本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。当日は記事内容以外にデモンストレーションも実施する予定です。
以下の記事内容とセットで実施する予定です。以下の記事がメインでこちらの記事がサブというアジェンダとなります。
実施済のセミナー動画がこちら。
本記事のタイトルには「ChatGPT」というキーワードを含めていますが、本文でご紹介するファインチューニングは、OpenAI社のLLMサービスである「GPT」のファインチューニング機能に関する内容です。
なお、ChatGPTはOpenAI社が提供するチャットボットサービスであり、その内部で使用されているLLMをChatGPTの画面からファインチューニングすることは今のところできませんのでご注意ください。
記事執筆時点では、ChatGPTをきっかけにLLMに興味を持ち、ファインチューニングを学びたいという方が多く見受けられました。そのため、より多くの方に関心を持っていただけるよう、あえて記事タイトルに「ChatGPT」という言葉を用いました。
はじめに
2022年暮れ、ChatGPTの登場以降、あらゆる企業がDXの在り方を問われはじめ、大規模言語モデルの仕組みをどのように業務に取り入れるかを検討されていると思います。
その検討の一つとして、「GPT(LLM)が学習していない企業内のデータや最新のデータも有効活用すべき」 という点は非常に大きな論点なのではないでしょうか。
ご存じの通り、LLMとはインターネット上に存在するドキュメントデータをクローリングにより大量に収集し、それを学習データとして機械学習にかけたモデルです。
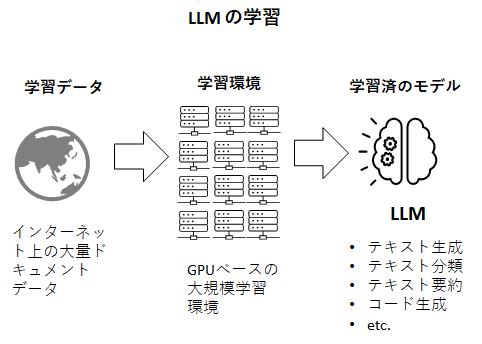
従って、至極当たり前の話ですが、LLMは学習したデータに入っていなかった情報に対する推論はできません。昨日発売されたばかりの新製品の市場での反応や、インターネットに公開されていない社内ドキュメントに関する情報を答えることはLLMプロバイダが提供するデフォルトのLLMではできないのです。
LLMは深層学習の産物であり、その深層学習について知見のある方はファインチューニングと呼ばれる手法があることをご存じだと思います。ファインチューニングとは公開されている学習済のモデルに、独自のデータを追加で学習させ、新たな知識を蓄えたモデルを作り出す技術。LLM以外でも深層学習の世界では伝家の宝刀のように広く知れ渡っており非常に一般的なプラクティスです。
よってLLMでもこれをすればよいということになり、さっそくGPTで試してみたいと思います。
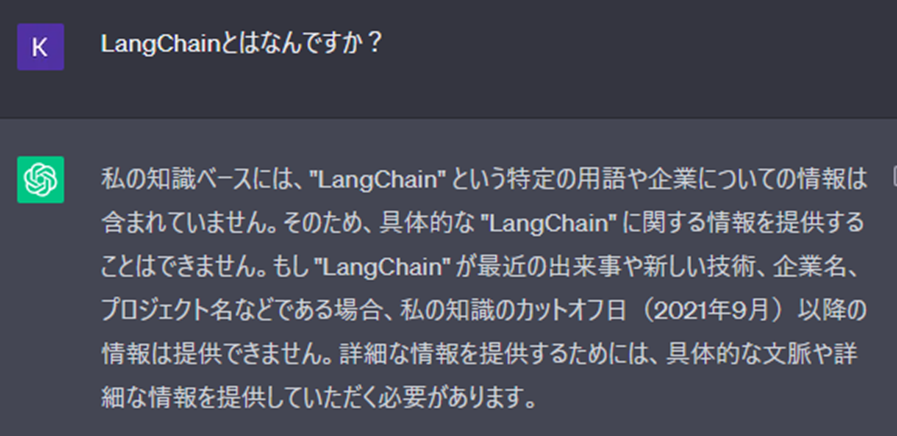
ChatGPTが知らないであろう質問をしてみる
ChatGPT(本記事の場合GPT3.5)が学習しているデータは2021年9月までのデータです。LangChainは2022年10月にリリースされたOSSですのでChatGPTに質問してみても当然以下のようにお馴染みのちょっとつれない回答。
Wikipedia LangChain
もっとわかりやすい例はこちら。
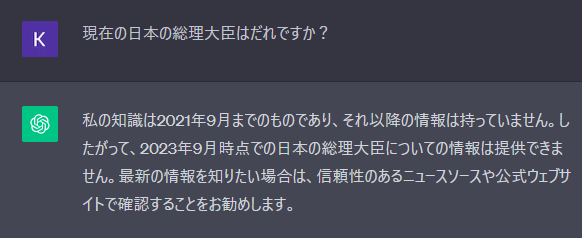
今回は、この状態からファインチューニングにより、LangChainの知識を追加してみます。
ファインチューニングによる知識追加とは
事前学習とファインチューニング
ファインチューニングとは冒頭で説明した通り、既に学習済のモデルを、新たなデータを使って追加学習を行うというものです。この際、初回の学習処理を「事前学習」(pre-trained)、その後の追加学習をそのまま「追加学習」もしくは「ファインチューニング」と呼んでいます。
ChatGPTの中で使われているLLMのGPT(Generative Pre-trained Transformer)はその名の通り、Pre-trained、つまり事前学習済です。 OpenAI社がインターネット上の大量のドキュメントデータをクローリングし、そこから作成したデータセットをあらかじめ事前学習させて提供しているLLMです。
このモデルは2021年9月までのインターネット上のデータを学習しており、同年9月より後に新たに生まれたデータはGPTにとって未知のデータということになります。加えて、インターネットに公開されていない企業内のデータについても学習しようがありません。
そこで、既に大量データで学習済のモデルであるGPTを、上述したようなGPTがまだ学習していないデータを追加で学習させ、GPTに新たな知識を追加する処理をファインチューニングと呼んでいます。
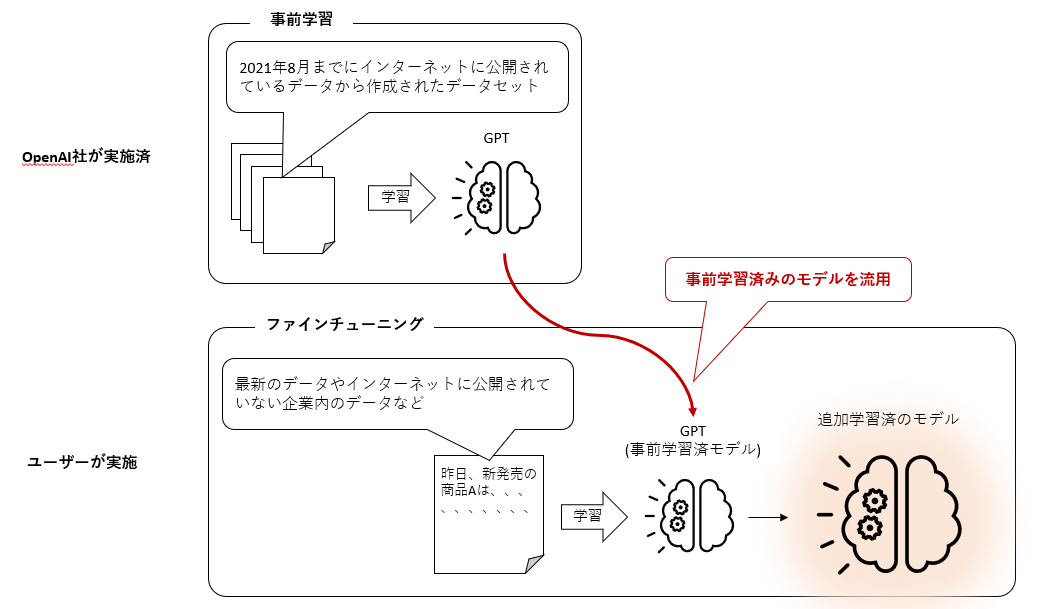
LLMの中で何が起こるのか?
そして、このファインチューニングをすることによって、LLMのニューラルネットワークの中で何が起こっているのでしょう。ファインチューニングでは、既にある程度最適化されているGPTの1750億(GPT4では1兆7千億ともいわれる)の一部のパラメータが新たなデータの学習処理によって更新されることにより、新たな知識を得たことになります。文字通り、パラメータをチューニングするような処理になりますのでファインチューニングという名前が付いています。
このあたりはディープラーニングの基本的な知識になり、もしご興味のある方は以前に実施した下記の動画をご参照ください。(※多少アカデミックな内容になっています)
ファインチューニングの手順概要
本来、ニューラルネットワークのファインチューニングはtensorflowやkeras、pytorchといったライブラリを駆使してコードを書くかなり手間のかかる作業ですが、GPTだけでなく、LLMプロバイダが提供するLLMでは、このファインチューニングが非常に簡単に実行できるようになっています。
GPTでのファインチューニングの作業フローは概ね下図のような流れです。
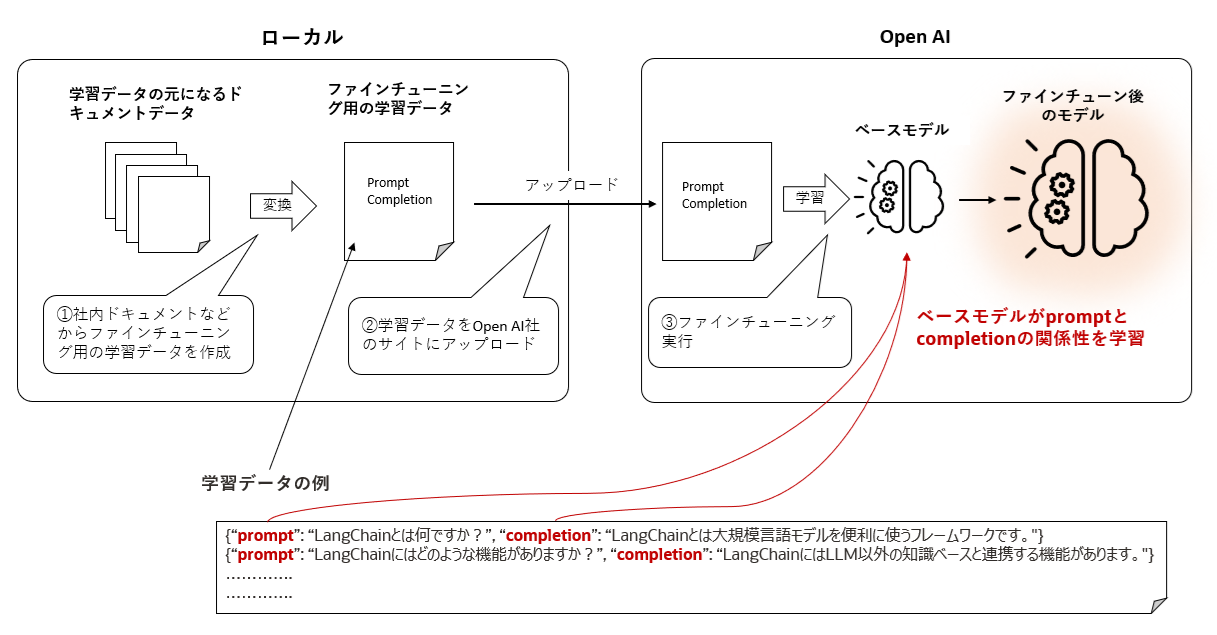
纏めてしまうと下記の3ステップという感じ。
- ファインチューニング用の学習データを作成
上図赤字のようにpromptとcompletionのセットを一行にして多数の行を作成します。promptに記載されているような入力があればcompletionに記載されているような文章を出力するという関係性で学習データを作成します。 - 作成した学習データをOpen AIのサイトにアップロードする
- ベースモデルのファインチューニングを実行
アップロードされた学習データの中のpromptとcompletionの関係性をモデルが学習します。
通常のディープラーニングのモデルでは、ニューラルネットワークの中間層の情報を確認しながらどの層からファインチューニングを行うかなどを決めて学習実行、出来上がったモデルの精度確認という作業を繰り返すことになりかなり大変な作業となりますが、LLMプロバーダーが提供しているモデルではそんなことをする必要はなく、上述したように非常に簡単に処理できるようになっています。
ファインチューニングでは、ローカルに沢山のGPUが必要と思いこまれている方がいるようなのですがそんなことはありませんのでご安心を。GPUパワーが必要な処理はLLMプロバイダー(OpenAI社など)のサイト側で処理されます。もちろんファインチューン用の課金体型があります。特に、ChatGPTでLLMが有名になる前からLLMを使われている方はローカルで全てを処理するケースが多いですから勘違いしがちかもしれません。
どのようなデータを学習させる?
機械学習で一番重要なものは学習データで、これはLLMの事前学習でもファインチューニングでも同じこと。そして、どのような目的(どのような知識を追加したいか)でこの学習データの内容が決まります。今現在、ファインチューニングの対象となるデータとして主だったものは以下の3つです。
-
社内のデータ
企業が持つ社内ドキュメントや、社員が日々作成しているドキュメントデータというものはインターネットに公開されていないものが多々あると思います。当然ながら、LLMプロバイダーが提供しているデフォルトのLLMはこれら企業内データを学習していませんので推論できないということになり、「追加の知識」の最有力候補となります。 -
専門性の高いデータ
基本的にTransformerタイプのLLMはファインチューニングやRAGを構成しなくても、なるべくLLM単体で推論ができることを目的として作られています。ですが、特に専門性の高いデータ(例えば、医療、法律、金融などなど)について言うと、現在一般的に提供されているLLMの推論精度はその分野の専門家が満足するレベルには至っていません。こちらは海外、国内の様々な団体や企業が業界特化型のLLMを開発する市場動向がありますが、まだまだ多くの企業がこのような取り組みを行える状況ではなく、簡単に専門性の高いデータを生成AIの対象にできる構成は需要が高いといっていい状況だと思います。 -
インターネットに公開されて間もない最新データ
LLMはあるインターネットから一定期間ため込まれた情報を使って学習処理を行った結果作られるものであり、インターネットに公開されて間もない最新データは学習していない可能性があります。最新の情報までをカバーしてタイムリーに精度高い推論ができることが求められるシステムも多々あります。
ファインチューニングの3ステップを実行
Step1 ) 学習データを作成
まずは追加学習のデータを用意します。ファインチューニングに使うデータはちょうど、質問(prompt)と回答(completion)のようなセットから構成し、jsonlフォーマットで保存します。
{"prompt": "LangChainとは何ですか?", "completion": "LangChain は、大規模言語モデルを使用してアプリケーションの作成を簡素化するように設計されたフレームワークです。"}
OpenAI社のマニュアルを見ると下記のように、このセットを少なくとも 10 個、通常50 ~ 100 個のトレーニング サンプルを用意せよとのことです。
と、さらっと書きましたがここが本当に大変なところ。。。本記事のようなデモであればちょっと面倒だなと感じる程度なのですが、実運用を考えるとかなりの工数とドメインナレッジを要する作業になることが容易に想像されます。ファインチューニングと言えど、機械学習。機械学習はデータを作るフェーズが結局は一番大変というのはLLMになっても変わらずというところでしょうか。。。
Example count recommendations
To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples with gpt-3.5-turbo but the right number varies greatly based on the exact use case.
We recommend starting with 50 well-crafted demonstrations and seeing if the model shows signs of improvement after fine-tuning. In some cases that may be sufficient, but even if the model is not yet production quality, clear improvements are a good sign that providing more data will continue to improve the model. No improvement suggests that you may need to rethink how to set up the task for the model or restructure the data before scaling beyond a limited example set.
ということで今回は少し少ないとは思いつつ、必要最低とされる以下10行のデータをsample.jsonlというファイル名で保存します。
{"prompt": "LangChainとは何ですか?", "completion": "LangChain は、大規模言語モデルを使用してアプリケーションの作成を簡素化するように設計されたフレームワークです。"}
{"prompt": "LangChainとは何ですか?", "completion": "LangChainには、言語モデルをより便利にするための様々な機能が含まれています。LangChainの主な機能はいくつかのモジュールで実現します。"}
{"prompt": "LangChainとは何ですか?", "completion": "LangChainの機能を用いると、AIが生成した回答を次のプロンプトに含めて入力できます。"}
{"prompt": "LangChainとは何ですか?", "completion": "GPT-3のような大規模言語モデルを利用してサービスの開発をしたいときに便利に使えるライブラリです。"}
{"prompt": "LangChainとは何ですか?", "completion": "ChatGPTのAPIを利用する際の欠点を補いつつ、アプリ開発やビジネスへの導入を目的とする際に非常に便利です。"}
{"prompt": "LangChainとは何ですか?", "completion": "LLMと外部リソースを組み合わせて、より高度なアプリケーションやサービスの開発をサポートすることを目的としているます。"}
{"prompt": "LangChainとは何ですか?", "completion": "OpenAIのChatGPTは一度に扱えるテキスト量に制限がありますが、LangChainを使用することで、これらの制約を克服し、大量のテキストを一度に処理することができます。"}
{"prompt": "LangChainとは何ですか?", "completion": "複数のLLMを組み合わせて活用することができます。複数のLLMの機能を追加したアプリケーション開発が可能です。"}
{"prompt": "LangChainとは何ですか?", "completion": "LangChainは、Python、JavaScript、TypeScriptなどの主要なプログラミング言語に対応しています。"}
{"prompt": "LangChainとは何ですか?", "completion": "例えば長文からなるPDFファイルを入力として要約された文章を受け取りたいという場合、LangChainを用いることで実現可能です。"}
Step 2) 作成した学習データをOpenAIのサイトにアップロード
openaiをインストール。
!pip install openai
OpenAIのサイトで登録したAPI Keyをセットします。
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
作成したデータセット(sample.jsonl)をファインチューニング用にOpenAIのサイトにアップロードします。
import json
import openai
# 学習用データのファイルパス
filepath = "/home/datascience/Langchain/sample.jsonl"
# アップロード
train_file = openai.File.create(
file=open(filepath, "r"),
purpose='fine-tune'
)
# 確認
print(train_file)
上図のようOpenAI社のサイトに目的のファイルがアップロードされたことが確認できます。こでれファインチューニング用データのアップロードが完了です。
Step 3) ファインチューニングの実行
アップロードされたデータを使って、ファインチューニングを実行するコードが下記。この例ではファインチューニングのベースとなるモデルは davinci を使っています。
# ファインチューニング実行
job_finetune = openai.FineTune.create(
training_file = train_file.id, model = 'davinci'
)
上記コードが実行されると、OpenAI社のサイトでファインチューンが実行されます。気をつけたい点としては、上記の処理の時点では、ファインチューンの実行を「予約しただけ」という状況です。つまり、コード実行後に直ぐにファインチューン処理が始まるわけではなく、待ち行列に並んだ状態だということです。
もちろん下記のように、ファインチューニングの処理のステイタスを確認することができます。
from datetime import datetime
# ファインチューニングのステイタス確認
finetune_data = job_finetune.list().data
print(finetune_data)
以下のような出力になりファインチューニングに関する様々な情報を取得できます。(すごく長いので折り畳みます)
出力結果
[<FineTune fine-tune id=ft-ism9RTLGpLjtHpi7tcRTG2OA at 0x7f87dad7c4f0> JSON: {
"object": "fine-tune",
"id": "ft-ism9RTLGpLjtHpi7tcRTG2OA",
"hyperparams": {
"n_epochs": 4,
"batch_size": 1,
"prompt_loss_weight": 0.01,
"learning_rate_multiplier": 0.1
},
"organization_id": "org-JIWNcGvdcc0tpNQDggn9VTyL",
"model": "davinci",
"training_files": [
{
"object": "file",
"id": "file-VWtlZNkzE4MjttAale5UQy9f",
"purpose": "fine-tune",
"filename": "file",
"bytes": 206,
"created_at": 1691144434,
"status": "processed",
"status_details": null
}
],
"validation_files": [],
"result_files": [
{
"object": "file",
"id": "file-P7xEGeeNGSMvogqPmwHDtpDQ",
"purpose": "fine-tune-results",
"filename": "compiled_results.csv",
"bytes": 350,
"created_at": 1691153915,
"status": "processed",
"status_details": null
}
],
"created_at": 1691144479,
"updated_at": 1691153916,
"status": "succeeded",
"fine_tuned_model": "davinci:ft-personal-2023-08-04-12-58-34"
}, <FineTune fine-tune id=ft-Cim0w45IfLzoSU0c169t5Jp4 at 0x7f87dad84360> JSON: {
"object": "fine-tune",
"id": "ft-Cim0w45IfLzoSU0c169t5Jp4",
"hyperparams": {
"n_epochs": 4,
"batch_size": 1,
"prompt_loss_weight": 0.01,
"learning_rate_multiplier": 0.1
},
"organization_id": "org-JIWNcGvdcc0tpNQDggn9VTyL",
"model": "davinci",
"training_files": [
{
"object": "file",
"id": "file-UOqtK5TqB55VFuAiFI5L5D0S",
"purpose": "fine-tune",
"filename": "file",
"bytes": 2213,
"created_at": 1692019910,
"status": "processed",
"status_details": null
}
],
"validation_files": [],
"result_files": [
{
"object": "file",
"id": "file-Rw03DMSqzsuqArL6IpYL5NjI",
"purpose": "fine-tune-results",
"filename": "compiled_results.csv",
"bytes": 2207,
"created_at": 1692021274,
"status": "processed",
"status_details": null
}
],
"created_at": 1692019914,
"updated_at": 1692021274,
"status": "succeeded",
"fine_tuned_model": "davinci:ft-personal-2023-08-14-13-54-33"
}, <FineTune fine-tune id=ft-9rIJEbhQNQUk3q1MGOrP9UOU at 0x7f87dad18270> JSON: {
"object": "fine-tune",
"id": "ft-9rIJEbhQNQUk3q1MGOrP9UOU",
"hyperparams": {
"n_epochs": 4,
"batch_size": 1,
"prompt_loss_weight": 0.01,
"learning_rate_multiplier": 0.1
},
"organization_id": "org-JIWNcGvdcc0tpNQDggn9VTyL",
"model": "davinci",
"training_files": [
{
"object": "file",
"id": "file-I1TpKM4QyNHlW3b8Qrwrc8BP",
"purpose": "fine-tune",
"filename": "file",
"bytes": 2213,
"created_at": 1692699025,
"status": "processed",
"status_details": null
}
],
"validation_files": [],
"result_files": [
{
"object": "file",
"id": "file-R87zOdyuk0bfQQJob3lsJdfE",
"purpose": "fine-tune-results",
"filename": "compiled_results.csv",
"bytes": 2246,
"created_at": 1692699911,
"status": "processed",
"status_details": null
}
],
"created_at": 1692699170,
"updated_at": 1692699912,
"status": "succeeded",
"fine_tuned_model": "davinci:ft-personal-2023-08-22-10-25-10"
}, <FineTune fine-tune id=ft-5auAZtej6YjOivSIa9xtasC9 at 0x7f87dad184f0> JSON: {
"object": "fine-tune",
"id": "ft-5auAZtej6YjOivSIa9xtasC9",
"hyperparams": {
"n_epochs": 4,
"batch_size": 1,
"prompt_loss_weight": 0.01,
"learning_rate_multiplier": 0.1
},
"organization_id": "org-JIWNcGvdcc0tpNQDggn9VTyL",
"model": "davinci",
"training_files": [
{
"object": "file",
"id": "file-pxtA6qJOQbVusLpG7IlgnPwM",
"purpose": "fine-tune",
"filename": "file",
"bytes": 2213,
"created_at": 1695172360,
"status": "processed",
"status_details": null
}
],
"validation_files": [],
"result_files": [],
"created_at": 1695172443,
"updated_at": 1695172577,
"status": "running",
"fine_tuned_model": null
}]
この出力ですと、非常にわかりにくいので必要な個所だけを抜き出してステイタスが簡単にわかるようにしてみます。
from datetime import datetime
for i in range(len(job_finetune)):
timestamp = finetune_data[i].created_at
datetime = datetime.fromtimestamp(timestamp)
fine_tuned_id = finetune_data[i].id
status = openai.FineTune.retrieve(id=fine_tuned_id).status
model = openai.FineTune.retrieve(id=fine_tuned_id).fine_tuned_model
print(f'Queued : {datetime}')
print(f'FineTune ID: {fine_tuned_id}')
print(f'Model: {model}')
print(f'Status: {status}\n')
結果、以下のような出力になります。
この出力は、既に4回のファインチューニングを実行した後のものです。マスクしていますが「ft-」で始まる文字列がファインチューンの処理IDや、そのモデルIDになります。
Queued : 2023-08-04 10:21:19
FineTune ID: ft-ism9RTLGpLjtHpxxxxxxxx
Model: davinci:ft-personal-2023-08-04-12-58-34
Status: succeeded
Queued : 2023-08-14 13:31:54
FineTune ID: ft-Cim0w45IfLzoxxxxxxxxxxx
Model: davinci:ft-personal-2023-08-14-13-54-33
Status: succeeded
Queued : 2023-08-22 10:12:50
FineTune ID: ft-9rIJEbhQNQUk3xxxxxxxxxx
Model: davinci:ft-personal-2023-08-22-10-25-10
Status: succeeded
Queued : 2023-09-20 01:14:03
FineTune ID: ft-5auAZtej6YjOxxxxxxxxxxx
Model: None
Status: pending
この例では、始めの3つはsuceeededのステイタスとなっておりファインチューニングが完了した状態だということがわかります。そして4つ目はまさに待ち行列に並んでいる状態でステイタスがpendingとなっています。(この状態から3日待ってるけど処理が開始しないとブーブーいっている人たちが沢山いるようです。。。筆者の場合は、十数分後にはstartとなり、データ量も少ないため数分の処理でsucceededとなりました。)
ファインチューニングされたモデルが出来上がったので、さっそく質問に答えられるかどうか確認してゆきたいと思います。
# ファインチューン後のモデルを指定
finetuned_model = 'davinci:ft-personal-2023-08-14-13-54-33'
# プロンプトを定義
prompt = "LangChainとは何ですか?"
# 推論の実行
completion = openai.Completion.create(
model= finetuned_model, # 定義したモデルを指定
prompt = prompt, # プロンプトを指定
max_tokens = 1024, # 出力の最大文字数
n = 1, # 出力の数
stop = None, # 指定した単語が出現した場合に文章生成を停止
temperature = 0.5 # 出力の結果のランダム度合いを指定(0 - 2)
)
# 推論結果(completion)からテキストを取得
response = completion.choices[0]["text"]
print(response)
各定義にコメントを入れましたが、肝心な点は、ファインチューンしたモデルIDを、推論で使うモデルとして定義しているという点です。また、推論時によく出てくるパラメータとしてtemperatureというものがあります。
これはLLMが推論する結果のランダム度合いを定義するパラメータです。LLMは質問者の質問内容を理解してそれに答えているわけではなく、あくまでも入力プロンプトに続く文字列を推論しているだけです。
ですので、3回実行した場合、3回とも同じ推論結果になる保証はありません。そのランダムの度合いをこのパラメータで調整します。毎回の出力結果を同じにしたい場合はこのパラメータの値を0にします。
出力結果
結果としては下記のような出力が得られました。

うーん、こんなもんなのか、、、という印象。ざっと見た感じ学習データの一部が単純にミックスされた文章が生成されているだけのように見えます。
やはり、データ量、データの質(質問の回答になるような文章になっているか)が適当だった(特にデータの質)のでしょうがないと言えばしょうがないという感じ。
似たような文章が何度も繰り返されている点については、推論処理実行時のパラメータが足りなかった(frequency_penaltyやpresence_penaltyを付けていなかった)ことが原因でファインチューニングとは直接関係ありません。
とは言え、データ量と質さえ確保すればビジネスに利用できるレベルの文章生成はできるそうな感触は感じます。
ちなみに学習データを一行しかデータを入れなかった場合は以下のような出力結果でお話になりませんでした。さすがにこれはデータ量が少なすぎる。
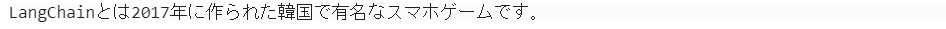
考察
ファインチューニングの処理自体は非常に簡単
まず、LLMプロバイダが提供するLLMサービスのファインチューニングは非常に簡単に実施できることが分かりました。自分でニューラルネットワークのファインチューニングをする作業と比較すると随分と工数は削減できるなという印象。プレイグラウンド(Web UI)からも実行できますのでプログラムを書かずに実行することも可能です。さすがにサービスとして課金するだけあって簡単に実行できるように作られています。
ファインチューニング用データの準備は困難な作業になる可能性あり
ファインチューニングは機械学習の学習処理ということですから、やはりデータの質と量が重要だということを再認識しました。と同時に、実運用を考えると、学習データに関するドメインナレッジはもとより、データを作る工数は非常に高負荷になるだろうと想像します。つまり、大量のドキュメントから抜け漏れなく、promptとcompletionのセットを高品質に作成することが難しいことが予想できます。
RAG構成と比べてどちらが精度が高くなるのか(結局はベンチマークするしかない?)
LLMに知識を追加する手法として、ファインチューニング以外に、RAG(Retrieval-Augmented Generation)と呼ばれる手法が存在します。ファインチューニングは学習データを抜け漏れなく作るという点が困難に感じます。それと比較してRAG構成(特にベクトルデータベースと組み合わせる構成)では、ある程度まとまった単位でテキストデータをベクトルデータベースにロードして適切なインデックスを付けておけばそれなりの文章が生成されるのでファインチューニングの学習データ作りよりも工数は少ないかもしれません。が、どちらの手法がよいかは、結局、実行するタスクやどこまでの精度を求めるかに依存するのだと思います。
RAG構成については以下に記事として作成していますので是非読み比べて比較検討してみてください。
自然言語処理関連のその他の記事