意外と知らない人が多かったため記事にしてみました。
手っ取り早く答えだけ知りたい方は結論まで飛ばしてください。
※Python3とPandasを使用することを前提としています。
背景
とあるデータを元に機械学習を行おうとしたところ
中のデータを見てみると
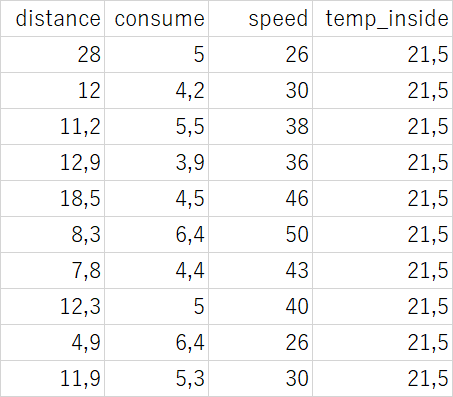
11,2や12,9など見慣れぬ表記が
Google先生に聞いてみると、どうやらドイツなどの一部地域では、小数点を'.'ではなく','で表記しているそうです。
しかし、このまま読み込んでしまうと
df = pd.read_csv("ファイルのパス")
print(type(df['distance'][0]))
<class 'str'>
このようにfloat型として扱いたいデータがstr型として扱われてしまいます。
ではどうすればこの問題を回避することができるのでしょうか
アイデア1:諦めてExcelで編集
Excel等で元データをいじれば解決しそうですが、このやり方はあまりスマートではありませんね。
また、Jupyter Notebook等でレポートを作成する際にも、元データの編集の履歴が残らないと、運用の際に不具合が起きる可能性がある上、再現性が低くなります。
アイデア2 str.replaceで置換してfloat型に変換
Excelで元データをいじるのがスマートでないなら、Pythonで変換してみましょう。
df['consume']= df['consume'].str.replace(',' , '.').astype(float)
df['temp_inside']= df['temp_inside'].str.replace(',' , '.').astype(float)
df['distance']= df['distance'].str.replace(',' , '.').astype(float)
このように各列に対して','を'.'に置換する処理を行い、float型に変換すると
print(type(df['distance'][0]))
<class 'numpy.float64'>
無事、float型として扱えるようになりました。
しかし、このやり方にも問題点はあります。
今回は対象とする列が少なかったため、一つずつ置換するやり方を行いましたが、これが100列、1万列となればどうでしょうか。
一つずつ変換をすれば確かに問題は解決しますが、ミスの原因になりやすいし、ソースが汚くなってしまいます。
どうにかして、全てを一括で変換する方法はないのでしょうか
アイデア3(おすすめ):読込の時点で小数点を識別する記号を指定
これが今回紹介したかった方法です。
pandasでcsvを読み込む際には read_csv という関数を使いますが、この関数には decimal という引数があります。この引数を以下のように指定すると
df = pd.read_csv("ファイルのパス", decimal=',')
たった一行で','を小数点として読み込ませることができます
実際に変換したデータを見てみると
df.head()

このようにすべてのデータに対して小数点が','から'.'に変換されています。
もちろんデータ型を確認しても
print(type(df['distance'][0]))
<class 'numpy.float64'>
float型として扱われています。
結論
df = pd.read_csv("ファイルのパス", decimal=',')
このように read_csv の引数として decimal=',' と指定するだけで小数点を','から'.'に変換されfloat型として扱うことができます。
是非データ分析等を行う際にご活用ください 。
read_csvの細かい仕様等は公式のドキュメントをご参照ください。