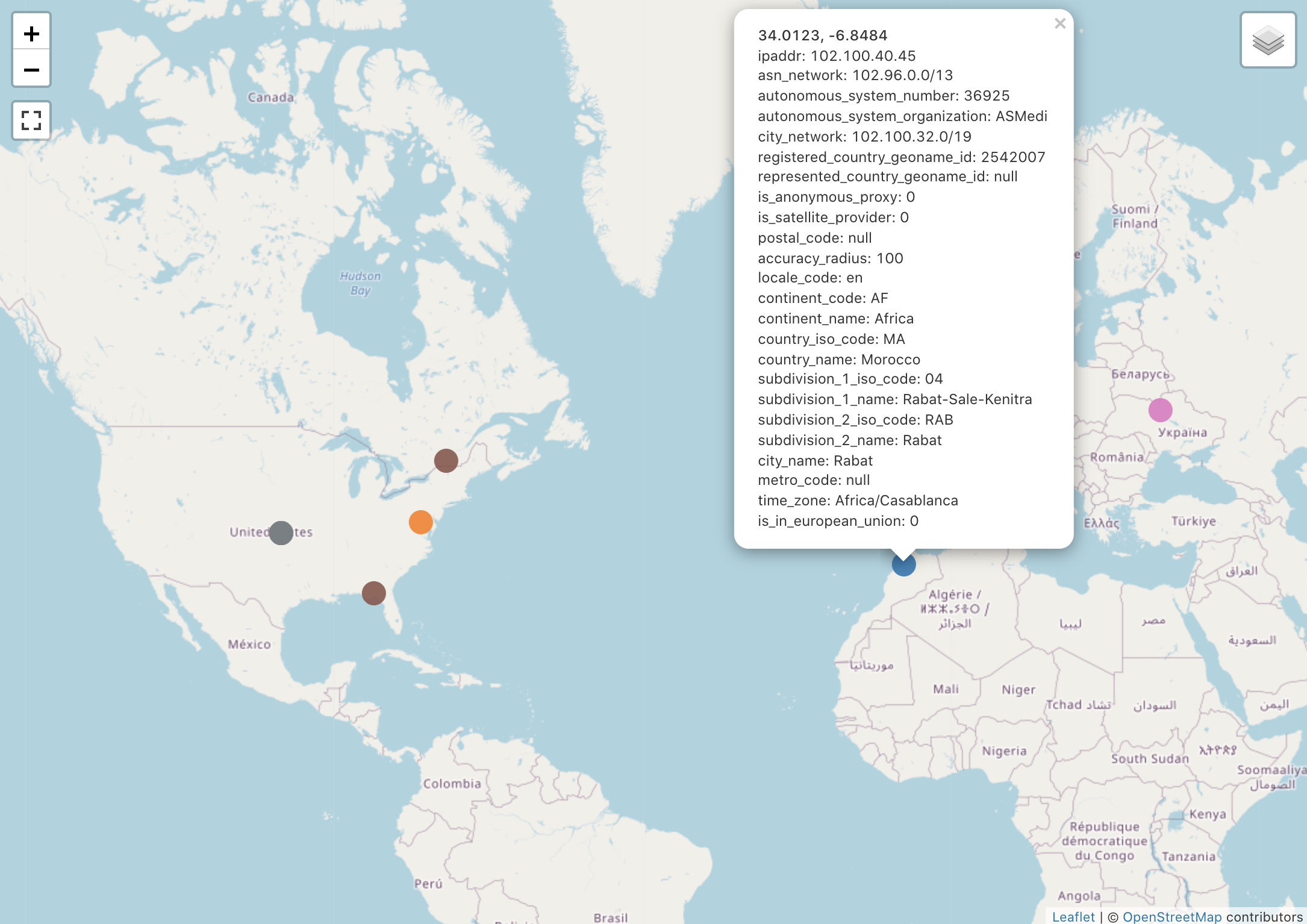
緯度経度でプロット
サンプルNotebookの使い方
サンプルNotebookでは以下のヘッダ部分の変数設定だけで、テーブルが作成が可能です。
# 例) s3://foo-bucket/bar/ 配下をデータ配置場所として使用する場合
S3_BUCKET_NAME = 'foo-bucket'
S3_DIRECTORY = 'bar'
GEOLITE2_LICENSE_KEY = 'GeoLite2のライセンスキーに置き換えてください' #(安全のためSecretを使用してください)
DELTA_DATABASE_NAME = 'test_geolite2'
GeoLite2のCSVダウンロードも含めたコードになっていますので、このNotebookを定期実行するだけで、最新のGeoLocation情報のテーブルに更新できます。
また、Delta Lakeのタイムトラベル機能がありますので、過去のテーブルの状態を復元・参照することも可能です。
まとめ
IP-GeoLocationのDeltaテーブルを常備しておくことでDatabricks上の様々なデータと掛け合わせて、地理情報を利用することができます。サンプルNotebookもすぐに使用できるコードになっていますので、併せて参照ください。