本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
セミナー動画は下記になります。
はじめに
2025年に入り、AI エージェントは生成 AI アプリケーションのメインストリームとなり、さまざまな企業がその活用方法を模索し始めました。しかし、その要素技術は未だ成熟途上であり、多様なツールやサービスが乱立している状況です。毎月のように新しい技術や製品が発表され続け、成熟と淘汰の方向性が見えにくい一方で、こうした黎明期にみられる標準化策定の動きも少しずつ現れ始めています。
本記事では、現在主流になっているAI エージェントとその要素技術である、function calling、MCP、マルチエージェントといったキーワードをおさらいしつつ、Oracle がリリースしたエージェント標準化ライブラリ Open Agent Specification(Agent Spec) の概要とサンプルコードをご紹介します。
AIエージェント
AIエージェントとはユーザーの指示に基づいて、「どのような処理を、どのような順序で実行するか」を自ら計画し、そして実際に実行し、その結果を返す自律的なプログラムです。
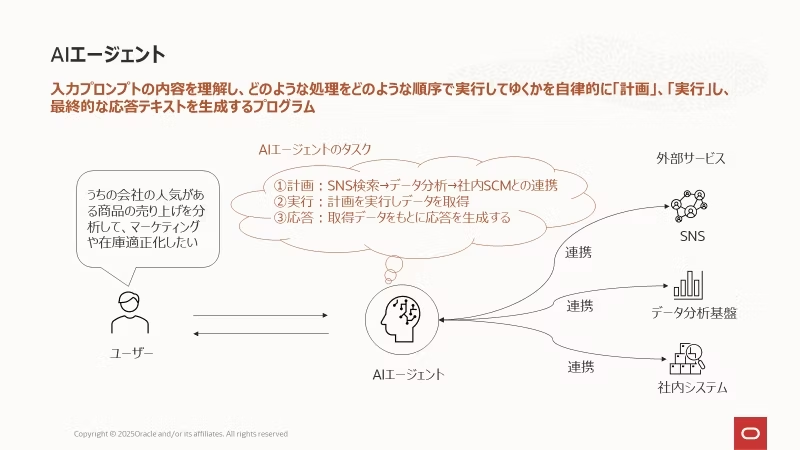
たとえば「自社の人気商品の売上を分析して、マーケティング施策や在庫の最適化を行いたい」とAIに話しかけると、AIが自律的にSNSで人気商品を調査し、その結果を分析、さらに社内のSCMと連携して在庫の過不足を調整してくれる――そんなイメージです。
そして、この 「連携」 を実現する方法がFunction CallingやMCPと呼ばれる技術です。
※AIエージェントについては下記に詳細記事を作成していますので併せてご参照ください。
MCP、Function Calling
MCPやFunction CallingによってAIエージェントは外部のサービスから必要な情報を得たり、外部のシステムを操作したりすることができるようになります。その役割から、MCP、Function Callingを総称して 「ツール」 と呼ばれています。
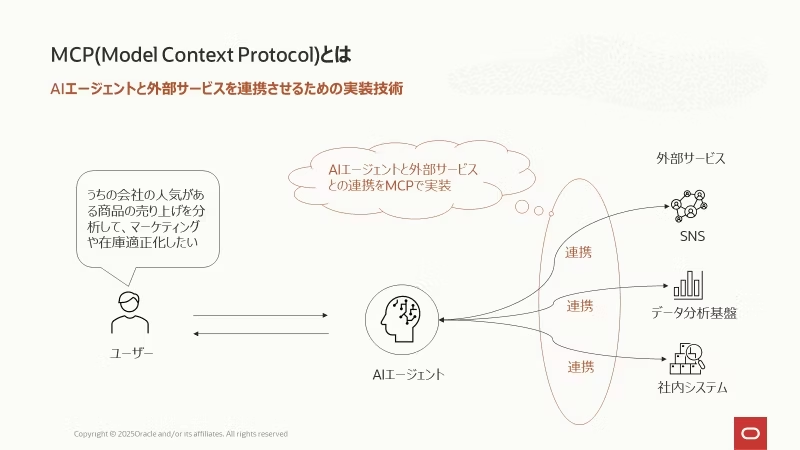
ChatGPTやGeminiなど出来上がったサービスのみを利用している方には想像しにくいかもしれませんが、LLM単体ではウェブ検索を実行したり、SNSを検索したりということはできません。
LLMは過去のデータを学習した機械学習の予測モデルのため現在のデータ(リアルタイムのデータ)に関する応答はできません。 LLM単体では今何時なのかですら答えることはできないんです。
現在のバージョンのChatGPTやGeminiなどがリアルタイムにウェブ検索を実行してくれるのは、LLM以外にそのようなプログラムが追加で実装されているからです。
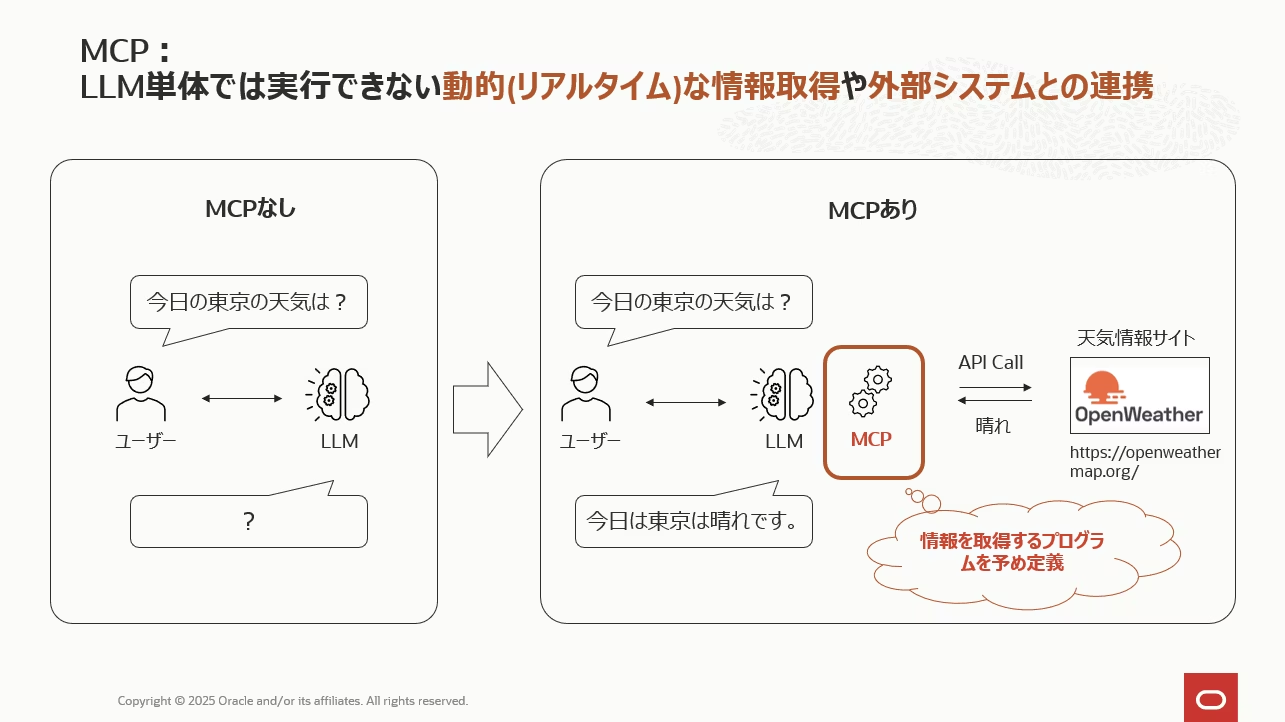
例えば上図のように、今日の天気予報というリアルタイムの情報を含んだテキストを生成したい場合、OpenWeatherなど天気情報を提供しているサービスに都度アクセスし、天気情報を取得する実装が必要になります。(上図の赤枠の部分)このように、LLMと「LLMの外の世界」を連携させるプログラムを開発できる仕組みがMCPやFunction Callingです。
※MCPについては下記に詳細記事を作成していますので併せてご参照ください。
マルチエージェント
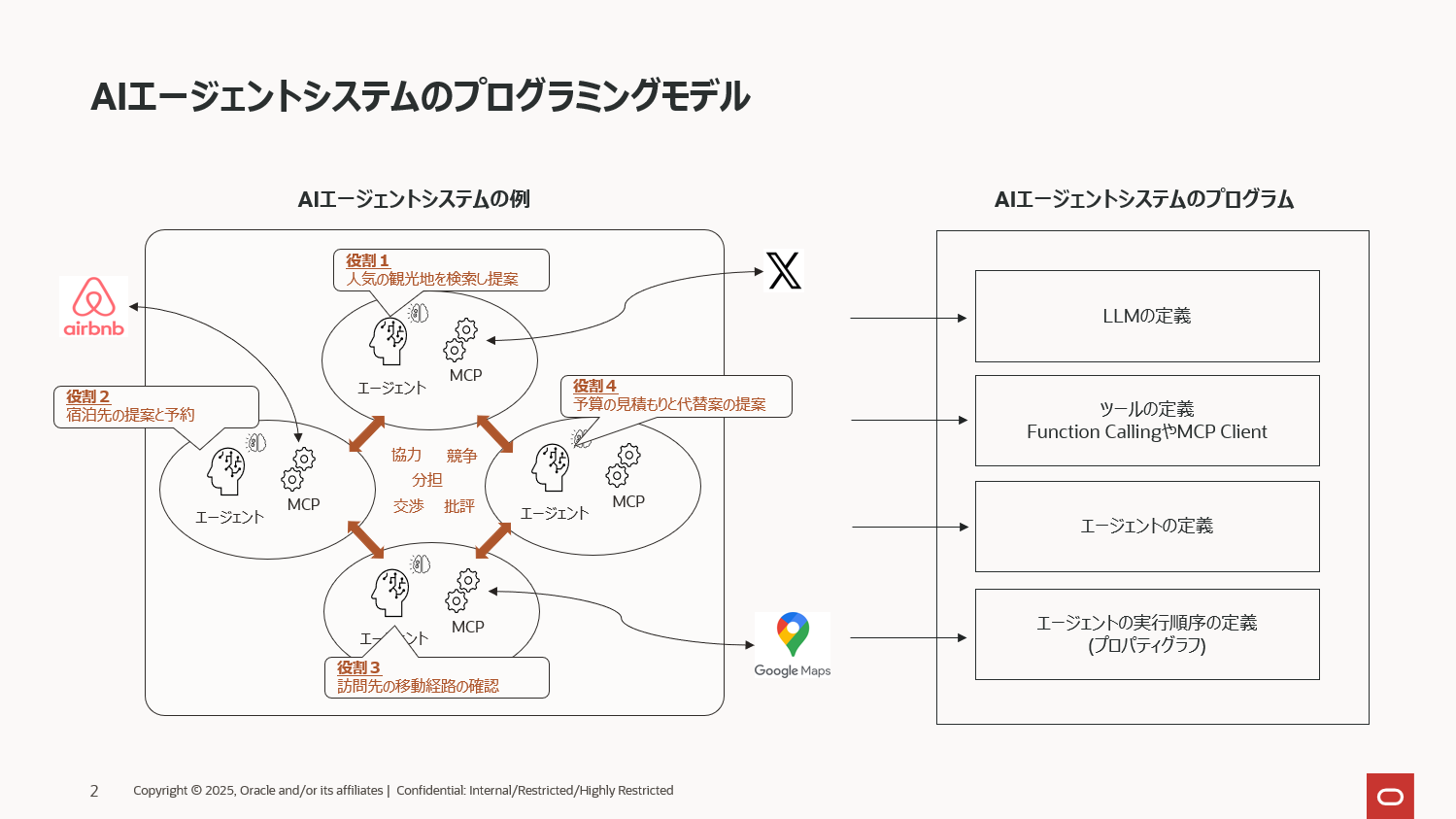
AIエージェントに複雑な処理を実行させる場合、単一エージェントでの対応には限界があります。そのため、処理を役割ごとに分担し、複数のエージェントが協調しながらタスクを進めるマルチエージェント構成が現在の主流となっています。 マルチエージェントでは、エージェント同士がそれぞれの専門性を活かして段階的に処理を行うことで、単一エージェントでは困難な高度なワークフローを実現できます。
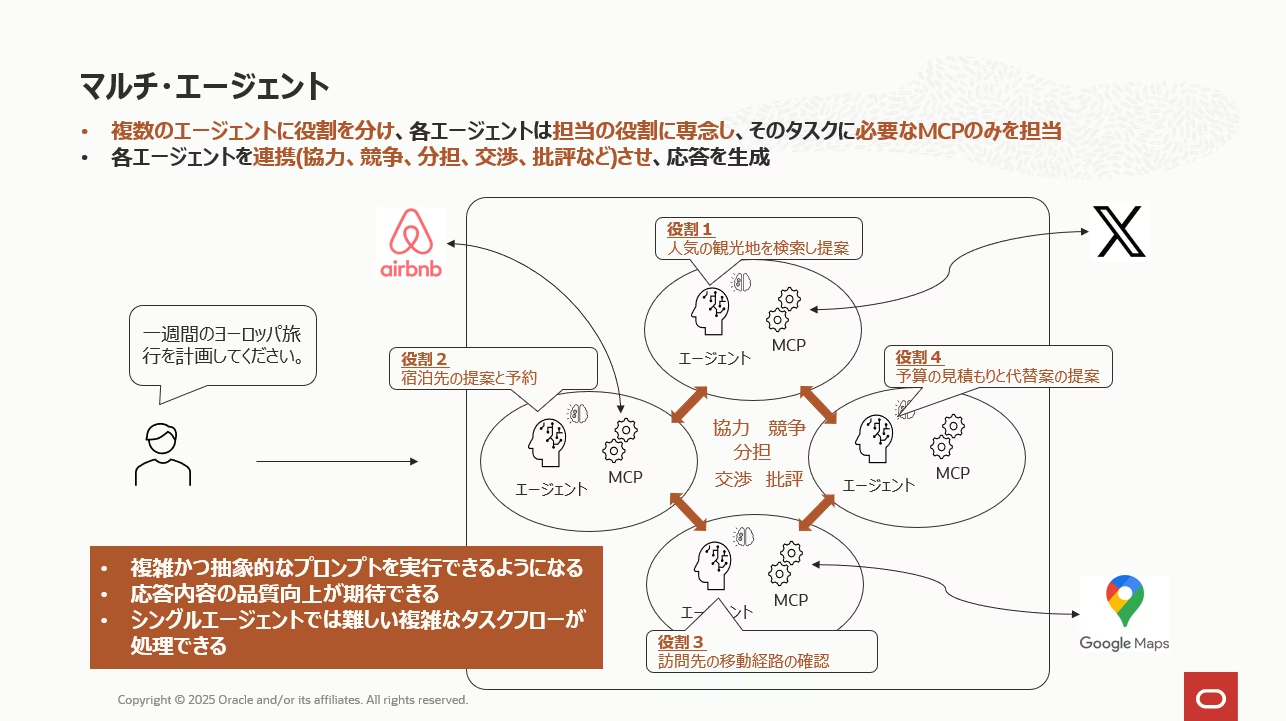
例えば、旅行計画を提案してくれるAIエージェントを開発する場合、上図のように4つのエージェントにそれぞれの専門的な役割を与え、それらを連携して処理するイメージです。
- エージェント1の役割 :「Xで人気の観光地を検索して提案する」
- エージェント2の役割 :「訪問する観光地周辺の宿泊先をAirbnbで検索し提案する」
- エージェント3の役割 :「訪問先への移動経路をGoogleマップで検索し提案する」
- エージェント4の役割 :「全体の予算の見積もりと代替案を提案」
複数のエージェントをどのように連携させ、どんな順序で処理を実行させるか——その振る舞いを設計する際に広く利用される概念がグラフデータモデルです。 グラフは現実世界に存在するあらゆる「関係性」を構造として表現し、分析するためのデータモデルであり、その中でもプロパティグラフと呼ばれるモデルは AI エージェント設計との相性が非常に良いことで知られています。
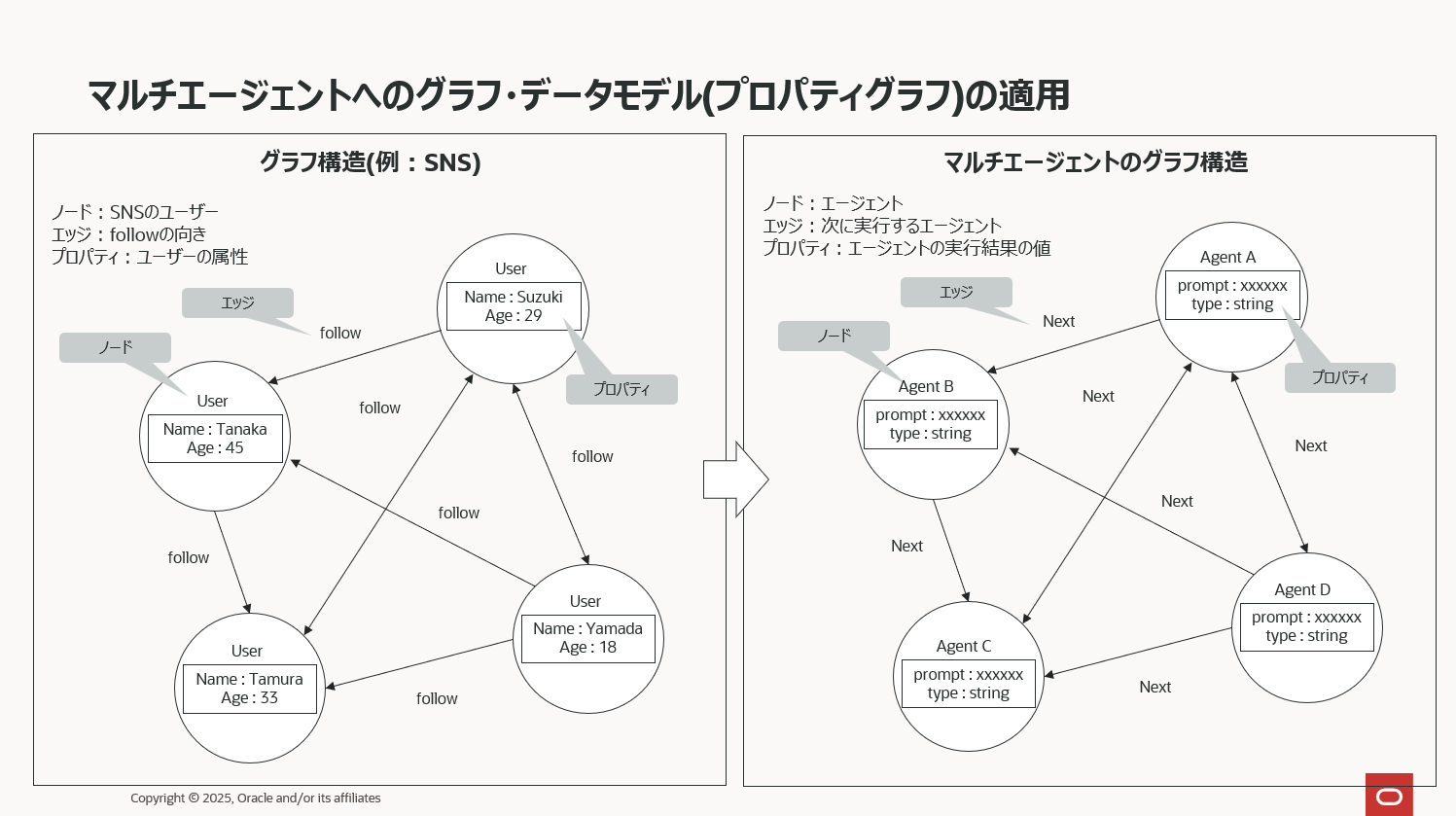
プロパティグラフは、ノード(Node)、エッジ(Edge)、プロパティ(Property)という 3 つの要素で構成されます。 例えばノードにSNSのアカウントユーザーを定義した場合、エッジは人とユーザー同士の関係性、ということでフォローしている、されているという情報を定義することになります。そしてプロパティはアカウントユーザーの名前と年齢を定義する、という感じです。
このプロパティグラフをマルチエージェント構成に適用すると、ノードには各エージェント、エッジにはエージェント間の実行順序や依存関係、そして プロパティには処理に必要なコンテキスト情報やパラメータ を定義する形になります。これにより、複雑なタスクフローでも関係性を明確に可視化しながら、エージェント同士の協調動作を精密に制御できるようになります。
AIエージェント開発にあたっては、これらの要素技術をベースにコードを実装することになります。
AIエージェントの基本的なコードの流れ
AI エージェントの実装には、ある程度共通した 「基本の流れ」 が存在します。 上図に示したパターンは、その典型的な構造を整理したものです。難解なものではなく、これまで解説してきたエージェントの要素技術を一つずつ定義していくだけで構築できます。たとえば、図の左側にあるような AI エージェントシステムを構築する場合、右側に列挙されている要素技術を順に定義してゆくことで自然と全体像が形になります。
-
LLMの定義
通常は 1つの LLM を複数のエージェントに関連付けますが、役割ごとに異なるモデルを割り当てることも可能です。いずれも定型的なコードで簡単に記述できます。また、クラウドの LLM ではなくローカル LLM を使用したい場合でも、GPU があれば vLLM や Ollama などで手軽に環境を整えられます。 -
ツールの定義
各エージェントの役割に沿った、ツール(Function CallingやMCP)を定義します。処理内容によりますが、AIエージェント開発の中では比較的工数がかかるパートです。MCPの場合、エージェント側に定義するのはMCP Clientとなり、MCP Serverを別途開発する必要があります。ベンダーから提供されているMCPサーバーを利用する場合、この開発は不要です。 -
エージェントの定義
定義済みの LLM とツールを組み合わせ、それぞれの役割を担うエージェントを順に作っていきます。この部分も基本的には定型コードです。ただし、複雑なマルチエージェント構成や、多数のツールを連携させるような高度なシステムでは、システムプロンプトや挙動のチューニングが必要になるため、動作確認に一定の工数を要することがあります。 -
エージェントの実行順序の定義
単純な構成であれば定型的なコードで処理順序を定義できます。しかし、複雑なタスクを実行するマルチエージェントでは、プロパティグラフ形式で詳細なフローを設計する必要があり、このグラフの設計が開発工数のポイントになります。
このように、多くの工程は定型的に記述でき、最小限のコードで AI エージェントを構築できます。これは、AI エージェント開発を支えるさまざまなフレームワークが存在しているからこそ実現できているものです。
現在、クラウドサービス、コーディングベースのライブラリ、さらにはローコードツールに至るまで、多数のベンダーが AI エージェント開発向けのプロダクトを次々とリリースしています。 エージェント構築の民主化が一段と進み、より幅広い開発者が高度な AI システムを扱える時代が到来したと言えるでしょう。
AIエージェント開発のフレームワーク
AIエージェントを開発する際には、クラウドベンダーが提供するサービスか、あるいはオープンソースのツール群を活用するのが一般的です。
クラウドサービスは、AI や LLM の専門知識がなくてもウィザードに沿ってローコードで開発できるなど、導入・実装の敷居が低いことが大きな魅力です。 一方で、細かな挙動を制御したい場合や独自のチューニングを施したい場面では、サービス側にそのための機能や画面が備わっていないケースもあり、自由度という点では制約が生じることがあります。
これに対してオープンソースのツールは、近年ローコード化が進んでいるとはいえ、依然としてコーディングベースのライブラリが主流です。Studio などのローコード開発ツールがバンドルされているライブラリも増えてきていますが、Studio で利用できるのは一部の関数に限られる場合もあり、事実上コーディングベースで開発することになります。
それでも、最先端の機能や革新的なアーキテクチャは依然としてオープンソース発であることが多く、最新技術の取り込みを求めるユーザーには魅力的な選択肢となります。
現在、AIエージェント開発、特にマルチエージェント領域にフォーカスした製品は非常に多様化しており、そのすべてを網羅したり、明確に分類したりすることは簡単ではありません。本記事では、その中でも比較的知名度の高いフレームワークをいくつかピックアップして紹介していきます。
| 名称 | 開発元 | 製品概要 |
|---|---|---|
| LangGraph | LangChain Inc. | LLMフレームワークで著名なLangChainの姉妹ライブラリとなり、マルチエージェントシステムの構築にフォーカスしたOSS。LangChainの幅広いエコシステムとの連携が可能で様々なプロバイダのLLMが利用可能。 |
| Autogen | Microsoft Research | マルチエージェントシステムの構築にフォーカスしたOSSライブラリ。グループチャットなどAIエージェント同士の対話やタスク分担を自動化するためのライブラリが特徴的。OpenAI以外の様々なモデルが利用可能かつ、LangChain、Dockerなどその他のライブラリとの連携も可能。 |
| OpenAI Agents SDK | OpenAI | OpenAI公式のエージェント開発用SDK。function callingやtool呼び出しをシンプルに統合でき、外部APIやデータソースと連携したエージェントアプリケーションを迅速に構築可能。OpenAIのモデル群との親和性が高い。 |
| Agent Development Kit | Google Research | Agent2Agentとの併用により高度なマルチエージェントシステムを構築可能。Googleの生成AIエコシステムやVertex AIとの連携を前提とし、A2Aプロトコルを活用したエージェント協調の実装を支援。 |
| WayFlow | Oracle Lab. | マルチエージェントシステムの構築に必要な機能を全て兼ね備えたライブラリ。同社の標準化ライブラリ Agent Specificationとの併用によりその機能を全て利用できるよう設計されたライブラリ |
| Dify | LangGenius Inc. | ノーコードでAIアプリやエージェントを構築できるプラットフォーム。UIでワークフローを可視化可能。様々なLLMが利用でき、マイナーなLLMのサポートタイミングも比較的早い。ノーコードで LLM ベースのチャットや情報検索アプリを作りたいユーザー向けのツール。 |
| N8N | n8n GmbH | ノーコード自動化ツール。AIモデルやAPI連携を簡単に組み合わせた自動処理ワークフローを作成できる。汎用的な業務の自動化および、SaaSやAPI をつなぎ、あらゆるシステム間でワークフローを制御したい場面で真価を発揮。 |
上述したものはあくまでごく一部に過ぎず、実際にはさまざまなプロダクトが乱立する群雄割拠の状態にあります。このトレンドは今後もしばらく続くと考えられ、短期的には淘汰が進む気配はありません。
それと同時に、AI エージェントを本格的に業務へ導入する企業は今後ますます増えていくことが確実視されており、それは世界中に「仕様が統一されていない独自形式のエージェント」が無数に存在する未来を意味します。
こうした状況下で重要性を増すのが「標準仕様」の存在です。標準仕様の策定は、新規参入を促し、業界全体の技術革新を加速させる重要な基盤となります。仕様が統一されることで開発のハードルが下がり、企業はより付加価値の高い機能開発に集中できます。また、エージェントの標準仕様により、異なる企業が開発したエージェント同士の連携開発もより効率的になることは間違いありません。
IT に限らず多くの業界で標準化が不可欠とされてきたように、AI エージェントの領域でも標準化は市場拡大を後押しし、投資を呼び込み、便利なツールやサービスが生まれる好循環を生み出すことになるでしょう。これはITだけでなく、あらゆる業界の歴史で繰り返されてきた市場の成長パターンです。
標準化のトレンド
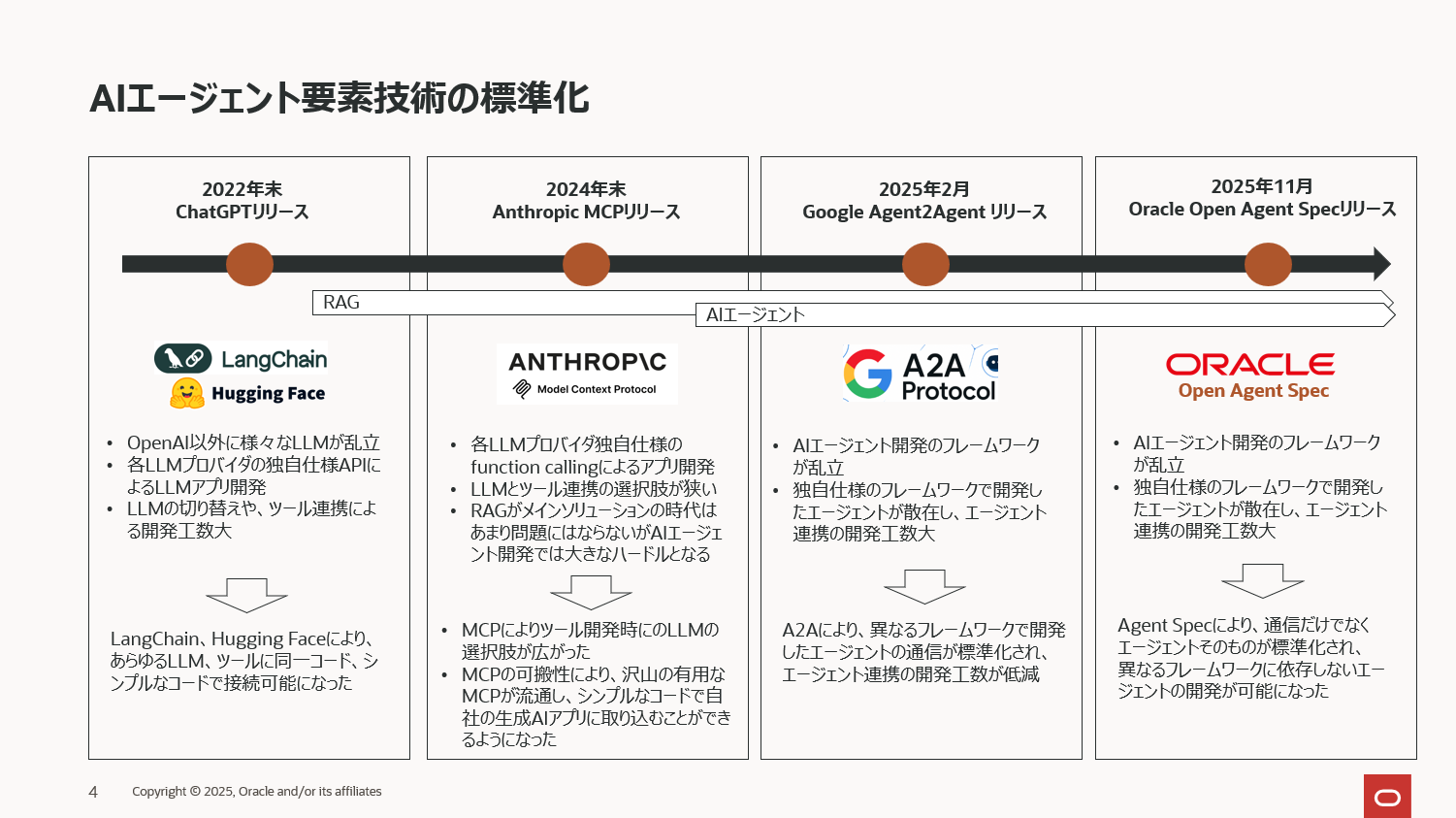
では今現在AIエージェント関連では全く標準仕様がないのか?といわれると、そうでもありません。過去リリースされた主だった標準仕様(もしくはそれに近しい技術)を纏めると下図のようになります。
-
LLM利用の標準化
2022 年末の ChatGPT の登場は、現在の爆発的な AI ブームの起点となり、その中心技術として大規模言語モデル(LLM)が一気に注目を集めました。OpenAIのGPTは市場で一番有名なLLMですが、2022年の時点でマイナーなLLMまで含めると既に50以上のプロバイダーがLLMをリリースしていました。そこから一定の淘汰が進んだとはいえ、新たな LLM が次々とリリースされる状況は今なお続いており、まさに乱立状態と言えます。
この“LLM の多様性”が抱える課題に対し、事実上の標準化レイヤーとして機能したのが LangChain と Hugging Faceです。両者は各 LLM の API 仕様の違いを吸収し、統一的なインターフェースで扱える環境を整備しました。その結果、開発者はモデル選定や API の差異悩まされることなく、LLM を用いたアプリケーションを迅速に構築できるようになりました。LLM 乱立期における「実質的な標準化」として、非常に大きな役割を果たした存在です。 -
ツールの標準化
LLM に外部機能を実行させる仕組みとして、各社が提供してきたfunction calling は長らく “プロバイダーごとの独自仕様” という課題を抱えていました。 しかし 2024 年 11 月、Anthropic が MCP(Model Context Protocol) を公開したことで状況は大きく転換します。MCP によって、LLM が利用するツール呼び出しの仕組みが事実上標準化され、ベンダー差異を気にせず統一的にツールを扱うことが可能になりました。また、この標準化によって、ツールに再利用性と可搬性が生まれ、開発済の便利なツールをgithubなどで公開し、市場に流通させることができうようになりました。そのため現在では数多くの MCP 対応ツールが公開され、開発者は高度な外部機能を簡単に組み込めるようになっています。現状、MCPに代わる更に有効な技術がリリースされる様子はなく、AI エージェントを構成する要素技術の中でも、MCP は最も成功した標準化仕様のひとつといって過言ではありません。 -
エージェントの標準化
2025 年 2 月、Google はエージェント間通信を標準化するプロトコル Agent2Agent(A2A) を発表しました。リリースと同時に各 IT 企業との幅広いアライアンスが公表され、エージェント同士の協調を支える重要な基盤として期待が高まっています。A2A は異なるフレームワークで開発されたエージェント同士を接続するための共通プロトコルであり、今後さらに増えるであろう多様なエージェントの連携において大きな役割を果たします。
そして、2025 年 11 月、Oracle は Open Agent Specification(Agent Spec)をリリースし、標準化の流れに続きます。Agent Spec は MCP のツール呼び出しや、A2Aの通信仕様といった部分的な標準化に留まらず、「エージェント全体の設計・運用」を対象とする包括的な標準仕様です。“フレームワークに依存しないエージェント開発と運用” を掲げ、今後も継続的に拡張されていく見込みです。
※Google A2Aについては過去のセミナーで取り扱いましたので是非下記記事を併せてご参照ください。
現在、マルチエージェント開発のライブラリは多数あるものの、標準仕様が存在しないため、当然全てが独自仕様となっており、将来的にフレームワーク間でのエージェントの移植、コンポーネントの再利用、そしてフレームワーク間でのソリューションの拡張が困難になる可能性があります。
これらの課題に対処するために、Oracle は AIエージェント開発のエコシステムに移植性、再利用性、拡張性をもたらすオープンで標準化されたライブラリ Open Agent Specificationをリリースしました。
国内にはまだあまり情報がありませんが、現在Cisco社が主導する「AGNTCY(エージェンシー)」 と呼ばれるプロジェクトがあります。このプロジェクトはAIエージェント同士が安全かつ相互運用的に連携できるようにするためのオープンソース基盤を策定する目的で進行しており、エージェントのアイデンティティ管理、ディスカバリ(エージェントのDNSのような機能)、暗号化メッセージング(SLIM)、可観測性といった共通インフラを提供し、異なるフレームワークや組織間でもエージェントが協調動作できる「Internet of Agents」を目指しています。コードはGitHubで公開され、Linux Foundation配下で開発が進められています。このプロジェクトは2025年3月に発表され、Dell Technologies、Google Cloud、Oracle、Red Hatなど、75社を超える多数の業界大手企業から支援を受ける形で進行中です。そして、OracleOpen Agent Specificationは今後リリースされるであろう同プロジェクト関連のOracleのソフトウェアリリースの第一弾となります。
AGNTCYの詳細については下記本家のサイトをご参照ください。
https://outshift.cisco.com/blog/building-the-internet-of-agents-introducing-the-agntcy
Orale Open Agent Specification(Agent Spec) 概要
Agent Specは、フレームワークに依存しない宣言型仕様であり、AIエージェントとワークフローをあらゆる互換性のあるフレームワーク間で移植可能、再利用可能、実行可能にするように設計されています。 機械学習モデルにおけるOpen Neural Network Exchange(ONNX)などの表現の成功に着想を得た Agent Specは、AIエージェント開発のエコシステムに相互運用性と最適化をもたらすことを目指し、2025年10月にOracle Labよりリリースされました。
AIエージェント開発に必要とされる全ての機能を装備
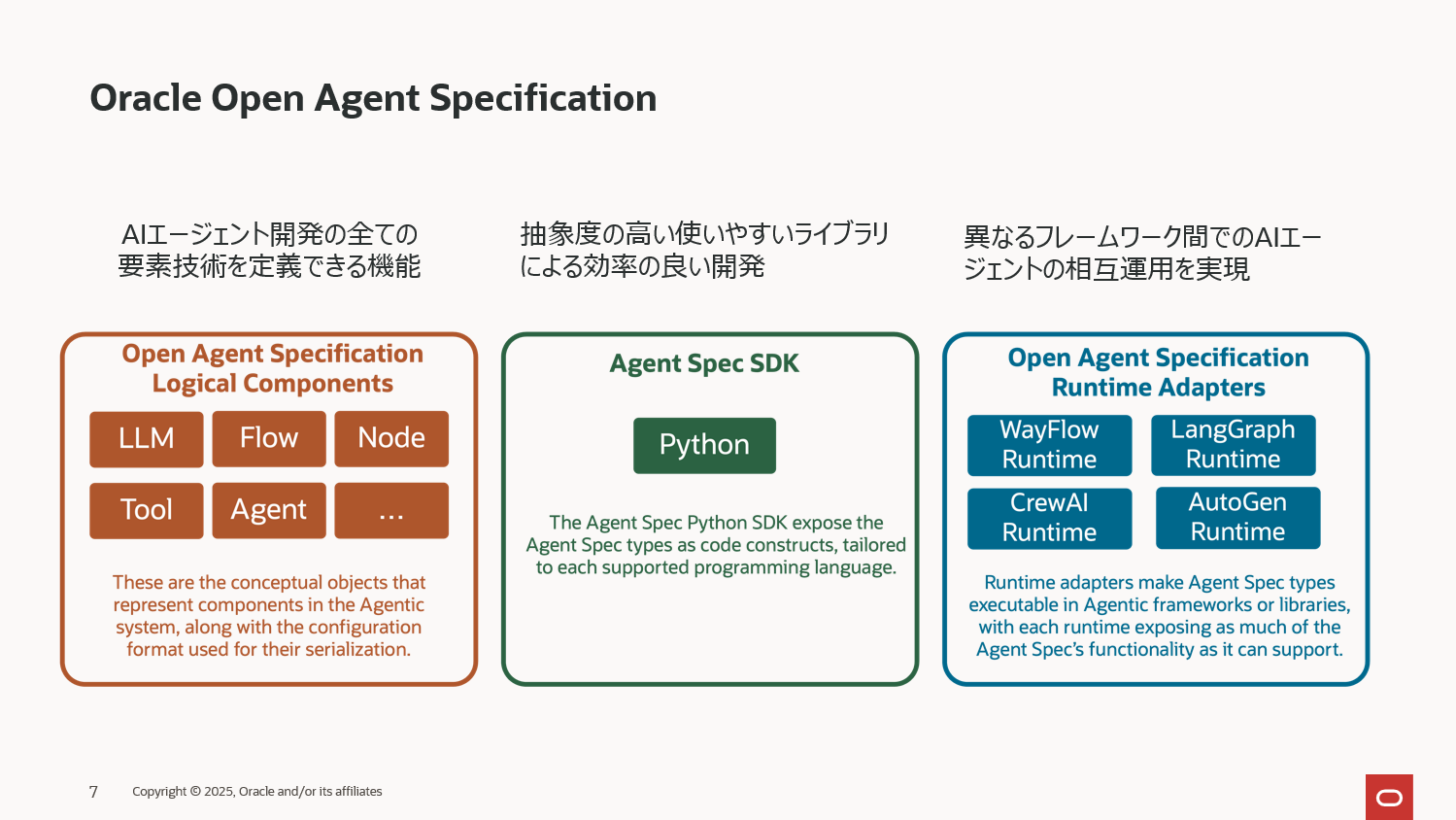
Agent Spec は、単一エージェントから複雑なマルチエージェント構成まで、一貫した方法で定義できる包括的なエージェント開発ライブラリです。Google の A2A が MCP を内包する形で設計されたのと同様に、Agent Spec は A2A と MCP の両方を包括するアーキテクチャ を採用しており、AIエージェントシステムの開発に必要な要素技術を簡素化されたコードで定義できる包括的なクラスを提供します。
A2A レイヤー自体は高度に抽象化されており、開発者は細かな通信仕様を意識する必要なくマルチエージェント環境を自然に定義できます。また、MCP クライアントの構築も簡潔で、必要なツールを最小限のコードで組み込めるクラスが標準提供されています。
さらに、Agent Spec は幅広い LLM をシームレスに扱えます。OCI Generative AI のLLMをはじめ、OpenAI 互換 API を持つ各種モデル、さらには vLLM、Ollama といったローカル LLM までサポートします。
そして、付属のグラフ定義ライブラリ Flow により、構築できるエージェントの幅は大きく広がります。単純なマルチエージェントはもちろん、条件分岐を含む複雑なワークフロー型のマルチエージェント、さらにはオーケストレーションタイプの高度なエージェント構成まで、 すべてをシンプルかつ一貫した形式で表現できます。
Agent Spec は、エージェント開発の煩雑さを取り払い、標準化された基盤の上で柔軟なエージェントシステムを構築できる次世代のフレームワークを目指しています。
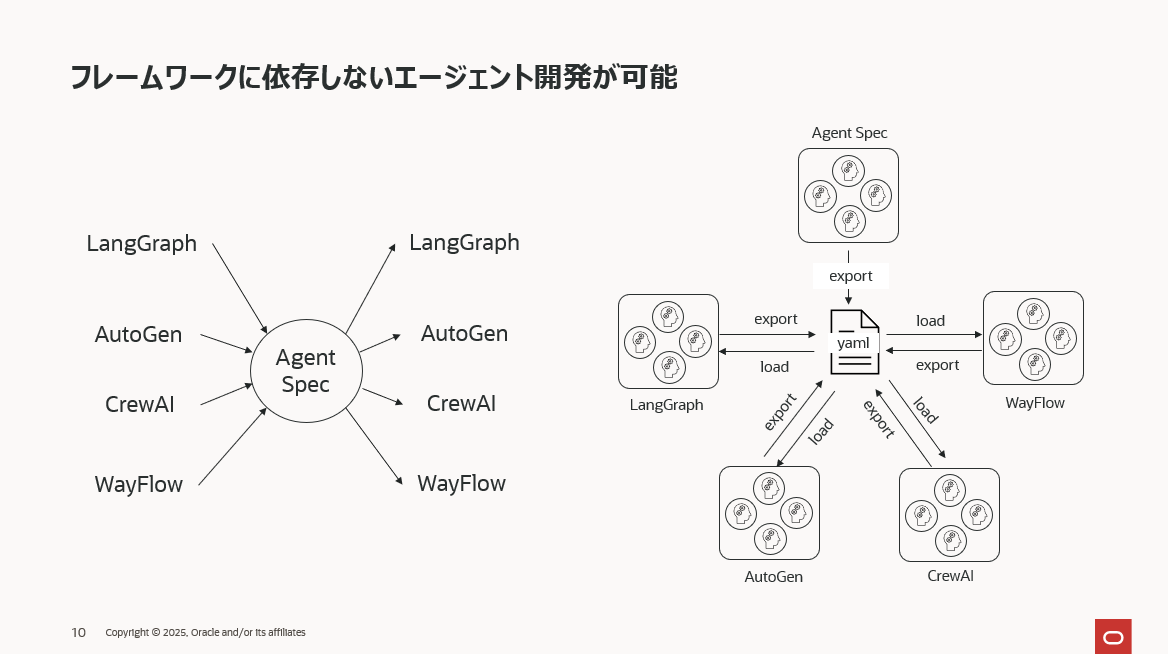
フレームワークに依存しないエージェント開発
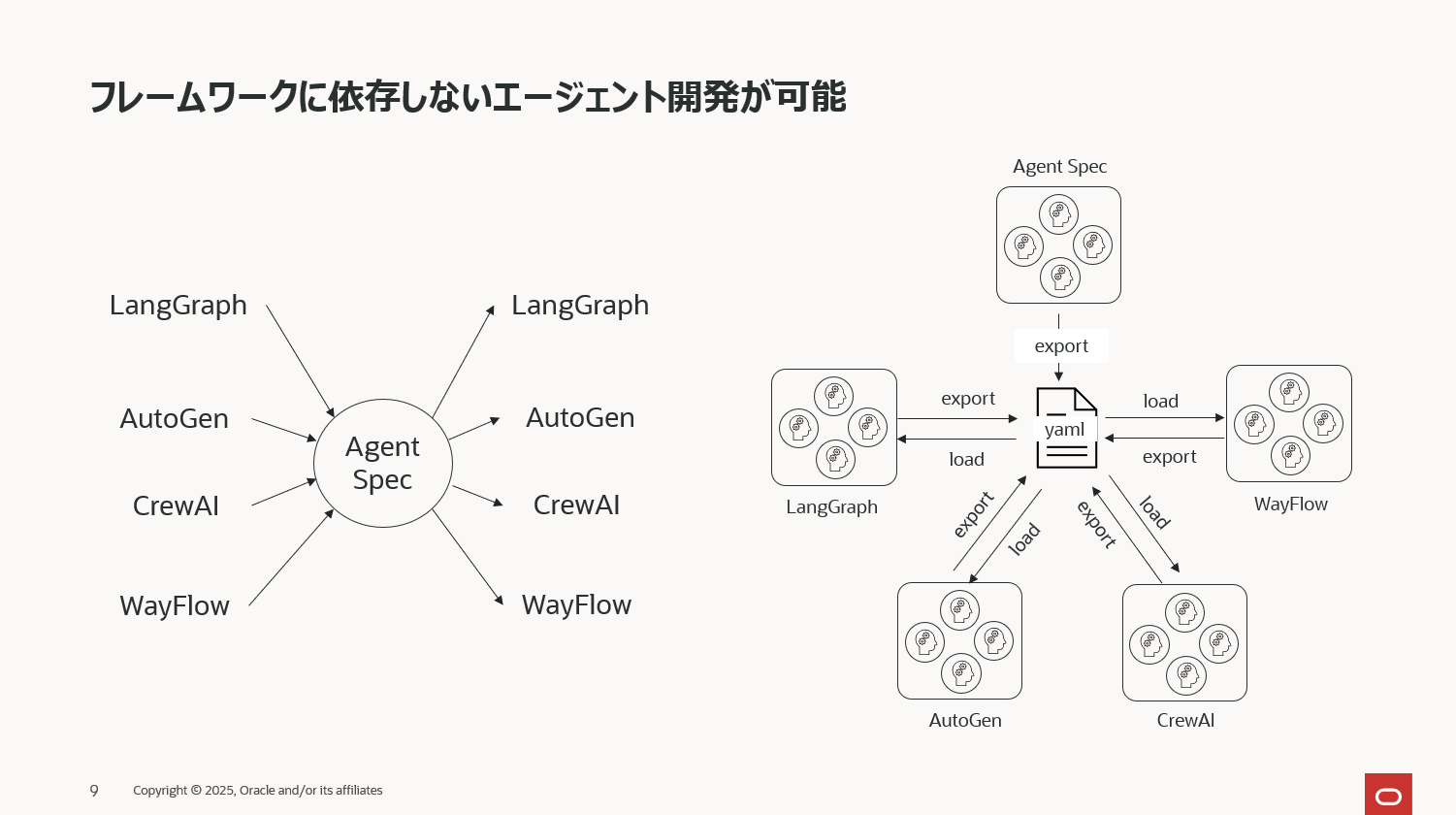
Agent Spec は、AI エージェントを宣言的に記述する、フレームワーク非依存の仕様として設計されています。Agent Spec が担うのは、エージェントとその処理フローを定義するところまでで、エージェントの実行はフレームワークが担当します。この 「定義」と「実行」の分離 によって、エージェント開発は特定フレームワークへの依存から解放され、Agent Specがサポートするどのフレームワークでも同じエージェントを動かせるという柔軟性を獲得します。
現時点で Agent Spec を実行できるフレームワークは LangGraph、AutoGen、CrewAI、WayFlow の 4 つが公式サポートされています。今後はさらに対応フレームワークが増える予定で、エージェント開発のポータビリティはより一層高まっていくでしょう。
この仕様が意味するところは、Agent Spec で定義したエージェントは、上記いずれのフレームワーク上でも動作可能であるという点です。さらに、Agent Spec を介することでフレームワーク間移植も容易になり、たとえば「LangGraph で構築したエージェントを AutoGen 環境へそのまま移す」といったことも簡単に行えるようになります。
サンプルコード
ここからAgent Specを中心に下記5つのサンプル実装をご紹介します。
- Agent Specでシンプルなエージェントの定義から実行まで
- ツール(MCP)を持ったエージェントの定義と実行
- Agent SpecのAIエージェントを様々なフレームワークで実行
- Agent Specのマルチエージェントの定義と実行
- AutoGenのマルチエージェントにAgent Specのエージェントを追加し拡張
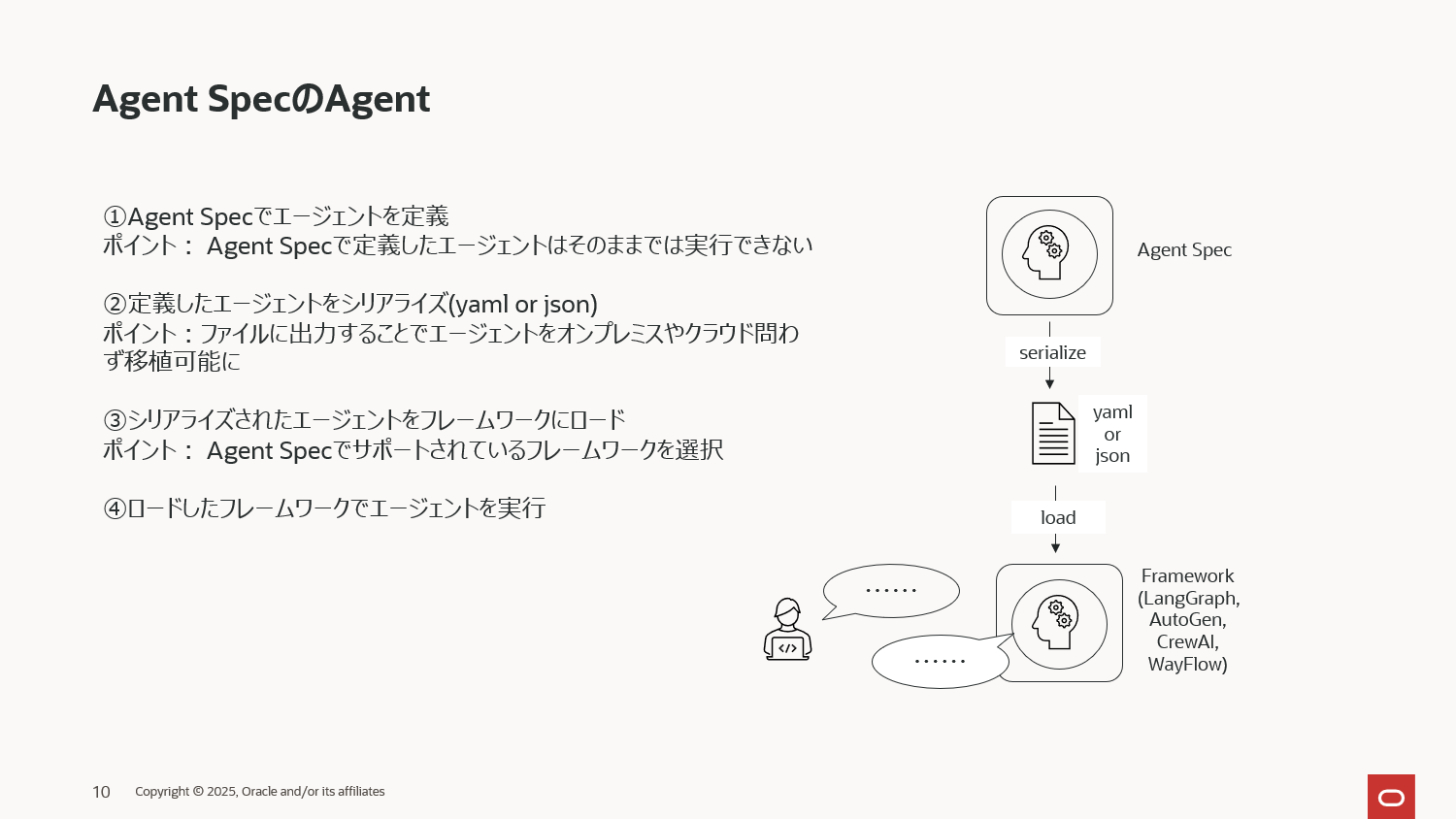
①Agent Specでシンプルなエージェントの定義から実行まで
最もシンプルなエージェントを定義してみます。Agent Specでシンプルなエージェントを定義し、定義したエージェントをWayFlowで実行する非常にシンプルなコードです。
まずはLLMの定義です。このサンプルではOCI Generative AI ServiceのLLMを使ってみます。
from pyagentspec.llms import OciGenAiConfig
from pyagentspec.llms.ociclientconfig import OciClientConfigWithApiKey
client_config = OciClientConfigWithApiKey(
name="Oci Client Config",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
auth_profile="DEFAULT",
auth_file_location="~/.oci/config"
)
llm_config = OciGenAiConfig(
name="Oci Client Config",
model_id="cohere.command-a-03-2025",
compartment_id="<compartment-id>",
client_config=client_config,
)
次にAgent Specでエージェントを定義します。
from pyagentspec.agent import Agent
agent = Agent(
name="Helpful agent",
llm_config=llm_config,
system_prompt="""
あなたは優秀なアシスタントです。事実をもとにユーザーの質問に回答してください。
仮に憶測の情報をもとに回答する場合は必ずその旨を述べて回答してください。
""",
)
Agent Specでのエージェントの定義はこれで完了です。
そしてここからがAgent Specの真骨頂です。
このAgentを下記コードでシリアライズします。
from pyagentspec.serialization import AgentSpecSerializer
serialized_assistant = AgentSpecSerializer().to_json(agent)
print(serialized_assistant)
# シリアライズしたエージェントをjsonファイルでローカルに保存する場合は下記コードを実行
# with open("agentspec_config.json", 'w') as f:
# f.write(serialized_assistant)
シリアライズしたjsonの内容は以下の通り。ここまでのエージェントのコードがjsonの宣言に変換されていることがわかります。
{
"component_type": "Agent",
"id": "8d69e786-170b-433f-b316-629abcfa8554",
"name": "Helpful agent",
"description": null,
"metadata": {},
"inputs": [],
"outputs": [],
"llm_config": {
"component_type": "OciGenAiConfig",
"id": "b7b255bb-7aeb-4077-9690-e26f86e0ba50",
"name": "Oci Client Config",
"description": null,
"metadata": {},
"default_generation_parameters": null,
"model_id": "cohere.command-a-03-2025",
"compartment_id": "<compartment_id>",
"serving_mode": "ON_DEMAND",
"provider": null,
"client_config": {
"component_type": "OciClientConfigWithApiKey",
"id": "aa7bb3fa-1678-4a38-9041-55accf920731",
"name": "Oci Client Config",
"description": null,
"metadata": {},
"service_endpoint": "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
"auth_type": "API_KEY",
"auth_profile": "DEFAULT",
"auth_file_location": "~/.oci/config"
}
},
"system_prompt": "あなたは優秀なアシスタントです。事実をもとにユーザーの質問に回答してください。仮に記憶の情報をもとに回答する場合は必ずその旨を述べて回答してください。",
"tools": [],
"agentspec_version": "25.4.1"
}
そして、次にこのエージェントを実行します。これまでにも説明してきた通り、Agent Specはエージェントを定義するところまでを担当し、実行自体はフレームワークのライブラリが担当します。現在 Agent Specでサポートしているフレームワークは下記4つです。
- LangGraph
- AutoGen
- CrewAI
- WayFlow
Agent Specは「フレームワークに依存しないエージェント開発」を目指すライブラリですから、今後もこのサポートされるフレームワークは増えていくでしょう。今回は WayFlow を使って Agent Specのエージェントを動作させてみます。
動作させるために、先ほどシリアライズしたjsonをWayFlowにAgentSpecLoaderでロードするという処理が必要となります。(サポートされているフレームワーク毎にこのクラスが用意されています。
from wayflowcore.agentspec import AgentSpecLoader
loader = AgentSpecLoader()
wayflow_assistant = loader.load_json(serialized_assistant)
print(wayflow_assistant)
# シリアライズしたjsonファイルから読み込む場合は下記コードを実行
# with open("agentspec_config.json") as f:
# wayflow_assistant = f.read()
WayFlowに変換されたエージェントの定義が下記です。
出力結果(非常に長いので折り畳みます)
Agent(
llm=<wayflowcore.models.ocigenaimodel.OCIGenAIModel object at 0x7f102cde7d70>,
tools=[],
flows=[],
agents=[],
custom_instruction=(
'あなたは優秀なアシスタントです。事実をもとにユーザーの質問に回答してください。'
'仮に憶測の情報をもとに回答する場合は必ずその旨を述べて回答してください。'
),
max_iterations=10,
context_providers=[],
can_finish_conversation=False,
initial_message='Hi! How can I help you?',
caller_input_mode=<CallerInputMode.ALWAYS: 'always'>,
agent_template=PromptTemplate(
id='34ed6e39-7870-4f44-b8a4-d6928109d461',
__metadata_info__={},
name='',
description=None,
messages=[
Message(
id='a5e0f323-7ed9-40d3-860d-e343bccc2e78',
__metadata_info__={},
role='system',
contents=[
TextContent(
content='{% if custom_instruction %}{{custom_instruction}}{% endif %}'
)
],
tool_requests=None,
tool_result=None,
display_only=False,
sender=None,
recipients=set()
),
Message(
id='9d2db367-f92e-473a-9218-b2f3eda837b0',
__metadata_info__={},
role='system',
contents=[
TextContent(content='$$__CHAT_HISTORY_PLACEHOLDER__$$')
],
tool_requests=None,
tool_result=None,
display_only=False,
sender=None,
recipients=set()
),
Message(
id='3eb516df-54eb-4d86-ac5e-a15cc6f97ecf',
__metadata_info__={},
role='system',
contents=[
TextContent(
content=(
'{% if __PLAN__ %}The current plan you should follow is the following: \n'
'{{__PLAN__}}{% endif %}'
)
)
],
tool_requests=None,
tool_result=None,
display_only=False,
sender=None,
recipients=set()
)
],
output_parser=None,
input_descriptors=[
StringProperty(
name='custom_instruction',
description='"custom_instruction" input variable for the template',
default_value='',
enum=None
),
StringProperty(
name='__PLAN__',
description='"__PLAN__" input variable for the template',
default_value='',
enum=None
),
ListProperty(
name='__CHAT_HISTORY__',
description='',
default_value=<class 'wayflowcore.property._empty_default'>,
enum=None,
item_type=AnyProperty(
name='',
description='',
default_value=<class 'wayflowcore.property._empty_default'>,
enum=None
)
)
],
pre_rendering_transforms=None,
post_rendering_transforms=[RemoveEmptyNonUserMessageTransform()],
tools=None,
native_tool_calling=True,
response_format=None,
native_structured_generation=True,
generation_config=None,
_partial_values={}
),
_filter_messages_by_recipient=True,
_add_talk_to_user_tool=True,
_used_provided_input_descriptors=[],
output_descriptors=[],
input_descriptors=[],
_all_variables=[],
_all_static_tools=[],
name='Helpful agent',
description='',
id='8d69e786-170b-433f-b316-629abcfa8554',
__metadata_info__={}
)
そしてこのWayFlowのエージェントの実行コードが下記になります。出力を見やすくするために長いコードになってしまいましたが、関数append_user_message()でユーザープロンプトを入力する部分がメインとなります。
from wayflowcore import MessageType
from IPython.display import display, Markdown
# 会話開始
conversation = wayflow_assistant.start_conversation()
conversation.append_user_message("日本の首相は誰ですか?")
# 同期的にエージェントを実行
wayflow_assistant.execute(conversation)
# メッセージ取得
messages = conversation.get_messages()
# ノートブック上に応答を表示
for message in messages:
if message.message_type == MessageType.TOOL_REQUEST:
display(Markdown(f"**{message.message_type.value}**: `{message.tool_requests}`"))
else:
display(Markdown(f"**{message.message_type.value}**: {message.content}"))
実行結果としては下記の通りです。さすがに2025年11月現在の首相は学習していないので下記のような応答テキストが生成されました。
USER: 日本の首相は誰ですか?
AGENT: 2023年10月現在、日本の首相は岸田文雄氏です。岸田氏は2021年10月4日に第100代内閣総理大臣に就任しました。
最終回答: 日本の首相は岸田文雄氏です。
上記コードではAgent Specで定義したエージェントをシリアライズし、同じPython環境で WayFlowにロードしていますが、シリアライズ時にyamlファイルで保存し、別のPython環境で読み込み、フレームワークにロードすることも当然ながら可能です。つまり、シリアライズすることによりエージェントに可搬性が生まれるということになります。
ここまでがAgent Specを使った最もシンプルなエージェントの開発から実行までの基本的な流れです。
この基本パターンに変化を加えたいくつかのサンプル実装を以降でご紹介します。
②ツール(MCP)を持ったエージェントの定義と実行
Agent Specでは当然MCPも使えます。①で説明したシンプルなエージェントにインターネット検索のMCPを追加し、LLMが学習していない最新の情報をインターネットから得られるようにしてみます。
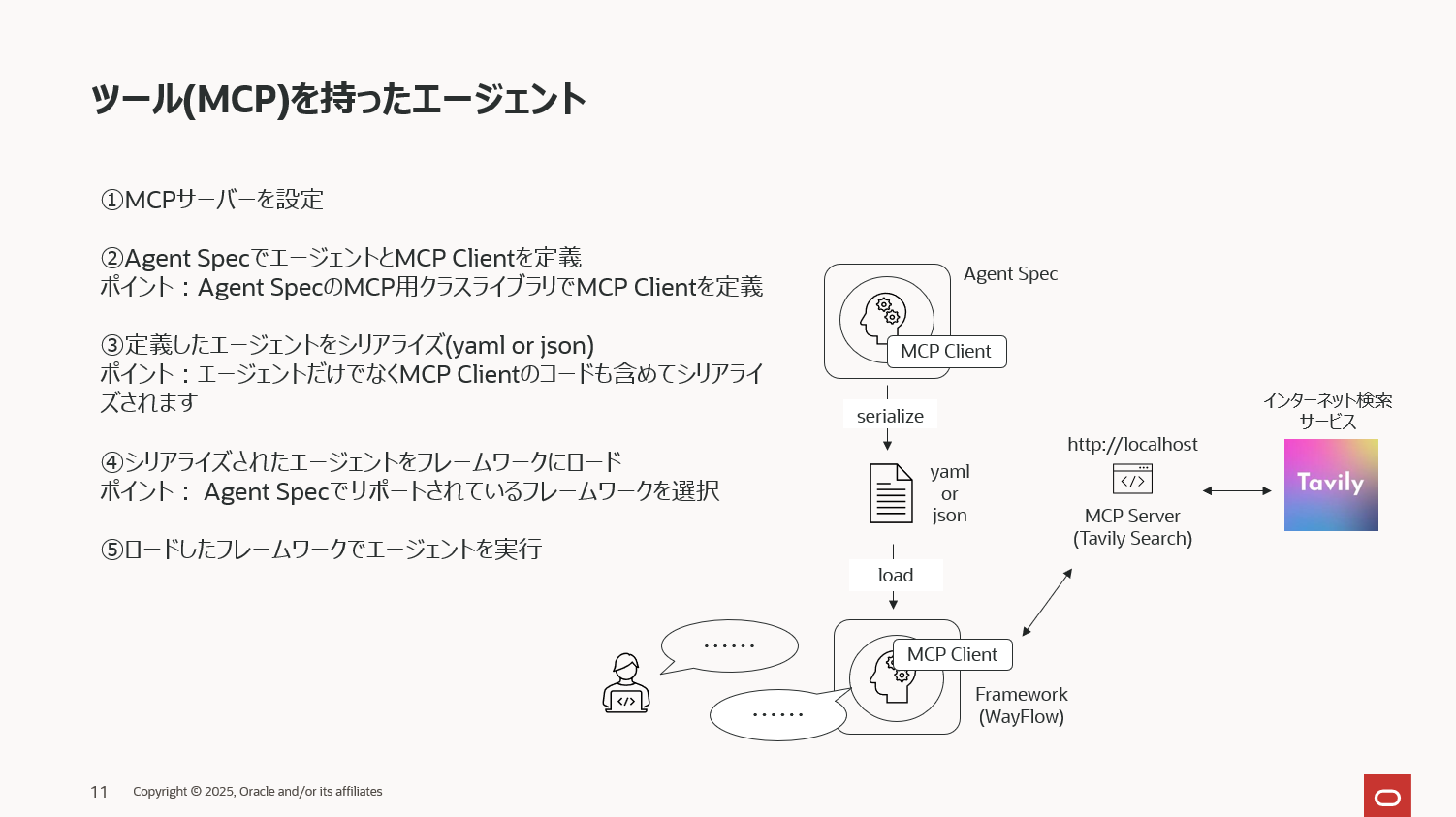
インターネット検索にはLLMユーザー御用達のTavily Searchを使い、下記のようにMCPを定義します。下記内容をtavily_mcp.pyというファイル名で保存し、pythonコマンドで実行すると、MCPサーバーが http://localhost:8080/sse で起動します。
# tavily_mcp.pyとして保存し、pythonコマンドで実行
from mcp.server.fastmcp import FastMCP
from tavily import TavilyClient
# Tavily API キー
TAVILY_API_KEY = "tavily searchのサイトで取得したapiキー"
def create_server(host: str, port: int):
"""Tavily検索用のMCPサーバーを作成"""
server = FastMCP(
name="Tavily MCP Server",
instructions="Perform web searches using the Tavily API.",
host=host,
port=port,
)
# --- Tavily クライアント作成 ---
client = TavilyClient(api_key=TAVILY_API_KEY)
@server.tool(description="ユーザーの入力に基づいてtavily searchで検索を実行します。")
def tavily_news_search(query: str):
"""ユーザーの入力に基づいてtavily searchで検索を実行します。"""
print(f"called tavily_news_search: {query}")
response = client.search(
query=query,
max_results=5,
search_depth="basic",
topic="general",
include_images=False,
region="JP",
)
results = []
for result in response.get("results", []):
results.append({
"title": result.get("title"),
"url": result.get("url"),
"snippet": result.get("content")[:200]
})
return results
return server
def start_mcp_server() -> str:
"""MCPサーバーを起動"""
host = "localhost"
port = 8080
server = create_server(host=host, port=port)
server.run(transport="sse") # Server-Sent Events で通信
return f"http://{host}:{port}/sse"
if __name__ == "__main__":
mcp_server_url = start_mcp_server()
print("Server running at:", mcp_server_url)
$ python ./tavily_mcp.py
INFO: Started server process [19252]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8080 (Press CTRL+C to quit)
先ほどと同じようにまずはLLMを定義します。
from pyagentspec.llms import OllamaConfig
llm_config = OllamaConfig(
name="Ollama Config",
model_id="gpt-oss:20b",
url="http://localhost:11434"
)
次に起動済のMCPサーバーに接続するMCPクライアントを定義します。
from pyagentspec.mcp import SSETransport
mcp_server_url = f"http://localhost:8080/sse" # change to your own URL
mcp_client = SSETransport(name="MCP Client", url=mcp_server_url)
internet_search_tool = MCPTool(
client_transport=mcp_client,
description="tavily searchを使ってインターネットを検索するツール",
name="tavily_news_search",
)
そしてエージェントの定義です。インターネット検索を実行するたにsystem_promptを少し変更している点と、tools=[internet_search_tool]としてMCPクライアントを定義している点が一つ前のサンプルコードのエージェントとの違いです。
from pyagentspec.agent import Agent
agent = Agent(
name="Helpful agent",
llm_config=llm_config,
system_prompt="""
あなたは優秀なアシスタントです。事実をもとにユーザーの質問に回答してください。
仮に憶測の情報をもとに回答する場合は必ずその旨を述べて回答してください。
最新の情報が必要な場合はinternet_search_toolを使ってtavily searchでインターネット検索を行い、その情報を元に回答してください。
""",
tools=[internet_search_tool]
)
これでエージェントの定義は完了ですので、ここまでのAgent Specの定義を下記コードでjsonにシリアライズします。
from pyagentspec.serialization import AgentSpecSerializer
serialized_assistant = AgentSpecSerializer().to_json(agent)
シリアライズされたエージェントをWayFlowにロードします。
from wayflowcore.agentspec import AgentSpecLoader
from wayflowcore.mcp import enable_mcp_without_auth
enable_mcp_without_auth()
loader = AgentSpecLoader()
wayflow_assistant = loader.load_json(serialized_assistant)
WayFlowでインターネット検索のツール(MCP)を持ったエージェントを実行してみます。
from wayflowcore import MessageType
from IPython.display import display, Markdown
# 会話開始
conversation = wayflow_assistant.start_conversation()
conversation.append_user_message("日本の首相は誰ですか?最新の情報をもとに回答してください。")
# 同期的にエージェントを実行
wayflow_assistant.execute(conversation)
# メッセージ取得
messages = conversation.get_messages()
# ノートブック上に応答を表示
for message in messages:
if message.message_type == MessageType.TOOL_REQUEST:
display(Markdown(f"**{message.message_type.value}**: `{message.tool_requests}`"))
else:
display(Markdown(f"**{message.message_type.value}**: {message.content}"))
下記の通り、インターネット検索のMCPで最新の情報を得られたため正しい応答テキストが生成されています。
USER: 日本の首相は誰ですか?最新の情報をもとに回答してください。
TOOL_REQUEST: [ToolRequest(name='tavily_news_search', args={'query': '現在の日本の首相 は ?', 'recency_days': 7, 'top_articles': 5}, tool_request_id='call_lz469de8')]
TOOL_RESULT: { "title": "内閣総理大臣の指名-令和6年10月1日",
"url": "https://www.gov-online.go.jp/press_conferences/prime_minister/202410/video-288640.html",
"snippet": "* English 現在の時間 0:00 長さ 0:00 ロード済み: 0% ストリームの種類 ライブ 残りの時間 -0:00 1x * 2x * 1.5x * 1x, 選択済み * 0.5x * チャプター * ディスクリプションオフ, 選択済み * captions and subtitles off, 選択済み 再生速度 画質 This is a modal window. この動画に対して" }
{ "title": "歴代内閣",
"url": "https://www.kantei.go.jp/jp/rekidainaikaku/index.html",
"snippet": "# 歴代内閣 これまでの総理大臣および 内閣の閣僚名簿をご紹介します。 ## 現職 * ### 第104代 高市 早苗 在職日数 日 ## 令和 * ### 第103代 石破 茂 在職日数345日 通算在職日数386日 + 第2次石破内閣 * ### 第102代 石破 茂 在職日数42日 + 第1次石破内閣 * ### 第101代 岸田 文雄 在職日数1,057日 通算在職日数1,094日 +" }
{ "title": "岸田文雄 (@kishida230) / Posts / X",
"url": "https://x.com/kishida230?lang=ja",
"snippet": "岸田文雄 (@kishida230) - Posts - 第100・101代内閣総理大臣。第27代自民党総裁。 いま日本は大きな岐路に立っています。世界のリーダーと共に平和と世界秩序、価値観" }
{ "title": "内閣総理大臣",
"url": "https://ja.wikipedia.org/wiki/%E5%86%85%E9%96%A3%E7%B7%8F%E7%90%86%E5%A4%A7%E8%87%A3",
"snippet": "| | | | | | | | | | | | | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | | | | | | | | | | | | | --- | --- | --- | --- | --- | --- | --- | --- | --- | | * 伊藤博文 * 黑田淸隆 *" }{ "title": "大臣・副大臣・政務官 | 議員", "url": "https://www.jimin.jp/member/minister/", "snippet": "総理大臣補佐官. 大臣. (2025年10月21日現在). 内閣総理大臣. 高市 早苗. 総務大臣. 林 芳正. 法務大臣. 平口 洋. 外務大臣. 茂木 敏充." }
AGENT: 現在の日本の内閣総理大臣は高市 早苗(第104代)です。彼女は令和6年10月1日に首相に就任しました。
【参考】
官房公式サイト(2025年10月更新): https://www.kantei.go.jp/jp/rekidainaikaku/index.html (現職: 高市早苗)
政府発表ビデオ(10月1日): https://www.gov-online.go.jp/press_conferences/prime_minister/202410/video-288640.html
③Agent SpecのAIエージェントを様々なフレームワークで実行
Agent Specはフレームワークに依存しないエージェント開発を目指しているライブラリです。そのため、Agent Specで定義したエージェントはAgent Specでサポートされているどのフレームワークでも実行できます。①のサンプルコードではAgent Specで定義したエージェントをWayFlowで実行しましたが、下記はAutoGenやLangGraphで実行しているコードです。
サンプルコード①でインターネット検索(Tavily Search)のMCPを作りましたが、ここではFunction Callingで同じツールを定義してみましょう。
まずはFunction Calling用の関数を定義します。
from getpass import getpass
import os
from tavily import TavilyClient
# --- API キー入力 ---
if not os.getenv("TAVILY_API_KEY"):
os.environ["TAVILY_API_KEY"] = getpass("Tavily API Key : ")
client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
def tavily_search(query: str):
"""ユーザーの入力に基づいて Tavily Search で検索を実行します。"""
print(f"called tavily_search: {query}")
response = client.search(
query=query,
max_results=3,
search_depth="basic",
topic="general",
include_images=False,
region="JP",
)
results = []
for idx, result in enumerate(response.get("results", []), start=1):
# --- 結果表示 ---
print(f"Result #{idx}")
print(" Title :", result.get("title"))
print(" URL :", result.get("url"))
print(" Snippet:", (result.get("content") or "")[:200], "…\n")
results.append({
"title": result.get("title"),
"url": result.get("url"),
"snippet": (result.get("content") or "")[:200],
})
return results
次にLLMを定義します。①のサンプルコードではOCI Generative AIサービスを利用しましたが、こちらも変更を加え、Ollamaを使ってローカルで OpenAI の gpt-oss:20b のモデルを動作させて使ってみたいと思います。
from pyagentspec.llms import OllamaConfig
llm_config_ollama = OllamaConfig(
name="Ollama Config",
model_id="gpt-oss:20b",
url="http://localhost:11434"
)
次に、Agent Specでのエージェントの定義です。①のサンプルコードとほぼ変わりませんが、MCPではなくFunction Callingを使っていますから、toolsの定義が少し変更されていることに注意してください。
from pyagentspec.agent import Agent
from pyagentspec.tools import ServerTool
from pyagentspec.property import StringProperty
agent = Agent(
name="Helpful agent",
llm_config=llm_config_ollama,
system_prompt="""
あなたは優秀なアシスタントです。事実をもとにユーザーの質問に回答してください。
仮に憶測の情報をもとに回答する場合は必ずその旨を述べて回答してください。
最新の情報が必要な場合はtavily_searchを使ってインターネット検索を行い、その情報を元に回答してください。
""",
tools=[
ServerTool(
name="tavily_search",
inputs=[StringProperty(title="query")],
outputs=[StringProperty(title="tavily_search")]
)
],
)
ここまででエージェントの定義が完了しました。
これまで同様下記コードでAgent Specのエージェントをシリアライズします。
from pyagentspec.serialization import AgentSpecSerializer
serialized_assistant = AgentSpecSerializer().to_yaml(agent)
シリアライズしたエージェントを下記コードでAutoGenにロードします。
from autogen_agentspec_adapter import AgentSpecLoader
loader = AgentSpecLoader(tool_registry={"tavily_search": tavily_search})
autogen_assistant = loader.load_yaml(serialized_assistant)
ロードsれたAutoGenのエージェントを下記コードで実行します。
from autogen_agentchat.messages import TextMessage
from autogen_core import CancellationToken
await autogen_assistant.on_messages(
[TextMessage(content="日本の首相はだれですか?", source="user")],
cancellation_token=CancellationToken()
)
出力結果は下記の通り、うまく動作していることがわかります。
出力結果(非常に長いので折り畳みます)
Response(
chat_message=TextMessage(
id='fa3017e7-46f9-408e-b56d-fae1db4d1a2f',
source='Helpful_agent',
models_usage=RequestUsage(
prompt_tokens=2404,
completion_tokens=404
),
metadata={},
created_at=datetime.datetime(
2025, 11, 18, 16, 46, 31, 779359,
tzinfo=datetime.timezone.utc
),
content='**現在(2025年11月18日現在)の日本の内閣総理大臣は、**
**高市早苗(たかいち さなえ)** です。
- **在任開始**:2025年10月21日(第104代総理大臣として就任)
- **党所属**:自由民主党(自民党)
- **歴史的意義**:日本初の女性総理大臣です。
**情報の出典**
- 高市早苗総理が就任したことを報じた複数のメディア記事(例:日経新聞、YouTubeなど)
- 日本国政府公式サイト(首相官邸)に掲載された最新の首相情報
(※最新情報は随時更新される可能性がありますので、正確な在任状況を確認したい場合は、公式サイトや主要報道機関の最新発表をご確認ください。)',
type='TextMessage'
),
inner_messages=[
ToolCallRequestEvent(
id='9f655e23-cc28-468c-8a45-8f1d207294b2',
source='Helpful_agent',
models_usage=RequestUsage(
prompt_tokens=1964,
completion_tokens=454
),
metadata={},
created_at=datetime.datetime(
2025, 11, 18, 16, 46, 24, 199979,
tzinfo=datetime.timezone.utc
),
content=[
FunctionCall(
id='6',
arguments='{"query": "高市早苗 日本 首相 2025年10月"}',
name='tavily_search'
)
],
type='ToolCallRequestEvent'
),
ToolCallExecutionEvent(
id='1630166b-83e0-4bd1-afdb-b156cb2305fc',
source='Helpful_agent',
models_usage=None,
metadata={},
created_at=datetime.datetime(
2025, 11, 18, 16, 46, 25, 856946,
tzinfo=datetime.timezone.utc
),
content=[
FunctionExecutionResult(
content="[
{
'title': '高市首相「日本最大の問題は人口減少」 人口戦略本部が初会合',
'url': 'https://www.nikkei.com/article/DGXZQOUA180TY0Y5A111C2000000/',
'snippet': '自民党の高市早苗総裁は2025年10月21日、衆参両院の本会議で第104代首相に指名されました...'
},
{
'title': '高市早苗内閣総理大臣 所信表明演説 2025年10月24日(金)',
'url': 'https://x.com/jimin_koho/status/1981652286947336613',
'snippet': '高市早苗総理が所信表明演説を行いました。'
},
{
'title': '【ノーカット】高市早苗総理が所信表明演説 - YouTube',
'url': 'https://www.youtube.com/watch?v=ruGK25rvfcY',
'snippet': '所信表明演説をノーカットで配信します。'
}
]",
name='tavily_search',
call_id='6',
is_error=False
)
],
type='ToolCallExecutionEvent'
)
]
)
続いて、今度はLangGraphで実行するパターンを試します。
ここまでと同様に下記コードでLangGraphにエージェントをロードします。
from langgraph_agentspec_adapter import AgentSpecLoader
loader = AgentSpecLoader(tool_registry={"tavily_search": tavily_search})
langgraph_assistant = loader.load_yaml(serialized_assistant)
print(langgraph_assistant)
LangGraphにロードされたエージェントを下記コード実行します。
langgraph_assistant.invoke(
{"messages": [{"role": "user", "content": "日本の首相はだれですか?"}]}
)
出力結果は下記の通り、うまく動作していることがわかります。
出力結果(非常に長いので折り畳みます)
called tavily_search: 日本の首相 2025
Result #1
Title : 現在の日本の総理大臣は石破ですか - X
URL : https://x.com/i/grok/share/BQP0anWCt3oBEsvDlIc3YicPr
Snippet: はい、石破茂氏が2025年10月12日現在の日本の内閣総理大臣です。自民党総裁選を経て2024年10月1日に就任し、2025年9月8日に辞任を表明したものの、正式な退任手続きが …
Result #2
Title : 高市早苗氏でもない…いま自民党内で急浮上している「次の首相」有力 ...
URL : https://president.jp/articles/-/103213?page=1
Snippet: 小泉進次郎氏でも、高市早苗氏でもない…いま自民党内で急浮上している「次の首相」有力候補の意外な名前【2025年9月BEST】 「こんなときは無色透明、無名が一番 …
Result #3
Title : 石破内閣総理大臣記者会見-令和7年10月10日 - YouTube
URL : https://www.youtube.com/watch?v=vlFtFdQa0Io
Snippet: 石破内閣総理大臣記者会見-令和7年10月10日
首相官邸
175000 subscribers
<中略>
ToolMessage(content='[{"title": "Japan\'s Prime Minister Faces Backlash Over 3 A.M. Staff Meeting", "url": "https://www.nytimes.com/2025/11/12/world/asia/japan-takaichi-work-overtime.html", "snippet": "[Skip to content](https://www.nytimes.com/2025/11/12/world/asia/japan-takaichi-work-overtime.html#site-content)[Skip to site index](https://www.nytimes.com/2025/11/12/world/asia/japan-takaichi-work-ov"}, {"title": "Takaichi Sanae: Japan\'s first female prime minister | Think Tank", "url": "https://www.europarl.europa.eu/thinktank/en/document/EPRS_BRI(2025)777965", "snippet": "In October 2025, for the first time in its history, Japan elected a female prime minister. Takaichi Sanae won the race for the leadership of"}, {"title": "How Japan\'s new prime minister has brought China\'s \'wolf ... - CNN", "url": "https://www.cnn.com/2025/11/12/asia/japan-takaichi-china-taiwan-analysis-intl-hnk", "snippet": "[China](https://www.cnn.com/world/china) [More](https://www.cnn.com/2025/11/12/asia/japan-takaichi-china-taiwan-analysis-intl-hnk) * [Sign out](https://www.cnn.com/2025/11/12/asia/japan-takaichi-chi"}]', name='tavily_search', id='993824c5-f717-4f72-b7fb-e7ca372e1d5b', tool_call_id='939739ff-1936-44ec-bfe3-35461f7c5da5'),
AIMessage(content='現在(2025年11月時点)の日本の首相は **高市早苗(たかいち さなえ)** さんです。\n\n- 彼女は2025年10月に総理大臣に就任し、日本史上初めて女性の首相となりました。 \n- 高市氏は自民党の長期にわたる政治家で、特に安全保障や外交政策に関する経験があります。 \n- 就任後は新型コロナ対策の延長、経済再生、地方創生などを重点課題とし、国内外でのリーダーシップを発揮しています。\n\nなお、公式情報は厚生省・内閣府などの公的発表や、信頼できるニュースメディア(朝日新聞・毎日新聞・NHK等)で確認できます。', additional_kwargs={}, response_metadata={'model': 'gpt-oss:20b', 'created_at': '2025-11-18T19:45:58.956537842Z', 'done': True, 'done_reason': 'stop', 'total_duration': 3534710307, 'load_duration': 198723097, 'prompt_eval_count': 903, 'prompt_eval_duration': 139826032, 'eval_count': 274, 'eval_duration': 3010807531, 'model_name': 'gpt-oss:20b', 'model_provider': 'ollama'}, name='Helpful agent', id='lc_run--39f0670b-e45a-44cc-aec9-270777d70782-0', usage_metadata={'input_tokens': 903, 'output_tokens': 274, 'total_tokens': 1177})]}
上述のサンプルコードでは Agent Specから他のフレームワークへのエージェントの移植コードを取り上げましたが、サポートフレームワーク間であればどのパターンも移植は可能です。上記で取り上げたパターン以外のものは下記githubにサンプルコードがありますのでご参照ください。
④Agent Specでマルチエージェントの定義と実行
ここまではシンプルなシングルエージェントのサンプルを取り上げましたが、Agent Specでは当然マルチエージェントも定義できます。下記は、コード生成用のエージェントがユーザーの入力に基づいたコードを生成し、もう一つのエージェントが生成されたエージェントをレビューするというシナリオのマルチエージェントになります。
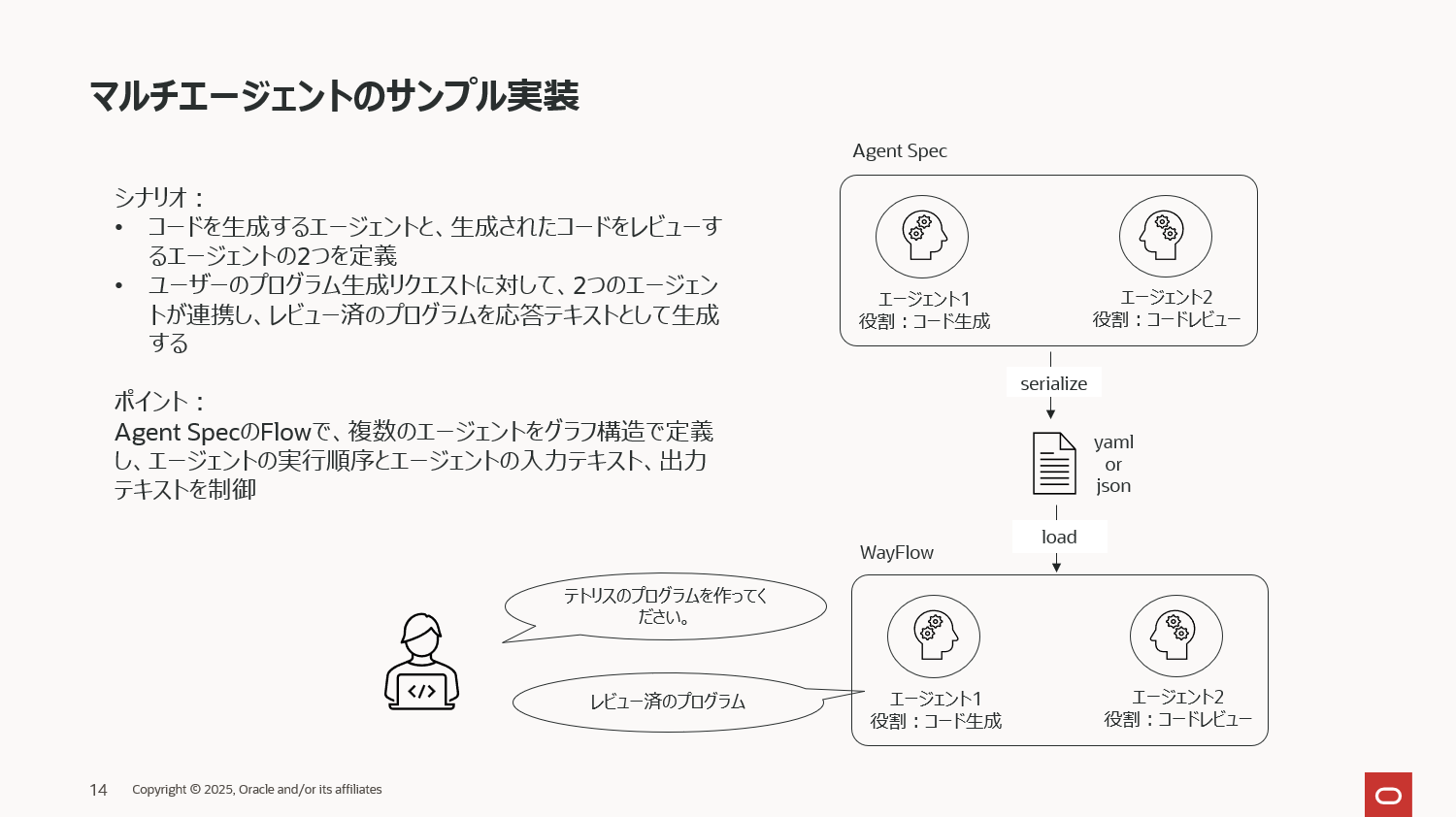
まずはLLMの定義です。今回もローカルにOllamaで起動したgpt-oss:20bを使ってみます。
from pyagentspec.llms import OllamaConfig
llm_config = OllamaConfig(
name="Ollama Config",
model_id="gpt-oss:20b",
url="http://localhost:11434"
)
マルチエージェントはその名の通り、複数のエージェントが各役割に応じて連携するため、その連携フローを定義する必要があります。この定義にはしばしば冒頭で説明したグラフデータモデルが使われるケースが多く、Agent Specでも同様で、このフロー定義のために Flow と呼んでいるクラスが用意されており、それを使ってエージェントの実行順序を制御します。
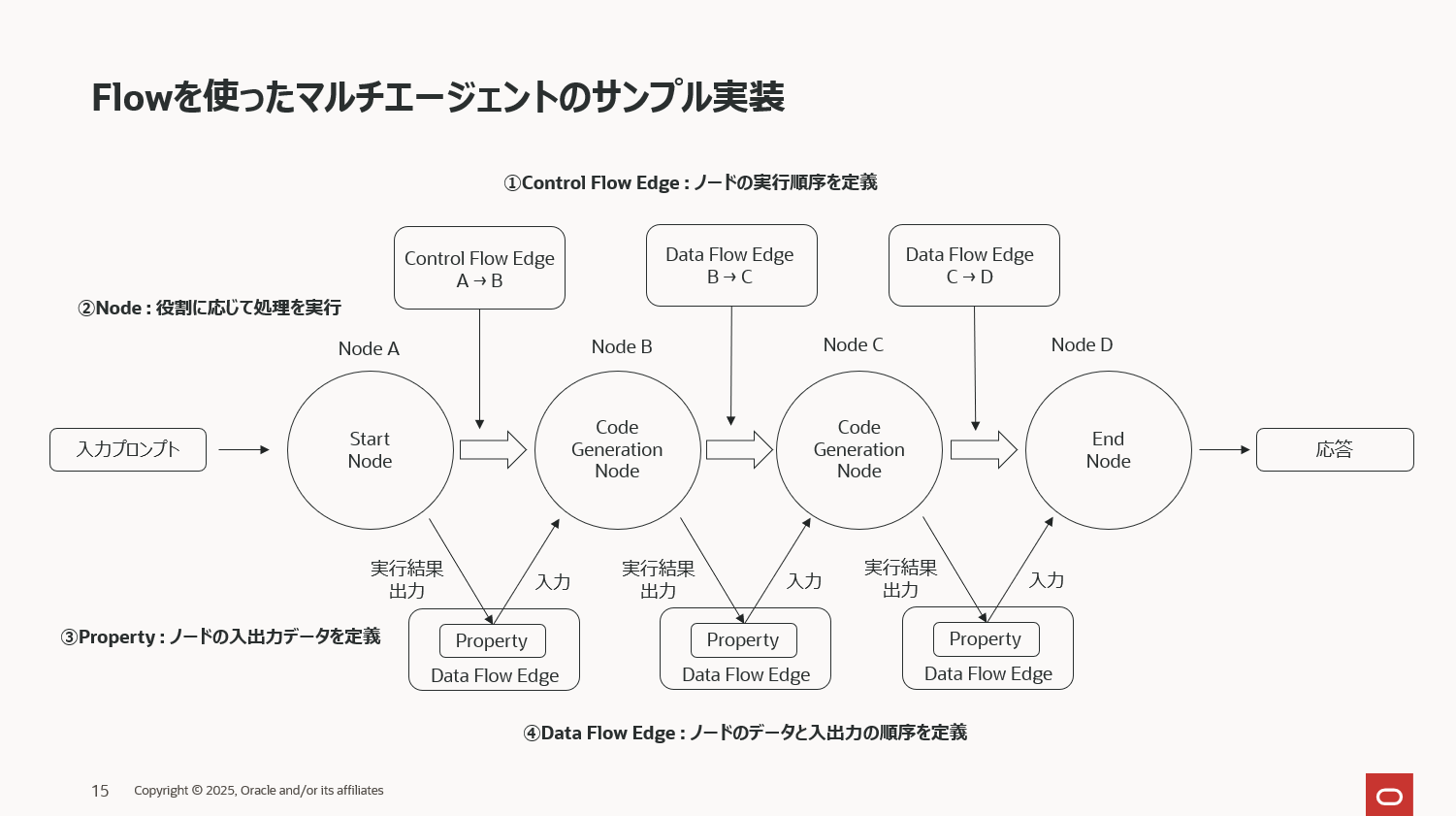
上図は以降のコードで定義するグラフデータモデル(Agent SpecのFlow)を模式図にしたものです。少し複雑な図になってしまいましたが、冒頭に説明したプロパティグラフのノード、エッジ、プロパティの3つを定義しているだけです。
まず、下記コードがFlowのプロパティの定義です。プロパティとは、エージェントが処理を実行するためにエージェントに入出力されるデータの名前や型を定義したものです。マルチエージェントでは複数のエージェントが役割分担し連携して最終的な応答を生成します。つまり、あるエージェント実行後の出力データは別のエージェントの入力データとなることでエージェント同士が連携します。そのため、エージェントに入出力されるデータをシナリオに沿って予め定義しておく必要がありそれがプロパティです。エージェント間でデータの受け渡しルールを明示的に決めておくことで、処理フローの安全性や追跡性を確保できるということです。必然的に、定義したプロパティは各エージェントに関連付けられることになります。
# --- プロパティ ---
from pyagentspec.property import Property
user_request_property = Property(json_schema={"title": "user_request", "type": "string"})
code_property = Property(json_schema={"title": "code", "type": "string", "default": ""})
review_property = Property(json_schema={"title": "review", "type": "string", "default": ""})
このサンプルコードでは、エージェント間でやり取りされるデータとして下記3つのプロパティを定義しています。
- user_request_property:ユーザー入力
- code_property:生成されたPythonコード
- review_property:コードレビューの結果
おおよそ想像がつくと思いますが、
- user_request_property(ユーザー入力)がgenerate_code_node(コードを生成するエージェント)の入力となり、code_propertyが(生成されたPythonコード)その出力です。
- この出力がreview_code_node(生成されたコードをレビューするエージェント)の入力となり、review_property(コードレビューの結果)がその出力です。
次にノードを定義します。このサンプルでは上述のシナリオから、コードを生成するエージェント(ノード)と、生成されたコードをレビューするエージェント(ノード)の2つを定義しています。その他、Flowで定義する際は、これらのエージェント以外にStartNodeとEndNode、つまり、フローの開始点とフローの終了点を表すノードを定義する必要があります。
# --- ノード ---
from pyagentspec.flows.nodes import StartNode, EndNode, LlmNode
start_node = StartNode(name="Start", inputs=[user_request_property])
generate_code_node = LlmNode(
name="Generate Code",
prompt_template="""
あなたは優れたPythonソフトウェアエンジニアです。
以下のユーザーリクエストに基づきPythonコードを作成してください:
{{user_request}}
以前のコード:
{{code}}
レビューコメント:
{{review}}
""",
llm_config=llm_config,
inputs=[user_request_property, code_property, review_property],
outputs=[code_property]
)
review_code_node = LlmNode(
name="Review Code",
prompt_template="""
あなたは優れたコードレビュー担当者です。
以下のPythonコードをレビューしてください:
{{code}}
""",
llm_config=llm_config,
inputs=[code_property],
outputs=[review_property]
)
end_node = EndNode(name="End", outputs=[code_property, review_property])
次にプロパティグラフのエッジを定義しますが、Flowでは2つのタイプのエッジがあります。その一つがコントロールフローエッジです。コントロールフローエッジとは各エージェント(ノード)の実行順序を定義したもので,
from_nodeとto_nodeでエッジを定義します。
下記の定義ではシンプルに4つのノードが順番に実行されるようにfrom_nodeとto_nodeが設定された3つのコントロールフローエッジが定義されていることがわかります。
# --- コントロールフローエッジ ---
from pyagentspec.flows.edges.controlflowedge import ControlFlowEdge
control_flow_edges = [
ControlFlowEdge(name="start_to_generate", from_node=start_node, to_node=generate_code_node),
ControlFlowEdge(name="generate_to_review", from_node=generate_code_node, to_node=review_code_node),
ControlFlowEdge(name="review_to_end", from_node=review_code_node, to_node=end_node),
]
そしてもう一つのタイプのエッジがデータフローエッジです。ノード間でどのデータ(プロパティの値)を受け渡すのかを定義します。例えば、下記の2つ目のデータフローエッジでは、エッジの両サイド(sourceとdestination)のノードがgenerate_code_nodeとreview_code_nodeになっており、generate_code_nodeで生成されたコードをcode_propertyの変数codeに代入、そしてreview_code_nodeで生成されたコードをレビューできるよう、変数codeを入力として定義しています。
# --- データフローエッジ ---
from pyagentspec.flows.edges.dataflowedge import DataFlowEdge
data_flow_edges = [
DataFlowEdge(
name="start_to_generate_user_request",
source_node=start_node,
source_output="user_request",
destination_node=generate_code_node,
destination_input="user_request"
),
DataFlowEdge(
name="generate_to_review_code",
source_node=generate_code_node,
source_output="code",
destination_node=review_code_node,
destination_input="code"
),
DataFlowEdge(
name="review_to_end_review",
source_node=review_code_node,
source_output="review",
destination_node=end_node,
destination_input="review"
),
]
最後に、ここまで定義した、ノード、プロパティ、コントロールフローエッジ、データフローエッジをフロー制御として纏めて下記コードで定義しています。
# --- Flow ---
from pyagentspec.flows.flow import Flow
final_flow = Flow(
name="Simple Code Generation Flow",
description="ユーザーリクエスト → コード生成 → コードレビュー → 出力",
start_node=start_node,
nodes=[start_node, generate_code_node, review_code_node, end_node],
control_flow_connections=control_flow_edges,
data_flow_connections=data_flow_edges,
)
少し複雑に見えるかもしれませんが、グラフは人間が極めて理解しやすい構造で定義されますので、一度シンプルなコードを経験すれば複雑なフローでも上述した各定義の個数が増えるだけでグラフの考え方と処理ロジックそのものは変わりません。
ここまででAgent Specでのマルチエージェントが定義できましたので、お馴染みのシリアライズを下記コードで行います。
# --- シリアライズ ---
from pyagentspec.serialization import AgentSpecSerializer
from wayflowcore.agentspec import AgentSpecLoader
シリアライズしたマルチエージェントを実行するため、下記コードでWayFlowにロードします。
# --- シリアライズ ---
serialized_agent = AgentSpecSerializer().to_yaml(final_flow)
loader = AgentSpecLoader()
wayflow_assistant = loader.load_yaml(serialized_agent)
ロードされたエージェントを下記コードで実行してみます。
# Flowの入力に必要なpropertyを指定
conversation = wayflow_assistant.start_conversation({
"user_request": "pythonでautogenのマルチエージェントのサンプルコードを提示してください。"
})
status = wayflow_assistant.execute(conversation)
# 入出力結果を表示
for output_name, output_value in conversation.state.input_output_key_values.items():
print(f"{output_name} >>> \n{output_value}")
下記の通りうまく動作していることがわります。
出力結果(非常に長いので折り畳みます)
('Start', 'user_request') >>>
pythonでテトリスのサンプルコードを作ってください。
('Generate Code', 'user_request') >>>
pythonでテトリスのサンプルコードを作ってください。
('Review Code', 'code') >>>
**Python サンプル - シンプルテトリス (pygame 版)**
以下は「pygame」を使って作った最小限のテトリスです。
`pygame` が入っていない場合は `pip install pygame` でインストールしてください。
```python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
簡易テトリス(Tetris)サンプル
・30×20 の盤面
・5 種類のブロック(L, J, O, I, T)
・左右移動、回転、落下
・行が埋まると消滅
・ゲームオーバー判定
"""
import pygame
import random
import sys
# -------------------------------------------------
# 定数
# -------------------------------------------------
WIDTH, HEIGHT = 10, 20 # コード上の幅×高さ
BLOCK_SIZE = 30 # ブロック1つのサイズ(ピクセル)
SCREEN_WIDTH = WIDTH * BLOCK_SIZE
SCREEN_HEIGHT = HEIGHT * BLOCK_SIZE
FPS = 60
# 色(R, G, B)
COLORS = [
(0, 0, 0), # 0: 空き
(0, 240, 240), # 1: I
(0, 0, 240), # 2: J
(240, 240, 0), # 3: L
(240, 0, 0), # 4: O
(240, 0, 240) # 5: T
]
# ブロック形状(4x4 行列のリスト)
SHAPES = {
1: [[1, 1, 1, 1]], # I
2: [[2, 0, 0],
[2, 2, 2]], # J
3: [[0, 0, 3],
[3, 3, 3]], # L
4: [[4, 4],
[4, 4]], # O
5: [[0, 5, 0],
[5, 5, 5]] # T
}
# -------------------------------------------------
# クラス
# -------------------------------------------------
class Shape:
"""テトリスブロック(Tetrimino)"""
def __init__(self, shape_id):
self.shape_id = shape_id
self.matrix = SHAPES[shape_id]
self.rotation = 0
# 初期位置(盤面上に出てくる位置)
self.x = WIDTH // 2 - len(self.matrix[0]) // 2
self.y = 0
def rotate(self, board):
"""回転(右回転) - 失敗したら元に戻す"""
new_matrix = self._rotate_matrix(self.matrix)
if not self._collision(board, new_matrix, self.x, self.y):
self.matrix = new_matrix
self.rotation = (self.rotation + 1) % 4
@staticmethod
def _rotate_matrix(matrix):
return [list(row)[::-1] for row in zip(*matrix)]
def move(self, dx, dy, board):
"""移動(dx, dy) - 失敗したら元に戻す"""
nx, ny = self.x + dx, self.y + dy
if not self._collision(board, self.matrix, nx, ny):
self.x, self.y = nx, ny
return True
return False
def _collision(self, board, matrix, x, y):
"""盤面との衝突判定"""
for i, row in enumerate(matrix):
for j, val in enumerate(row):
if val == 0:
continue
bx, by = x + j, y + i
if bx < 0 or bx >= WIDTH or by < 0 or by >= HEIGHT:
return True
if board[by][bx] != 0:
return True
return False
class Tetris:
"""ゲーム本体"""
def __init__(self):
pygame.init()
self.screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT))
pygame.display.set_caption("Tetris")
self.clock = pygame.time.Clock()
self.board = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)]
self.current_shape = self._new_shape()
self.drop_time = 0
self.drop_speed = 500 # ms
def _new_shape(self):
return Shape(random.choice(list(SHAPES.keys())))
def run(self):
while True:
self._handle_events()
self._update()
self._draw()
self.clock.tick(FPS)
# -------------------------------------------------
# イベント処理
# -------------------------------------------------
def _handle_events(self):
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
# キー処理(1フレームだけ)
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT:
self.current_shape.move(-1, 0, self.board)
elif event.key == pygame.K_RIGHT:
self.current_shape.move(1, 0, self.board)
elif event.key == pygame.K_DOWN:
self.current_shape.move(0, 1, self.board)
elif event.key == pygame.K_UP:
self.current_shape.rotate(self.board)
elif event.key == pygame.K_SPACE: # 一気落下
while self.current_shape.move(0, 1, self.board):
pass
# -------------------------------------------------
# 更新
# -------------------------------------------------
def _update(self):
self.drop_time += self.clock.get_time()
if self.drop_time > self.drop_speed:
if not self.current_shape.move(0, 1, self.board):
# ブロックが止まったら盤面に固定
self._add_to_board()
self._clear_lines()
self.current_shape = self._new_shape()
if self.current_shape._collision(self.board, self.current_shape.matrix,
self.current_shape.x, self.current_shape.y):
# 新たなブロックがすぐ衝突 -> Game Over
print("Game Over!")
pygame.quit()
sys.exit()
self.drop_time = 0
def _add_to_board(self):
"""ブロックを盤面に固定"""
for i, row in enumerate(self.current_shape.matrix):
for j, val in enumerate(row):
if val:
self.board[self.current_shape.y + i][self.current_shape.x + j] = self.current_shape.shape_id
def _clear_lines(self):
"""埋まった行を消す"""
new_board = [row for row in self.board if any(cell == 0 for cell in row)]
lines_cleared = HEIGHT - len(new_board)
for _ in range(lines_cleared):
new_board.insert(0, [0 for _ in range(WIDTH)])
self.board = new_board
# -------------------------------------------------
# 描画
# -------------------------------------------------
def _draw(self):
self.screen.fill((50, 50, 50))
# 盤面
for y, row in enumerate(self.board):
for x, val in enumerate(row):
if val:
pygame.draw.rect(self.screen,
COLORS[val],
(x * BLOCK_SIZE, y * BLOCK_SIZE, BLOCK_SIZE, BLOCK_SIZE))
# 現在のブロック
for i, row in enumerate(self.current_shape.matrix):
for j, val in enumerate(row):
if val:
pygame.draw.rect(self.screen,
COLORS[val],
((self.current_shape.x + j) * BLOCK_SIZE,
(self.current_shape.y + i) * BLOCK_SIZE,
BLOCK_SIZE,
BLOCK_SIZE))
pygame.display.flip()
# -------------------------------------------------
# 実行
# -------------------------------------------------
if __name__ == "__main__":
Tetris().run()
```
### コードのポイント
| 機能 | 実装方法 | 補足 |
|------|---------|------|
| ブロックの回転 | `Shape._rotate_matrix()` | 右回転のみ |
| 衝突判定 | `Shape._collision()` | 盤面とブロックの両方 |
| 行消し | `Tetris._clear_lines()` | 盤面上で行が埋まると上方向へ行を挿入 |
| ゲームオーバー | 新ブロックが即座に衝突 | 盤面左上に `Game Over!` と出力 |
| キー操作 | 左右移動, 角度回転, 1段落下, 一気落下 | 1フレームごとに処理 |
| フレームレート | Pygame の Clock | 60 FPS で滑らか |
### 改善案(レビューコメントの一例)
1. **重なり判定を関数化**
`Collision` をクラスレベルに抽出すると再利用性が上がります。
2. **ライン消去の点数計算**
複数ライン同時消去に応じて段階的にスコア増加。
3. **プレイヤー入力のバウンドリミット**
連打によるスムーズな移動を実装(キー保持時に遅延を設定)。
4. **GUI 要素の追加**
`pygame.font` でスコアや次のブロックを表示。
5. **設定ファイル化**
盤面サイズ・速度・色などを外部 JSON で管理すると拡張性が高まります。
このサンプルをもとに、自分の好きな機能を追加してさらに楽しいテトリスを作ってみてください!
('End', 'review') >>>
## コードレビュー
以下は、掲示いただいた **「pygame 版シンプルテトリス」** を対象にした詳細なレビューです。
実装のポイントや改善点、潜在的なバグ・パフォーマンスの注意点をまとめています。
日本語でまとめましたので、実装にすぐに反映しやすいと思います。
---
### 1. ざっくりまとめ
| 目的 | 実装 | コメント |
|------|------|----------|
| Tetrisブロックの定義 | `SHAPES` 辞書 | 4x4 でなく可変長 2~4 行 |
| 回転 | `Shape._rotate_matrix()` | 右回転のみ、縦横比の変化を考慮 |
| 移動/衝突 | `Shape.move()`, `Shape._collision()` | 盤面配列と合わせて直接判定 |
| 行消し | `Tetris._clear_lines()` | すべての行を走査して新盤面を作成 |
| フレーム管理 | `pygame.time.Clock` + `drop_speed` | 1 フレーム単位でダウンタイムを増算 |
---
### 2. 良い点(強み)
| 項目 | 内容 | 価値 |
|------|------|------|
| **シンプルさ** | 90 行程度、クラス構造も 2 クラス | 学習教材・デモに最適 |
| **直感的な移動ロジック** | `Shape.move()` が「失敗したら元に戻す」だけで OK | コードを読むだけで動きをイメージしやすい |
| **ライン消しの実装** | リスト内包表現で簡潔 | Pythonic で読みやすい |
| **ゲームオーバー判定** | 新ブロック生成時に衝突チェック | すぐに判定できる |
| **コメントとdocstring** | クラス/メソッドごとに簡潔に | 読み手の学習を助ける |
---
### 3. 改善点・提案
#### 3.1 コーディングスタイル(PEP‑8)
| 問題 | 行番号例 | 改善例 | コメント |
|------|----------|--------|----------|
| インデントの不揃い | 29行前後 | ` self.screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT))` | 4 スペースで揃える |
| 変数名に数字を前置 | `shape_id` | `shape_key` | 意味がわかりやすい |
| 定数のキャメルケース | `COLORS`, `SHAPES` | `COLORS`, `SHAPES` も OK | ただし `COLORS` / `SHAPES` だけは大文字列 |
| 空行の余分 | `__init__` 直後 | 2 行目に `"""` の前に空行を 1 行にする | 目安は 2 行 |
| `sys.exit()` 直後の `pygame.quit()` の順序 | `Tetris._update` | `pygame.quit(); sys.exit()` | Pygame のリソースを先に解放 |
#### 3.2 型ヒントの追加
```python
def _collision(self, board: List[List[int]], matrix: List[List[int]],
x: int, y: int) -> bool:
...
```
Python 3.8+ なら `list[list[int]]` でさらにシンプルに書けます。
型ヒントを入れると IDE で補完がきくだけでなく、`mypy` で静的チェックも可能です。
#### 3.3 乱数取得の安全性
```python
def _new_shape(self):
return Shape(random.choice(list(SHAPES.keys())))
```
- `list(SHAPES.keys())` は毎回リストを生成。
- 代わりに `random.choice(tuple(SHAPES))` でタプルにしておくと高速です。
#### 3.4 `Shape._rotate_matrix` の汎用性
```python
def _rotate_matrix(matrix):
return [list(row)[::-1] for row in zip(*matrix)]
```
- これは左回転(90°)ではなく **右回転**(clockwise) に相当します。
- もし左回転を入れたい場合は、`zip(*matrix[::-1])` を使う等の説明を書きましょう。
#### 3.5 回転時の衝突チェック
- 現在は `new_matrix = self._rotate_matrix(self.matrix)` を呼び、
`if not self._collision(board, new_matrix, self.x, self.y):` のみ確認しています。
- 盤面上に落ちているブロックがあった場合、回転できないケースでは *元に戻す* だけで済んでいますが、
**壁クランプ(壁衝突を許容して位置を調整)** を追加すると遊びやすくなります。
- 例)回転後の x,y を右に1〜3 スペース試し、衝突が無ければ確定。
#### 3.6 行消しの効率化
```python
new_board = [row for row in self.board if any(cell == 0 for cell in row)]
```
- すべての行を走査して 0 が無い行だけ除外するので O(HEIGHT × WIDTH)。
- 実際に `HEIGHT` は 20 なので問題ありませんが、
*ライン消し後に盤面を下に移動(落下)* を実装したい場合は
`enumerate` を使ってインデックスで操作できる方が高速です。
#### 3.7 速度制御と FPS
- `drop_speed = 500 # ms` と固定値を使っているので、
レイテンシがあると **1 秒あたりの落下数** が不正確になる場合があります。
- `pygame.time.get_ticks()` と `time.perf_counter()` の差で計測し、
0.5 秒ごとに `drop` を行うと同じ速度でゲーム進行できます。
#### 3.8 キー入力の滑らかさ
- 現在は `KEYDOWN` のみで判定。
- キーを押し続けると、**連打によって移動がずれてしまう**(連打速度と FPS が一致しない)。
- `pygame.key.set_repeat(low_delay, high_delay)` でキー保持時の遅延を設定したり、
`pygame.key.get_pressed()` で毎フレーム状態をチェックすると滑らかな入力になります。
#### 3.9 ゲームオーバーの通知
- `print("Game Over!")` だけだと、pygame のウィンドウが閉じる前に出力が確認できない。
- `pygame.font` で画面中央に「Game Over!」を描画し、
`pygame.time.Clock().tick(1)` で 1 秒待ってから終了すると、ユーザーに見せやすくなります。
#### 3.10 デバッグ用情報を追加
- **スコア**(ライン数 × 100 など)
- **次ブロック**のプレビュー
- **フレーム数**・**FPS** の表示
これらは `pygame.font` と `pygame.display.set_caption()` で簡単に追加可能です。
#### 3.11 可能なバグ/リスク
| バグ | 内容 | 対策 |
|------|------|------|
| `current_shape._collision` で自分自身のブロックをチェック | `_collision` は「現在のブロックの位置」も盤面と比較するので、固定済みブロックに重なる可能性がある | `move` 前に一時的に自分のブロックを盤面から除外するか、`move` で衝突チェック時に「自分自身は除外」論理を入れる |
| `self.current_shape.move(0, 1, self.board)` 後の追加 | ループで直接 `while self.current_shape.move(0, 1, self.board): pass` を使うと、`move` の内部で衝突後に `_collision` チェックが二重に行われる | 最終位置が確定したら、`_add_to_board()` を呼び、`drop_time` をリセット |
| `board[by][bx]` のインデックス外アクセス | `_collision` で `bx, by` が盤面範囲外のときに `if bx < 0 or bx >= WIDTH ...` で早期リターンしているので安全 | 既に守られているが、テスト時に `IndexError` を防ぐための `try/except` を入れても安全 |
| O ブロックの初期位置 | `len(self.matrix[0])` で 2 になるが、`x = WIDTH//2 - 1` で右寄せされる。 | 位置を `x = WIDTH//2`(左寄せ)にすると、すべてのブロックで中央寄せが統一される。 |
---
### 4. コードサンプル(一部リファクタリング例)
```python
# 例: Shape クラスの型ヒントとリファクタリング
from __future__ import annotations
from typing import List
class Shape:
def __init__(self, shape_id: int) -> None:
self.shape_id = shape_id
self.matrix: List[List[int]] = SHAPES[shape_id]
self.rotation = 0
self.x = WIDTH // 2 - len(self.matrix[0]) // 2
self.y = 0
@staticmethod
def _rotate_matrix(matrix: List[List[int]]) -> List[List[int]]:
# 右回転 90°
return [list(row)[::-1] for row in zip(*matrix)]
def _collision(self, board: List[List[int]], matrix: List[List[int]],
x: int, y: int) -> bool:
for i, row in enumerate(matrix):
for j, val in enumerate(row):
if val == 0:
continue
bx, by = x + j, y + i
if bx < 0 or bx >= WIDTH or by < 0 or by >= HEIGHT:
return True
if board[by][bx] != 0:
return True
return False
```
---
### 5. まとめ
- **シンプル**で *動かして遊べる* ところが魅力。
- PEP‑8 などの細かいスタイル問題や、型ヒントを加えることで可読性とメンテナンス性が向上します。
- 回転の「壁クランプ」や入力の滑らか化、スコア・次ブロック表示などを追加すれば、実際にプレイする際の体感が格段に良くなるでしょう。
ぜひ、上記の改善点を一つずつ取り入れてみてください。
実装を進める中で「何ができるのか」「どうしたいか」を明確にしてから改良を加えると、より楽しいテトリスが完成しますよ!
上記のシンプルなものから、下記のような複雑なマルチエージェントの構成も定義できます。いずれもAgent SpecのFlowsを使います。
⑤AutoGenのマルチエージェントにAgent Specのエージェントを追加し拡張
既にAutoGenで開発・運用しているエージェントを拡張するケースのサンプルコードです。
3つのエージェントで動作しているAutoGenのマルチエージェントに、Agent Specのエージェントを一つ追加するようなイメージです。
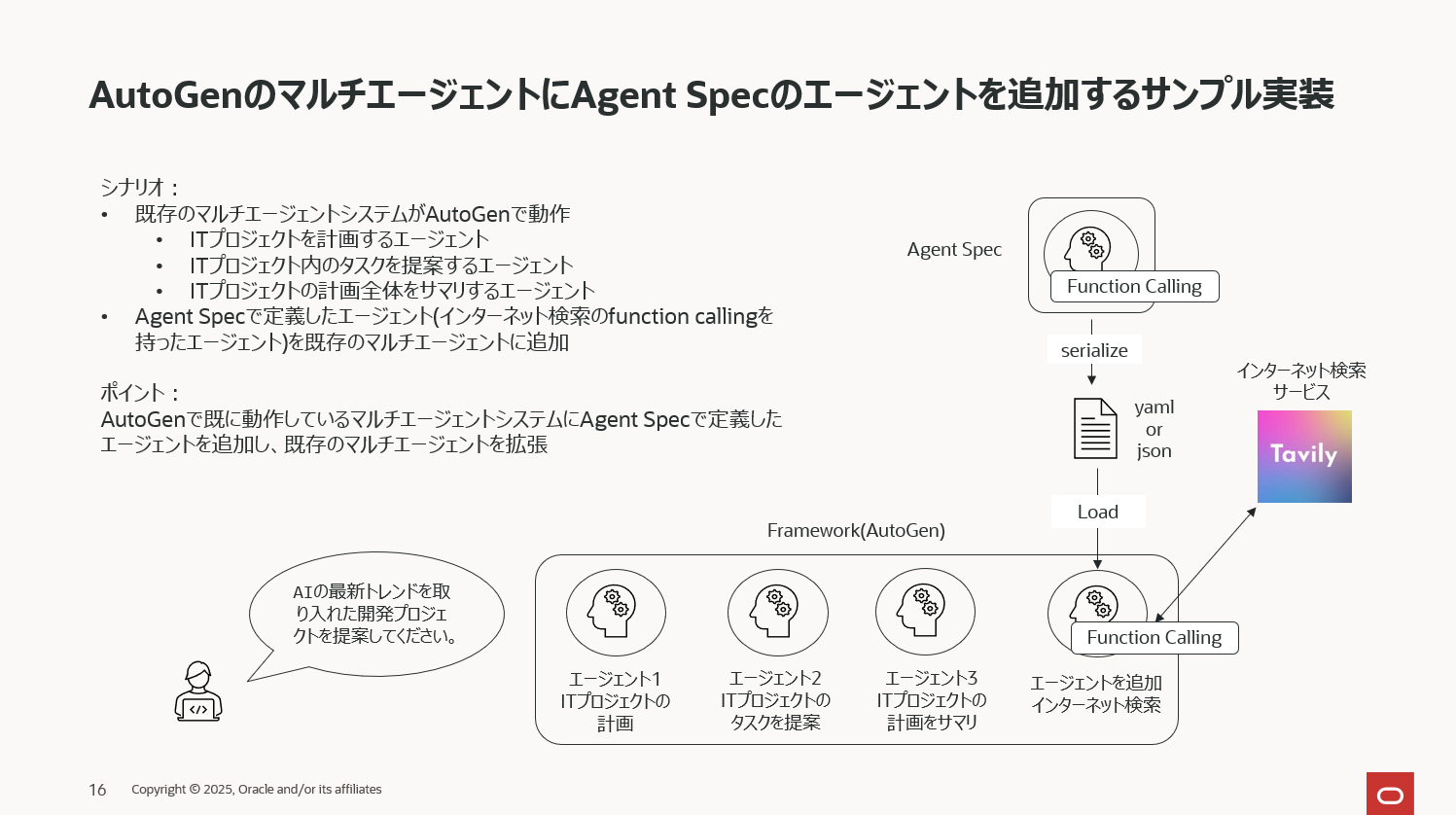
始めに、AutoGenで3つのエージェントからなるマルチエージェントのシステムを定義します。ここは純粋にAutoGenのコードのみで定義し、このマルチエージェントを運用しているという状態を想定しています。
from autogen_ext.models.ollama import OllamaChatCompletionClient
from autogen_core.models import ModelInfo
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
# LLMの定義
model_info = ModelInfo(
model_type="llm",
mode="chat",
vision=False,
function_calling=False,
return_full_text=False,
json_output=False,
)
llm_config_ollama = OllamaChatCompletionClient(
model="gpt-oss:20b",
model_info=model_info,
max_tokens=100,
)
# ITプロジェクト全体をプランするエージェント
planner_agent = AssistantAgent(
"planner_agent",
model_client=llm_config_ollama,
description="ITプロジェクト計画を作成するアシスタント",
system_message="あなたは、ユーザーのリクエストに基づいてITプロジェクトの計画を提案できるアシスタントです。",
)
# 技術的タスクやツール選定を提案するエージェント
task_agent = AssistantAgent(
"task_agent",
model_client=llm_config_ollama,
description="ITタスクやツールを提案するアシスタント",
system_message="あなたは、プロジェクトに必要な技術的タスクやツールをユーザーに提案する便利なアシスタントです。",
)
# 提案を統合して最終的なプロジェクトプランを提示するエージェント
project_summary_agent = AssistantAgent(
"project_summary_agent",
model_client=llm_config_ollama,
description="ITプロジェクト計画をまとめるアシスタント",
system_message="あなたは他のエージェントの提案を統合し、最終的なITプロジェクト計画を提供するアシスタントです。計画が完成したらTERMINATEで応答してください。",
)
termination = TextMentionTermination("TERMINATE")
group_chat = RoundRobinGroupChat(
[planner_agent, task_agent, project_summary_agent],
termination_condition=termination,
max_turns=4
)
AutoGenのマルチエージェントが作れました。
下記で動作確認をします。
from autogen_agentchat.ui import Console
await Console(group_chat.run_stream(task="AIエージェントのプロジェクト案を提示してください。"))
結果は下記の通り、うまく動作しています。
出力結果(非常に長いので折り畳みます。)
---------- TextMessage (user) ----------
AIエージェントのプロジェクト案を提示してください。
---------- TextMessage (planner_agent) ----------
## AIエージェント プロジェクト提案書
(例:**“Personal Productivity AI Assistant”** – 日常業務支援型AI)
| 項目 | 内容 |
|------|------|
| **プロジェクト名** | PPA(Personal Productivity AI) |
| **目的** | 個人や小規模チームの業務効率化を図り、情報検索・タスク管理・スケジュール調整を自然言語で行えるAIアシスタントを構築する。 |
| **対象ユーザー** | フリーランス・スタートアップ創業者・個人事業主・リモートワーカー |
| **主要成果物** | ① Web+モバイルアプリ(チャットインタフェース) ② 企業向け API/統合プラグイン ③ ダッシュボード(タスク・スケジュール可視化) ④ 既存業務ツール(Slack, Outlook, Google Calendar 等)との連携モジュール |
<中略>
---------- TextMessage (task_agent) ----------
## AIエージェント プロジェクト提案書
(例:**“Health‑Wise AI Coach”** – ヘルスケア&ウェルネス支援型AI)
| 項目 | 内容 |
|------|------|
| **プロジェクト名** | HWA(Health‑Wise AI Coach) |
| **目的** | ユーザーの健康・フィットネス・メンタルケアを総合的にサポートし、生活習慣を改善・維持できるようにする。 |
| **対象ユーザー** | 健康志向の一般消費者・ダイエット/筋トレ愛好者・ストレス・不眠を抱える社会人・シニア層 |
| **主要成果物** | ① Web+モバイルアプリ(チャット+ダッシュボード) ② 既存ウェアラブル・ヘルスAPI連携モジュール ③ 週次・月次レポート・進捗通知 ④ 企業向け健康管理パッケージ(職場導入向け) |
---
## 1. 背景・課題
- **健康情報の過剰**:スマホやウェアラブルからのデータが膨大になり、どれを重視すべきか分からないケースが増加。
- **継続的なモチベーション維持**:個人でのダイエットやトレーニングはやる気が続かず、挫折しやすい。
- **メンタルヘルスの可視化不足**:ストレス・不眠の兆候を早期に検知・対処できる手段が限られている。
<中略>
---------- TextMessage (project_summary_agent) ----------
## 1. プロジェクト概要
| 項目 | 内容 |
|------|------|
| **プロジェクト名** | **Unified AI Assistant (UAA)** |
| **ミッション** | 個人の生産性と健康を統合的に支援するAIアシスタントを構築し、日常業務とウェルネスを自然言語でシームレスに管理・最適化する。 |
| **対象ユーザー** | フリーランス・スタートアップ創業者・個人事業主・リモートワーカー・健康志向の一般消費者・企業の従業員 |
| **主要成果物** | ① Web + モバイルチャットアプリ(React/Next + React‑Native)<br>② 生産性・健康データ統合ダッシュボード<br>③ API/SDK(Slack, Outlook, Google Calendar, Trello, Notion, Fitbit, Oura, Apple HealthKit, Google Fit)<br>④ エンタープライズ向け健康管理パッケージ<br>⑤ 24/7 モニタリング・サポートインフラ |
> **理由**
> PPA(Personal Productivity AI)とHWA(Health‑Wise AI Coach)の機能を融合することで、ユーザーは業務タスクと健康状態を同一インターフェースで管理でき、相互に影響を最小化しつつ最大のシナジーを得られる。
---
## 2. 背景・課題
1. **情報過多・分散化**
- メール・チャット・ドキュメント・ウェアラブルデータが多岐にわたり、必要情報の抽出・統合が困難。
2. **業務・健康の分断**
- 生産性向上策と健康維持策が別々に存在し、連携が欠如。
<中略>
## 10. 次のステップ
1. **ステークホルダー合意会議**(要件・予算確定)
2. **最小可用性プロトタイプ**(チャット+タスク+食事提案)
3. **パイロット導入**(30 社・1000 ユーザー)
4. **正式リリース**(段階的スケール)
5. **企業向けパッケージローンチ**(Q4)
---
**完了**
TERMINATE
TaskResult(messages=[TextMessage(id='a59d0b76-f790-4fa5-bd49-c3d76bca77a7', source='user', models_usage=None, metadata={}, created_at=datetime.datetime(2025, 11, 17, 0, 23, 47, 595818, tzinfo=datetime.timezone.utc), content='AIエージェントのプロジェクト案を提示してください。', type='TextMessage'), TextMessage(id='7a40c946-4d60-44b3-9564-557290e9301f', source='planner_agent', models_usage=RequestUsage(prompt_tokens=121, completion_tokens=2712), metadata={}, created_at=datetime.datetime(2025, 11, 17, 0, 24, 22, 249673, tzinfo=datetime.timezone.utc), content='## AIエージェント プロジェクト提案書 \n(例:**“Personal Productivity AI Assistant”** – 日常業務支援型AI)\n\n| 項目 | 内容 |\n|------|------|\n| **プロジェクト名** | PPA(Personal Productivity AI) |\n| **目的** | 個人や小規模チームの業務効率化を図り、情報検索・タスク管理・スケジュール調整を自然言語で行えるAIアシスタントを構築する。 |\n| **対象ユーザー** | フリーランス・スタートアップ創業者・個人事業主・リモートワーカー |\n| **主要成果物** | ① Web+モバイルアプリ(チャットインタフェース) ② 企業向け API/統合プラグイン
<中略>
クティブユーザー | 10,000人(12か月目) |\n| 日次タスク完了率 | 75% |\n| リコメンデーション精度 | 85% 以上 |\n| 平均応答時間 | < 1.5 秒(90%) |\n| NPS | 70 以上 |\n| 連携API数 | 10 以上(Slack, Outlook, Trello, Google Calendar, Fitbit, Oura, Apple HealthKit, Edamam, Apple Health, Google Fit) |\n| 予算遵守率 | 95% 以上 |\n\n---\n\n## 10. 予算概算(12か月) \n| 項目 | 金額(円) |\n|------|-----------|\n| 人件費(7名) | 18,000,000 |\n| LLM API利用料(月平均) | 3,000,000 |\n| クラウドインフラ(AWS, Vercel, Fly.io, Supabase) | 1,200,000 |\n| 外部API利用料・サポート | 300,000 |\n| マーケティング & PR | 600,000 |\n| テスト・セキュリティ | 500,000 |\n| 予備費 | 700,000 |\n| **合計** | **24,200,000** |\n\n> **備考** \n> - LLM API利用料はトークン使用量に応じて変動。 \n> - 人件費は開発・運用・サポートを含む。 \n\n---\n\n## 10. 次のステップ \n1. **ステークホルダー合意会議**(要件・予算確定) \n2. **最小可用性プロトタイプ**(チャット+タスク+食事提案) \n3. **パイロット導入**(30 社・1000 ユーザー) \n4. **正式リリース**(段階的スケール) \n5. **企業向けパッケージローンチ**(Q4) \n\n---\n\n**完了** \nTERMINATE', type='TextMessage')], stop_reason="Text 'TERMINATE' mentioned")
このマルチエージェントに Agent Specで定義したエージェントを一つ組み込みます。
下記で定義しているエージェントは③で定義したエージェント(tavily searchのインターネット検索をfunction callingで定義したエージェント)と全く同じものです。
from getpass import getpass
import os
from tavily import TavilyClient
from pyagentspec.llms import OllamaConfig
from pyagentspec.agent import Agent
from pyagentspec.tools import ServerTool
from pyagentspec.property import StringProperty
# --- API キー入力 ---
if not os.getenv("TAVILY_API_KEY"):
os.environ["TAVILY_API_KEY"] = getpass("Tavily API Key : ")
client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
def tavily_search(query: str):
"""ユーザーの入力に基づいて Tavily Search で検索を実行します。"""
print(f"called tavily_search: {query}")
response = client.search(
query=query,
max_results=3,
search_depth="basic",
topic="general",
include_images=False,
region="JP",
)
results = []
for idx, result in enumerate(response.get("results", []), start=1):
# --- 結果表示 ---
print(f"Result #{idx}")
print(" Title :", result.get("title"))
print(" URL :", result.get("url"))
print(" Snippet:", (result.get("content") or "")[:200], "…\n")
results.append({
"title": result.get("title"),
"url": result.get("url"),
"snippet": (result.get("content") or "")[:200],
})
return results
# LLMを定義
llm_config_ollama = OllamaConfig(
name="Ollama Config",
model_id="gpt-oss:20b",
url="http://localhost:11434"
)
# エージェントの定義
agent = Agent(
name="Tavily Search Agent",
llm_config=llm_config_ollama,
system_prompt="""
あなたは優秀なアシスタントです。事実をもとにユーザーの質問に回答してください。
仮に憶測の情報をもとに回答する場合は必ずその旨を述べて回答してください。
tavily_searchを使ってインターネット検索を行い、最新の情報を元に回答してください。
""",
tools=[
ServerTool(
name="tavily_search",
inputs=[StringProperty(title="query")],
outputs=[StringProperty(title="tavily_search")]
)
],
)
Agent Specで定義した追加用のエージェントを下記コードでシリアライズします。
from pyagentspec.serialization import AgentSpecSerializer
agentspec_with_tool_json = AgentSpecSerializer().to_yaml(agent)
そして、AutoGenのエージェントに変換します。
from autogen_agentspec_adapter import AgentSpecLoader
autogen_agent_with_tool_from_agentspec = AgentSpecLoader(tool_registry={"tavily_search": tavily_search}).load_yaml(agentspec_with_tool_json)
拡張用のエージェントが出来上がりましたので、これをAutoGenの既存のエージェントに追加します。
(AutoGenのグループチャットの定義にautogen_agent_with_tool_from_agentspecを追加)
# AutoGenのマルチエージェントに組み込む
from autogen_agentchat.teams import RoundRobinGroupChat
group_chat_new_member = RoundRobinGroupChat(
[autogen_agent_with_tool_from_agentspec, planner_agent, task_agent, project_summary_agent],
termination_condition=termination,
max_turns=4
)
エージェントが追加されたマルチエージェントを実行してみます。
from autogen_agentchat.ui import Console
await Console(group_chat_new_member.run_stream(task="AIの最新トレンドを取り入れた開発プロジェクトを提案してください。"))
出力結果は以下の通り、うまく動作していることが分かります。
出力結果(非常に長いので折り畳みます)
---------- TextMessage (user) ----------
AIの最新トレンドをインターネットで検索し、それを取り入れた開発プロジェクトを提案してください。
---------- ToolCallRequestEvent (Tavily_Search_Agent) ----------
[FunctionCall(id='3', arguments='{"query": "latest AI trends 2025"}', name='tavily_search')]
---------- ToolCallExecutionEvent (Tavily_Search_Agent) ----------
[FunctionExecutionResult(content='[{\'title\': "6 AI trends you\'ll see more of in 2025 - Microsoft Source", \'url\': \'https://news.microsoft.com/source/features/ai/6-ai-trends-youll-see-more-of-in-2025/\', \'snippet\': \'In 2025, AI will evolve from a tool for work and home to an integral part of both. AI-powered agents will do more with greater autonomy and help simplify your\'}, {\'title\': \'5 AI Trends Shaping Innovation and ROI in 2025 | Morgan Stanley\', \'url\': \'https://www.morganstanley.com/insights/articles/ai-trends-reasoning-frontier-models-2025-tmt\', \'snippet\': \'The top trends in new AI frontiers and the focus on enterprises include AI reasoning, custom silicon, cloud migrations, systems to measure AI\'}, {\'title\': \'AI trends 2025: Adoption barriers and updated predictions - Deloitte\', \'url\': \'https://www.deloitte.com/us/en/services/consulting/blogs/ai-adoption-challenges-ai-trends.html\', \'snippet\': \'From compliance to workforce readiness, explore common organizational barriers to adopting agentic, physical and sovereign AI—and how the\'}]', name='tavily_search', call_id='3', is_error=False)]
---------- TextMessage (Tavily_Search_Agent) ----------
## Project Proposal
**“SmartHealth Assist – AI‑Powered Autonomous Care Agent”**
| **What** | An autonomous, multimodal AI agent that handles every step of a patient’s care journey (from triage & appointment booking to virtual follow‑up & medication reminders) and delivers evidence‑based care recommendations directly to clinicians. |
|----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
---
### 1. Why this idea is timely
| AI Trend (2025) | How it’s leveraged | Key sources |
|-----------------|--------------------|-------------|
| **Agentic & autonomous AI** – “AI agents that can act, plan, and negotiate” | The core of the system is a self‑contained agent that can book appointments, analyze symptoms, and propose next‑steps without human intervention. | “6 AI trends you’ll see more of in 2025 – Microsoft Source” |
| **Foundation models + multimodal reasoning** – Models that combine vision, text, and structured data to reason across domains | Patient records, imaging, voice notes, and wearable data are fed into a multimodal LLM that can synthesize a holistic view and generate personalized care plans. | “AI trends 2025: Adoption barriers and updated predictions – Deloitte” |
<中略>
---------- TextMessage (planner_agent) ----------
## Project Proposal
**“SmartManufacturing AI – Autonomous Plant‑Ops Agent”**
| **What** | An AI‑powered agent that continuously monitors a manufacturing floor, autonomously plans maintenance, optimises production schedules, and delivers explainable insights to plant‑managers and field‑engineers. |
|----------|-------------------------------------------------------------------------------------------------------------------------------------------------------------|
---
### 1. Why this idea is timely
| AI Trend (2025‑2026) | How it’s leveraged | Key sources |
|-----------------------|-------------------|-------------|
| **Agentic & autonomous AI** – “Agents that can plan, negotiate, and act in the real world” | The agent autonomously books maintenance, reallocates resources, and negotiates with vendors, all without human touch‑point. | “AI trends 2025: Agentic systems reshape operations” – Gartner, 2025 |
| **Foundation models + multimodal reasoning** – Models that fuse vision, speech, text, and structured data | Sensor streams (vibration, temperature), camera feeds, maintenance logs, and ERP data are fed into a multimodal LLM that predicts failure modes and proposes counter‑measures. | “Multimodal Foundation Models in Industry” – MIT Technology Review, 2025 |
<中略>
---------- TextMessage (task_agent) ----------
## プロジェクト提案書
**“SmartRetail AI – 自律型店舗・オンライン体験エージェント”**
| **What** | 店舗内・オンラインの顧客接点をすべて統合した、**自律型 AI エージェント**。顧客の動線をリアルタイムで解析し、在庫管理・レコメンド・価格最適化・カスタマーサポートを自動で実行。人手の介入を最小化し、売上と顧客満足度を同時に向上させる。 |
|----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
---
### 1. 企画がタイムリーな理由(2025‑2026 の AI トレンド)
| AI Trend (2025‑2026) | 具体的活用例 | 主な情報源 |
|----------------------|--------------|------------|
| **Agentic & autonomous AI** – “エージェントが行動・計画・交渉を自律的に行う” | エージェントはレジで自動で価格変更、棚卸し作業、広告配置を予約・実行し、同時にオフラインの POS とオンラインのチャットを交差させて交渉。 | Gartner 2025 “AI Trends 2025: Agentic Systems in Retail” |
| **Foundation models + multimodal reasoning** – 画像・音声・テキスト・構造化データを同時に推論 | 店内センサー(人流・熱画像・RFID)+カメラ映像+チャットログ+購入履歴を 1 つの LLM で融合し、顧客行動の “インサイトチェーン” を生成。 | MIT Technology Review 2025 “Multimodal Foundation Models for Retail” |
| **Explainable & trustworthy AI** – 監査・規制対応が必須 | 推薦・価格変更・在庫補充のすべてに “理由チェーン”(ルールベース+LLMトレース)を付与し、ISO 22301・GDPR・PCI‑DSS に自動ログを出力。 | Siemens Xcelerator “Explainable AI in Retail” 2025 |
<中略>
---------- TextMessage (project_summary_agent) ----------
**Unified Autonomous AI Agent Platform (UAAP)**
*An end‑to‑end, domain‑agnostic architecture that leverages 2025‑2026 AI trends to deliver self‑contained, multimodal, explainable agents for healthcare, manufacturing, and retail.*
---
## 1. Project Vision
Deploy a single, extensible agent‑based platform that can be instantiated in **smart care, smart production, and smart retail** contexts.
Each agent is **autonomous, multimodal, and trustworthy**—capable of collecting heterogeneous data, reasoning with foundation models, planning with reinforcement learning, and acting with edge‑first inference—all while producing auditable “reason chains” that satisfy regulatory requirements (HIPAA, ISO 55001, GDPR, PCI‑DSS).
---
## 2. AI‑Trend Matrix (2025‑2026)
| Trend | How UAAP Uses It | Example Benefit |
|-------|-----------------|-----------------|
| **Agentic & Autonomous AI** | Core logic, planning, and actuation handled by a single agent per domain. | 24 h availability, zero‑human‑touch triage/maintenance/sales. |
| **Foundation Models + Multimodal Reasoning** | GPT‑4o/Claude‑3.5 + vision + sensor embeddings + structured data fusion. | Unified “patient‑image‑vitals‑history” or “machine‑vibration‑log‑image” context. |
| **Explainable & Trustworthy AI** | Every recommendation includes a traceable reason‑chain (rule‑based + LLM). | Instant audit compliance for HIPAA, ISO, PCI‑DSS. |
<中略>
5. **NVIDIA, “Edge AI for Domain‑Optimised Deployments.”** 2025.
6. **Harvard Business Review, “Reinforcement Learning for Dynamic Scheduling.”** 2026.
7. **Siemens Xcelerator, “Explainable AI in Healthcare & Manufacturing.”** 2025.
8. **PCI‑DSS & ISO 22301 Compliance Guidelines, 2025 Updates.** 2025.
---
## 7. Next Steps for Stakeholder Alignment
1. **Stakeholder Workshop** – Clarify regulatory scope per domain.
2. **PoC Design Documents** – Detailed data connector specs, domain rule sets, reason‑chain schema.
3. **Cost‑Benefit Model** – Hardware, licensing, staffing, maintenance vs. projected savings.
---
**When you’re ready to move forward, let me know the domain priority (or all three) and I’ll deliver the detailed technical specifications and budget model.**
**TERMINATE**
本記事で説明したサンプル実装はAgent SpecとWayFlowのごく一部になります。下記マニュアルには多数のサンプル実装がありますので是非ご参照ください。
-
Open Agent Specification のマニュアル
https://oracle.github.io/agent-spec/development/agentspec/index.html -
Open Agent Specification の様々な実装サンプル
https://oracle.github.io/agent-spec/development/howtoguides/index.html -
WayFlowのマニュアル
https://oracle.github.io/wayflow/development/index.html -
WayFlowの様々な実装サンプル
https://oracle.github.io/wayflow/development/core/howtoguides/index.html
さいごに
現時点では「フレームワークに依存しない AI エージェントを開発したい」というニーズはまだ多くはないかもしれません。しかし、将来的に自分が使っているフレームワーク以外で画期的な機能が登場した際には、それを試したり、現在運用している AI エージェントに組み込みたいと思う場面が必ず出てきます。
Agent Spec を活用していれば、そのような場合でも 簡単にターゲットのフレームワークへ移植 することが可能で、新機能の導入や検証がスムーズに行えます。また、今後さまざまなベンダーから Agent Spec 対応のクラウドサービスが登場すれば、開発した AI エージェントをどのサービス上でも稼働させられる未来が期待できます。
Agent Spec はまだリリースされて間もないため、サポートされているフレームワークは限定的ですが、これからの発展にぜひご注目ください。